 夜雨聆风
夜雨聆风从2022年底ChatGPT横空出世到2025年大模型争奇斗艳,AI产业的爆发让GPU成为算力架构体系的核心,曾经久居处理器王座的CPU一度沦为辅助角色。但从2025年底以来,强化学习(RL)、智能体(Agent)推理、检索增强生成(RAG)等场景的普及,彻底扭转了这一格局。CPU 不再是 “配角”,而是AI系统的调度中枢、执行引擎与记忆载体,AI算力体系需求从 “1颗CPU带8颗 GPU” 激增到 “1:4 甚至 1:1”,驱动x86与ARM阵营开启新一轮技术迭代。无论是Intel股价一年内涨幅接近500%,还是Arm打破经典商业模式亲自设计处理器,都成为这一波AI时代CPU王者归来大戏最好的注脚。
CPU的价值回来了
随着应用不断演进,CPU的价值重新回到AI算力系统的核心位置。AI应用的复杂度不断提升,带动算力系统从 “GPU 主导的训练集群” 演进为 “CPU-GPU 异构协同的复杂系统”,CPU 的作用已从简单数据搬运,升级为全链路管控、高密度执行、大容量存储三大核心角色,覆盖训练、推理、强化学习全场景。
在 AI 训练集群中,CPU 作为头节点(Head Node),承担GPU全生命周期管理,直接决定GPU利用率。在任务调度与负载均衡方面,CPU的价值体现在分配模型分片、数据批次,避免GPU空闲或过载等方面,成为真正的算力中枢。随着数据读取速度成为影响AI系统性能的关键因素,CPU在内存与 I/O 管理方面的价值不断提升,CPU通过控制DDR/HBM带宽和CXL/NVLink路由,可以有效解决GPU显存瓶颈。针对数据预处理与供给,CPU用以完成图像和视频编解码、文本清洗、格式转换,为GPU和大模型训练提供规整输入。此外,CPU可以通过实时检测GPU故障和网络中断,保障集群稳定性。
尤其是2025 年后,强化学习(RL)成为大模型优化核心,而 RL 环境的模拟、交互、验证高度依赖 CPU,特别是环境模拟中的代码编译、数学计算、物理仿真(如机器人控制、游戏场景),以及借助CPU并行执行百万级Agent动作,实时反馈奖励值,同时通过校验合成数据精度,剔除无效样本,保障训练质量。微软 Fairwater 数据中心的执行效率显示:48MW CPU 集群支撑 295MW GPU 集群,CPU用于RL的算力占比达60%,成为训练瓶颈。
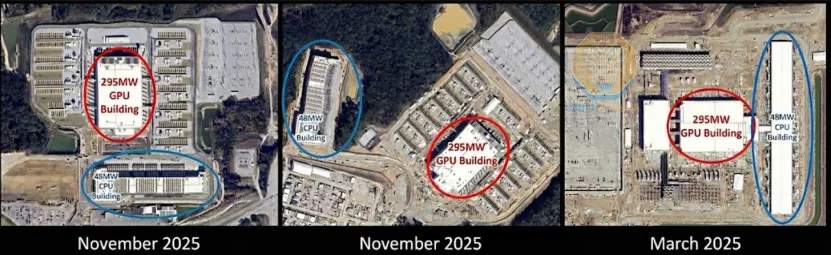
图1 微软 “Fairwater” GPU 与 CPU 数据中心大楼。来源:Google Earth
