 夜雨聆风
夜雨聆风
6月9日全球AI新闻
Langchain开源harness框架,
前沿大模型的融资逻辑正在从"私募轮"切换到"公开市场,
AI 开发者,正在成为供应链攻击的靶心
WWDC 2026 开幕,Siri 大改与 Apple Intelligence 更新
01
一、今日最重要的 5 个信号
信号 1:模型卷平之后,真正的胜负手在"壳"里
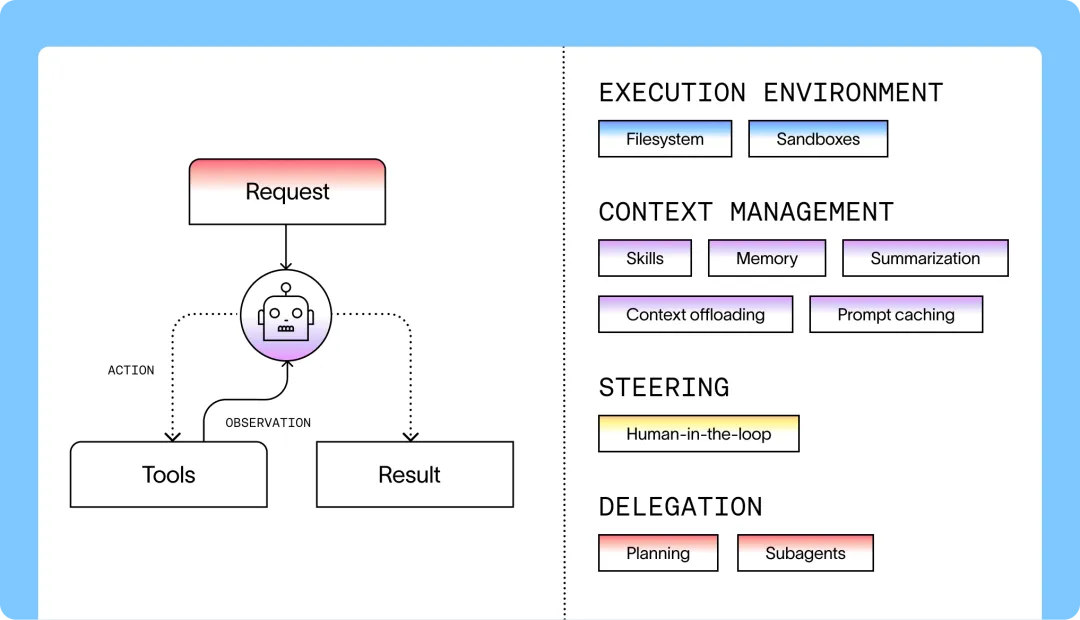
开发者 Elie Bakouch 把 Claude Code 与 Codex 的相似功能做成一条时间线,结论是两者高度趋同、平均只差 11 天。36氪 的 MiniMax 访谈里有一句更狠的引述:一份拆解 Claude Code 泄露代码的报告称,真正属于"模型决策"的代码只有 1.6%,剩下 98.4% 全是管权限、管上下文、兜错的 harness。这个数字我无法独立复现,应视为"业内流传的拆解结论"而非官方数据,但方向是可信的:当 Opus、GPT、Qwen、GLM、Kimi 在编码上都"不在话下",差距就转移到了脚手架层。LangChain 当天开源 Deep Agents 正是这个判断的注脚。

信号 2:两家最强 AI 公司前后脚冲 IPO,中国独角兽同步翻倍

OpenAI 在 Anthropic 递交 IPO 一周多之后,也秘密提交了 S-1。同一天,月之暗面(Kimi)被曝目标估值冲到 300 亿美元、约为去年 12 月的 6 倍。两件事拼在一起说明:前沿大模型的融资逻辑正在从"私募轮"切换到"公开市场"。这对从业者的现实影响是,未来这些公司的收入、毛利、算力开支会被迫透明化,行业终于要面对"单位经济模型"的拷问。需要提醒:IPO 是"秘密递交",估值是"洽谈中/目标值",都还不是成交事实,别当成既定结论。

信号 3:AI 开发者,正在成为供应链攻击的靶心

微软下架了数十个被注入窃密代码的 GitHub 开源项目,受影响的多是 Azure 及 AI 开发工具链(涉及 Claude Code、Gemini CLI、VS Code)。社区侧的预警则指向 npm 上 `@redhat-cloud-services` 的 32 个包、约 11.7 万周下载量,恶意代码会驻留在编辑器配置里、卸载包也清不掉。这两条很可能是同一波供应链投毒的不同侧面。信号意义在于:当"用 AI 写代码"成为标配,AI 编码工具的配置文件和凭证就成了高价值攻击面。 出于安全边界,本文不展开任何可操作的攻击细节,只强调:这是系统性风险,不是个案。

