 夜雨聆风
夜雨聆风本文主要参考 QUADAS-3 最新解释与阐释文章,对其评估流程和核心内容进行中文化整理。框架和表述借助 ChatGPT 辅助梳理,已由本人结合原文重新校对和修改。
一、QUADAS-3的总体评判逻辑
QUADAS-3主要评价两件事:
1. Risk of bias:偏倚风险
即某个诊断准确性估计值是否可能因为研究设计、实施、判读或统计分析过程而被系统性高估或低估。
需要注意:QUADAS-3评价的不是“整篇文章好不好”,而是评价某个具体的准确性估计值,例如某篇文章中某个模型、某个阈值、某个验证集上的 sensitivity/specificity。
一篇研究可以报告多个准确性估计值,因此同一篇文章内部,不同模型、不同数据集、不同阈值、不同目标疾病定义的偏倚风险可能不同。
2. Concerns regarding applicability:适用性担忧
即研究中的人群、index test、target condition是否与你系统综述真正想回答的问题一致。
它不是问研究质量高不高,而是问:
这项研究的结果能不能用于我的系统综述问题?
二、QUADAS-3的6个评判阶段
QUADAS-3共分为6个阶段:
| 阶段 | 内容 | 完成层面 |
|---|---|---|
| Phase 1 | 明确系统综述的synthesis questions | 每个review一次 |
| Phase 2 | 为每个synthesis question定义ideal test accuracy trial | 每个review一次 |
| Phase 3 | 为每篇研究画流程图 | 每篇研究一次 |
| Phase 4 | 确定要评价哪些准确性估计值 | 每篇研究一次 |
| Phase 5 | 对每个选定估计值评估risk of bias和applicability | 每个准确性估计值一次 |
| Phase 6 | 给出overall judgment | 每个准确性估计值一次 |
Phase 1:明确系统综述的“合成问题”
第一步不是直接评价文献,而是先写清楚你的系统综述或DTA Meta分析到底要回答什么问题。
每个 synthesis question 至少要明确以下三项:
| 要素 | 需要写清楚的内容 |
|---|---|
| Participants | 目标人群,即这个检查未来要用于哪些患者 |
| Index test | 被评价的检查、模型、评分、影像指标或检测策略 |
| Target condition | 这个检查要诊断、筛查、分期或预测的目标疾病/状态,并说明由什么reference standard定义 |
只有 Participants、Index test、Target condition 中至少一个不同,才需要作为不同的 synthesis question 处理。
Phase 2:定义“理想诊断准确性试验”
这是QUADAS-3最关键的变化之一。
你需要先构想一个理论上最理想的诊断准确性研究,即 ideal test accuracy trial。之后再拿每篇真实研究去和这个理想研究比较,判断哪些偏离可能造成偏倚,哪些偏离会影响适用性。
ideal test accuracy trial需要定义的内容
| 模块 | 理想情况下应如何定义 |
|---|---|
| Objective | 研究目的应与综述问题一致,说明index test在临床路径中的角色,如筛查、分诊、替代、附加、诊断或分期 |
| Participants | 应代表真实临床中会接受该检查的人群,最好是前瞻性、single-gate、连续或随机纳入 |
| Index test | 说明检查/模型的版本、实施方式、操作者/阅片者、是否按推荐流程执行、阈值如何设定 |
| Target condition / reference standard | 明确目标疾病/状态,说明参考标准是什么,是否足够准确,是否所有人使用同一标准 |
| Timing | index test和reference standard之间的时间间隔是否足够短,避免疾病状态改变 |
| Analysis | 是否纳入所有受试者,缺失值如何处理,分析单位是什么,敏感度/特异度是否计算正确 |
Phase 3:为每篇研究画流程图
第三步是为每篇纳入研究画出 participant flow。
流程图不一定要正式发表,也可以手画。它的目的不是美观,而是帮助你看清楚研究中受试者和检测结果是如何流动的。
流程图建议包括
| 内容 | 目的 |
|---|---|
| 初筛人数 | 看研究来源和选择过程 |
| 纳入人数 | 判断是否连续或随机纳入 |
| 完成index test人数 | 看是否存在未完成检查 |
| 完成reference standard人数 | 看是否存在partial verification bias |
| 进入2×2表分析人数 | 看是否排除了缺失、不可判读、中间结果 |
| 排除原因 | 判断是否可能造成偏倚 |