大模型推理(尤其是 RAG、Agent)场景中,CPU承担了70%以上的计算任务,包括RAG 检索中的向量数据库查询、API 调用、网页抓取、数据格式化,在Agent任务拆解中CPU用来执行复杂指令拆分为子任务,调度工具(数据库、代码解释器)。针对海量的轻量级推理任务,通过将中小模型、低延迟场景直接在 CPU 运行,有效减少GPU的负载以及能源消耗。针对上下文存储应用,CPU可以承载 KV Cache、对话历史,缓解 GPU 显存压力。此时CPU是推理性能的核心瓶颈,端到端延迟中CPU处理占比达 50%—90%。
CPU价值的提升,直接带动其与GPU的用量对比变化。SemiAnalysis的分析显示,针对如今大模型训练的算力需求,1 颗CPU理想配比2—4颗GPU,而对推理应用来说,1颗 CPU理想对应1—2颗GPU,CPU性能不足将会导致GPU利用率低于 50%。
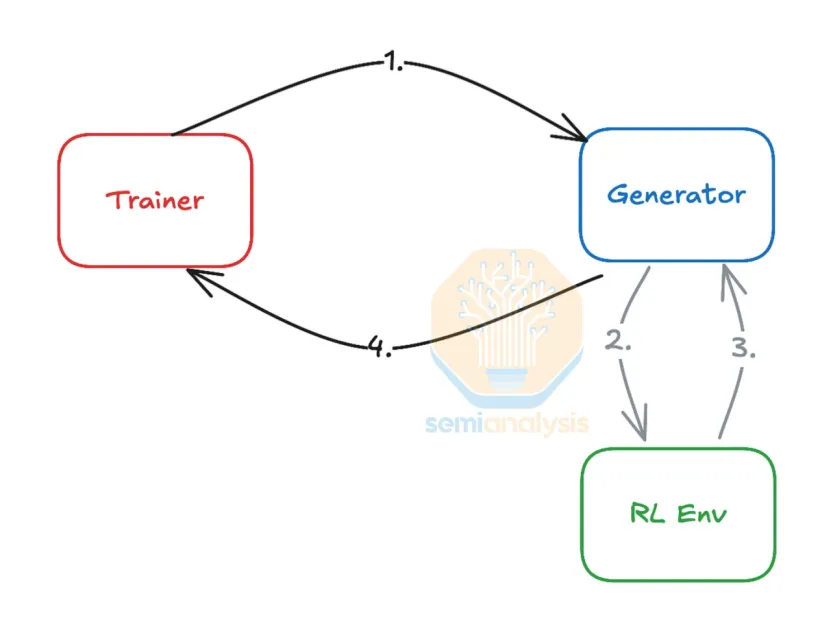
图2 强化学习训练循环,CPU在强化学习环境的作用(绿色标识)。来源:SemiAnalysis
机会留给有准备的CPU
AI算力架构的市场虽大,但不是所有的CPU都拥有入场的机会,这也是Arm 设计AGI CPU的初衷,同时也是英伟达设计Vera CPU的战略切入点。因为AI 场景需求的多元化,彻底颠覆了传统CPU的设计逻辑,从 “单核性能优先” 转向多核扩展、内存优化、异构互联、指令集增强四大方向。
1. 微架构:高单核性能 + 高核密度 + 无 SMT 取舍
单核性能拉满:Agent、RAG 等分支密集型任务,依赖高 IPC(每周期指令数)与低延迟,单核性能提升直接降低端到端延迟;
高密度能效核(E-core):RL、沙箱执行等并行任务,需要大量低功耗核心,如 Intel Sierra Forest、AMD Bergamo;
SMT 取舍:为规避 Spectre/Meltdown 风险,Intel Diamond Rapids 取消 SMT,核心数 = 线程数,提升安全性但降低多线程吞吐量。
2. 内存系统:超大缓存 + 高带宽 + 大容量
三级缓存扩容:L3 缓存从几十 MB 提升至几百 MB(如 AMD Venice 128MB/CCD、Intel Emerald Rapids 320MB),降低内存访问延迟;
高带宽内存支持:DDR5-8800、MRDIMM(1.64TB/s)、HBM 集成,满足 KV Cache、大模型参数存储需求;
内存一致性优化:Mesh/NoC 架构、NUMA 感知,解决多核心、多芯片间内存访问冲突。
3. 互联架构:Mesh 为主、Chiplet 化、异构高速互联
片上互联(NoC):从 Ring 总线升级为2D Mesh(Intel、AMD),支持数百核心低延迟通信,带宽达 TB/s 级;
