 夜雨聆风
夜雨聆风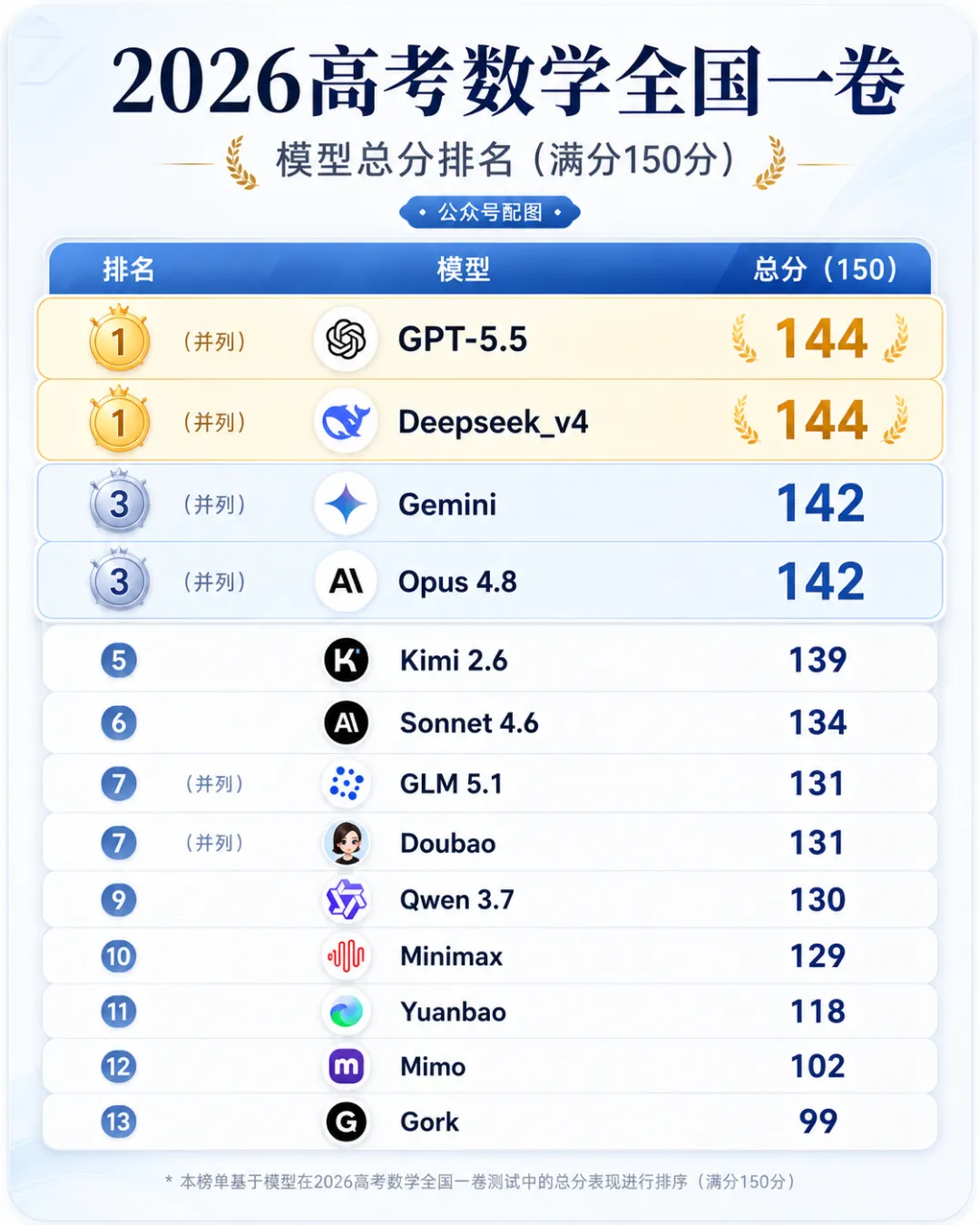
EDITORIAL ESSAY
026年高考数学全国一卷,13个顶级AI模型同场竞技。
GPT-5.5和Deepseek-v4并列第一,144分。满分150。Gemini和Opus 4.8紧随其后,142。最差的Grok只有99——第一名和最后一名差了45分,这差距,快赶上人和人之间的了。
看完这张表,多数人的第一反应是:AI太强了。数学这门人类智力的硬通货,顶级模型已经摸到了清北线。
但很少有人注意到一个细节:所有模型,包括那个144分的"考霸",都在多选题上翻了车。翻车的方式很统一——把"看起来也成立"的选项塞了进去。模型太聪明了,聪明到它会在边界条件上过度发挥,把"有可能对"的东西当成"一定对"。
这不是粗心,这是AI的底层逻辑缺陷。而这个缺陷,远比你想的更致命。

跑分是驾考,落地才是晚高峰的北京二环。
驾考考什么?侧方停车、坡道起步、直角转弯——标准动作,标准场地,标准评分。你把动作做对,就能拿证。
晚高峰的二环考什么?加塞的公交、逆光的路口、突然蹿出来的外卖小哥、暴雨里看不清的标线。没有人给你标准动作,你必须在0.3秒内判断:这个黑影是坑还是水?