信号 4:"堆参数"退潮,能力提升开始靠工程而非靠更大
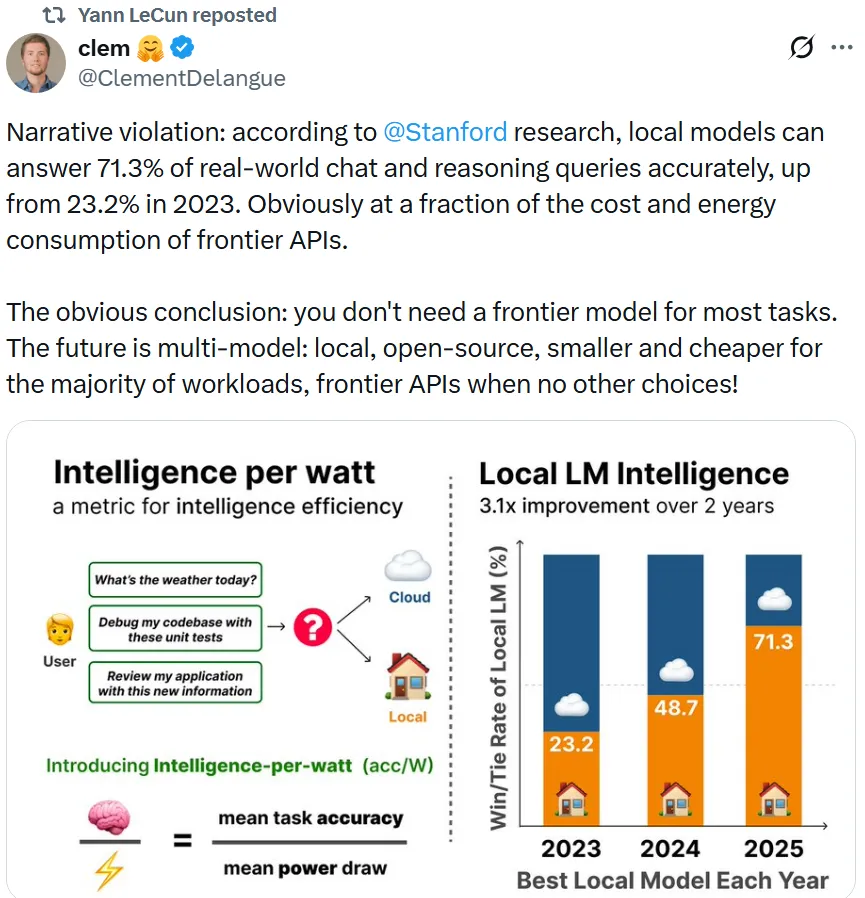
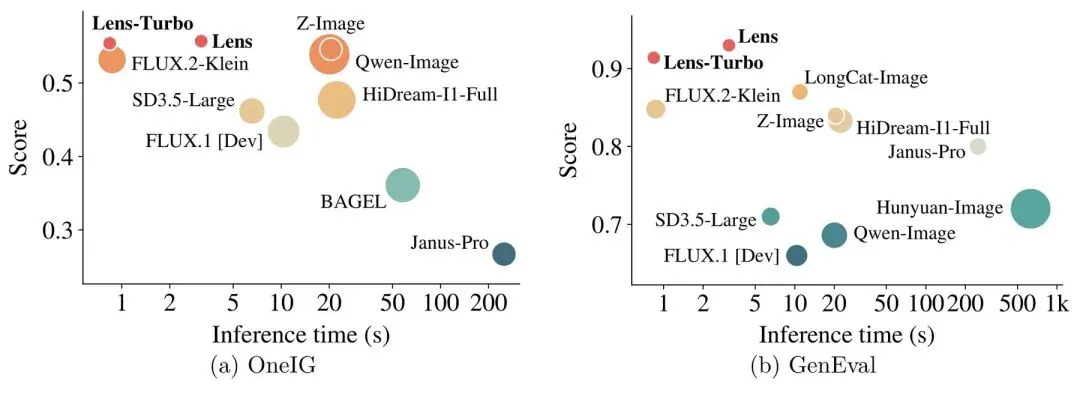
三条独立来源指向同一结论:更强不再等于更大。微软 Lens 用 3.8B 参数 + 8 亿条详细 caption,在基准上追平更大的模型;斯坦福研究称本地模型对真实查询的准确率从 2023 年的 23.2% 升到 71.3%;云知声用 U2 讲"生成式 AI 向生产力 AI"的成本叙事。这对创业者和产品团队是好消息:很多任务用更小、更便宜、可本地化的模型就够了,前沿 API 留给真正啃不动的活。需要注意的是,斯坦福那条来自 KOL 转述、Lens 是第一方论文结果,都还缺乏大规模第三方复现。