Chiplet(小芯片):计算 / IO / 内存分离,先进制程(3nm/2nm)做计算芯粒,成熟制程做 IO 芯粒,平衡性能与成本;
异构互联:NVLink-C2C(NVIDIA)、EMIB(Intel)、Infinity Fabric(AMD),CPU-GPU 带宽达 900GB/s—1.8TB/s,支持内存共享。
4. 指令集:AI 加速 + 宽向量 + 专用指令
AVX512 增强:AVX512_FP16、AVX_VVNI_INT8,加速矩阵运算与推理;
专用 AI 指令:AMD AVX512_BMM(二进制矩阵乘法)、Intel AMX(高级矩阵扩展),提升 AI 任务能效;
ARM SVE2:可扩展向量,适配不同 AI 模型维度。
5. 虚拟化与安全:硬件隔离 + 低开销
硬件虚拟化增强:支持微虚拟机(MicroVM),快速启动、隔离沙箱环境,适配 Agent 并发执行;
安全加固:SMT 可选关闭、内存加密、侧信道防护,规避 AI 场景数据泄露风险。
从 1:8 到 1:1 的底层逻辑
从英伟达黄仁勋,到AMD苏姿丰,以及英特尔陈立武和Arm哈斯,处理器巨头的掌舵人们纷纷公开支持CPU在当下AI基础设施硬件体系中需求量将大幅提升的预测。根据SemiAnalysis的模型预测,CPU和GPU配比从1:8甚至可能演进到1:1,这其中任务处理需求变化以及成本和能效比的提升是最关键技术推动因素。
2025 年底,全球AI日调用量达万亿次,Agent、RAG、企业级推理成为主力,随之而来的是RAG应用企业知识库、智能客服、金融分析等需求的激增,每次调用需数据库查询、API 调用、文本生成,这部分算力开销中CPU占比高达70%。另一方面,Agent爆发后推升代码助手、数据分析师、自动化办公等应用需求暴涨,单Agent需拆解10+子任务,百万级Agent 并发需百万级 CPU 核心。另一方面,边缘推理负载不断下沉,工业质检、自动驾驶、智能家居,中小模型直接在CPU运行能够降低成本与功耗开销。
AI应用任务需求的变化,带来的是算力需求的反转,AI 推理与训练的任务特性完全相反,GPU优势场景收缩,CPU主场场景扩张。AI模型训练,重点集中在密集矩阵乘法、并行计算,算力分配方面以GPU为绝对主导,CPU仅作为辅助。而推理 / Agent应用中重点强调分支判断、逻辑控制、系统调用和沙箱执行,这些任务的执行以CPU为主导,GPU仅做生成。而到了RL环境下,代码编译、仿真交互、数据验证都属于纯CPU任务,GPU无法替代。
