 夜雨聆风
夜雨聆风很多人用 Ollama 的第一反应,是把它当成“本地跑大模型的命令行工具”:安装、拉模型、ollama run llama3,然后开始对话。
这个理解没有错,但如果只停在使用层,会错过 Ollama 源码里最有价值的一条主线:一个看起来很轻的 CLI 命令,背后其实跨过了本地 daemon、HTTP API、模型调度器、runner 缓存,以及一个真正负责推理的 llama-server 子进程。

本文源码基准
为了避免版本变化导致读者校对不上,先把本文使用的源码快照放在这里:
- • 本地源码目录:
sources/ollama - • 分支:
main - • commit:
11be8f6ac87479bbb0cb3370de9f46c678681b53 - • commit 时间:
2026-05-29 16:33:40 -0700 - • commit 信息:
mlx: fix dev mode search path (#16355)
后面提到的路径和源码行为,都以这个快照为准。Ollama 迭代很快,如果你在更新版本里核对,局部实现和文件位置可能已经变化。
说明:本系列为 AI 辅助源码阅读,已尽量按本地源码和 pinned commit 核对,但仍可能存在遗漏、理解偏差或版本差异。关键细节请以对应 commit 的源码、测试和官方文档为准。
先抓住一条链路
读 Ollama 源码,最容易走偏的地方,是一上来就把它看成一个普通 Go API server。
真正值得跟的链路是:
ollama run -> Cobra command -> local API client -> /api/generate -> Scheduler -> LlamaServer interface -> llama-server /completion
这条链路解释了几个关键问题:
- • 为什么
ollama run有时会自动拉起本地 server。 - • 为什么一次请求可能复用已有模型,也可能触发加载、排队或卸载。
- • 为什么 Go 层没有直接实现推理,而是把请求转给本地
llama-server。 - • 为什么用户看到的是连续输出,代码里却是本地 HTTP 与流式响应在配合。
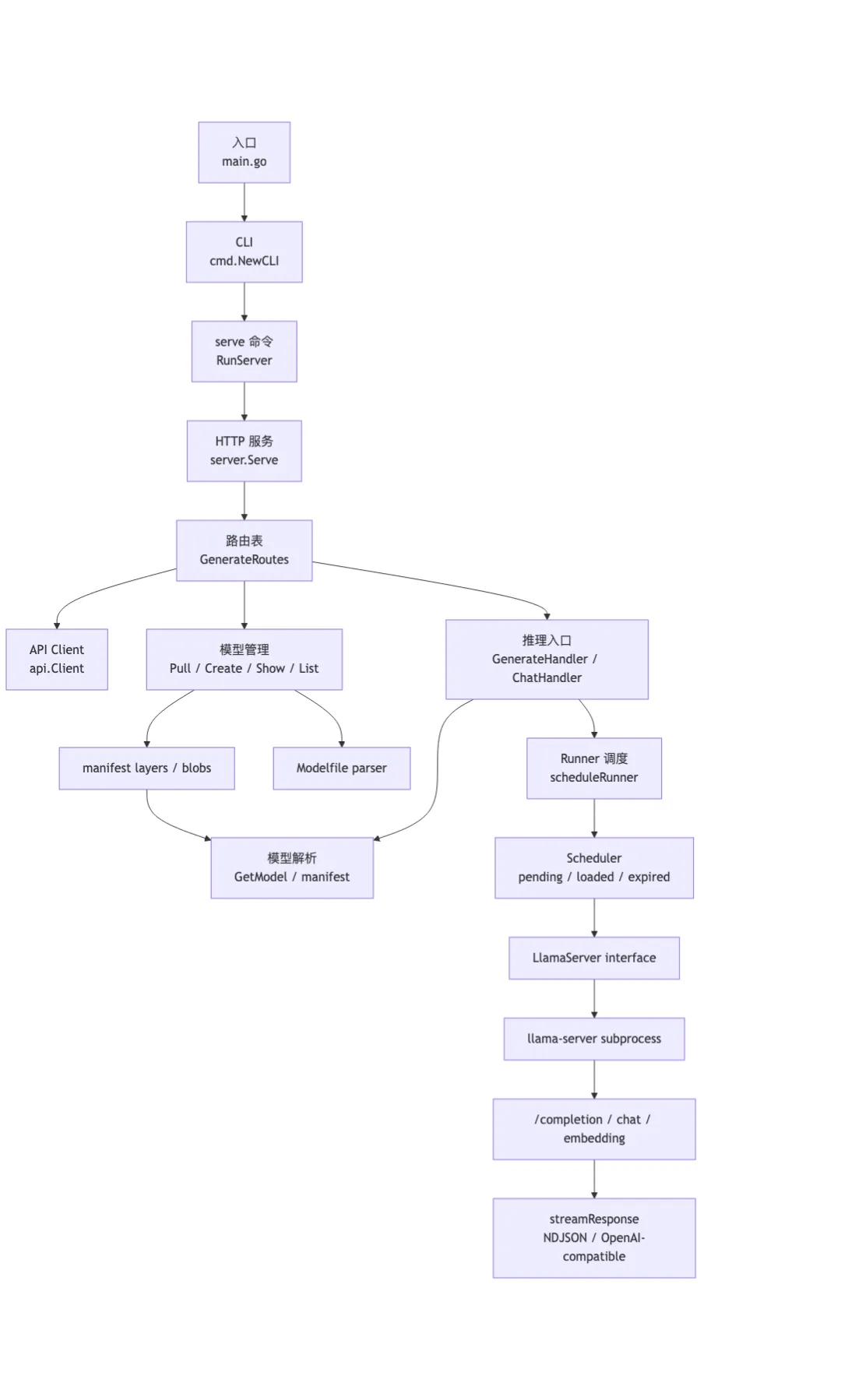
CLI 入口很薄,但它连接了长期进程
Ollama 的 main.go 很短,核心就是执行 cmd.NewCLI().ExecuteContext()。真正的命令注册在 cmd/cmd.go。
这里能看到用户熟悉的 run、serve、pull、create、ps,也能看到隐藏命令,比如 runner 和 gpu-discover。这说明 Ollama 的命令行并不只是一个交互壳,它同时承担了服务启动、模型管理、运行时辅助进程等入口。
