 夜雨聆风
夜雨聆风论文题目:Using the improved YOLOv7-Seg model to segment symbols from rock art images
作者:Dongxu Huo,Su Yang,Miaole Hou
作者单位:北京建筑大学测绘与城市空间信息学院;建筑遗产精细重构与健康监测重点实验室;中国矿业大学(北京)地球科学与测绘工程学院
发表期刊:npj Heritage Science
发表时间:2025 年 2 月
DOI:10.1038/s40494-025-01620-2
文章地址:
https://doi.org/10.1038/s40494-025-01620-2
YOLOv7-Seg算法
本文采用 YOLOv7-Seg 作为岩画符号分割的基础模型。YOLOv7 是 YOLO 系列目标检测算法中的代表性模型,其核心优势在于能够通过多分支特征提取结构、密集跳跃连接和下采样结构,在保证检测速度的同时提升目标特征表达能力。针对岩画图像中人物、动物等符号边缘模糊、背景复杂、颜色差异明显等问题,本文并未直接采用普通目标检测框架,而是选择具有实例分割能力的 YOLOv7-Seg 模型,使其不仅能够判断图像中是否存在岩画符号,还能够在像素层面输出对应的符号分割结果。
在具体流程上,YOLOv7-Seg 首先将不同尺寸的输入彩色图像统一预处理为 640×640 像素,然后送入骨干网络进行特征提取。模型整体主要由三部分组成:第一部分是 Backbone,用于从输入图像中提取岩画符号的颜色、纹理、边缘和形状特征;第二部分是 FPN,用于对不同尺度的特征进行融合和增强,使模型能够同时关注较大的动物符号和较小的人物符号;第三部分是预测层,用于在多个尺度上完成目标类别、目标位置和分割掩膜的预测。经过网络预测后,模型再通过 Yolohead 层和非极大值抑制等后处理方法,生成最终的岩画符号分割结果。
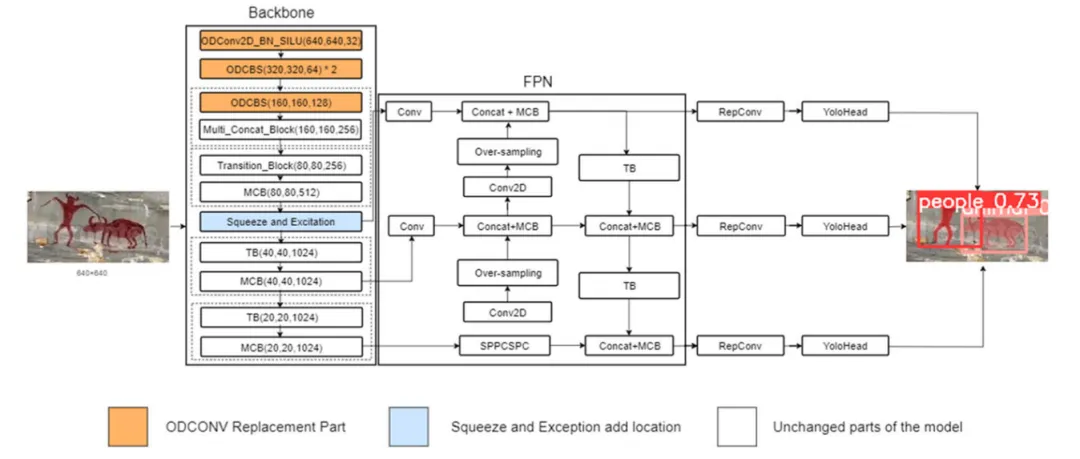
图1:改进 YOLOv7-Seg 模型结构