此外,AI推理应用更面向终端用户,因此对成本的诉求更为苛刻。如今高端AI算力GPU价格是高端CPU的3-5倍,SemiAnalysis认为,推理场景CPU替代GPU可降低约50%的成本。电力成本方面CPU也有明显优势,CPU的功耗约150—300W,而GPU功耗高达500—800W,大规模推理CPU更易部署。在负载利用率方面,推理应用中CPU可90%以上的满负载运行,GPU推理利用率仅30%—50%,CPU能效明显更高。
根据SemiAnalysis的统计模型分析,AI算力应用架构中的配比变化数据如下。
传统训练:1 颗 CPU 带 8—12 颗 GPU,CPU 核心数:GPU 核心数 = 1:8;
2025 推理:1 颗 CPU 带 4 颗 GPU,配比 1:4;
2026 Agent:1 颗 CPU 带 1 颗 GPU,配比 1:1;
RL 集群:CPU 算力:GPU 算力 = 6:1,CPU 数量反超。
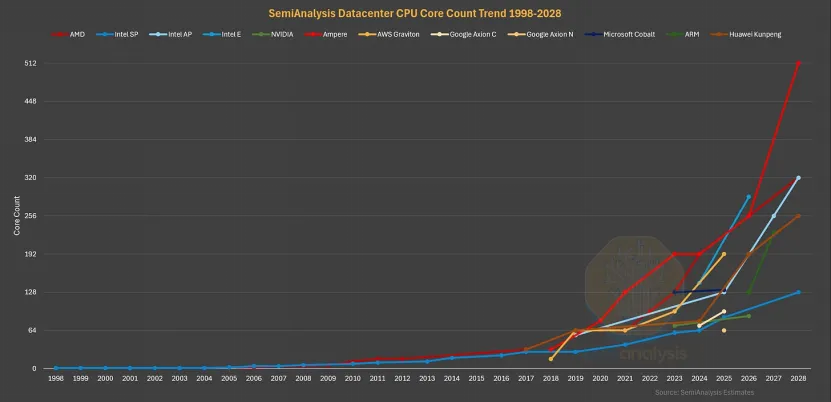
图 数据中心 CPU 内核数量发展趋势。来源:SemiAnalysis
2026年主流CPU产品盘点
1. AMD:Zen6 架构 + Chiplet,AI 全场景领跑
核心产品:Venice(2026 下半年)
架构:Zen6c(高密度)/Zen6(高性能),TSMC 2nm,Chiplet 设计(8 个 CCD+2 个 IO 芯粒);
规格:最高 256 核(Zen6c)/96 核(Zen6),16 通道 DDR5/MRDIMM(1.64TB/s),PCIe 6.0;
AI 特性:AVX512_BMM、增强 AMX,CCD 内 Mesh 互联,芯粒间高速链路;
优点:
1. 核心数领先,Zen6c 密度适配 RL / 推理;
2. 内存带宽 2.67 倍于上代,适配大 KV Cache;
3. Chiplet 成熟,成本低、良率高;
4. 单核性能强,Agent 延迟低。
缺点:
1. IO 芯粒拆分,跨芯粒延迟略高;
2. 高端型号价格高,中小企业适配难。
2. Intel:Xeon 6+,能效优先,追赶AI市场
核心产品:Diamond Rapids、Clearwater Forest
Diamond Rapids(2026 上半年):
架构:P 核(无 SMT),Intel 18A,4 个 CBB+2 个 IMH 芯粒;
规格:最高 192 核 / 192 线程,16 通道 DDR5,PCIe 6.0/CXL 3;
优点:IO 带宽高,头节点适配性强;
缺点:取消 SMT,多线程性能弱于 AMD,能效差距大。
Clearwater Forest(2026 上半年):
架构:E 核,Intel 18A,Foveros Direct 堆叠(计算芯粒 + 基础芯粒);
规格:最高 288 核,低功耗,适配云原生 / RL;
优点:能效比高,高密度;
缺点:性能提升仅 17%(对比上代),延迟高,堆叠良率低。
