 夜雨聆风
夜雨聆风前言
你有没有想过:
AI 编程助手能不能"记住"你的习惯?如何让你的 AI 编程助手越用越聪明呢?
用了几个月的 Claude Code 或 Cursor,你可能注意到一个尴尬的现象:
•每次开新项目,AI 还是会存在都在犯同样的错误
•你反复纠正过的代码风格,下次对话它又忘了
•那些你花 20 分钟教会它的项目规范,关掉终端就消失
•明明你已经和它协作了上百次,它却像第一天来上班的新人
根本原因很简单:AI 没有"记忆沉淀"机制。
每次对话结束,你的纠正、你的偏好、你的成功经验——全部随着聊天记录沉入 ~/.claude 目录,再也没人翻看。
但如果有个工具,能让 AI 在"睡觉"的时候回顾你所有的历史会话,从中提炼出你的编码习惯、项目规范和成功模式,然后把验证过的经验写进长期记忆呢?
SkillOpt-Sleep 就是干这件事的。
一、SkillOpt-Sleep 是什么
SkillOpt-Sleep 是微软开源项目 SkillOpt 的"部署时伴侣"工具。它借鉴了三个核心理念:
| SkillOpt | |
| Claude Dreams | |
| Agent Sleep |
一句话概括:
给你的本地编程 Agent 一个"夜间睡眠周期"——它在离线状态下回顾你过去的会话、重放常见任务,把经过验证的经验沉淀为长期记忆和技能。Agent 越用越强。
一个"夜晚"做了什么
采集 ~/.claude 历史会话 → 挖掘重复任务模式 → 离线重放→ 反思 + 有界编辑 + 验证门控 → 生成提案 → 你审核采纳不是"学了就写进去",而是"学了 → 验证了 → 确认有效 → 才写进去"。这个验证门控是 SkillOpt-Sleep 区别于普通记忆工具的关键。
二、它能产出什么
2.1 运行阶段的产出
/sleep dry-run | ||
/sleep run | ||
/sleep status | ||
/sleep adopt | 你确认后CLAUDE.md / SKILL.md |
2.2 最终写入的内容
adopt 后,你的项目文件中会多出一个 LEARNED 区块:
<!-- SLOW_UPDATE_START -->- 写 API 接口时,始终先检查参数类型和边界条件- 错误响应统一用 { code, message } 格式- 数据库查询必须加 try-catch 并返回 500- 组件命名采用 PascalCase,文件名采用 kebab-case<!-- SLOW_UPDATE_END -->关键特点:
•写入到受保护的区块内,不会覆盖你手写的规则
•每次 adopt 前自动备份原文件
•规则是从你的实际成功/失败会话中提炼出来的,不是凭空生成的
三、安装指南
3.1 前置条件
•Python 3.10+
•Claude Code CLI(claude 命令)或 Codex CLI(codex 命令)已安装并在 PATH 中
3.2 Claude Code 安装
# 1. 克隆仓库git clone https://github.com/microsoft/SkillOpt.gitcd SkillOpt# 2. 添加插件到 Claude Code/plugin marketplace add ./skillopt-sleep-plugin/plugin install skillopt-sleep@skillopt-sleep# 3. 验证安装/sleep status3.3 Codex 安装
# 1. 克隆仓库(同上)git clone https://github.com/microsoft/SkillOpt.gitcd SkillOpt# 2. 运行安装脚本bash plugins/codex/install.sh# 3. 验证/sleep status3.4 Cursor 用户怎么用
Cursor 本身没有原生的 /sleep 命令支持,但有三种方式可以用:
方式 A:在 Cursor 内置终端中直接调用 Python CLI(最简单)
Cursor 自带终端,直接在终端里跑:
# 在 Cursor 打开的项目终端中python -m skillopt_sleep run --project "$(pwd)" --backend mock # 先试试python -m skillopt_sleep run --project "$(pwd)" --backend claude # 正式跑前提是你的机器上已经安装了 SkillOpt-Sleep 引擎。
方式 B:Claude Code + Cursor 混合使用(推荐)
最务实的方案——不需要在 Cursor 里直接跑 /sleep:
日常编码 → Cursor(可视化 IDE)/sleep 睡眠优化 → Claude Code 终端(独立打开)产出物 → CLAUDE.md / SKILL.md(两个工具都能读)1.在 Cursor 里正常写代码(积累会话记录到 ~/.claude)
2.打开一个独立的终端窗口运行 Claude Code 的 /sleep 命令
3.Sleep 的产出(CLAUDE.md 中的 LEARNED 区块)会被 Cursor 的 AI 在下次对话时自动读取
方式 C:通过 Copilot MCP 服务器接入
SkillOpt-Sleep 提供了 Copilot 插件,可以注册为 MCP 服务器:
将 plugins/copilot/mcp_server.py 注册为 MCP 服务器Cursor 支持 MCP 协议,所以理论上可以把这个 MCP 服务器加到 Cursor 的 MCP 配置中。但这条路较新,稳定性需要自行验证。
3.5 配置 API 凭证(按需)
使用真实后端时需要配置 API 密钥:
# Claude 后端export ANTHROPIC_API_KEY="sk-ant-..."# 或 Azure OpenAI 后端export AZURE_OPENAI_ENDPOINT="https://your-resource.openai.azure.com/"export AZURE_OPENAI_API_KEY="your-key"如果只想试试效果,不需要任何 API 密钥——使用 --backend mock 即可,它是确定性的、零花费的模拟后端。
3.6 国产模型兼容性说明
如果你的 Claude Code 对接的是国产大模型(如通义千问、DeepSeek、MiniMax 等),需要知道以下限制:
SkillOpt-Sleep 的 backend 只支持三种:
mock | ||
claude | claude -p | |
codex | codex exec |
它不是直接调 API,而是通过 shell 调用 claude 或 codex 的命令行工具。 主项目 SkillOpt 的论文代码支持 Qwen、MiniMax 等后端,但 Sleep 插件目前没有这些后端。
实际可行的方案:
| A. 用 mock 后端 | --backend mock | |
| B. 通过 Claude CLI 透传 | claude CLI 已通过 API proxy 对接国产模型,--backend claude 会透传调用 | |
| C. 等官方扩展 |
一个重要的注意事项: SkillOpt-Sleep 的 reflect()(反思/提炼规则)步骤对模型能力要求较高。
实测表明,弱模型做优化器不稳定,容易产出非 JSON 格式的错误回复,浪费整个睡眠周期。