重点关注
如果研究声称纳入200例,但最后只有120例用于计算AUC、敏感度、特异度,你必须弄清楚剩余80例为什么被排除。
常见问题包括:
没有病理结果;
图像质量差;
分割失败;
模型无法输出结果;
index test结果不确定;
reference standard缺失;
只保留完整数据病例;
只分析某些亚组。
这些情况都可能影响偏倚风险判断。
Phase 4:确定要评价哪些准确性估计值
QUADAS-3不是要求评价文献中所有AUC或所有模型,而是只评价与你 Phase 1 综述问题相关的准确性估计值。
通常优先评价能够形成2×2表的成对准确性估计值,例如:
sensitivity;specificity;TP;FP;FN;TN;
一篇研究中可能有多个准确性估计值,通常应分别考虑,尤其Meta分析要用哪个就评哪个,只评与你综述问题相关的模型,只评你纳入分析的阈值对应结果,只评与你综述问题一致的目标条件,与理想试验设定一致
建议建立estimate selection表
| Study | Dataset | Model/index test | Target condition | Threshold | TP | FP | FN | TN | 是否纳入Meta | QUADAS-3评估对象 |
|---|---|---|---|---|---|---|---|---|---|---|
这样可以避免把不相关的模型或不相关的target condition错误纳入主Meta分析。
Phase 5:对每个选定估计值进行4个领域评估
QUADAS-3包括4个domain:
| Domain | 中文理解 | 评估内容 | 是否评Risk of bias | 是否评Applicability |
|---|---|---|---|---|
| Domain 1 | Participants | 研究对象如何选择 | 是 | 是 |
| Domain 2 | Index test | 被评价检查/模型如何实施和解释 | 是 | 是 |
| Domain 3 | Target condition | 目标疾病及参考标准 | 是 | 是 |
| Domain 4 | Analysis | 数据处理和统计分析 | 是 | 否 |
每个domain的结构基本相同:
摘录文献信息;
回答signaling questions;
给出domain-level risk of bias判断;
写明risk of bias判断理由;
对前三个domain还要判断applicability;
写明applicability判断理由。
Signaling questions怎么回答?
| 选项 | 含义 |
|---|---|
| Y | Yes,是,明确符合低偏倚风险 |
| PY | Probably yes,可能是,描述不完整但大概率符合 |
| PN | Probably no,可能不是,描述不完整但大概率不符合 |
| N | No,否,明确不符合 |
| NI | No information,无信息,文献完全没有足够信息判断 |
重要规则
所有signaling questions都设计成:Y/PY倾向于低偏倚风险。
NI只能在真的没有信息时使用,不要把“写得不详细”都判成NI。
QUADAS-3没有“not applicable”选项;如果某个问题在你的研究场景中确实不适用,应填Y,因为它不会引入该项偏倚。
PN或N不自动等于该domain高风险,而是提示可能存在偏倚。
最终domain-level judgment要结合预设规则、临床意义和方法学判断。
三、四大Domain的具体评判内容
Domain 1:Participants,研究对象选择
这个domain评估:
研究对象的选择方式是否会导致谱偏倚,研究对象是否符合你的综述问题。
Risk of bias的4个问题
| 编号 | Signaling question | 判断重点 |
|---|---|---|
| 1.1 | 是否使用single-gate design? | 是否从同一临床入口纳入疾病状态未知的人群,而不是先找病例再找对照 |
| 1.2 | 受试者是否前瞻性纳入? | 是否在index test和reference standard之前纳入,而不是从已有病历/数据库回顾性筛选 |
| 1.3 | 是否连续或随机纳入? | 是否避免方便抽样、选择性纳入 |
| 1.4 | 研究样本是否代表该研究的intended-use population? | 是否排除了难诊断人群、只纳入严重病例、只纳入特定亚组 |
Domain 1常见高偏倚风险情况
病例-对照设计,即先找已知疾病组,再找健康对照组;
只纳入典型病例或严重病例;
使用健康人作为对照,而不是临床疑似但最终无病的人;
回顾性从数据库中筛选有完整检查和病理的人;
排除了难以诊断的人群,如合并症、图像质量差、非典型表现者;
未说明是否连续纳入或随机纳入。
Applicability怎么判断?