如图1所示,本文在 YOLOv7-Seg 原有结构的基础上进行了针对性改进。原模型中保持不变的部分继续承担基础特征提取、特征融合和分割预测任务,而改进部分主要集中在骨干网络的特征提取阶段。为了增强模型对岩画符号局部细节、纹理特征和形状轮廓的适应能力,本文将 ODConv 全维动态卷积引入骨干网络,并加入 SE 注意力机制,使模型能够更加关注岩画符号区域中的关键通道信息和边缘特征。通过这种改进,模型在面对岩壁背景变化、符号边界模糊和局部图案退化等情况时,能够提取更有效的符号特征,从而提升岩画人物和动物符号的分割精度。
挤压-激发网络
为了使 YOLOv7-Seg 模型更好地适应岩画符号的边缘轮廓、纹理特征和几何形态,本文在模型中引入了挤压-激发网络,即 SE 模块。SE 是一种轻量级通道注意力机制,其核心思想是通过建模不同通道之间的关系,自动判断哪些特征通道对岩画符号分割更加重要,并对这些关键通道赋予更高权重,从而增强模型对有效符号信息的表达能力。

图2:SE模块结构
如图2所示,SE模块主要包括挤压、激发和特征重标定三个过程。首先,在挤压操作中,模型沿空间维度对局部特征图进行聚合,将原本包含空间信息的特征压缩为通道描述向量,用于表示每个通道的重要性。其次,在激发操作中,模型利用前一步得到的通道描述向量生成一组通道权重,每个权重对应一个特征通道,用于控制该通道特征在后续计算中的增强或抑制。最后,模型将生成的权重重新作用到原始特征上,得到经过加权调整后的特征序列,使网络能够更加关注与岩画人物、动物符号相关的边缘、轮廓和纹理信息,同时降低复杂岩壁背景、颜色差异和无关纹理对分割结果的干扰。
通过引入 SE 注意力机制,本文提升了 YOLOv7-Seg 对通道特征关系的建模能力,使模型不再只是被动提取图像中的局部纹理,而是能够结合全局上下文信息筛选更具判别力的符号特征。这对于岩画图像中常见的背景复杂、符号边界模糊、局部风化明显等问题具有重要作用,有助于提高模型在复杂场景下的岩画符号分割精度。
全维度动态卷积
为进一步提升模型对岩画符号局部细节和复杂背景的适应能力,本文在 YOLOv7-Seg 的骨干网络中引入了全维度动态卷积,即 ODConv。传统卷积神经网络中的卷积核通常是固定的,模型在特征提取过程中使用静态卷积核对输入图像进行处理,这种方式虽然结构稳定,但在面对岩画图像中背景颜色差异大、岩壁纹理复杂、符号边缘模糊等情况时,容易受到无关背景信息干扰,难以充分捕捉人物和动物符号的细节变化。