AI的跑分就是驾考。干净的测试集、明确的评判标准、理想化的条件——模型在这些条件下表现完美,就像一个科目二满分的学员。但真实场景是晚高峰。数据有噪声、环境会变、条件从来不是干净的。那个在多选题上把"看起来也成立"的选项塞进去的144分模型,跟一个驾考满分但第一次上二环就追尾的新手,没有任何区别。
问题来了:如果跑分不等于落地,那大模型竞赛到底在争什么?
FIELD REPORT
5,000张图跑出99.8%
我有一个亲身经历,比任何理论都更能回答这个问题。
为了拿下一家光伏巨头的订单,我们团队在实验室里闭关了两个月。工业界的常态是,合格的良品要多少有多少,但代表缺陷的废品样本极其罕见——如果工厂天天能产出几万件废品,这厂早就倒闭了。客户最后在数据库里翻箱倒柜,也只给我们凑出了1000张原始缺陷图,包括隐裂、划伤、崩边这些。
1000张,喂不饱深度学习。我们用算法对这1000张珍贵的"种子图"做了高频旋转、裁剪和光照模拟,硬生生扩充出了一套5000张的训练集。
在实验室干净的GPU服务器上,这套方案跑出了近乎神迹的成绩:精确率99.8%。0.05毫米的微米级边缘崩角,秒级锁死,无一漏网。
99.8%。我们带着这份完美的跑分答卷,骄傲地把机器拉到了江苏某个光伏大厂的无尘车间。
然后,翻车了。

现场翻车:40度高温与"洗洁精"的逆袭
设备上线第一天,模型就彻底疯了。系统后台的红色警报响成一片,"过杀率"——也就是把好片当废品抓——直接飙到了42%。传送带后面的气动机械手像打摆子一样,疯狂地把一片片毫无问题的合格硅片拍进废品箱。
厂长指着我们的鼻子大骂:"你们这模型是不是有精神病?纯良品全给老子扔了,今天产线要是完不成出货,你们连人带机器给老子滚蛋!"
算法工程师当场就懵了,赶紧调出报错的图片。一看,冷汗顺着脊梁骨往下流。
模型在它自己的"逻辑"里,判定得极其严谨——那些硅片表面确实出现了大面积的"弯曲连续性阴影"。但在物理世界的车间现场,真实情况是这样的:
一、物理环境的"脏":水汽与洗洁精
硅片在进入视觉检测工位前,要经过一道酸洗和水洗。实验室给我们的那1000张样本,全都是烘干、冷却、擦拭得一尘不染的"标本"。但真实车间里,那天正好是七月份,工业空调坏了一台,局部温度飙到40度,湿度极大。硅片从水洗线出来还没完全烘干,表面带着一层极薄的水汽微膜。更绝的是,车间工人为了清洗设备上的顽固油污,私自往水箱里加了一点类似洗洁精的表面活性剂——水汽在硅片表面形成了一圈圈、若隐若现的彩色干涉条纹,物理上叫牛顿环。
二、"考霸模型"的降维打击
这层水汽和纹路,在肉眼和老质检员大妈眼里,根本不是事儿。大妈拿劳保手套一抹,或者眼睛一闭直接放行——因为她们知道这完全不影响电池片的导电性能。
但在我们那个99.8%的"考霸模型"眼里,这简直是惊天大罪。它太聪明了,特征提取能力太强了,敏锐地捕捉到了牛顿环带来的反射率微弱变化。模型的逻辑是:在我训练的那5000张完美考卷里,从来没有出现过这种彩色线条——这一定是未知的恶性表面划伤!
