 夜雨聆风
夜雨聆风
以"Prompt 评测系统"的完整开发过程为例,讲清楚 SDD、资产沉淀、TDD + Code Review 三件事。
前后端真实项目:Go + Gin 后端,React + TypeScript 前端。
从一次翻车说起
1.1 需求背景
我们在做一件事:评测 AI Prompt 的产出质量。具体来说——当用户用 Prompt 让 AI 生成"排班表""课程表"这类表格时,我们需要一个系统来评测这些 Prompt 的效果好不好。
这不是一个"写个脚本跑一下"的事情,它是一个有前后端的完整系统:
后端要管理场景(排班表、课程表等不同类型)、管理被评测的 Prompt、调用 LLM 执行评测、计算评分
前端要展示场景列表、评测结果、多 Prompt 之间的横向对比
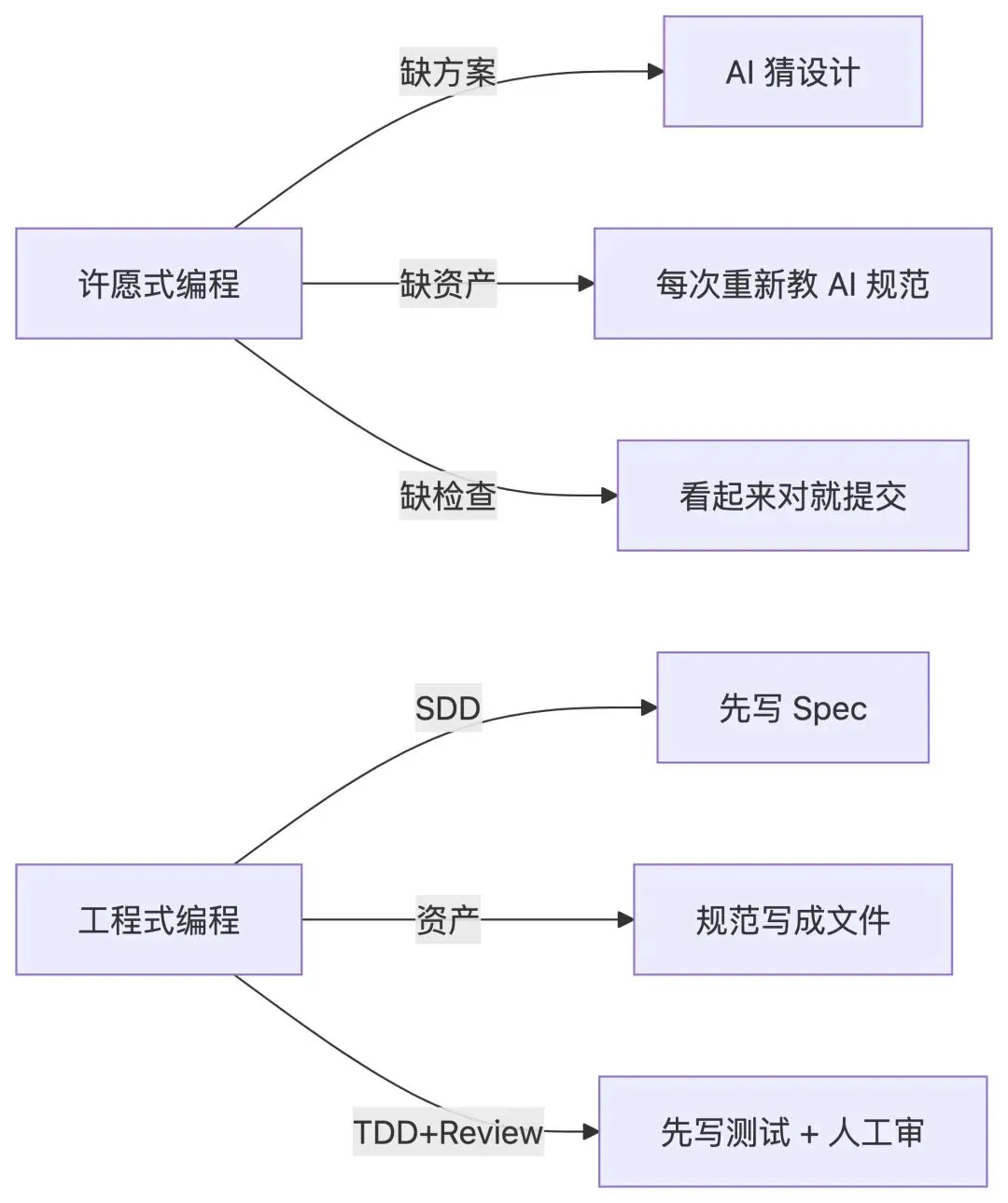
1.2 许愿式对话
大多数人拿到这个需求,跟 AI 的对话是这样的:
帮我做一个 Prompt 评测系统。后端用 Go + Gin,前端用 React。要能评测"新建表格"类 Prompt 的产出质量,比如排班表、课程表这些场景。做好用一点。四句话,需求说完了。AI 开始哐哐写代码。
你很开心——不用自己想架构、不用自己写模型、不用自己配路由。一个小时后,AI 交付了一堆文件:目录结构有、handler 有、前端页面有,go run 能跑,npm start 能开。
1.3 AI 交付了什么
打开后端代码,核心逻辑长这样:
// handler/eval.go — AI 生成的代码func RunEval(c *gin.Context) { prompt := c.PostForm("prompt") result, _ := llm.Call(prompt) db.Create(&EvalResult{ Prompt: prompt, Output: result, Score: 0, }) c.JSON(200, result)}看起来能跑。但你认真读一遍,问题一个接一个冒出来。
1.4 问题全景
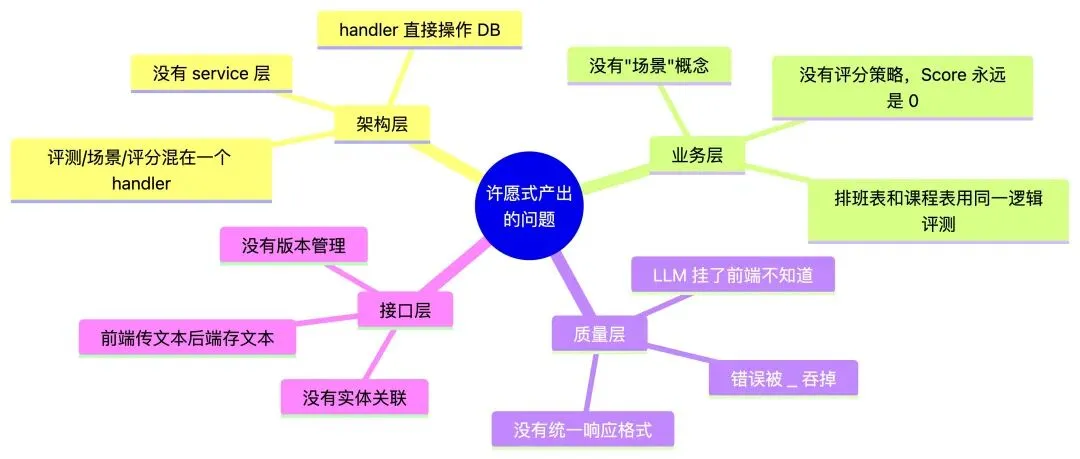
逐个展开:
架构问题 — 所有逻辑堆在一个 handler 里
func RunEval(c *gin.Context) { prompt := c.PostForm("prompt") // 1. 参数绑定 result, _ := llm.Call(prompt) // 2. 业务逻辑(调 LLM) db.Create(&EvalResult{...}) // 3. 数据持久化 c.JSON(200, result) // 4. 响应}参数绑定、业务逻辑、数据操作、响应格式化全在一个函数里。一旦需要改评测逻辑(比如加评分策略),你必须在这个已经很乱的函数里继续加代码。没有 service 层,没有 repository 层,改一处动全身。
业务问题 — 没有"场景"这个概念
排班表的评测维度是"是否满足连班限制""公平性",课程表的评测维度是"是否有时间冲突""教室是否重复分配"。这两个场景的评判标准完全不同。
但 AI 写的代码里只有一个 EvalResult 结构体,没有"场景"这个实体。所有评测用同一个逻辑——等于没有评测。 质量问题 — 错误被静默吞掉
result, _ := llm.Call(prompt) // LLM 返回错误?吞掉。db.Create(&EvalResult{...}) // DB 写失败?不知道。c.JSON(200, result) // 永远返回 200。LLM 服务挂了,前端收到的是 200 + 空内容。DB 写失败了,数据丢了但没人知道。用户看到空白页面,以为系统在加载,等了半天什么都没有。
接口问题 — 没有实体关联
前端传一段 prompt 文本,后端存一段 prompt 文本。没有 ID、没有版本号、没有关联。下次修改了 prompt 内容重新评测,你看不出"这次评测用的是哪个版本的 prompt"——数据库里都是独立的文本记录。
1.5 根因分析
这些问题的根源不是 AI 写代码的能力不行。GPT、Claude 都能写出分层清晰、错误处理完善的代码。问题是:
你没给它足够的设计输入。
四句话的需求里,你没说:
系统里有哪些实体,它们之间什么关系
接口应该长什么样
什么算"做完了"
什么不需要做
AI 只能自己猜。猜对了算运气好,猜错了你花时间纠正——纠正三次发现越改越乱,不如推翻重来。
这就是许愿式编程:把一个模糊的愿望扔给 AI,期待它心领神会。
下面三个原则,就是许愿式编程的解药。
原则一:SDD — 方案先于代码
什么是 SDD
SDD 全称 Specification-Driven Development(规格驱动开发)。核心思想:
在写第一行代码之前,先写一份 Spec(规格文档)。Spec 定义系统里有什么实体、接口长什么样、怎么算做完。AI 读 Spec 写出来的代码,和你想的是一回事。
SDD 不是写长篇大论。对一个中等复杂度的功能,Spec 通常是 30-50 行。但这 30-50 行决定了后面几千行代码的走向。
用 Prompt 评测系统来具体说明。
第一步:定名词 — 系统里有什么东西
这是 SDD 最核心的一步。你要回答的问题是:
这个系统里有哪些实体?它们之间是什么关系?每个实体叫什么名字?
为什么名词这么重要?因为名词会直接变成代码里的结构体、数据库表、API 路径、前端组件。名词层想清楚了,代码的骨架就清楚了。