01
二、AI 企业官宣:哪些官方动态值得看?
1. OpenAI:秘密递交 IPO,紧随 Anthropic

一句话概括:OpenAI 在官方博客宣布已秘密提交 IPO 申请,比 Anthropic 晚了一周多。
核心内容:
OpenAI 周一发文确认已向 SEC 秘密递交 S-1;
时点紧随 Anthropic(6 月 1 日递交)之后,把两家的竞赛摆到了公开市场;
WIRED、The Verge 同步证实,公司近期估值被提及约 8520 亿美元区间。
为什么重要:前沿大模型公司集中冲 IPO,意味着行业要从"故事估值"转向"财报检验",算力开支、毛利、获客成本都将被迫透明。
我的判断:这对二级市场投资者和从业者是分水岭事件,但要分清"秘密递交"≠"已上市"。真正值得追踪的是后续公开的招股书数字,而不是今天的传闻估值。

2. Apple:WWDC 2026 开幕,Siri 大改与 Apple Intelligence 更新

一句话概括:苹果 WWDC 2026 主打 Siri 重构、Apple Intelligence 升级与 iOS 27。
核心内容:
久拖未决的 Siri 重构终于落地,并传出与第三方模型(含 Gemini)整合、独立 App 化;
Apple Intelligence 在 Image Playground、系统级听写等场景更新;
苹果同时强调"更便宜的 AI"来吸引中小开发者。
为什么重要:苹果是把 AI 能力推到数十亿终端的关键变量,它选择"自研 + 接入第三方模型"的路线,对整个端侧 AI 生态影响巨大。
我的判断:苹果的 AI 叙事一向"稳健到保守",演示效果好不等于稳定可用——尤其在 250M 美元虚假广告和解的阴影下,今年的 demo 更需要用实际可用性来检验,别把发布会承诺当成已交付能力。而且根据资料查询,短时间不会在中国发布,且欧盟对其也有着限制。

3. Google:NotebookLM 升级到 Gemini 3.5,并接入 Antigravity

一句话概括:NotebookLM 迎来史上最大更新之一,切到 Gemini 3.5,并嵌入 Antigravity 与"云端电脑"。
核心内容:
升级到 Gemini 3.5,支持更多文件类型和更顺滑的网页来源整合;
借助 Antigravity,可以在云端"电脑"上对资料做更复杂的处理;
Sundar Pichai 转发团队说法,强调"可以把检索扩展到自有资料之外"。
为什么重要:NotebookLM 是 Google 少数没被砍掉、且真正有口碑的 GenAI 产品,它从"问答"走向"带工具的研究助手",是 RAG 产品形态升级的样本。
我的判断:这条与 Perplexity 的"chat → agent"研究互为印证——知识工作的入口正从"对话"变成"有计算环境的 agent"。但要注意,"云端电脑 + 自动扩展来源"也意味着更大的数据边界,企业用户要把权限和合规想清楚再上。

4. Moonshot / Kimi:估值目标冲向 300 亿美元

一句话概括:Kimi 母公司月之暗面洽谈新一轮约 20 亿美元融资,目标估值约 300 亿美元。
核心内容:
据报道目标估值 300 亿美元,约为去年 12 月 43 亿美元的 6 倍;
这将是其近 6 个月内第三轮融资,累计融资额居国内大模型创业公司之首;
36氪 称其赴港 IPO 节奏在提速。
为什么重要:中国头部大模型公司的融资与上市节奏,是观察国产模型商业化和资本环境的关键指标。
我的判断:避免民族主义口号,看本质——估值 6 倍跳涨的背后是 Agent/编码赛道的资本共识,而非已兑现的收入。对国产模型,更该盯的是开源质量、单位成本和产品化落地,而不是估值数字本身。这条仍是"洽谈中",未成交。

01
三、科技名人 / 官方研究动态:他们今天说了什么?
1. Anthropic:为什么 AI 在编程上进步快于生物学?