于是,42%的过杀率。
注意这个数字:99.8%精确率的模型,比一个90%精确率的"笨"模型更容易崩。因为90%的模型不够聪明,它抓不到那些微弱的边界特征,反而不会把好片误杀。而99.8%的模型太聪明了,它把"看起来也成立"的特征全塞了进去——跟高考多选题翻车,一模一样的逻辑。
跑分越高,可能越危险。
MECHANISM
模型越聪明,越容易把噪声当信号
我们那个99.8%的模型不是犯了错——在它的逻辑里,牛顿环确实是"从未见过的异常特征",判为废品是严谨推理的结果。问题出在更深处:模型越聪明,特征提取能力越强,它就越容易把真实场景里那些"不该被看见"的东西也抓出来。水汽、洗洁精、40度高温、坏掉的空调——这些在训练数据里从不存在的"脏",在聪明模型眼里全是信号。
这不是某个模型的bug,而是所有"聪明模型"的结构性风险。真实场景永远是脏的,而训练数据永远是干净的标本。你永远无法穷举真实场景里所有可能出问题的条件,就像你永远无法穷举晚高峰二环上所有可能发生的意外。
洗洁精打崩99.8%的模型,这是落地层的失效。但更深层的问题是:即使在跑分这个"驾考"里,"大力出奇迹"也快走到头了。

TECHNOLOGY SHIFT
技术逻辑变天:从"谁卡多谁赢"到"谁数据巧谁赢"
2025年底,OpenAI前首席科学家Ilya Sutskever公开说了一句话:"我们已经从扩展时代,重新回到研究时代。"翻译成大白话:靠堆参数、堆数据、堆算力来换取智能跃迁的时代,结束了。
不是他一个人这么看。Sam Altman含蓄地承认,光靠更多GPU已经换不来同比例的智能提升。黄仁勋的立场更折中——Scaling Law本身没失效,但传统的"堆规模"路径已经到了极限。
三重夹击之下,"大力出奇迹"越走越窄:
一、收益递减——模型参数翻一倍,性能提升越来越小。Chinchilla研究早就证明了这一点:模型规模和数据规模必须成比例扩展,否则就是浪费。
二、数据枯竭——维基百科、arXiv论文、GitHub代码,公开文本基本抓光。
三、同质化——各家模型喂的是同一批语料,长出来的回答套路越来越像。
但就在"大力出奇迹"撞墙的同时,有人证明了另一条路走得通。
2026年5月,一家叫Sapient Intelligence的公司发布了HRM-Text-1B。1B参数,1500美元训练成本,16块H100跑了不到两天——在数学推理测试中,打赢了参数量大2到7倍的传统模型。它的训练量只有同级别常规模型的数百分之一。
1B vs 7B
1B参数打赢7B · 1500美元干翻几百万美元
这不是靠更大的肌肉,而是靠更巧的招式。HRM-Text的核心思路是:在有限数据和有限算力下,通过架构设计提高每一次计算的产出——就像一个聪明学生不用刷一万套题,而是把一百套题吃透,照样考高分。
竞赛规则变了:从"谁卡多谁赢"变成"谁数据巧谁赢"。
但且慢——HRM-Text打赢7B,打赢的是跑分。回到我们的工厂故事:跑分99.8%的模型被洗洁精打崩了。技术逻辑变天只是第一层,更深的变天在产业那一层。
INDUSTRY SHIFT
产业逻辑变天:驻场从成本中心变护城河
MIT斯隆管理学院做过一项关于临床场景AI部署的研究,得出了一个让很多算法工程师心凉的数字:
每花1小时完善模型,还需要大约4小时,才能让它在真实场景中可靠运转。