Scenario(评测场景) 护士排班(nurse)、课程表(course)、工厂排班(factory)、 客服排班(cs_support)、餐饮排班(restaurant) 每个场景包含: - name: 场景名称 - description: 场景描述 - dimensions[]: 评分维度列表(如"格式正确性""约束满足度") - expected_sample: 期望输出示例(给 LLM 做参考)Prompt(被评测对象) 用户提交的 prompt 文本 - content: prompt 内容 - version: 版本号(每次修改自增) - created_at: 创建时间 关系:一个 Prompt 可以跑多个 Scenario 的评测EvalRun(一次评测执行) 一个 Prompt × 一个 Scenario = 一次 EvalRun - prompt_id: 关联 Prompt - scenario_id: 关联 Scenario - model: 使用的 LLM 模型名 - status: pending → running → done / failed - raw_output: LLM 原始输出 - scores: 分维度评分(JSON) - duration_ms: 耗时 - error_msg: 失败原因(status=failed 时) 关系:属于一个 Batch(批量评测)Batch(批量评测) 一次"点击评测"创建一个 Batch,包含 N 个 EvalRun - prompt_id: 这次评测的 Prompt - scenario_ids[]: 选择了哪些场景 - status: pending → running → done / partial_failed - created_at: 创建时间ScoreCard(评分卡) 每个 Scenario 定义自己的评分维度和权重 - scenario_id: 属于哪个场景 - dimensions[]: [{name, weight, description}] 例:护士排班的 ScoreCard 格式正确性(0.3) — 表头、时间粒度、人员列是否齐全 约束满足度(0.4) — 连班限制、公平性是否满足 完整性(0.3) — 是否覆盖了所有时间段和人员这份名词表的价值:
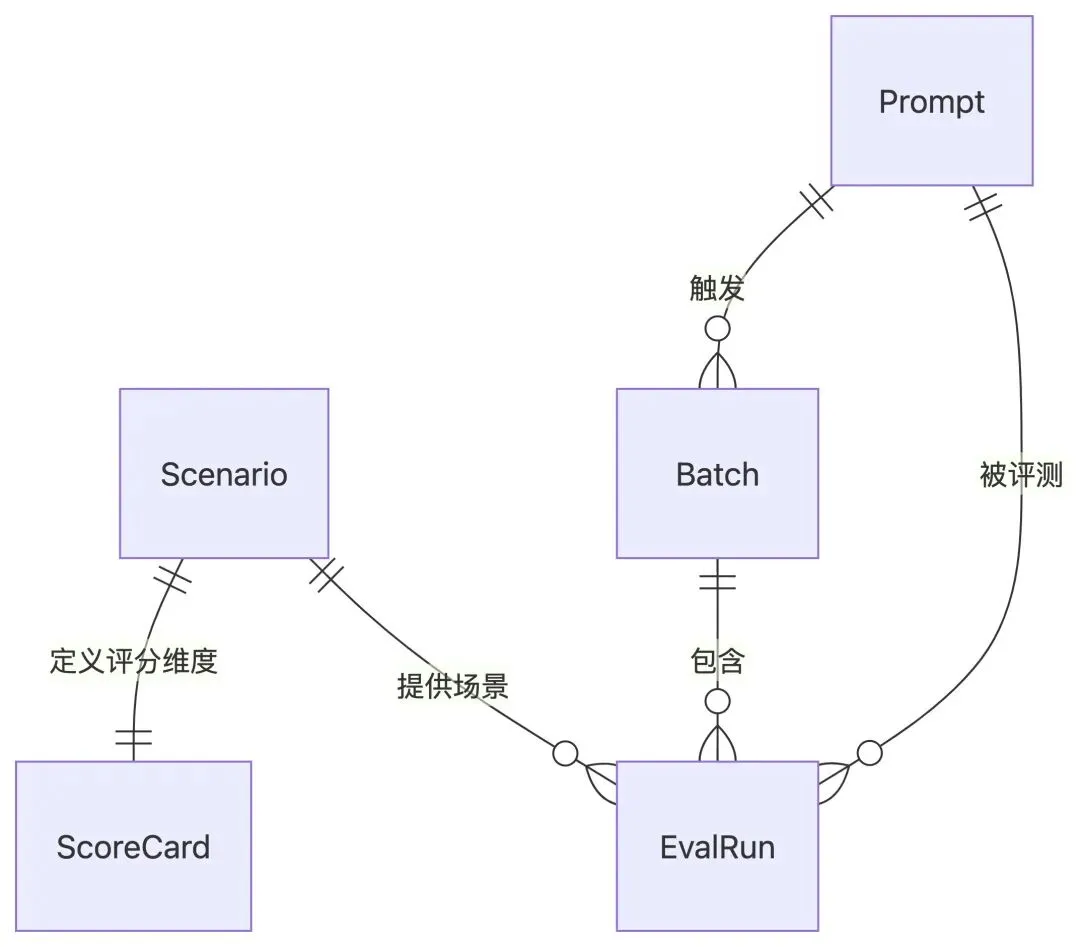
AI 读到这份名词表后:
会创建 5 个结构体 / 数据库表,名字和你定义的一致
会正确建立外键关系:
EvalRun关联Prompt和Scenario不会把所有字段塞进一个
EvalResult里不会自己发明一个你没定义的实体
如果你不写这份名词表,AI 会自己编。编出来的可能叫 Result / Record / Evaluation / Test——在不同文件里用不同的名字指同一个东西,三天后你自己都搞不清楚代码里的 Record 是指评测记录还是日志记录。
第二步:定接口 — 前后端的契约
名词层定义了"有什么",接口层定义了"怎么用"。
后端 REST API:
场景管理 POST /api/scenarios → 创建场景(含评分维度) GET /api/scenarios → 场景列表(分页,支持按名称搜索) GET /api/scenarios/:id → 场景详情(含 ScoreCard) PUT /api/scenarios/:id → 更新场景 DELETE /api/scenarios/:id → 删除场景Prompt 管理 POST /api/prompts → 提交新 Prompt GET /api/prompts → Prompt 列表(分页) GET /api/prompts/:id → Prompt 详情 PUT /api/prompts/:id → 更新 Prompt(版本号自增) GET /api/prompts/:id/versions → Prompt 版本历史评测执行 POST /api/eval/run → 创建批量评测 请求体: { prompt_id, scenario_ids[], model } 响应: { batch_id, eval_run_ids[] } 行为: 创建 Batch + N 个 EvalRun,异步执行,立即返回 GET /api/eval/batch/:batch_id → 查询批量评测结果 响应: { batch, eval_runs[] }(含每个 run 的状态和评分)评测对比 GET /api/eval/compare → 多 Prompt 对比 参数: prompt_ids[]=1&prompt_ids[]=2&scenario_id=3 响应: { scenario, prompts_scores[] }(同场景下不同 Prompt 的评分)统一响应格式:
{ "code": 0, "data": { ... }, "msg": "ok"}错误响应:
{ "code": 40001, "data": null, "msg": "scenario not found"}前端页面结构:
/scenarios → 场景列表页 ├── 场景卡片网格(名称、维度数、评测次数) └── "新建场景" 按钮 → 弹窗表单/scenarios/:id → 场景详情页 ├── 基本信息编辑 ├── 评分维度管理(拖拽排序、权重调整) └── 期望输出示例编辑/prompts → Prompt 列表页 ├── Prompt 卡片列表(内容预览、版本号、最近评测评分) └── "提交新 Prompt" 按钮/prompts/:id → Prompt 详情页 ├── Prompt 内容编辑区 ├── 版本历史时间线 └── "选择场景 → 开始评测" 操作区/eval/:batchId → 评测结果页 ├── Batch 状态概览(进度条:3/5 完成) └── 按场景分组的评分卡片: ┌─────────────────────────────┐ │ 护士排班 │ │ 格式正确性 ██████████░░ 0.85 │ │ 约束满足度 ████████░░░░ 0.70 │ │ 完整性 █████████░░░ 0.80 │ │ 综合评分 ████████░░░░ 0.78 │ └─────────────────────────────┘/compare → 对比页 ├── 选择要对比的 Prompt(多选) ├── 选择对比的场景 └── 雷达图 / 柱状图展示同场景下不同 Prompt 的评分这份接口契约的价值:
后端和前端可以并行开发。后端按契约写 handler,前端按契约 mock 数据先行
AI 生成的路由路径、请求参数、响应结构和你定义的完全一致
前端工程师看到这份契约就知道要调哪些接口、数据结构长什么样
第三步:定验收标准 — 怎么算做完
验收标准不是"测试通过",是一组具体的场景描述,每个场景都能用手点一遍或写一个测试来验证。