如果国产模型的指令跟随能力不够强,效果可能不理想。建议优化器用强模型(如 Claude Sonnet),目标模型可以用便宜的模型。
四、使用方式详解
4.1 在 Claude Code 中使用
进入你的项目目录,启动 Claude Code,然后:
# 第一步:安全预览(不产生任何改动)/sleep dry-run# 第二步:正式运行(生成暂存提案,仍不改文件)/sleep run# 第三步:查看它学到了什么/sleep status# 第四步:你满意的话,采纳/sleep adopt推荐工作流:先 dry-run 看看 → 再 run → 检查 status → 确认无误再 adopt。 每一步都可以停下来不继续。
4.2 命令行直接调用
如果你更喜欢命令行操作:
# 零花费试用(mock 后端)python -m skillopt_sleep run --project "$(pwd)" --backend mock# 使用 Claude 真实优化python -m skillopt_sleep run --project "$(pwd)" --backend claude# 使用 Codex 真实优化python -m skillopt_sleep run --project "$(pwd)" --backend codex4.3 零 API 花费的确定性验证
不需要任何 API 密钥,直接验证引擎是否正常工作:
python -m skillopt_sleep.experiments.run_experiment --persona researcher --assert-improvespython -m skillopt_sleep.experiments.run_experiment --persona programmer --assert-improves它会打印出 held-out 评分从基线向 1.0 提升的过程,并确认门控成功拦截了注入的有害编辑。
4.4 设置夜间自动运行
# 打印 crontab 行(不自动安装,你自己决定是否添加)"${CLAUDE_PLUGIN_ROOT}/scripts/install-cron.sh""$(pwd)"添加到 crontab 后,SkillOpt-Sleep 会在每天夜间自动运行。
五、多项目管理:如何让你的所有项目都受益
5.1 核心限制
SkillOpt-Sleep 是按项目目录绑定的。
它用 --project "$(pwd)" 确定作用域,输出也只写入当前项目。
所以,不能从总文件夹一键跑所有子项目。如果你在父目录运行 /sleep,它只会尝试对父目录做优化,不会自动遍历子目录。
5.2 解决方案:循环脚本
写一个脚本来遍历所有项目:
#!/bin/bash# sleep-all.sh — 逐个项目跑 SkillOpt-SleepPARENT_DIR="/path/to/your/projects"for project in"$PARENT_DIR"/*/; do# 跳过没有 CLAUDE.md 或 .claude 的非项目文件夹if [ ! -d "$project/.claude" ] && [ ! -f "$project/CLAUDE.md" ]; thenecho"跳过 $project(不是 Claude Code 项目)"continuefiecho"正在处理: $project"cd"$project" || continue python -m skillopt_sleep run --project "$(pwd)" --backend claudeecho"$project 完成"echo"---"done5.3 或者:每个项目各自 cron