serve 最终会进入 RunServer():它初始化本机 keypair,监听 OLLAMA_HOST 对应地址,然后调用 server.Serve(ln)。这一步把 CLI 世界切换到一个长期运行的本地 server。
更有意思的是 ollama run。如果本地 server 没启动,它会尝试后台启动 ollama serve,再轮询 heartbeat。也就是说,用户以为自己只是在跑一个命令,实际已经进入了“CLI 负责用户入口,本地 daemon 负责运行时”的结构。
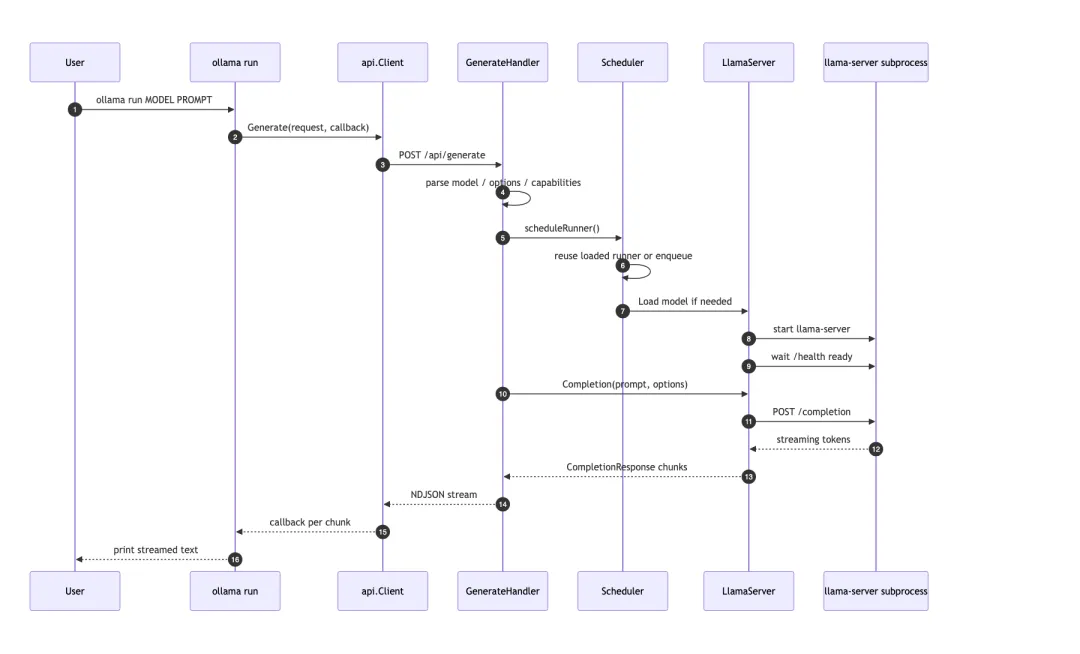
/api/generate 是推理主入口
ollama run MODEL PROMPT 后面会构造 api.GenerateRequest,再通过 api.ClientFromEnvironment() 发到本地 server。
API client 的流式处理也值得注意:它设置 Accept: application/x-ndjson,用 bufio.Scanner 逐行读取响应 body。每一行先检查是否是 error,再解析成对应 response 结构并交给回调函数。用户在终端看到的连续文本,本质上是本地 HTTP response 的逐行处理结果。
server 侧的核心入口是 GenerateHandler()。它不是简单把 prompt 原样转发出去,而是做了一整段运行时准备:
- • bind JSON 到
api.GenerateRequest。 - • 解析和校验 model ref。
- • 查找本地模型。
- • 处理空 prompt 加
keep_alive=0的 unload 请求。 - • 校验 raw、template、system、context 等组合。
- • 判断 completion、insert、thinking 等 capability。
- • 调用
scheduleRunner()拿到可用 runner。 - • 构造最终 prompt。
- • 调用 runner 的
Completion()。 - • 按
stream参数输出 NDJSON 或聚合 JSON。
所以 /api/generate 的重点不只是“有个 HTTP 路由”。它是把用户请求变成一次可调度、可复用、可流式返回的本地推理任务。
Scheduler 才是运行时核心
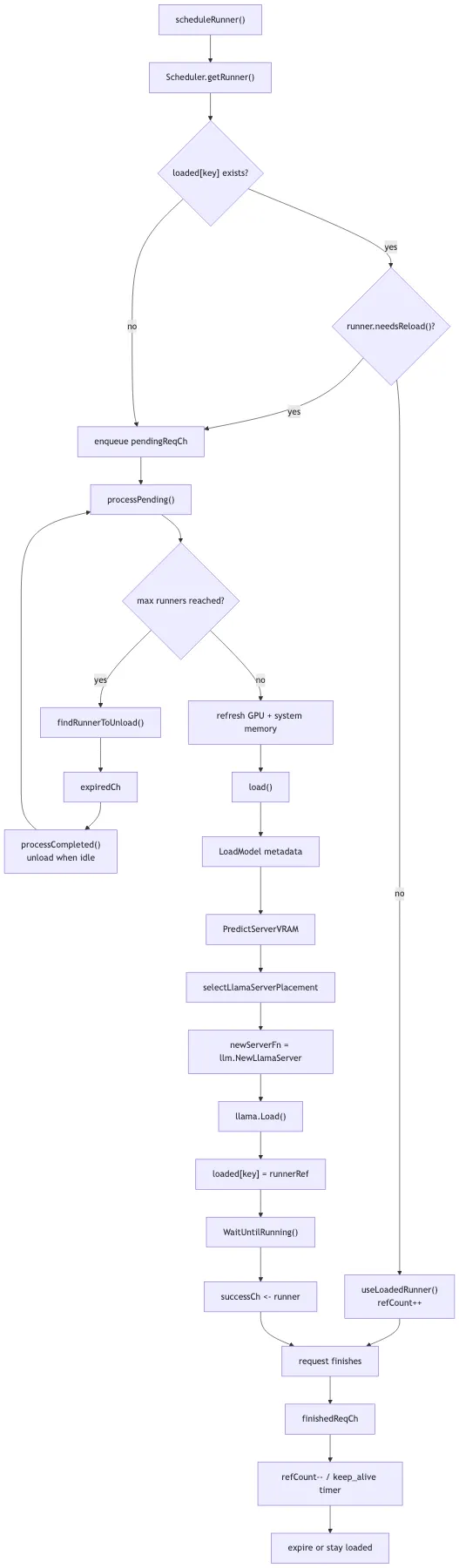
Ollama 源码里最值得细看的对象,是 server/sched.go 里的 Scheduler。
它维护的不是一个简单队列,而是一组运行时状态:pendingReqCh、finishedReqCh、expiredCh、unloadedCh、activeLoading,以及 loaded map[string]*runnerRef。
当 GenerateHandler() 调 scheduleRunner() 时,真正发生的是:
- • 如果目标模型已经加载,且 options、adapter、projector、context shift 等条件不要求 reload,就直接复用。
- • 如果不能复用,就把请求放进 pending 队列。
- • 如果加载数量达到上限,就选择已有 runner 卸载。
- • 加载前刷新 GPU 和系统内存信息。
- • 根据模型信息、context、并发数等估算资源。
- • 决定是否能放进现有 GPU/内存,再启动新的 runner。
这里的 runnerRef 很关键。它保存 refCount、llama、pid、loading、gpus、expireTimer、model、modelKey 和 options。也就是说,Ollama 对模型运行态的管理,不是“来一个请求起一个进程”,而是维护一批可复用、会过期、能卸载的 runner。
keep_alive 也在这里变成真实行为。请求结束后,processCompleted() 会减少引用计数;如果 keep_alive <= 0,runner 会尽快过期;如果大于 0,就设置或重置 timer。过期后如果没有引用,就执行 unload,并等待显存恢复。
这也是 Ollama 作为本地模型 runtime 的核心价值:它不只是帮你发一次推理请求,还要在本机资源有限的情况下决定模型什么时候加载、什么时候复用、什么时候让位。
推理边界在 llama-server 子进程
继续往下看,会发现 Ollama 没有把推理实现直接塞进 Gin handler。
它在 llm/server.go 里定义了 LlamaServer interface,包含 Load、Ping、WaitUntilRunning、Completion、Chat、Embedding、Tokenize、Detokenize、Close、MemorySize、VRAMByGPU、ContextLength 等方法。
真正启动推理后端的是 llm/llama_server.go。startLlamaServer() 会找到 llama-server binary,分配 localhost 随机端口,构造 --model、--port、--host、--no-webui、--offline、-c、-np 等参数,再加上 LoRA、mmap、KV cache、flash attention、batch、GPU offload 等配置,最后用 exec.Command() 启动子进程。
子进程起来后,Ollama 会通过 /health 轮询等待 ready。真正执行 completion 时,Go 层会检查 runner 健康状态,处理 prompt truncation,构造 llamaServerCompletionRequest,再 POST 到本地 http://127.0.0.1:<port>/completion,然后解析流式响应。