## 验收场景清单### 场景管理- [ ] 新建"护士排班"场景,配置 3 个评分维度(格式/约束/完整性),设置权重- [ ] 编辑场景,修改评分维度的权重,保存后刷新页面数据一致- [ ] 删除场景时,如果有关联的 EvalRun,提示"该场景下有 N 条评测记录,确认删除?"### Prompt 管理- [ ] 提交一个新 Prompt,版本号为 1- [ ] 修改该 Prompt 内容,保存后版本号变为 2,版本历史显示两条记录### 评测执行- [ ] 选择 1 个 Prompt + 3 个场景,点击"开始评测"- [ ] 页面跳转到评测结果页,显示进度(0/3 → 1/3 → ... → 3/3)- [ ] 每个场景展示分维度评分,格式如上述评分卡片- [ ] 综合评分按 ScoreCard 权重加权计算### 异常处理- [ ] LLM 调用失败时,该 EvalRun 状态为 failed,显示错误信息- [ ] Batch 中部分 Run 失败时,Batch 状态为 partial_failed- [ ] 网络断开时前端显示重试提示### 对比功能- [ ] 选择两个 Prompt,在同一个场景下对比评分- [ ] 雷达图 / 柱状图展示各维度得分差异第四步:定不做清单 — 显式的边界
"不做清单"比"做什么"更重要。 为什么?
你不说"不做流式输出",AI 就会主动给你搞 SSE 推送——几百行代码处理流式连接、前端 EventSource 监听、断线重连。你没要求,也不需要,但 AI 觉得"这样更好"就给你加了。审代码时你得看、得理解、得判断这几百行是否正确——白白浪费你的审查精力。
## 不做清单- ✗ 不做 Prompt 自动优化/改写(本系统只评测,不优化)- ✗ 不做多用户权限系统(单用户够用,不需要登录)- ✗ 不做 LLM 响应的实时流式展示(评测是异步的,不需要实时看生成过程)- ✗ 不做评测结果的导出/分享功能(第一版不需要)- ✗ 不做 Prompt 模板市场 / 社区功能- ✗ 前端不做 SSR,纯 CSR 就行每一条"不做"都在为你省代码、省审查时间、省理解成本。
SDD 的效果对比
把上面四步写完,你得到的是一份大约 50-80 行的 Spec。下面对比两种方式的结果:
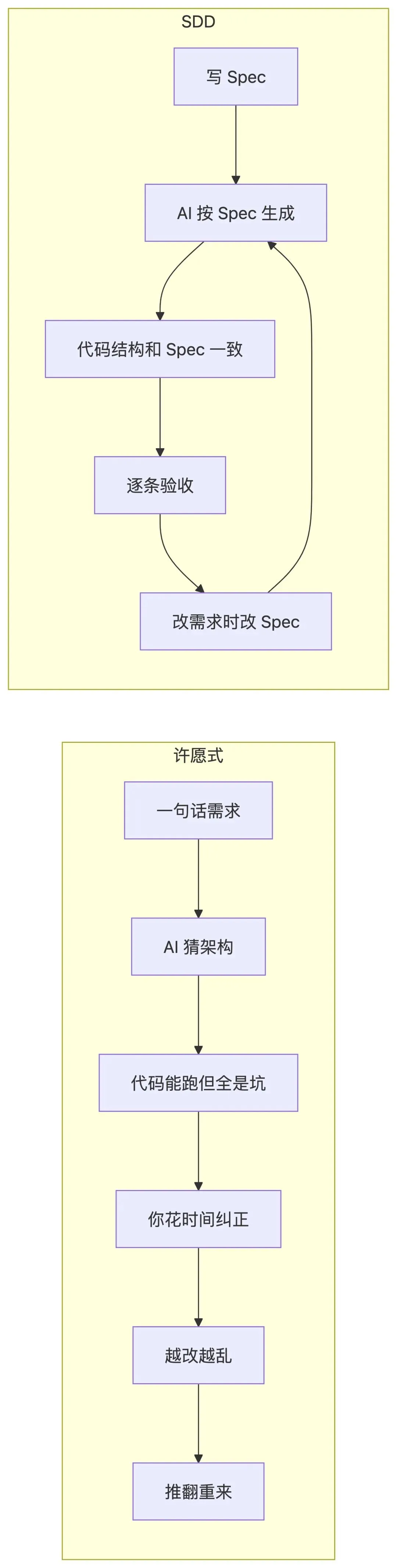
| 维度 | 许愿式 | SDD |
SDD 的本质:把"你脑子里的设计决策"变成"AI 能读到的文件"。
原则二:资产是 AI 的工作记忆
你有没有这样的经历
你跟 AI 说"帮我写一个创建场景的 API"。AI 给你写了:
// AI 第一次写的 CreateScenariofunc CreateScenario(c *gin.Context) { var s models.Scenario c.ShouldBindJSON(&s) // 没检查 error db.DB.Create(&s) // handler 直接操作 DB c.JSON(200, s) // 应该返回 201 // 没有统一响应格式}你纠正:"不要在 handler 里直接操作数据库,走 service 层;返回用统一 envelope;创建返回 201。"
AI 改了。
然后你说"帮我写一个创建 Prompt 的 API"。AI 给你写了:
// AI 写的 CreatePrompt — 又犯了同样的错func CreatePrompt(c *gin.Context) { var p models.Prompt c.ShouldBindJSON(&p) // 又没检查 error db.DB.Create(&p) // 又直接操作 DB c.JSON(200, p) // 又返回 200}同样的错误,每个 handler 犯一遍。
为什么?因为 AI 没有记忆。每一次对话,甚至同一次对话里切换了话题,AI 都可能"忘记"你之前说的规范。你的项目约束在你脑子里,不在 AI 能读到的地方。
解决方案:写成文件
把你反复纠正的东西写成一份文件,放在项目里。AI 每次启动都会读到它。
完整的 AGENTS.md 示例:
# Prompt 评测系统 — AI 协作规范## 架构分层本项目使用三层架构: handler → service → repository- handler 只做:参数绑定(ShouldBindJSON)、调用 service、格式化响应- service 做:业务逻辑、校验、编排- repository 做:数据库操作(GORM)**硬约束:handler 中禁止出现任何 db.* 调用。**## Go 编码规范### 错误处理- 错误必须处理,禁止 `_, err := xxx` 后不检查 err- 禁止 `_ = xxx` 吞掉可能失败的调用- 业务错误用自定义错误码,不要用 HTTP status code 表达业务含义### 响应格式所有 API 返回统一 envelope: 成功: { "code": 0, "data": {...}, "msg": "ok" } 失败: { "code": 40001, "data": null, "msg": "场景不存在" }HTTP Status Code 约定:- 200: 查询成功 / 更新成功- 201: 创建成功- 204: 删除成功- 400: 参数校验失败- 404: 资源不存在- 500: 服务端内部错误### 并发- 共享状态用 sync.Mutex 保护- channel 优先于 mutex(当逻辑适合 CSP 风格时)- goroutine 必须有退出机制,禁止泄漏## GORM 约定- 表名 snake_case 复数:scenarios, prompts, eval_runs, batches- 主键用 uint 自增- 软删除用 gorm.DeletedAt- 时间字段用 time.Time,不要用 int64 时间戳- 警惕 N+1 查询:批量关联查询用 Preload- 事务操作用 db.Transaction(func(tx *gorm.DB) error {...})## 前端规范### 技术栈- React 18 + TypeScript(strict 模式)- 状态管理:zustand(不用 redux)- 请求:axios,统一封装在 /src/api/ 目录- UI 组件库:antd### 代码规范- 组件 PascalCase:ScenarioCard.tsx- hooks 以 use 开头:useScenarioList.ts- API 文件以资源命名:/src/api/scenario.ts- 禁止 any 类型断言- 禁止 inline style(用 CSS Modules 或 tailwind)## 提交规范- type 用英文,description 用中文- scope 用模块目录名- 格式:`feat(scenario): 新增场景的评分维度管理`- type: feat / fix / refactor / docs / test / chore有规范和没规范的代码对比
没有规范 — AI 写的 CreateScenario:
func CreateScenario(c *gin.Context) { var s models.Scenario c.ShouldBindJSON(&s) db.DB.Create(&s) c.JSON(200, s)}5 行代码,4 个问题:没检查绑定错误、直接操作 DB、没用 envelope、创建返回 200。
有规范 — AI 读到 AGENTS.md 后写的 CreateScenario:
func (h *ScenarioHandler) CreateScenario(c *gin.Context) { var req dto.CreateScenarioReq if err := c.ShouldBindJSON(&req); err != nil { c.JSON(http.StatusBadRequest, envelope.Error( code.InvalidParam, "参数校验失败: "+err.Error(), )) return } scenario, err := h.scenarioService.Create(c.Request.Context(), req) if err != nil { c.JSON(http.StatusInternalServerError, envelope.Error( code.InternalError, err.Error(), )) return } c.JSON(http.StatusCreated, envelope.OK(scenario))}✅ 参数绑定检查了 error
✅ handler 不碰 DB,调 service
✅ 统一 envelope 响应
✅ 创建返回 201
✅ 传了 context(支持超时取消)
关键区别:这不是 AI 变聪明了,是你给了它正确的约束。
更重要的是——你只需要写一次 AGENTS.md,后面写 CreatePrompt、CreateEvalRun、CreateBatch 时,AI 每一个 handler 都会自动遵守这些规范。写一次,省 N 次纠正。
资产分层
不是所有信息都放在一个文件里。不同层级的信息有不同的受众和生命周期:
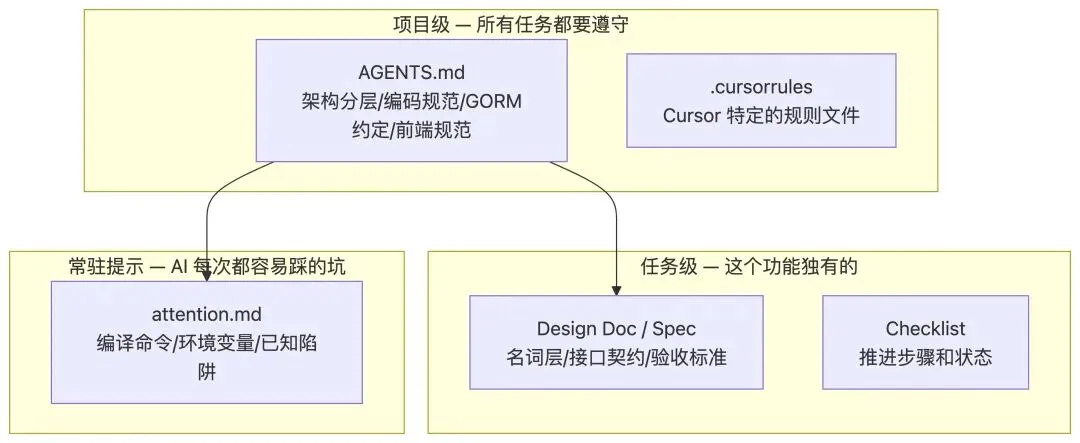
| 层级 | 内容示例 | 载体 | 生命周期 |
| 项目级 | |||
| 任务级 | |||
| 常驻提示 |
常驻提示的具体示例:
# attention.md — AI 每次启动必读## 环境- Go 1.22, Node 20- PostgreSQL 15(Docker)- LLM API Key 通过环境变量 LLM_API_KEY 注入,绝对不要硬编码## 开发命令- 后端启动: `go run cmd/server/main.go`- 前端启动: `cd frontend && npm run dev`(proxy 到 localhost:8080)- 跑测试: `docker compose up -d postgres && go test ./...`## 已知陷阱- GORM 的 AutoMigrate 在有外键的表上顺序敏感,先迁移被引用的表- LLM 调用平均 3-5 秒,批量评测必须异步,不要在 handler 里同步等- antd 的 Form.Item 在 strict mode 下会有 ref 警告,用 forwardRef 包一层写好资产的三个标准
资产不是写得越多越好。烂的资产比没有资产更糟——AI 读到一堆冲突的、过时的规则,产出的代码会更混乱。
标准 1:具体
❌ 注意代码分层✅ handler 中禁止出现任何 db.* 调用前者 AI 读了可以忽略(太模糊不知道怎么做),后者 AI 读了必须遵守(明确到可以 grep 检查)。
标准 2:可验证
❌ 代码要写得好✅ 所有 API 返回统一 envelope: { "code": 0, "data": {...}, "msg": "ok" }后者你可以在 Code Review 时一眼看出是否遵守了——看响应格式就知道。
标准 3:最小必要
❌ Go 语言的 goroutine 是轻量级线程,由 Go runtime 调度...(教科书搬运)✅ goroutine 必须有退出机制,禁止泄漏AI 已经知道 goroutine 是什么,你不需要教它。你只需要告诉它你的项目里对 goroutine 有什么特殊要求。
原则三:TDD + Code Review — 人在环
SDD 和 TDD 的关系
SDD 管的是"做什么"——先写 Spec,定义实体、接口、验收标准。
TDD 管的是"做对没"——先写测试,定义"正确行为"的标准。
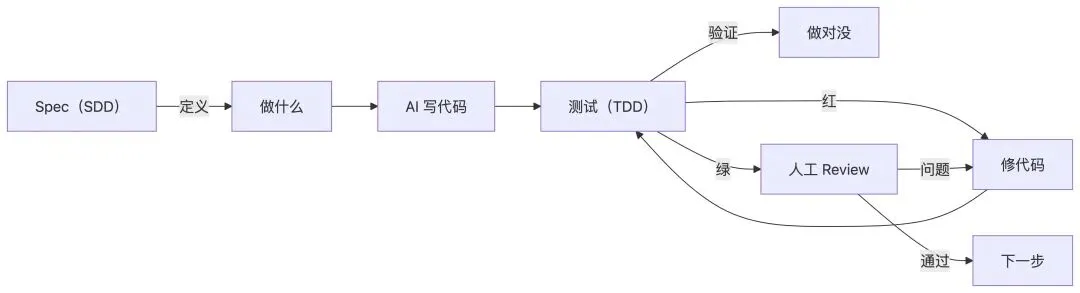
两个一起用,形成完整的闭环:
SDD:你写 Spec → AI 按 Spec 生成代码
TDD:你写测试 → AI 的代码必须通过测试
Review:测试过了,你再审一遍核心逻辑
TDD 是什么
TDD(Test-Driven Development,测试驱动开发)的核心流程是红 → 绿 → 重构:
🔴 红 — 先写测试,让它失败
在写任何实现代码之前,先写一个测试。这个测试描述的是"正确的行为应该是什么样"。因为还没有实现代码,测试必然失败(红色)。
🟢 绿 — 写最少的代码让测试通过
让 AI 写实现代码,目标是让刚才的测试从红变绿。只写刚好够让测试通过的代码,不多写。
🔵 重构 — 优化结构
测试通过了,代码能跑了。现在审一遍结构,优化可读性、性能、可维护性。重构的安全网就是刚才写的测试——改完跑一遍,还是绿的就没改坏。
TDD 实操:评测服务
用 Prompt 评测系统的核心逻辑来演示完整的 TDD 流程。
场景 1:正常评测流程
先写测试,定义"正确行为":