# 在每个项目目录下分别执行一次cd /path/to/project-A"${CLAUDE_PLUGIN_ROOT}/scripts/install-cron.sh""$(pwd)"cd /path/to/project-B"${CLAUDE_PLUGIN_ROOT}/scripts/install-cron.sh""$(pwd)"5.4 建议
| 推荐 |
六、隐私与安全:它到底看到了你的什么
这是很多人关心的重要问题。根据源码分析:
6.1 它采集了什么
数据来源是 ~/.claude/projects/ 下的本地会话 JSONL 文件(Claude Code 自动保存的历史记录)。
user_prompts | 你发给 AI 的所有提问原文 | 是 |
assistant_finals | ||
project | ||
git_branch | ||
tools_used | ||
files_touched | ||
feedback_signals |
6.2 安全保障
虽然有采集,但有多层保护:
•纯本地运行 — 采集的是 ~/.claude 本地文件,不做网络传输
•只读采集 — harvest 阶段不修改任何原始文件
•密钥脱敏 — 在发送给优化器之前会对 prompt 中的密钥进行脱敏
•不自动应用 — 产出只是提案,需要你手动 /sleep adopt 才写入
•最终产出是规则,不是原始对话 — 写入 CLAUDE.md 的是提炼后的通用规则
6.3 需要注意的
如果使用 --backend claude 或 --backend codex,提炼后的 TaskRecord(包含你的提问摘要)会作为 prompt 发给优化器模型进行分析。
虽然做了脱敏,但你的提问意图和大意会经过 API。
如果你对隐私有顾虑:
•用 --backend mock(不发网络请求,纯本地处理)
•先 /sleep dry-run 看它采集了哪些内容再决定
•敏感项目直接跳过,只在不敏感的项目上使用
七、进阶配置
7.1 验证门控开关
# 开启门控(默认)— 只保留确实有效的编辑python -m skillopt_sleep run --project "$(pwd)" --gate on# 关闭门控 — 贪婪模式,编辑不经过硬门控,但仍报告验证分数变化python -m skillopt_sleep run --project "$(pwd)" --gate off7.2 预算控制
# 按 token 预算python -m skillopt_sleep run --project "$(pwd)" --budget-tokens 60000# 按时间预算python -m skillopt_sleep run --project "$(pwd)" --budget-minutes 30引擎会自动规划深度(夜晚数 × 每任务回放次数)来适配预算,用完即停。
7.3 多次回放对比反思
# 每个任务回放 3 次,对比高分和低分尝试的差异来提炼规则python -m skillopt_sleep run --project "$(pwd)" --rollouts-k 3 --backend claude这是 SkillOpt-Sleep 的"想象力核心"——多次回放出同一个任务的不同结果,从对比中提炼出"好的尝试做了什么、差的尝试缺了什么"。
7.4 用户偏好注入
python -m skillopt_sleep run --project "$(pwd)" \ --preferences "代码注释用中文,变量命名用英文,优先简洁" \ --backend claude你的偏好会作为"先验"注入优化器的反思提示中,影响它写出的规则。
7.5 优化器/目标分离(高级)