一句话概括:Anthropic 发科学博客,讨论生物数据库为何"对 agent 不友好"。
核心内容:
提出一个形象比喻:生物数据库像"汽车出现前建的城市",对 agent 来说很难"开进去";
核心问题是为 agent 重建可用的基础设施,而非单纯堆模型能力;
与 Anthropic 近期"编码进展快于科研"的系列论述一脉相承。
为什么重要:它点出了一个被低估的瓶颈——Agent 的天花板往往不在模型,而在数据与工具的可用性,这正好呼应了信号 2 的 harness 论。
我的判断:这是观点 + 研究方向,不是产品发布。比喻很精彩,但"如何重建"仍是开放问题;把它当成对"垂直领域 Agent 难点"的提醒最合适。(注:该推文原文标题以官方博客为准。)

2. Perplexity × Harvard:从聊天到 Agent,知识工作被重写

一句话概括:与哈佛合作的 3 个月研究称,用自主 agent(Computer)的工人完成任务耗时减少 87%、成本降低 94%。
核心内容:
对比"仅用 Search",使用 Computer 的满意度更高、效率更高;
结论是"更多自主性"与"更高质量和满意度"正相关;
这是第一方研究,由 Perplexity 与哈佛联合发布。
为什么重要:它给"chat → agent"的迁移提供了量化证据,正面支撑了 OpenAI/Google 当天的产品方向。
我的判断:87%/94% 这种数字非常诱人,但这是厂商第一方研究,样本、任务定义、对照设置都需要独立验证,不能直接当作行业普遍结论。

3. Microsoft AI(Mustafa Suleyman):超级智能临近,但"不会抢你工作"

一句话概括:微软 AI 负责人称超级智能在临近,但主张其定位不是替代人类工作。
核心内容:长访谈,覆盖训练新模型的方法、与 OpenAI 的关系、自动化与就业等议题。
为什么重要:作为微软 AI 的掌舵者,他对"超级智能 vs 就业"的公开表态,会影响监管与企业采纳的舆论基调。
我的判断:这是高管观点,不是事实陈述。"超级智能临近"属于愿景宣示,缺乏可验证指标;真正值得记的是他刻意把"超级智能"与"抢工作"切割——这是产业在主动管理监管与公众情绪。

01
四、开源与开发者生态:哪些项目值得跟进?
1. LangChain Deep Agents:把"长任务 agent"做成开源脚手架
一句话概括:开源 harness,让 agent 能规划、用工具、委派子 agent、写文件、跑长任务,并在 LangSmith 提供托管版。
核心内容:强调长时程(long horizons)、子 agent 委派与文件写入;配套 Managed Deep Agents 落到 LangSmith。
为什么重要:这正是信号 2 的具体落地——大家不再只卷模型,而是卷"让模型稳定干长活"的脚手架。
我的判断:可用性看点在于"托管 + 开源"双形态;但开源 harness 的真实考验是长任务下的失败模式、权限与成本控制。license、维护活跃度、长任务稳定性需各自验证.

2. Hugging Face × Meta 等:OpenEnv 找到新家,开源模型也要"配套训练"
一句话概括:OpenEnv(RL 环境/harness)迁入由 HF、Meta-PyTorch、Nvidia、Prime Intellect、Unsloth 等组成的委员会共管。
核心内容:原帖点破一个关键洞察——"Claude 懂 Claude Code,GPT-5.5 懂 Codex,这不是偶然,是一起训出来的";开源模型也应享有同样的"模型 + harness 协同训练"。
为什么重要:它把"harness 竞争"上升为开源社区的基础设施问题,目标是让开源模型不再只发权重、还能配套环境。
我的判断:方向极有价值,多家共管也降低了单点风险;但跨厂商委员会的治理与持续投入是真正难点,能不能形成事实标准,要看后续半年的提交活跃度。

3. vLLM-Omni v0.22.0:全模态推理与机器人服务

一句话概括:vLLM-Omni 大版本升级,覆盖全模态世界模型、机器人实时服务、生产级 TTS 与更广的量化支持。
核心内容:
Day-0 支持 NVIDIA Cosmos 3 世界模型(文本/图像/音频/视频/动作);
机器人服务(DreamZero + OpenPI 实时 API)、生产级 TTS(Qwen3-TTS/Omni 等);
更广量化(FP8/INT8、MXFP4/MXFP8、W4A16);339 commits、124 贡献者。
为什么重要:推理框架是开源 AI 的"水电煤",全模态 + 机器人 + 量化的扩展,直接决定开源模型能否进生产。
我的判断:贡献者与 commit 数据反映社区活跃度不错;但"Day-0 支持"是工程兼容性宣告,真实吞吐、延迟与稳定性需要在自己的负载上压测,不能直接采信宣传口径。