func TestRunBatch_Success(t *testing.T) { // 准备:mock 依赖 promptRepo := &mockPromptRepo{ data: map[uint]*Prompt{1: {ID: 1, Content: "生成一个护士排班表..."}}, } scenarioRepo := &mockScenarioRepo{ data: map[uint]*Scenario{ 1: {ID: 1, Name: "nurse", Dimensions: []Dimension{ {Name: "格式", Weight: 0.3}, {Name: "约束", Weight: 0.4}, {Name: "完整", Weight: 0.3}, }}, }, } llmClient := &mockLLM{ response: "| 时间 | 护士A | 护士B |\n| 8:00-16:00 | ✓ | |\n...", } svc := NewEvalService(promptRepo, scenarioRepo, llmClient) // 执行 batch, err := svc.RunBatch(context.Background(), 1, []uint{1}, "gpt-4") // 断言 assert.NoError(t, err) assert.Equal(t, "done", batch.Status) assert.Len(t, batch.Runs, 1) run := batch.Runs[0] assert.Equal(t, "done", run.Status) assert.Equal(t, uint(1), run.PromptID) assert.Equal(t, uint(1), run.ScenarioID) assert.NotEmpty(t, run.RawOutput) assert.Greater(t, run.DurationMs, int64(0)) // 评分应该有 3 个维度,每个维度 0-1 之间 assert.Len(t, run.Scores, 3) for _, score := range run.Scores { assert.GreaterOrEqual(t, score.Value, 0.0) assert.LessOrEqual(t, score.Value, 1.0) }}这个测试在实现代码写好之前会编译失败(NewEvalService 还不存在)。这就是红色。
然后让 AI 写实现,让测试变绿。
场景 2:LLM 调用失败
这是许愿式编程最容易漏的场景:
func TestRunBatch_LLMFails(t *testing.T) { svc := NewEvalService( mockPromptRepo, mockScenarioRepo, &failingLLM{err: errors.New("rate limit exceeded")}, ) batch, err := svc.RunBatch(context.Background(), 1, []uint{1, 2}, "gpt-4") // 批量评测不应该因为单个 LLM 调用失败就整体失败 assert.NoError(t, err) assert.Equal(t, "partial_failed", batch.Status) // 失败的 run 应该有明确的错误信息 failedRun := batch.Runs[0] assert.Equal(t, "failed", failedRun.Status) assert.Contains(t, failedRun.ErrorMsg, "rate limit") assert.Empty(t, failedRun.Scores)}为什么先写这个测试很重要?
如果你先让 AI 写代码再补测试,AI 大概率会写 result, _ := llm.Call(...) 把错误吞掉。然后你补测试时,你会下意识写一个"验证当前行为"的测试——因为代码已经在那里了,你会写出一个跟代码行为一致的测试。错误被吞了?那我测试里也不检查错误好了。
先写测试就不会有这个问题。 你在写测试时脑子里想的是"正确行为应该是什么"——LLM 挂了,这条 run 应该标 failed,应该有错误信息。测试先写好了,AI 必须写出满足这个行为的代码。
场景 3:Prompt 不存在
func TestRunBatch_PromptNotFound(t *testing.T) { svc := NewEvalService( &emptyPromptRepo{}, // 空 repo,找不到任何 prompt mockScenarioRepo, mockLLM, ) _, err := svc.RunBatch(context.Background(), 999, []uint{1}, "gpt-4") assert.Error(t, err) assert.Contains(t, err.Error(), "prompt not found")}场景 4:并发安全
func TestRunBatch_Concurrent(t *testing.T) { svc := NewEvalService(mockPromptRepo, mockScenarioRepo, mockLLM) var wg sync.WaitGroup for i := 0; i < 10; i++ { wg.Add(1) go func() { defer wg.Done() _, err := svc.RunBatch(context.Background(), 1, []uint{1}, "gpt-4") assert.NoError(t, err) }() } wg.Wait() // 应该有 10 个独立的 batch,不应该相互影响 batches, _ := batchRepo.List() assert.Len(t, batches, 10)}写完这 4 个测试场景,你还没写一行实现代码,但你已经定义了:
正常流程的完整行为
LLM 失败时的降级策略
资源不存在时的错误处理
并发场景下的隔离性
现在让 AI 写实现。AI 必须让这 4 个测试全部通过。
Code Review:测试能过 ≠ 代码没问题
AI 写完了代码,测试全绿了。你能放心了吗?