不到20%的精力在模型本身,超过80%的精力在"脏活"——数据集成、模型验证、确保经济价值、监控漂移、治理。我们那个光伏厂的故事,就是这个1:4定律的完美注脚:两个月闭关做模型,上线第一天就被洗洁精打崩。真正让我们最终把过杀率从42%降下来的,不是调参数,而是重新对接水洗工序的流程、在检测工位加装烘干模块、跟车间工人确认清洗剂的添加规范——全是脏活。
95%
生成式AI试点项目,没有产生任何可衡量的业务成果
MIT的另一项研究更扎心:95%的生成式AI试点项目,没有产生任何可衡量的业务成果。100个试点,只有5个真正跑出了结果。成功和失败的差异从来不在于模型本身,而在于企业集成的"学习缺口"。
所以当你看到下面这条新闻,就不会觉得意外了——
2026年5月,OpenAI成立了一家部署公司,初始投资超过40亿美元。这笔钱如果用来买英伟达的H100算力卡,可以买到数万张。但OpenAI选择买下的,是一家人工只有150名的AI咨询公司Tomoro。这150个人有一个特殊身份:前沿部署工程师,FDE。
一周后,Anthropic也宣布联合黑石、高盛成立15亿美元的部署合资公司。
55亿美元
全球最头部的两家AI公司,押注同一件事
全球最头部的两家AI公司,几乎同时用真金白银押注了同一件事:光拼跑分不够了,得比谁能把AI嵌进客户的生产流程。
FDE这个岗位,跟传统的"驻场工程师"完全不是一回事。传统驻场是IT人力外包——拿着需求文档,把标准产品硬拧进客户环境,干完走人。FDE是"嵌进去"的——变成客户组织的一部分,从头搭建AI系统,根据真实业务不断微调,再把客户需求变成可复用的能力反哺平台。吴恩达专门发了一条长推文聊这个岗位,说它现在是AI行业最炙手可热的角色。LinkedIn的数据显示,2023到2025年,FDE岗位数量增长了42倍,是AI所有岗位中增速最快的。
中信证券的研报用一句话做了总结:"大模型竞争正由模型性能的单维比拼,延伸至企业级生产力的综合能力较量。"
翻译成大白话:驻场不再是成本中心,而是护城河。
谁先理顺了客户现场的数据和流程,谁就先拿到了喂养下一版模型的独家养分。这就是为什么OpenAI宁愿花40亿美元买150个人,也不买卡——因为卡谁都能买,但嵌在客户流程里的数据和认知,买不到。

CLOSING
回到开头那张高考跑分表。
GPT-5.5和Deepseek-v4的144分,值得尊敬。那是AI在"驾考"上交出的满分答卷。但驾考满分只是起点,不是终点。
变天之后,竞赛的胜负手不再是"谁的模型跑分更高",而是"谁先从驾考满分走向二环不翻车"。技术层面,1B参数打赢7B说明暴力扩展不再是唯一路径,架构创新和数据效率正在改写规则。产业层面,OpenAI和Anthropic用55亿美元押注部署能力,说明最聪明的人已经看清楚了——
跑分看上限,脏活看下限,决定你能不能用的是下限。
我们那个被洗洁精打崩的99.8%模型,后来怎么样了?我们花了比做模型多四倍的时间,把水洗工序、烘干参数、车间温湿度全链路摸了一遍,在检测工位前加装了独立的烘干模块,跟车间工人重新确认了清洗规范,又花了数周在产线上反复调试验证——最终过杀率从42%降到了2%以下。
花在脏活上的时间,是做模型的四倍。但正是这四倍的脏活,才是模型真正"能用"的原因。
大模型竞赛的逻辑,真的变天了。赢的不是跑分最高的,而是最能在脏乱差里活下来的。