3. NVIDIA:Vera,定向开发的GPU最佳搭档,头节点专用
核心产品:Vera(2026,Rubin 平台配套)
架构:自研 Olympus ARM(支持 SMT),TSMC 3nm,Chiplet(1 计算 + 4 内存 + 1IO 芯粒);
规格:88 核 / 176 线程,1.5TB SOCAMM 内存(1.2TB/s),NVLink-C2C 1.8TB/s;
AI 特性:SVE2,6x 128b 浮点端口,2MB L2 / 核;
优点:
1. CPU-GPU 带宽行业最高,内存共享;
2. 单核性能强,头节点延迟低;
3. 专为 Agent 设计,适配 Rubin GPU。
缺点:
1. 价格极高,仅适配 NVIDIA 生态;
2. 通用场景兼容性差。
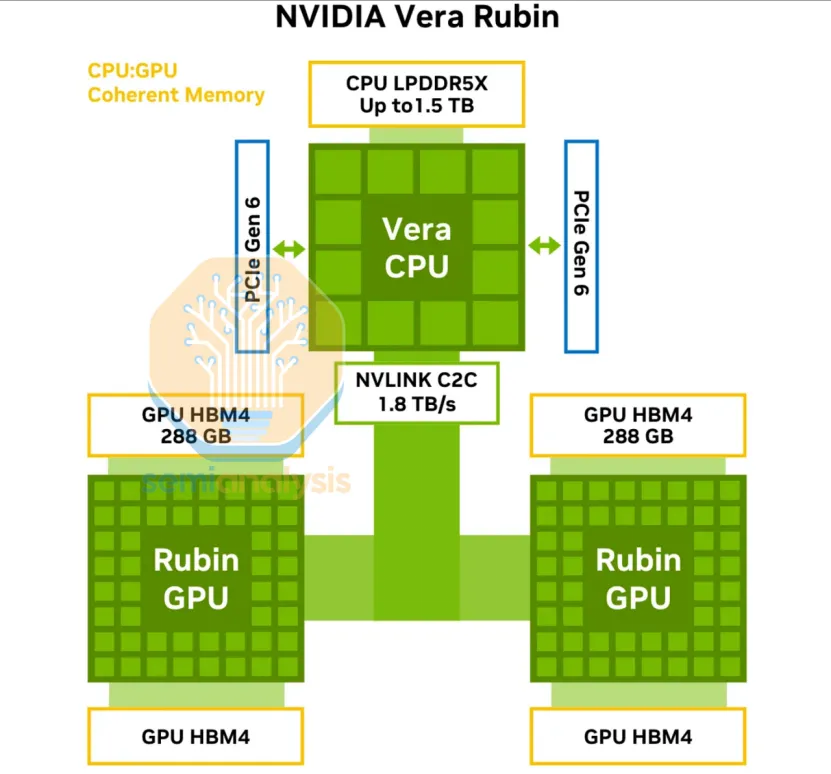
图 英伟达Vera Rubin NVLink 芯片间互联示意图。来源:英伟达
4. ARM 阵营:AWS Graviton5、Microsoft Cobalt 200、Arm Phoenix
AWS Graviton5(2026)
架构:Neoverse V3,TSMC 3nm,192 核,8x12 Mesh;
优点:性价比高,AWS 生态适配,推理能效强;
缺点:单核性能弱于 x86,复杂 Agent 适配差。
Microsoft Cobalt 200(2026)
架构:Neoverse V3,TSMC 3nm,132 核,双 Mesh;
优点:Azure 深度适配,虚拟化优化;
缺点:不做 AI 头节点,仅通用推理。
Arm Phoenix(2026,自研成品 CPU)
架构:Neoverse V3,TSMC 3nm,128 核,双 Mesh;
优点:Meta/OpenAI 定制,Agent 优化;
缺点:首次做成品,生态不成熟。
总结
AI 时代,CPU 已从 “GPU 附庸” 升级为异构协同核心,RL、Agent、RAG 三大场景驱动其需求爆发,配比从 1:8 逆转至 1:1。技术上,CPU 走向高核密度、大内存带宽、Chiplet 互联、AI 专用指令。对于工程师而言,AI 系统设计需重构 CPU-GPU 配比:训练场景 1:4—1:8,推理 / Agent 场景 1:1—2:1;选型优先高单核性能 + 大缓存 + 高互联带宽的 CPU,同时关注虚拟化与安全特性,以适配百万级 Agent 并发与复杂 AI 工作流。
关注视频号 EEPW芯视角
洞察芯世界 了解芯趋势

END

商务合作,投稿等需求,请发邮件 mayueyue@eepw.com.cn。
↓↓↓↓点击阅读原文,查看更多新闻