不能。来看一个例子——AI 写的 RunBatch 实现:
func (s *EvalService) RunBatch( ctx context.Context, promptID uint, scenarioIDs []uint, model string,) (*Batch, error) { prompt, err := s.promptRepo.Get(ctx, promptID) if err != nil { return nil, fmt.Errorf("prompt not found: %w", err) } batch := &Batch{ PromptID: promptID, Status: "running", } s.batchRepo.Create(ctx, batch) var runs []EvalRun for _, sid := range scenarioIDs { sc, _ := s.scenarioRepo.Get(ctx, sid) // ← 问题 1 output, err := s.llm.Call(ctx, prompt, sc, model) // ← 问题 2 run := EvalRun{ BatchID: batch.ID, PromptID: promptID, ScenarioID: sid, Model: model, } if err != nil { run.Status = "failed" run.ErrorMsg = err.Error() } else { run.Status = "done" run.RawOutput = output run.Scores = s.score(sc, output) } runs = append(runs, run) } s.runRepo.BatchCreate(ctx, runs) // 更新 batch 状态 allDone := true hasFailed := false for _, r := range runs { if r.Status == "failed" { hasFailed = true } if r.Status != "done" { allDone = false } } if allDone { batch.Status = "done" } else if hasFailed { batch.Status = "partial_failed" } s.batchRepo.Update(ctx, batch) batch.Runs = runs return batch, nil}测试全过了。但你 Review 时应该发现这些问题:
| 严重度 | 位置 | 问题 | 细节 |
sc, _ := s.scenarioRepo.Get(...) | 错误被吞 | s.score(sc, output) 会 panic | |
for _, sid := range scenarioIDs | 串行调 LLM | ||
s.scenarioRepo.Get(ctx, sid) | N+1 查询 | ||
| 没有幂等 | |||
s.batchRepo.Creates.runRepo.BatchCreate + s.batchRepo.Update | 没有事务 |
为什么测试全过了但还有这些问题?
因为测试用的是 mock。mock 的 scenarioRepo.Get 永远返回正确的数据,不会触发 nil panic。mock 的 LLM 是瞬间返回,不会暴露串行耗时问题。
这就是为什么 TDD 之后还需要人工 Review。
TDD 保证的是"行为正确"——输入什么、输出什么、错误时怎么办。但 TDD 不保证:
代码是否和 Spec 一致(Spec 说异步,代码是同步的)
是否有性能问题(串行 vs 并行)
是否有数据一致性问题(事务)
是否有边界 case 的代码缺陷(nil 引用)
Review 的两个层面
AI 能帮你做的(自动化):
你可以让 AI 审自己写的代码——是的,让 AI Review AI 写的代码。这不是浪费,因为"写代码的 AI"和"审代码的 AI"虽然是同一个模型,但 prompt 不同、关注点不同。
请 review 以下代码,重点检查:1. 错误处理是否完整(有没有 _ 吞错误的地方)2. 是否有 N+1 查询3. 是否有并发安全问题4. 是否和 design.md 里定义的接口一致AI 能找到大部分机械性问题:吞错误、N+1、类型断言无保护。
你必须亲自看的(工程判断):
核心业务逻辑 — AI 会"语义幻觉":代码逻辑通顺但业务含义错误。比如评分权重加权公式写反了,AI Review 可能看不出来
和 Spec 的一致性 — Spec 说异步执行,代码是同步的。AI Review 可能不知道去对照 Spec
边界和并发 — 空值、重复请求、竞态条件。这些需要你结合业务场景去想"用户会不会这样操作"
架构合理性 — 代码能跑,但如果场景从 5 个变成 500 个,串行调 LLM 的方案还行不行?
完整的 Review 检查清单
## Code Review 检查清单### 正确性- [ ] 错误处理完整,没有 _ 吞错误- [ ] nil/空值检查到位- [ ] 边界条件覆盖(空数组、零值、负数、超长字符串)- [ ] 并发安全(共享状态有锁保护、goroutine 有退出机制)### 与 Spec 一致性- [ ] 实体命名和 Spec 名词层一致- [ ] API 路径、参数、响应和 Spec 接口契约一致- [ ] 行为和 Spec 验收场景一致(异步执行?分页?状态流转?)- [ ] "不做清单"里的功能确实没做(AI 有时会画蛇添足)### 性能- [ ] 没有 N+1 查询(循环里查 DB)- [ ] 没有不必要的串行等待(可并行的操作是否并行了)- [ ] 大数据量场景是否分页### 安全- [ ] 没有硬编码的密钥/token- [ ] SQL 注入防护(GORM 参数化查询,不要拼字符串)- [ ] 权限校验(即使第一版不做权限系统,也要确认没有越权漏洞)### 可维护性- [ ] 函数不超过 80 行- [ ] 没有神秘常量(magic number)- [ ] 变量命名清晰kflow 的设计思路:为什么需要这些节点
kflow[1]是我私下用的比较多的一个工作流:
前面讲了三个原则(SDD、资产、TDD + Review),但这些原则单独存在时,你很容易忘——忙起来就跳步骤了,觉得"这次简单,不用写 Spec 了吧"。
kflow 是一个把这些原则固化成工作流节点的框架。每个节点存在都有一个具体的理由:它在防止一个你一定会犯的错。
全流程一图

下面逐个节点解释:它在防什么?如果跳过它会怎样?
k-brainstorm — 防止"没想清楚就开干"
防什么错:你有一个模糊的想法——"做个评测系统"——直接去写代码。结果写到一半发现"排班表和课程表的评分维度不一样,我的数据模型根本没考虑这个",推翻重来。
这个节点做什么:
不是让你写文档,是让 AI 当思考伙伴挑战你的想法。它会问:
"你说的评测,是评测 Prompt 的输出格式?还是评测内容的正确性?还是两个都要?"