4. 给 Claude Code 当老师:1000 名工程师、单价 280 美元

一句话概括:Anthropic 通过数据公司 Snorkel 的"Marlin"项目,用约 1000 名工程师反馈打磨 Claude Code。
核心内容:项目代号 Marlin,约 1000 名软件工程师参与;文中提到 Claude Code 负责人称自己两个多月没手写代码、单日由模型提交 22–27 个 PR。
为什么重要:它揭示了"编码 agent 变强"背后的隐性成本——高质量人类反馈数据,而不只是模型本身。
我的判断:这条是媒体转述,"280 美元一单"等细节需以原报道为准。但它点破一个被忽视的事实:AI 编码能力的护城河之一是数据标注与反馈工程,这恰恰是创业者难以低成本复制的部分。

01
五、Benchmark / Research:模型能力出现了什么变化?
1. OpenSkill:不依赖监督信号的自进化 Agent,刷新多项 SOTA

一句话概括:里海大学孙立超团队提出 OpenSkill,让 agent 在无目标任务监督信号下也能获得可执行、可迁移的 skills。
核心内容:
不依赖人工策划/LLM 生成/监督信号,解决真实部署中前提难满足的问题;
在多个基准上取得 SOTA 自动化表现,学到的 skill 可迁移到更弱模型;
资源已在 GitHub 公开。
为什么重要:自进化 + 可迁移 skill,直指"长期运行的 agent 如何持续学习"这一核心难题。
我的判断:贡献清晰(去掉监督信号依赖),但要看清边界——"刷新多项基准 SOTA"是论文自报结果,benchmark 的任务定义、是否存在污染、第三方复现都需独立核验。距离稳定的生产级长任务 agent 仍有距离,先当作有价值的研究线索。

2. Codex 撞脸 Claude Code:一条时间线看尽 coding agent 同质化

一句话概括:开发者把两家相似功能排成时间线,发现平均只差 11 天,几乎贴身同步。
核心内容:时间线跨 2025 年 2 月到 2026 年 6 月,从 /goal、子 agent 到 OpenAI 的"dreaming"记忆机制,橙(Claude Code)蓝(Codex)交替推进。
为什么重要:它用可视化方式证明了"模型卷平、产品趋同",把竞争焦点逼向更上层的工程与生态。
我的判断:这是开发者个人整理的观察,不是严谨评测,时间线的取舍有主观性。但作为"行业体感"的证据很有说服力,配合 OpenEnv、Deep Agents 一起看,主题非常一致。

3. MiniMax-M3:Intelligence Index 55,但这是上周发布的二次传播

一句话概括:MiniMax-M3 在 Artificial Analysis Intelligence Index 上拿到 55,权重发布后将是最强开源权重模型。
核心内容:M3 是 MiniMax 首个多模态 M 系列模型,加入图像/视频输入和 1M 上下文;55 分略高于 Kimi K2.6(54)与 MiMo-V2.5-Pro(54);官方称约 10 天内放权重。
为什么重要:开源权重模型的能力上沿仍在抬升,对模型选型有参考意义。
我的判断:必须诚实标注——这是一次"date trap"。经核查,MiniMax-M3 约在 6 月 1 日发布、Artificial Analysis 约 6 月 3 日给出分析,本窗口的推文属于二次传播,不是 6 月 8 日的新事件。同时 55 分来自第三方榜单、权重"尚未释放",所以"最强开源"目前只是预期、未成事实。把它作为背景信号即可,别当成当日突破。

4. Microsoft Lens:3.8B 参数靠"详细 caption"追平大模型

一句话概括:微软 Lens 用 3.8B 参数 + 8 亿条详细 caption,在基准上追平更大的文生图模型,训练成本大幅降低。
核心内容:核心是"数据质量(详细 caption)比纯规模更重要",由模型自动生成的高质量描述驱动训练效率。
为什么重要:为信号 5"堆参数退潮"提供了第一方实验证据,对中小团队训练成本是直接利好。
我的判断:贡献明确、机制可解释(caption 质量 → 训练效率)。但这是第一方论文结果,"追平大模型"的基准范围有限,缺乏独立复现;当作"数据工程优先"的有力旁证,而非定论。
完



OpenProduct
分享超级个体AI工具
和学习者一起成长
创作不易,一起“点赞”三连↓