比较真实研究对象和你Phase 2定义的理想人群是否一致。
常见高适用性担忧包括:
你的综述想评价普通临床疑似患者,但研究只纳入手术病例;
你的综述想评价所有肺结节,但研究只纳入纯磨玻璃结节;
你的综述想评价术前CT模型,但研究只纳入已知病理分级的回顾性病例;
你的综述想评价临床真实人群,但研究排除了肥胖、图像质量差、合并疾病、非典型病例。
Domain 2:Index test,被评价检查或模型
这个domain评估:
index test是否按照临床真实使用方式执行、解释和设定阈值。
Risk of bias的4个问题
| 编号 | Signaling question | 判断重点 |
|---|---|---|
| 2.1 | index test是否按推荐说明执行和解释? | 检查流程、扫描参数、试剂/设备/模型版本、操作者是否符合预设 |
| 2.2 | index test解释时是否不知道reference standard结果? | 阅片者、模型开发者或特征提取者是否被病理或最终诊断影响 |
| 2.3 | index test解释时获得的信息是否与真实临床一致? | 不能多拿临床中不会提前知道的信息,也不能故意不给临床中本应有的信息 |
| 2.4 | 如使用阈值,是否为标准阈值或预先指定? | 阈值不能事后根据本研究数据挑选最佳cut-off |
Domain 3:Target condition,目标疾病和参考标准
这个domain评估:
reference standard能不能正确判定目标疾病,target condition是否与你综述问题一致。
Risk of bias的8个问题
| 编号 | Signaling question | 判断重点 |
|---|---|---|
| 3.1 | reference standard能否充分识别有无target condition? | 参考标准是否足够可靠 |
| 3.2 | 所有受试者是否都接受了target condition评估? | 是否存在partial verification bias |
| 3.3 | 所有受试者是否以同样方式评估target condition? | 是否有人用病理,有人用随访,有人用其他标准 |
| 3.4 | reference standard是否避免纳入index test? | 避免incorporation bias |
| 3.5 | reference standard是否按推荐说明执行和解释? | 病理、随访、复合标准是否规范 |
| 3.6 | reference standard解释时是否不知道index test结果? | 病理或最终诊断是否被index test影响 |
| 3.7 | 如reference standard有阈值,是否为标准或预设阈值? | 例如病理分级、培养阳性阈值、评分阈值 |
| 3.8 | index test和reference standard之间时间间隔是否合适? | 间隔太长可能疾病进展、治疗改变状态 |
Domain 4:Analysis,数据处理和统计分析
这个domain只评risk of bias,不评applicability。
它关注的是:
数据处理、缺失值处理、分析单位和准确性计算是否会引入偏倚。
Risk of bias的4个问题
| 编号 | Signaling question | 判断重点 |
|---|---|---|
| 4.1 | 是否所有受试者都纳入分析? | 入组后是否有人因缺失、无病理、不可判读、中间结果被排除 |