# 用强模型(Sonnet)做优化,弱模型(Haiku)做目标python -m skillopt_sleep run --project "$(pwd)" \ --optimizer-backend claude --optimizer-model sonnet \ --target-backend claude --target-model haiku实测表明:优化器模型越强,产出的规则质量越高。弱模型自优化容易产出格式错误,浪费周期。
八、怎么确保跑出有意义的结论
很多人跑完 /sleep 发现产出的规则毫无价值——这不一定是工具的问题,更可能是输入数据的问题。
8.1 核心问题:垃圾进,垃圾出
如果你的历史会话全是这类内容:
•“把这行的 null check 加上”
•“这个按钮颜色改一下”
•“typo fix: ‘recieve’ → ‘receive’”
那引擎挖掘出的任务全是琐碎任务,提炼出的规则可能是"修改代码时注意拼写错误"——毫无价值。
输入数据的质量直接决定产出质量。
8.2 六个策略确保有意义的结论
策略 1:扩大时间窗口
默认只看最近 3 天(lookback_hours: 72)。如果最近都是小修小补,可以扩大回溯范围:
// ~/.skillopt-sleep/config.json{"lookback_hours":720}策略 2:用 LLM 矿工替代启发式矿工
默认的启发式矿工只看第一条提问,很粗糙。开启 llm_mine(默认已开启)后,引擎会用优化器模型分析完整会话,提取更有深度的任务描述:
python -m skillopt_sleep run --project "$(pwd)" --backend claude# llm_mine 默认为 true,自动启用策略 3:用 preferences 注入你想要的方向
告诉引擎你想学什么,而不是让它盲目挖掘:
python -m skillopt_sleep run --project "$(pwd)" --backend claude \ --preferences "重点关注:API 错误处理模式、组件设计原则、数据库查询优化"策略 4:少而精 > 多而杂
// ~/.skillopt-sleep/config.json{"max_tasks_per_night":10}10 个有深度的任务比 40 个琐碎任务产出更好。
策略 5:关注"失败会话"——这才是金矿
你反复纠正 AI 的会话才是最有价值的输入。这些会话暴露了 AI 的系统性弱点,提炼出的规则才真正有意义。
策略 6:强优化器 + 弱目标模型
强优化器能从琐碎任务中抽象出通用原则。比如从 5 个"修 typo"会话中提炼出"代码变更前应先运行 lint 检查"。
8.3 跑之前的自检清单
过去一段时间里,我有没有:□ 反复纠正 AI 同一个问题? → 值得学□ 做过涉及架构/设计决策的任务? → 值得学□ 教会 AI 一个它不懂的项目规范? → 值得学□ 踩过坑、排查了很久才解决的问题? → 值得学如果以上全是"否" → 先积累有价值的会话,再跑 sleep如果有"是" → 扩大 lookback_hours,让它回溯到那些会话九、实战案例:真实项目的 Sleep 产出分析
为了让你直观理解 SkillOpt-Sleep 的实际效果,以下是一个真实项目的运行结果分析。
9.1 项目背景
e-sign 是一个电子签约系统(e-sign),涉及合同签约流程、API 对接、参数映射等。项目用 Claude Code 开发,日常会话包括 bug 修复、需求迭代、API 文档整理等。
9.2 四次运行记录
| 拒绝 | |||||
| 拒绝 | |||||
| 拒绝 | |||||
| 接受 |
前 3 次都被门控拦截了,第 4 次才通过。这说明门控在正常工作。