ODConv 的核心思想是通过多维度动态注意力机制,对传统卷积核的设计方式进行改进。与普通动态卷积只在卷积核数量维度上进行加权不同,ODConv 不仅动态调整卷积核数量,还同时从空间尺寸、输入通道和输出通道等多个维度对卷积核进行自适应调整。这样一来,模型可以根据不同输入图像的内容变化,动态选择更加合适的卷积特征表达方式,从而增强对岩画符号轮廓、纹理和形状特征的提取能力。
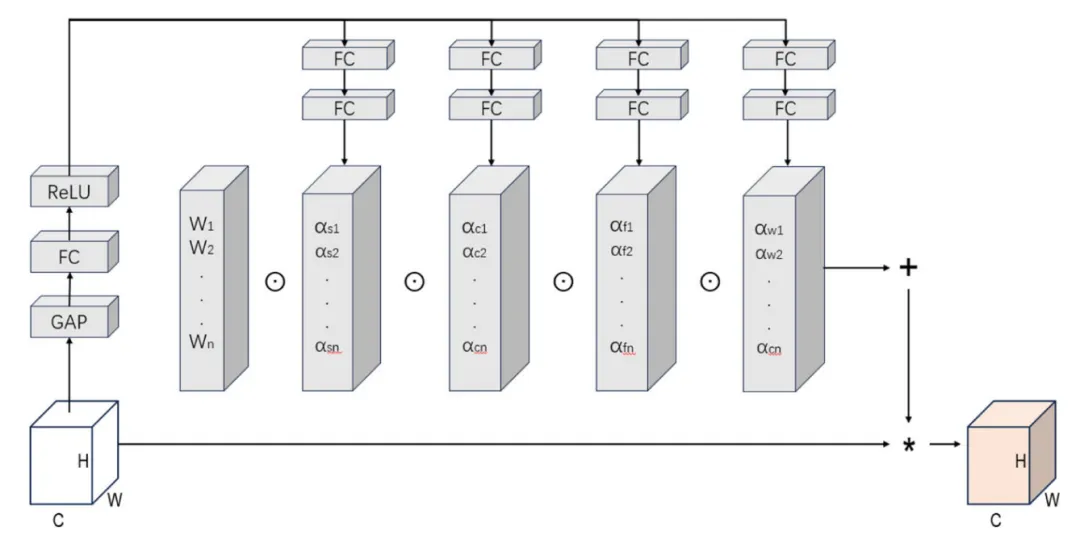
图3:ODConv结构
如图3所示,ODConv 通过并行策略同时学习不同维度上的注意力信息,使模型能够在处理岩画图像时综合考虑空间结构、通道关系和卷积核响应之间的联系。对于人物、动物等岩画符号而言,其形态往往具有较强的不规则性,且符号边界常常与岩壁背景交织在一起。ODConv 的引入能够帮助模型根据图像局部区域的特征变化灵活调整卷积响应,使网络更加关注符号区域本身,而不是被岩壁纹理、颜色斑驳或风化痕迹所干扰。
因此,在本文的改进 YOLOv7-Seg 模型中,ODConv 主要承担增强特征提取能力的作用。它通过动态、细粒度的卷积调整方式,提高了模型对岩画符号边缘、局部纹理和几何结构的感知能力,与前文引入的 SE 注意力机制共同作用,使模型能够在复杂背景下实现更准确的岩画符号分割。
本文使用的数据集主要由沧源岩画图像构成,并结合部分公开岩画图像进行补充。具体来说,研究对象是云南省沧源佤族自治县的沧源岩画,该地区岩画具有较长历史,图像中包含大量人物、动物等可识别符号,是开展岩画符号分割实验的重要数据来源。

图4 | 位于云南省苍元瓦祖自治县的苍元岩画

图5 | 用于训练改进模型的数据集样本(黄色标注代表人类,蓝色标注代表动物)
图6a展示了训练过程中的损失曲线:train/box_loss表示边界框预测相关的损失,train/ seg_loss 代表分割任务的损失,train/obj_loss 对应目标检测或分类任务的损失,而train/ cls_loss 则指类别预测或分类任务的损失。图6b显示了验证过程中的损失曲线。图6a和b均表明模型在训练10个周期后损失值开始逐渐下降,并在约50个周期时总损失趋于稳定。对比可见,训练与验证过程在完成100个周期训练后,损失值均维持在0至0.03之间,表明模型在目标检测和分割任务中均实现了高精度。