| 4.2 | 缺失数据是否处理恰当? | 是否采用合理方法,如多重插补、合理敏感性分析等 |
| 4.3 | 分析单位是否与理想试验一致? | patient-level、lesion-level、sample-level不能混淆 |
| 4.4 | sensitivity和specificity是否计算正确? | 2×2表数字是否一致,TP/FP/FN/TN是否能对应 |
Phase 6:给出总体判断
Phase 6是对每个选定的准确性估计值给出总判断。
Overall risk of bias判断规则
| Domain-level结果 | Overall risk of bias |
|---|---|
| 任一domain为High | Overall = High |
| 所有domain均为Low | Overall = Low |
| 至少一个domain为Insufficient information,且没有High | Overall = Insufficient information |
Overall applicability判断规则
适用性总体判断类似:
| Domain-level结果 | Overall applicability concern |
|---|---|
| 任一domain为High concern | Overall = High concern |
| 所有相关domain均为Low concern | Overall = Low concern |
| 至少一个domain为Insufficient information,且没有High concern | Overall = Insufficient information |
QUADAS-3不建议增加“moderate risk”这一档。如果某个准确性估计值在一个domain中被判为高偏倚风险,则该估计值总体应判为高风险。
四、实际操作时推荐的Excel表格结构
如果你后续要真正做QUADAS-3,建议Excel至少设置6张表。
Sheet 1:Synthesis question
| Question ID | Participants | Index test | Target condition | Reference standard | Intended clinical role |
|---|---|---|---|---|---|
Sheet 2:Ideal test accuracy trial
| Question ID | Objective | Ideal participants | Ideal index test | Ideal reference standard | Ideal timing | Ideal analysis |
|---|---|---|---|---|---|---|
Sheet 3:Study flow
| Study | Screened | Included | Index test done | Reference standard done | Analyzed | Excluded after enrollment | Reason |
|---|---|---|---|---|---|---|---|
Sheet 4:Accuracy estimates selected