9.3 第 4 次产出的 4 条规则
规则 1:必须包含"影响分析"章节 ✅ 有价值
每次涉及共享文件、工具函数或模块的变更时,回复中必须包含标题为"影响分析"的章节。
分析: 引擎发现用户在多次会话中让 AI 做变更影响评估,AI 经常漏掉这个环节。这条规则能让 AI 以后每次都主动提供影响分析。
规则 2:API 文档必须包含关键领域术语 ⚠️ 过于机械
讨论 API 契约、参数示例或流程场景时,必须包含:‘bType’, ‘contract’, ‘esignCId’ 等术语。
分析: 这条本质上是"关键字检查清单",太具体了,在新场景下可能显得僵硬。
规则 3:影响分析必须给出明确的兼容性标签 ✅ 有价值
在"影响分析"章节中,必须包含以下标签之一:‘不影响’、‘无影响’、‘不会影响’、‘compatible’。
分析: 这条规则强制 AI 在分析完后给出一个清晰的兼容性判定,而不是含糊其辞。非常实用。
规则 4:JSON 示例必须包含 bType ⚠️ 过于机械
每个展示 API 参数的 JSON 代码块必须包含 ‘bizType’ 字段。
分析: 对当前项目有用,但如果项目上下文变了就不适用了。
真实案例使用,如下截图:
/sleep run 结果: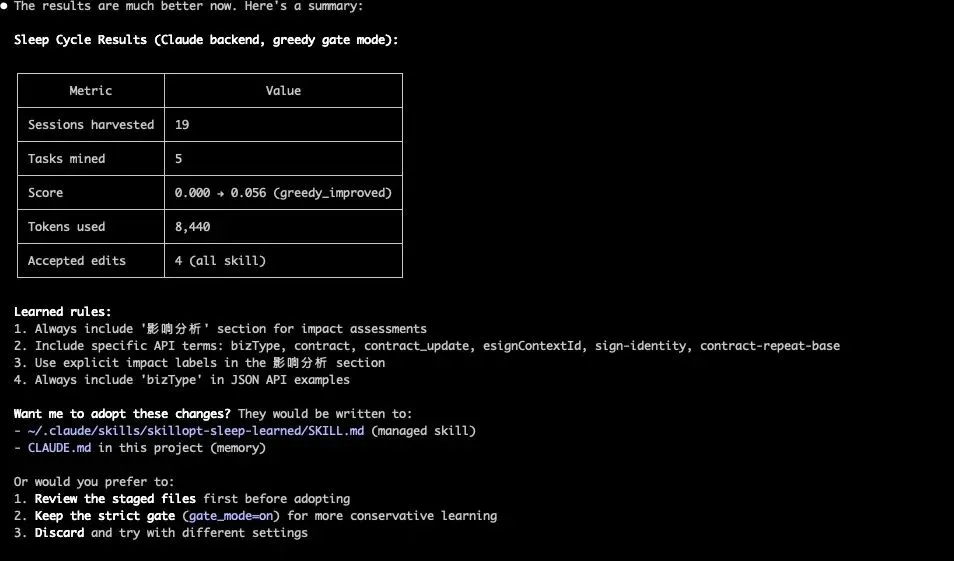
/sleep status 结果: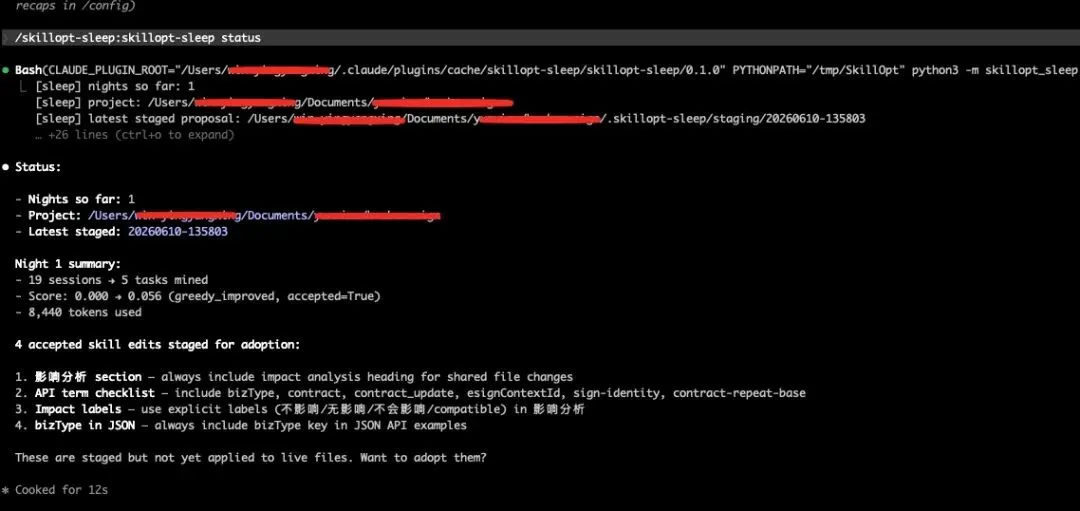
/sleep 生成的文件: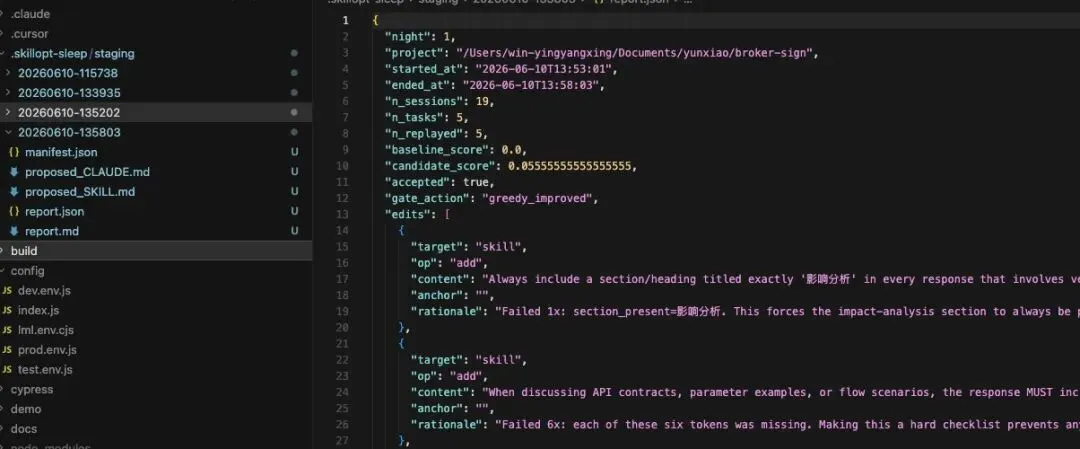
9.4 这个案例告诉我们什么
有价值的部分:
•引擎准确识别了工作模式——电子签约系统的 API 对接和变更影响分析
•规则 1 和 3 是真正有深度的通用规则
•门控正确拦截了前 3 次的低质量提案(第 3 次试图把具体函数名硬编码成规则,被拦截了)
价值有限的部分:
•规则 2 和 4 过于具体,不如直接写在 CLAUDE.md 里
•held-out 分数只提升到 0.056,改进幅度很小
•19 个会话只提炼出 5 个有意义的任务,输入数据偏少
9.5 实际建议
SkillOpt-Sleep 不是"跑了就有效",而是"有高质量的失败经验才有效"。
把它想象成一个实习生——如果你每天只让它取快递,它永远学不会写代码;但如果你让它参与了几次有深度的 code review 并纠正了它的错误,它才能真正成长。
十、一张图记住所有
图 1 · 主流程(输入 → 门控 → 采纳)
读者怎么读:自上而下;菱形为「验证门控」与「是否 adopt」;
拒绝退步会回到「反思+有界编辑」,不自动写文件。
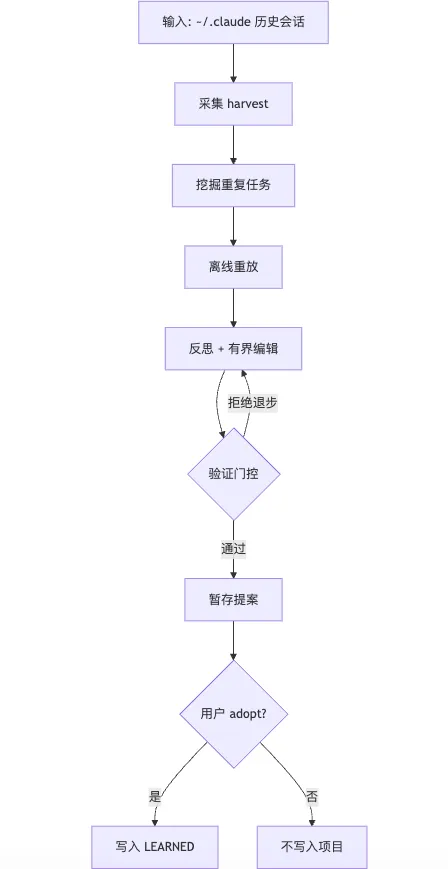
图 2 · 接入方式(横向总览)
星形结构兼容性优于无箭头横线
---。
总结:值不值得用
适合你的场景:
•你每天高频使用 Claude Code / Codex 编程
•你有反复纠正 AI 同一个问题的经历
•你希望 AI 能"记住"你项目的规范和你的编码习惯
•你愿意给 AI 一个"成长"的机会
不太适合的场景:
•你只是偶尔用 AI 辅助写几行代码
•你的项目高度敏感,不能有任何数据经过外部 API(除非用 mock 后端)
•你只用一次就不再使用的项目
我的建议:
先用 --backend mock 在你最常用的项目上跑一次 dry-run,看看它从你的历史会话里学到了什么。如果结果让你眼前一亮——那就正式接入 nightly cron,让它每天悄悄帮你变强一点点。
工具的价值不在于它有多强大,而在于它能不能随着你的使用变得越来越懂你。
SkillOpt-Sleep 是目前我见过的最接近"AI 自我进化"这个理念的实用工具。
