 夜雨聆风
夜雨聆风
https://github.com/bytedance/Bernini
https://bernini-ai.github.io/
https://huggingface.co/ByteDance/Bernini-R
https://arxiv.org/abs/2605.22344
哈喽,大家好,我是 01墨客。
不知道大家在尝试 AI 视频编辑的时候,有没有过这种“崩溃”的时刻:
你只是想给视频里的主角换件衣服,结果 AI 把背景也给换了;你想让主角做一个挥手的动作,结果主角的脸瞬间扭曲成了外星人。这种“一改就崩、主体变形、背景乱闪”的现状,让很多极具创意的视频二创想法,最终都变成了“废片”。[1][3]
但就在今天,字节跳动商业化技术团队扔出了一枚重磅炸弹:Bernini 统一视频生成与编辑框架正式开源!
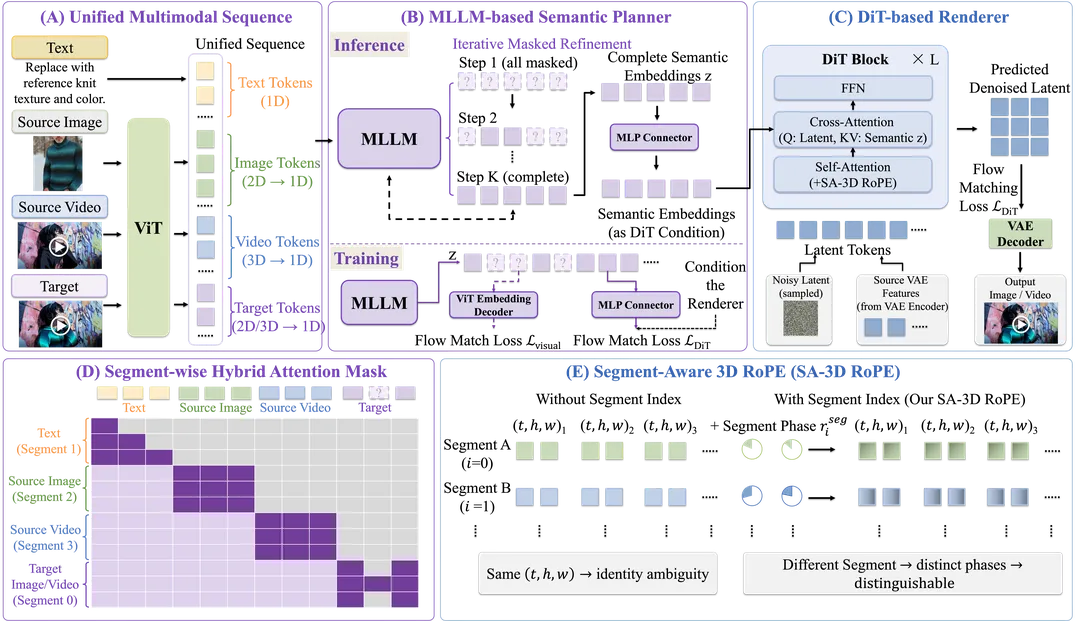
它最让我震撼的不是它的生成质量,而是它在“可控性”上的降维打击:它给视觉渲染模型配了一个“大模型军师”,坚持“先理解、再生成”,让视频编辑稳得不像话。[1][7]
一、问题到底在哪:为什么“盲目生成”是视频编辑的死穴?
传统的视频生成模型(如早期的 DiT 架构)大多是“视觉派”。
它们擅长根据提示词画出漂亮的像素,但往往缺乏深层的语义理解。当你给出一个复杂的编辑指令时,模型往往不知道哪些该动、哪些不该动。这在视频这种对连续性要求极高的媒介中,会产生三个致命伤:
• 主体不一致:改了衣服,脸变了;动了胳膊,腿没了。 • 背景漂移:编辑局部内容时,整个背景像是在地震一样晃动。 • 动作断裂:新生成的动作与原视频无法自然衔接,显得非常生硬。
今天大部分大模型解决的是“画得美不美”,而 Bernini 解决的是“改得准不准”。
这就是为什么它被称为视频编辑领域的“清流”。
二、Bernini 到底强在哪:它构建了一个“先理解、再生成”的协同体系
Bernini 最核心的突破,是它把视频生成/编辑工作流拆分成了语义规划与视觉渲染两个阶段。[1][4][11]
它巧妙地结合了多模态大语言模型(MLLM)的逻辑能力和扩散模型的画图能力。为了让大家看清这个“视频军师”的威力,我整理了一份技术规格表:
| 语义规划 | ||
| 视觉渲染 | ||
| 统一能力 | ||
| 实战表现 |
这种“分工明确”的设计,让 Bernini 在处理复杂视频二创任务时表现得异常稳健。它会先通过 MLLM 搞清楚你要改哪里、怎么改,然后再交给渲染器去执行。这种“谋定而后动”的策略,彻底解决了视频编辑中的一致性难题。[7][11]
官方称其视频编辑能力在内部自建平台的盲测中已达到领先闭源商业模型的第一梯队。
模型权重采用 Apache 2.0 协议在 HuggingFace 发布,推荐使用打包了 Wan2.2 基础组件的 Diffusers 格式,并建议在 Hopper 架构 GPU 上运行以获得最佳性能。
三、它为什么突然有存在感:因为它开启了“精准视频操控”的新纪元
这次字节跳动强调的几个点,其实非常具有行业风向标意义。
首先是极致的可控性。Bernini 不仅仅是生成一段视频,它能精准地响应你的文字指令,比如“把主角的红色外套换成蓝色西装”,或者“在背景的桌子上放一瓶可乐”。这种“指哪打哪”的能力,是视频 AI 进入专业工作流的前提。[15]
其次是商业化基因的注入。作为字节商业化团队的作品,Bernini 在设计之初就考虑到了广告创意、电商视频自动化生成等实战场景。它能将特定材质、指定主体甚至广告海报与视频内容完美融合,这对于短视频创作者和广告主来说,简直是“生产力核武器”。[3]
说人话就是:
它给了你一个“顶级剪辑师”,还顺便配了一个“高智商导演”。导演负责看懂剧本、规划镜头,剪辑师负责完美执行。
这种从“概率生成”向“逻辑操控”的转变,是视频 AI 赛道实现质变的关键。
四、Bernini 最值得看的,不是它的开源,而是这三项“硬核黑科技”
如果让我总结这波最值得关注的点,我会说不是它画得有多好,而是下面三件事。