| Study | Estimate ID | Dataset | Index test/model | Threshold | Target condition | Unit | TP | FP | FN | TN | Sens | Spec | Included in meta |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Sheet 5:QUADAS-3 domain assessment
| Study | Estimate ID | Domain | Signaling questions | ROB judgment | ROB rationale | Applicability judgment | Applicability rationale |
|---|---|---|---|---|---|---|---|
Sheet 6:Overall summary
| Study | Estimate ID | D1 ROB | D2 ROB | D3 ROB | D4 ROB | Overall ROB | D1 Applicability | D2 Applicability | D3 Applicability | Overall Applicability | Main reason |
|---|---|---|---|---|---|---|---|---|---|---|---|
五、QUADAS-3实际评判流程总结
可以把QUADAS-3操作概括为以下顺序:
先定义综述问题明确Participants、Index test、Target condition。
建立ideal test accuracy trial作为后续所有判断的参照标准。
画每篇研究流程图梳理纳入、检测、参考标准、排除和分析过程。
选择要纳入Meta的准确性估计值只评价与你综述问题相关的estimate。
按4个domain评价ROB和适用性Domain 1 Participants;Domain 2 Index test;Domain 3 Target condition;Domain 4 Analysis。
给每个estimate总体判断任一domain高风险,则overall high risk。
将QUADAS-3结果用于系统综述解释可用于叙述性总结、敏感性分析、亚组分析、meta回归和GRADE证据质量评价。
六、官方Graphs示例
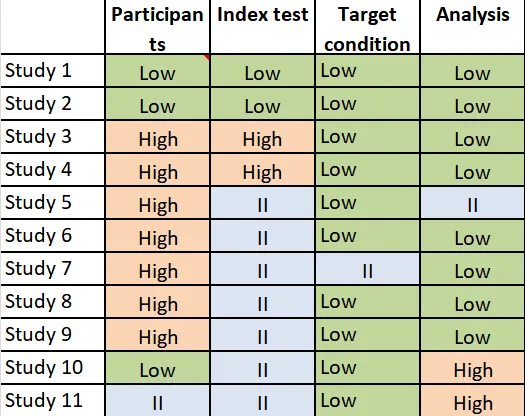
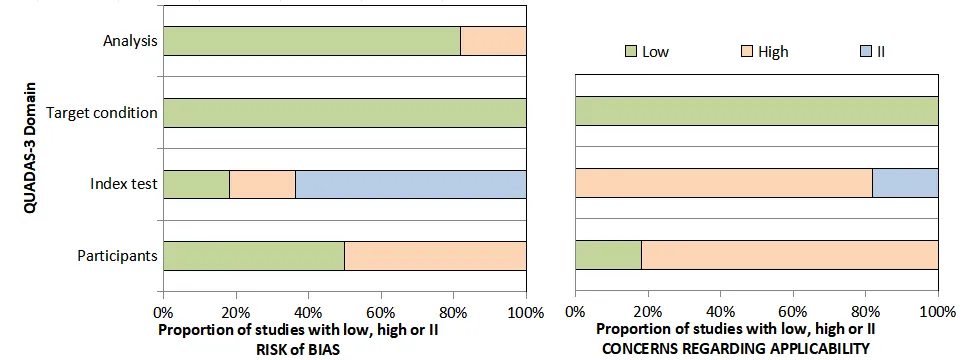
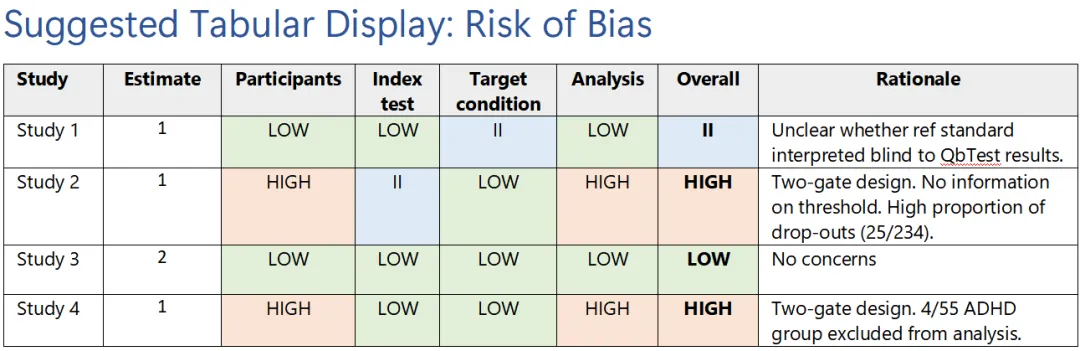
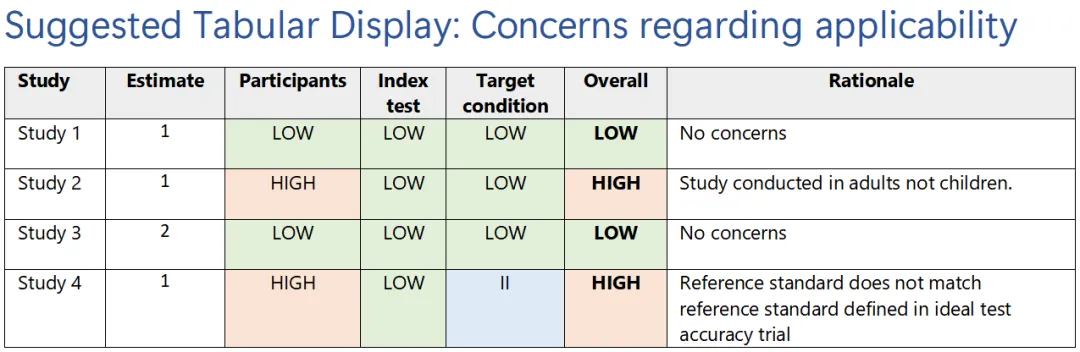
参考文献
Davenport CF, Rutjes AWS, Mallett S, Tomlinson E, Yang B, Holmes J, Westwood ME, Takwoingi Y, Reitsma JB, Hyde C, Bossuyt PMM, Deeks JJ, Leeflang MMG, Whiting PF.QUADAS-3 Explanation and Elaboration: Guidance for Quality Assessment of Diagnostic Test Accuracy Studies. Annals of Internal Medicine. 2026;179:e2504943. doi:10.7326/ANNALS-25-04943.