"排班表和课程表的评测标准一样吗?不一样的话你需要一个'场景'的概念"
"这个系统是你自己用还是团队用?影响要不要做权限"
通过这些追问,你脑子里模糊的想法被逐步澄清。
分诊机制:brainstorm 不是无限发散。它有三个出口:
| 聊完发现... | 走向 |
如果跳过:你直接让 AI 写代码。AI 按自己的理解猜了一个架构,你不满意,改,再改,越改越乱。花了一天时间跟代码较劲,其实 30 分钟的 brainstorm 就能把方向定下来。
k-feat-design — 防止"AI 和你想的不是一回事"
防什么错:你告诉 AI "做个评测系统",AI 开始写代码。写完你发现:它把所有逻辑塞进一个 handler、没有场景的概念、评分永远是 0——就是本文开头的翻车场景。
这个节点做什么:
强制你在写代码之前产出一份方案文件(design.md)。方案文件有固定结构:
方案文件结构(design.md)├── 第 0 节:术语约定 — 统一名词,避免"你说的 Record 和我说的 Record 是不同东西"├── 第 1 节:决策与约束 — 需求摘要 + "明确不做" + 关键决策理由├── 第 2 节:名词与编排│ ├── 2.1 名词层 — 实体、接口、类型定义("现状 → 变化"两段式)│ ├── 2.2 编排层 — 主流程图、调用链、错误处理策略│ └── 2.3 挂载点 — 本 feature 改动了哪些已有模块的哪些位置├── 第 3 节:验收契约 — 关键场景清单 + 反向核对项("不做"的事确实没做)└── 第 4 节:与架构文档的关系 — 这个 feature 完成后要回写哪些架构文档为什么要这么细? 因为每一节都在解决一个具体问题:
| 方案节 | 解决的问题 |
checkpoint 机制:方案写完,AI 不会自动开始写代码。必须等你确认方案(status: approved)才进入下一步。 这就是"人在环"——你在方案层面签了字,才允许 AI 动手。
如果跳过:就是本文开头的翻车。AI 按自己的理解写了一版代码,你发现问题后开始在代码层面纠正——但代码层面的纠正效率极低,因为你在跟几千行代码打交道,而不是跟 50 行 Spec 打交道。
k-feat-impl — 防止"AI 一口气跑到底"
防什么错:你确认了方案,让 AI 开始写代码。AI 一口气写了 20 个文件、3000 行代码。你打开一看——前面一半没问题,后面一半偏了。但前后代码已经耦合在一起,你没法只回滚后一半。
这个节点做什么:
把实现过程按步骤切片。方案文件里的推进策略被抽成一个 checklist(checklist.yaml),每个步骤是一个独立的、可验证的切片:
steps: - slug: scenario-crud title: "Scenario CRUD" status: pending - slug: prompt-crud title: "Prompt CRUD" status: pending - slug: eval-core title: "EvalRun + Batch 评测核心" status: pending - slug: compare title: "Compare 对比功能" status: pending - slug: frontend-pages title: "前端页面" status: pendingAI 每次只做一个步骤。做完一步,汇报这一步改了什么、通过了什么测试,然后等你确认再做下一步。
三条写代码的姿态(kflow 在 k-feat-impl 里强制的):
写最少的代码 — 只写当前步骤需要的。不顺手加"以后可能要"的抽象层
不顺手改邻居 — 这个函数旁边的函数风格丑?除非跟本次改动冲突,否则别碰。记成后续 issue
方案没说的事不自己拍板 — 写到一半发现方案没覆盖的角落?停下来,回方案讨论,不要硬冲
如果跳过:AI 一口气写完所有代码。你审的时候面对的是 3000 行 diff——实际上没人能有效 Review 3000 行。结果是你走马观花看了一遍,说"看起来没问题",但实际上串行调 LLM、N+1 查询、错误吞掉这些问题全漏了。
k-feat-accept — 防止"做完了没人检查"
防什么错:代码写完了,测试也过了,你说"好了可以 merge 了"。三天后发现评分公式跟方案里写的不一样——方案说按维度权重加权,代码里是简单平均。
这个节点做什么:
逐节对照方案和代码,产出一份验收报告。不是走过场——它有 9 个必填节:
验收报告结构├── 1. 接口契约核对 — 方案定义的接口,代码一一对应了吗?├── 2. 行为与决策核对 — 方案说"异步执行",代码真的是异步的吗?│ └── 挂载点反向核对 — grep 代码里本 feature 的所有引用,确认都在清单内├── 3. 验收场景核对 — 场景清单逐条跑,附可观察证据├── 4. 术语一致性 — 方案叫 EvalRun,代码里有没有叫 Result 的地方?├── 5. 架构归并 — 新增的实体/流程写回架构文档├── 6. 需求回写 — 需求文档反映这个能力已实现├── 7. Roadmap 回写 — 如果从 roadmap 发起,标记为 done├── 8. attention.md 候选 — 这次踩的坑有没有下次还会踩的?└── 9. 遗留 — 后续优化点、已知限制两个关键设计:
发现偏差先修代码,不是在报告里写"已知偏差"。报告里写"已知偏差暂不处理"是反模式——下次按方案找代码会被绊倒
用户终审确认,AI 产出验收报告后必须等你确认才算完
如果跳过:代码 merge 了,方案和代码之间出现了偏离但没人知道。三个月后有人看方案文档理解系统,按方案去找代码,发现对不上——方案变成了误导性文档。