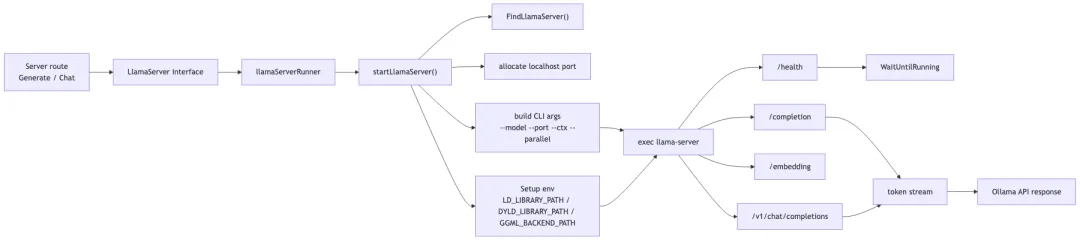
这一层边界很重要。Ollama 的 Go server 更像本地模型运行时的控制面:它负责 API、模型管理、调度、缓存、兼容层和子进程生命周期;真正的底层推理大量发生在 llama-server 侧。
如果把这点看错,就容易把 Ollama 讲成“Go 实现的大模型推理框架”。源码实际呈现的是一套把用户请求、模型文件、本机资源和推理后端组织起来的 runtime。
Modelfile 不是一段配置文本
Ollama 还有一层容易被使用者忽略:模型不是只有一个 GGUF 文件。它还有 Modelfile、manifest、layers、blobs 这一套模型包结构。
parser/parser.go 里的 ParseFile() 会用状态机解析 Modelfile,把 FROM 转成内部的 model command,把 PARAMETER 转成具体参数名,并校验 MESSAGE 的 role。
随后 Modelfile.CreateRequest() 会把 Modelfile 转成 API request,覆盖 base model、adapter、template、system、license、renderer、parser、requires、message、parameter 等信息。server/create.go 里的 CreateHandler() 再把这些请求转成本地 manifest 和 layer。
这解释了为什么 Ollama 可以让用户用简洁的 Modelfile 定义模型行为,同时在运行时仍然能追踪 layer、blob、template、参数和 adapter。它把“模型文件”提升成了一个可创建、可复用、可分层管理的本地模型包。

这套设计最值得学什么
Ollama 源码的重点,不在于某个 handler 写得多精巧,而在它把本地模型运行拆成了几个清楚的边界。
第一,用户入口和长期进程分开。CLI 负责命令体验,本地 server 负责运行时状态。
第二,API handler 和模型调度分开。GenerateHandler() 处理请求语义,Scheduler 决定 runner 复用、加载、排队、过期和卸载。
第三,控制面和推理后端分开。Go 层管理 LlamaServer interface 和子进程生命周期,底层 completion 通过本地 llama-server 的 HTTP 接口完成。
第四,模型定义和模型存储分开。Modelfile 给用户一个可读入口,manifest/layers/blobs 给运行时一个可管理结构。
这就是 Ollama 对做本地 AI 工具、模型网关、桌面 AI 应用和私有推理平台最有参考价值的地方:它把“跑一次模型”整理成了一个完整的本地 runtime 问题,包括入口、协议、调度、资源、子进程和模型包管理。读懂这条链路,比只记住几个 API endpoint 更有用。