第一,它实现了“语义与视觉的深度解耦”。
通过将规划和渲染分开,Bernini 避免了传统模型中“语义干扰视觉”的问题。这让它在处理复杂指令时,依然能保持画面的纯净和稳定。[1][11]
第二,它把“高阶视频编辑能力”带到了“开源社区”。
以前这种级别的视频编辑和参考生成,往往是闭源巨头的“压箱底”技术。Bernini 的开源,让每一个开发者都能在本地拥有一个“视频二创神器”。[12]
第三,它构建了一个“面向未来的二创生态”。
Bernini 发布首日就得到了 ComfyUI 等社区的支持。这意味着,你可以通过工作流的方式,将 Bernini 与其他 AI 工具组合,创造出前所未有的视频特效。[14]
五、但话说回来,视频 AI 现在也不是没有挑战
如果把它吹成“完美无缺”,那就有点过了。
虽然“先理解、再生成”的逻辑非常完美,但如何进一步提升 MLLM 对复杂动态场景的理解精度,依然需要海量视频数据的喂养。此外,视频生成对算力的要求依然是“吞噬者”级别,想要在普通家用电脑上实现极速编辑,仍需进一步的量化和优化。
这也是我对 Bernini 当前阶段的判断:它给了我们一个极具革命性的视频编辑框架,但要真正实现“电影级”的自由操控,依然需要整个开源社区去共同丰富它的语义库和渲染能力。
所以如果你问我,它是不是已经能完全替代专业剪辑师了?
我会说,它在重复性劳动和创意原型生成上已经展现出了惊人的效率,但在处理极具艺术感的镜头语言和细腻的情感表达上,人类导演的直觉依然是不可替代的。
它不是在卷视频时长。
它是在卷“谁能让 AI 真正听懂人类的创意,成为精准的视频操控工具”。
六、如果你准备在项目里接入 Bernini,有几个现实建议
第一,重点测试它的“语义规划”在复杂指令下的表现。
不要只给简单的指令。试着给它一些涉及多个主体、复杂动作变化的指令,看看 MLLM 规划器在逻辑拆解上的真实实力。
第二,充分利用 ComfyUI 的社区工作流。
既然已经有了 Day-0 支持,那就赶紧去下载对应的节点。在 ComfyUI 中,你可以更直观地观察语义蓝图的生成过程,并根据需要进行微调。[14]
第三,关注“参考生成”在商业场景的落地。
如果你是做电商或广告的,重点研究一下 Bernini 如何将产品素材与视频背景融合。这种高一致性的生成能力,可能是你提升转化率的关键。
七、最后怎么判断:Bernini 值不值得重视?
我的答案是:非常值得,因为它代表了视频 AI 的“下半场”——从“生成”转向“操控”。
今天很多 AI 视频产品,还停留在“随机抽卡”。但 Bernini 这波更像是在说:我不只想给你漂亮的画面,我想给你掌控感,让你能用 AI 真正完成那些严谨的视频创作工作。
这件事一旦跑通,会很可怕。
因为它改的不是某个模型、某个功能,而是“人类如何表达视觉创意”这件事本身。
当然,Bernini 现在还在快速演进中。它有亮点,也有挑战;有巨大的潜力,也还需要更多创作者的实操反馈。[1]
但话说回来。
如果你现在关注的不是“哪个 AI 生成的视频更长”,而是“哪个 AI 能真正听懂我的编辑指令、保持主体不变、还能让我精准操控”,那 Bernini 绝对是你不能错过的核心武器。
一句话总结:Bernini 最值得看的,不是它又开源了,而是它终于让“视频可控编辑”从一个玄学的概念变成了每一个创作者都能触达的技术实体。
你对字节跳动这款“视频军师”怎么看?你觉得 AI 拥有了语义规划能力后,会改变你的视频创作习惯吗?欢迎在评论区跟我聊聊。如果这篇文章对你有启发,别忘了点赞、在看、分享!🚀
参考内容
[1]: 字节 Bernini:统一的视频生成和编辑框架 - OSCHINA[2]: 字节开源 Bernini:视频生成与编辑模型 - X[3]: 先理解再动手!字节开源统一框架 Bernini - 搜狐[7]: 字节开源统一框架 Bernini:给 DiT 配个“大模型军师” - 量子位[12]: ByteDance/Bernini-R - Hugging Face