k-onboard + attention.md — 防止"AI 每次失忆"
防什么错:你每次新开一个对话窗口,都要告诉 AI "我们用 GORM,注意 N+1""handler 不碰 DB""创建返回 201"。换个窗口,全忘了。
这个节点做什么:
k-onboard 在项目里创建一套标准骨架(.kflow/ 目录),其中 attention.md 是 AI 每次启动必读的文件——相当于 AI 的"上下文预热"。
所有 kflow 的技能在启动时,第一件事都是:
开始任何判断或动作前,先读取 attention.md
这意味着 AI 不会失忆。你写在 attention.md 里的编译命令、环境变量、已知陷阱,AI 每次都能看到。
如果跳过:你反复纠正同一个错误。每个 handler 都在犯"handler 直接操作 DB"的问题,你纠正了 CreateScenario 的,CreatePrompt 又犯。写一次 AGENTS.md + attention.md,这些问题永远消失。
k-audit — 防止"只修不扫"
防什么错:你每天在写新功能、修 bug。但没有人主动扫描"已有代码里有没有安全漏洞、性能问题、架构偏离"。问题一直在那里,直到某天线上出事了才发现。
这个节点做什么:
在你指定的范围内主动扫描代码,按 5 个维度出一份发现清单:
| 维度 | 扫什么 |
每个发现打严重度 × 性质 × 置信度三个标签,附 文件:行号 + 代码片段。
关键设计:audit 只发现不修。修是 k-issue / k-refactor 的事。这样避免"顺手修"导致的范围蔓延——修一个顺手改了三个,最后分不清这次改动到底为了什么。
为什么需要人工 checkpoint
你可能会问:为什么不让 AI 自己跑完全流程?为什么每个阶段之间都要人确认?
因为 AI 有一个根本性的局限:它不为结果负责,你为。
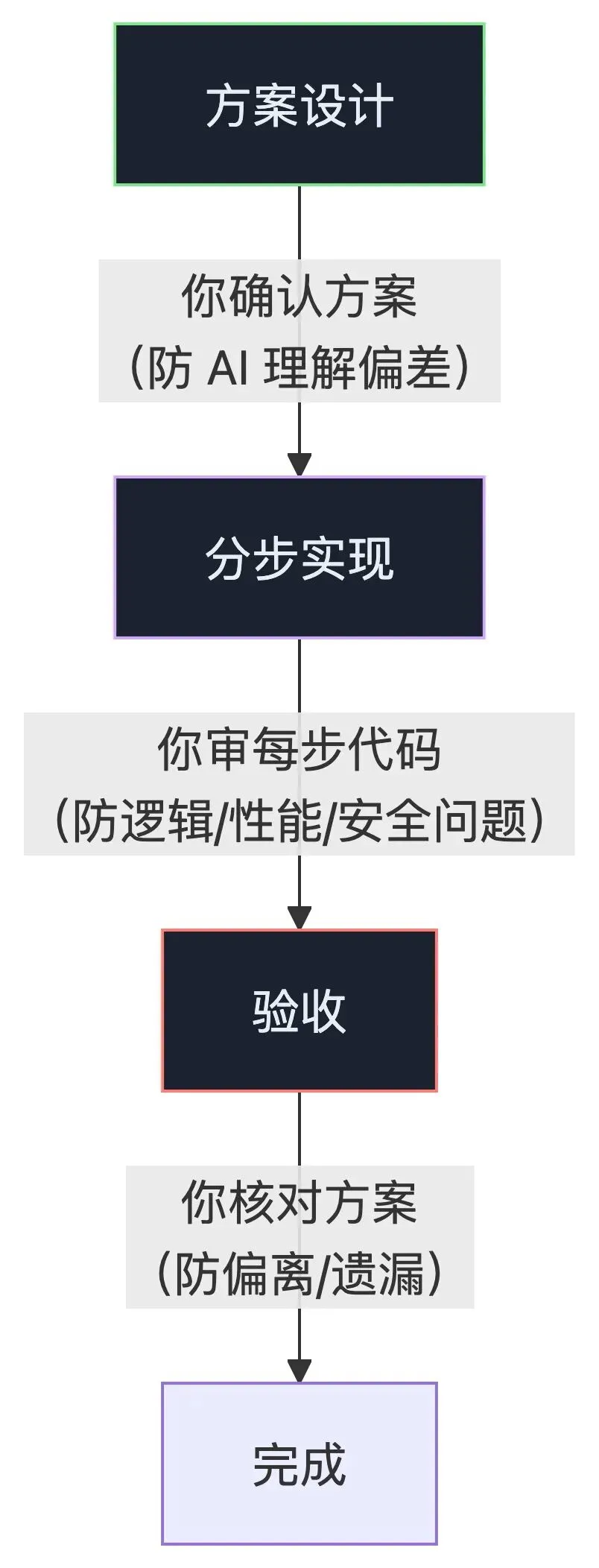
每个 checkpoint 拦截的是不同类型的风险:
| checkpoint | 你确认的是什么 | 防的是什么风险 |
AI 一口气跑完会怎样? 你会拿到一个"看起来完整"的系统。测试可能也过了。但方案理解有偏差、某些接口设计不合理、错误处理有漏洞——这些问题埋在几千行代码里,你只有逐行读才能发现。这比在方案阶段花 5 分钟确认方向贵 100 倍。
把三个原则串起来:完整工作流
三个原则不是独立的,它们组成了一个完整的工作流:
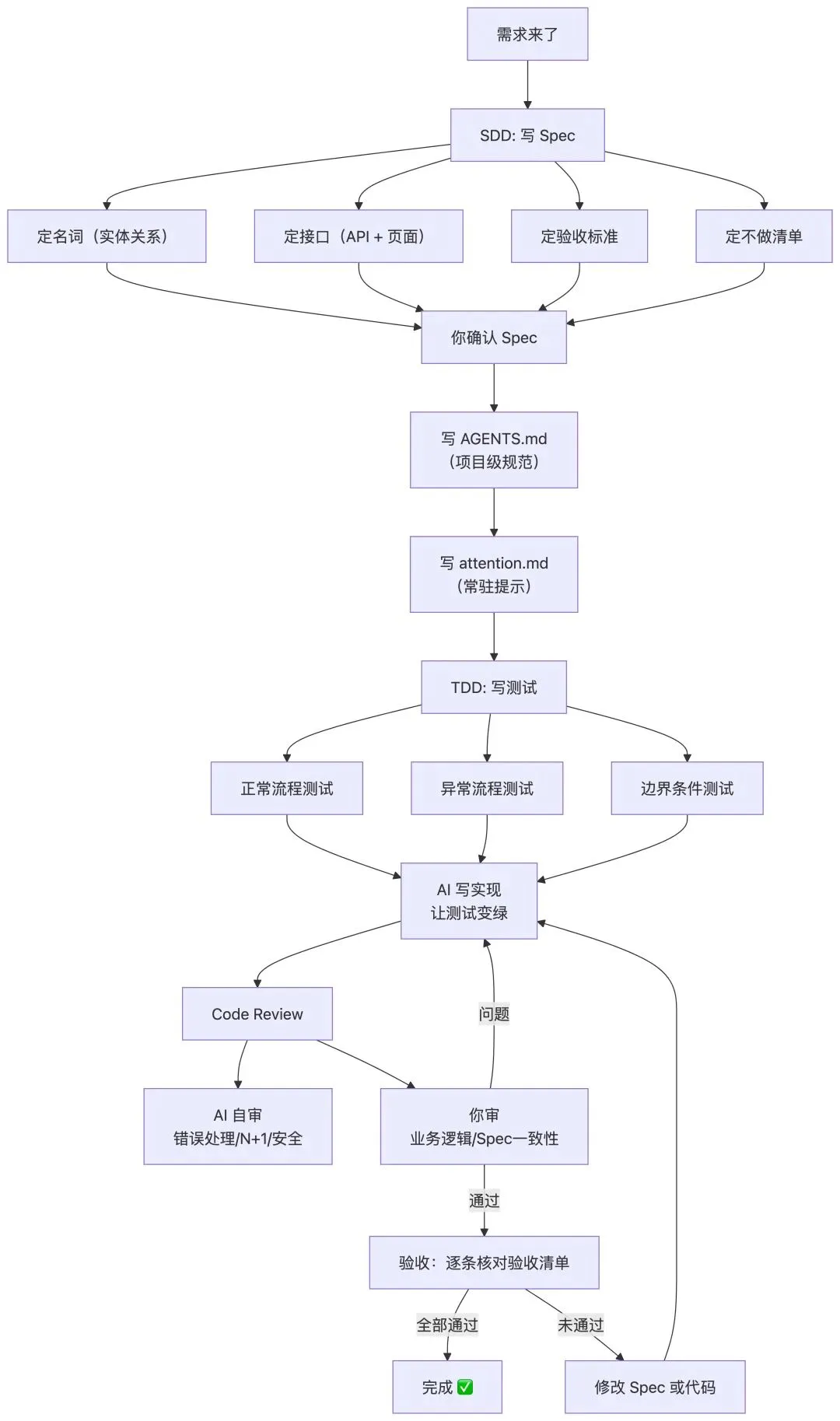
实际执行节奏
以 Prompt 评测系统为例,一个推荐的执行节奏:
第 1 步:SDD(约 30 分钟)
写 Spec——名词层、接口、验收标准、不做清单。不需要很长,50-80 行。
第 2 步:资产准备(约 15 分钟)
如果是新项目,写 AGENTS.md 和 attention.md。如果项目已有这些文件,检查是否需要补充。
第 3 步:分步实现(主体时间)
不要一口气让 AI 把整个系统写完。按 API 拆分:
Step 1: Scenario CRUD(场景管理) → 写测试 → AI 实现 → Review → 通过Step 2: Prompt CRUD(Prompt 管理) → 写测试 → AI 实现 → Review → 通过Step 3: EvalRun + Batch(评测执行核心) → 写测试(重点:异步、失败降级、并发) → AI 实现 → Review → 通过Step 4: Compare(对比功能) → 写测试 → AI 实现 → Review → 通过Step 5: 前端页面 → 按页面拆分,每个页面单独实现和验证每一步都是一个完整的 TDD 循环。不要跳步骤——Step 3 的评测核心是最复杂的,如果跳过测试直接让 AI 写,就会重蹈开头"翻车"的覆辙。
第 4 步:验收(约 20 分钟)
拿出验收场景清单,逐条手动跑一遍。测试过了不代表业务对了——前端点一遍才能确认用户体验是否符合预期。
三个原则的常见误区
| 误区 | 正解 |
总结
| 原则 | 做什么 | 具体落地 |
| SDD — 方案先于代码 | ||
| 资产即记忆 | ||
| TDD + Review — 人在环 |
许愿式编程的反面不是"不用 AI",是用工程方法驾驭 AI。
AI 是高效执行体。你给它一句话的许愿,它给你一堆能跑但经不起推敲的代码。你给它一份 Spec + 一套规范 + 一组测试,它给你一个和你预期一致的系统。
差别不在 AI,在你。
原则、节点、工具——三层对应
最后做一个总览,把前文讲的三个原则、kflow 的流程节点、以及你日常可以用的工具串起来:
| 原则 | 解决的问题 | kflow 节点 | 节点做什么 | 你的动作 |
| SDD | ||||
| SDD | ||||
| 资产 | .kflow/ 骨架,初始化 attention.md / AGENTS.md | |||
| 资产 | ||||
| TDD + Review | ||||
| TDD + Review | ||||
| 持续质量 |
这套东西不是在增加你的工作量——是在把"你迟早要做的事"搬到更早、更便宜的阶段去做。
方案阶段改一行 Spec 需要 1 分钟。代码阶段改一个设计决策需要 1 小时。线上阶段改一个架构问题需要 1 天。
kflow 的所有节点设计,本质上就是在帮你花今天的 1 分钟,省明天的 1 小时。
引用链接
[1]https://github.com/kunbo928/kflow