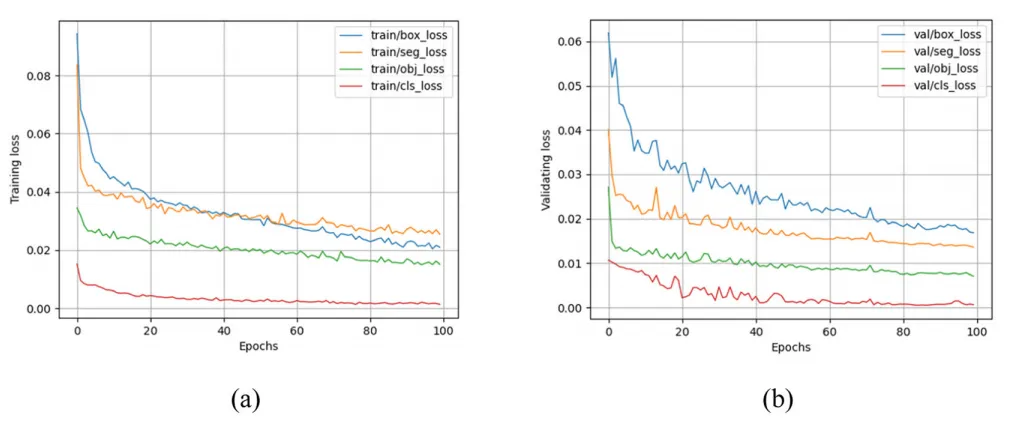
图6 | 模型训练与验证过程中的损失曲线:a 训练阶段的损失曲线;b 验证阶段的损失曲线
经过100个训练周期后,模型的PR曲线和F1置信度曲线如图所示。训练完成后,采用PR曲线和F1分数评估模型对岩画的分割性能。图7a展示了岩画的AP值(AP为精确率-召回率曲线下面积),AP值越高表明模型检测结果越准确:人物类AP值为0.948,动物类为0.973,整体AP值为0.961;图7b显示F1置信度曲线,在置信度为0.510时达到最高F1分数0.95。两幅图均证实了模型具有较高的检测精度。
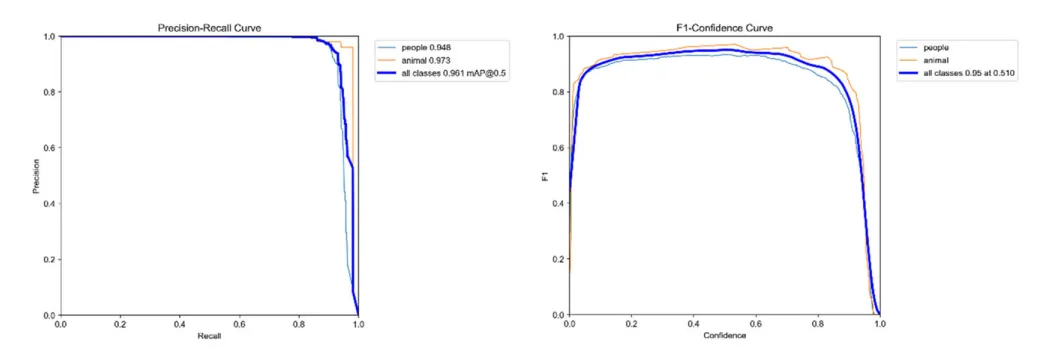
图7 | 模型训练后的PR曲线与F1置信度曲线。a PR曲线;b F1置信度曲线
图8a-h展示了不同背景下的岩画分割效果,该模型能够在多种背景环境及分辨率下成功实现岩画分割。图8a、b 还显示了人物与动物类别的成功分割结果。

图8 | 不同背景下的分割结果。其中a、c、e、g为原始图像,b、d、f、h为分割后的图像。(绿色标注表示人物,蓝色标注表示动物)。
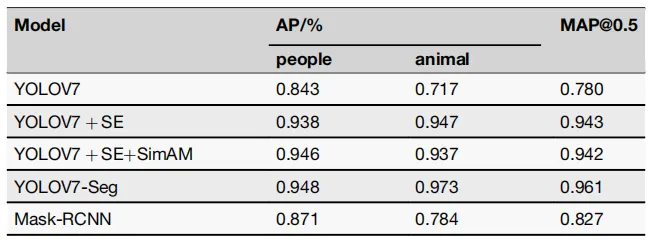
总体来看,本文围绕岩画符号自动分割这一文化遗产数字化保护问题,提出了一种基于改进 YOLOv7-Seg 的岩画人物和动物符号分割方法。针对岩画图像中背景复杂、符号边缘模糊、纹理干扰明显等问题,本文在 YOLOv7-Seg 模型中引入 SE 注意力机制和 ODConv 全维动态卷积,使模型能够更充分地关注岩画符号的边缘、轮廓和通道特征。实验结果表明,改进后的模型在人物和动物符号分割中取得了较高精度,整体 AP 达到 0.961,并且明显优于原始 YOLOv7 和 Mask R-CNN。该研究不仅提高了岩画符号提取的自动化水平,也为岩画符号数据库建设、文化遗产信息管理和后续保护研究提供了技术支持。不过,本文数据主要集中于沧源岩画,未来仍需要进一步扩展不同地区、不同类型岩画样本,以提升模型的泛化能力和实际应用价值。
