 夜雨聆风
夜雨聆风核心判断:AI落地的数据准备,最大的误区不是"数据质量差",而是"想先治理完再用"——正确的做法是"边用边治",在AI应用场景中驱动数据治理,而不是脱离业务场景做数据治理。
关键数字
60%+ — 企业数据治理项目未产生预期业务价值(Gartner 2025)
200万 — 某制造企业一年数据治理投入,但AI用不上的数据占一大半
72%→91% — "边用边治"模式下,3个月内AI模型准确率的提升幅度
1/3 — "边用边治"模式的数据治理投入,仅为"先治理后使用"的1/3
一家中型制造企业,2024年花了200万做数据治理。项目做了整整一年:梳理了数据字典、定义了数据标准、清洗了主数据、建了数据质量监控体系。项目验收时,数据治理团队交出了一份漂亮的报告:数据完整性从65%提升到92%,数据标准覆盖率从40%提升到85%。
但问题来了:当企业启动AI项目时,发现花了200万治理的数据,AI模型用不上的占一大半。AI真正需要的数据维度——比如特定时间窗口的温度变化曲线、压力与良率的关联关系——治理时根本没覆盖到。
"数据治理的方向错了:企业在'囤数据',但AI需要的是'精准食材'。"
我在AI落地咨询项目中观察到一个共性现象:AI落地的数据准备,最大的误区不是"数据质量差",而是"想先治理完再用"——企业把数据治理当成了AI的前置条件,而非并行过程。数据团队埋头治理了一年,等"治理好了"再给AI用,但AI场景需要的数据维度和质量标准,只有在实际使用中才能定义清楚。
Gartner的调研也印证了这一点:超过60%的企业数据治理项目没有产生预期的业务价值,主要原因是治理目标与业务场景脱节。
差距在哪?拆开看三个层面的"坑"。
一、路径错配:脱离AI场景做数据治理,是个无底洞
大多数企业做数据治理的逻辑是这样的:先梳理全量数据资产,建数据字典;定义数据标准和质量规则;清洗数据、建监控体系;"等治理好了,再给AI用"。
这个逻辑听起来没问题,但有个致命缺陷:没有AI场景牵引的数据治理,不知道"治理到什么程度才算好"。
某金融企业2023年启动数据治理项目,目标是"为AI应用打好数据基础"。项目做了两年:统一了客户数据模型、清洗了交易数据、建了数据质量仪表盘。但等到AI团队开始做"客户流失预测"时,发现:治理时重点清洗的"客户基本信息"对AI模型帮助不大,AI真正需要的"客户交互行为数据"反而没有被系统采集。
通俗理解:就像做饭前先把整个厨房打扫一遍——但你可能只需要切个葱花。打扫得很干净,但耽误了做饭。
某金融企业后来调整了策略:不再做"全量数据治理",而是先明确AI场景,再定义数据维度,最后只治理这些维度。3个月后,AI模型效果显著提升,而数据治理投入只有原计划的1/3。
"关键转折点不是花了更多钱治理数据,而是让AI场景定义了治理方向。"
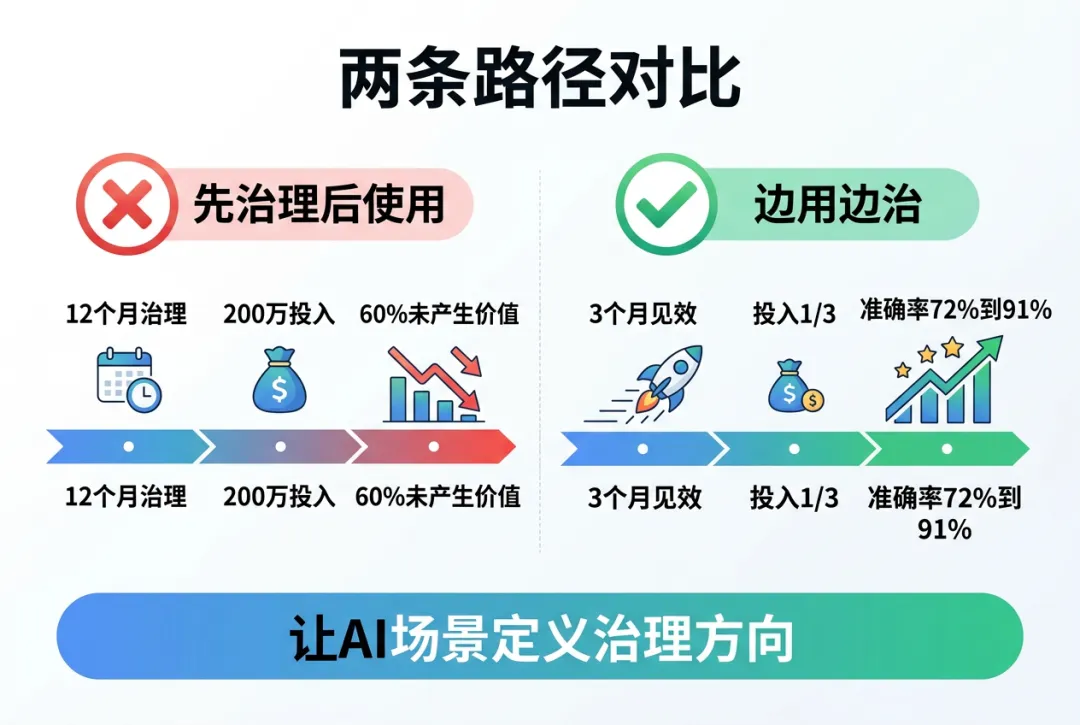
▲ 图:两条数据准备路径对比——"先治理后使用" vs "边用边治"
二、发现错位:数据质量问题,只有在AI场景中才能真正暴露
即使治理方向对了,还有一个问题:你怎么知道数据质量是否"够好"?
很多企业先做一轮数据质量评估,出一份报告——"数据完整性85%、准确性90%、一致性88%"。然后基于这些指标决定"是否可以启动AI"。但这些指标有个问题:它们是"通用指标",不是"AI场景指标"。
某制造企业做数据质量评估,报告显示"生产数据完整性95%"。看起来不错。但当AI团队开始做"工艺参数优化"模型训练时,发现:那5%的缺失数据,恰好集中在某个关键工艺阶段。通用质量报告显示"合格",但AI场景发现"不合格"。
通俗理解:就像做体检——通用体检报告说"基本健康",但专科检查发现某个指标异常。通用检查发现不了专科问题。
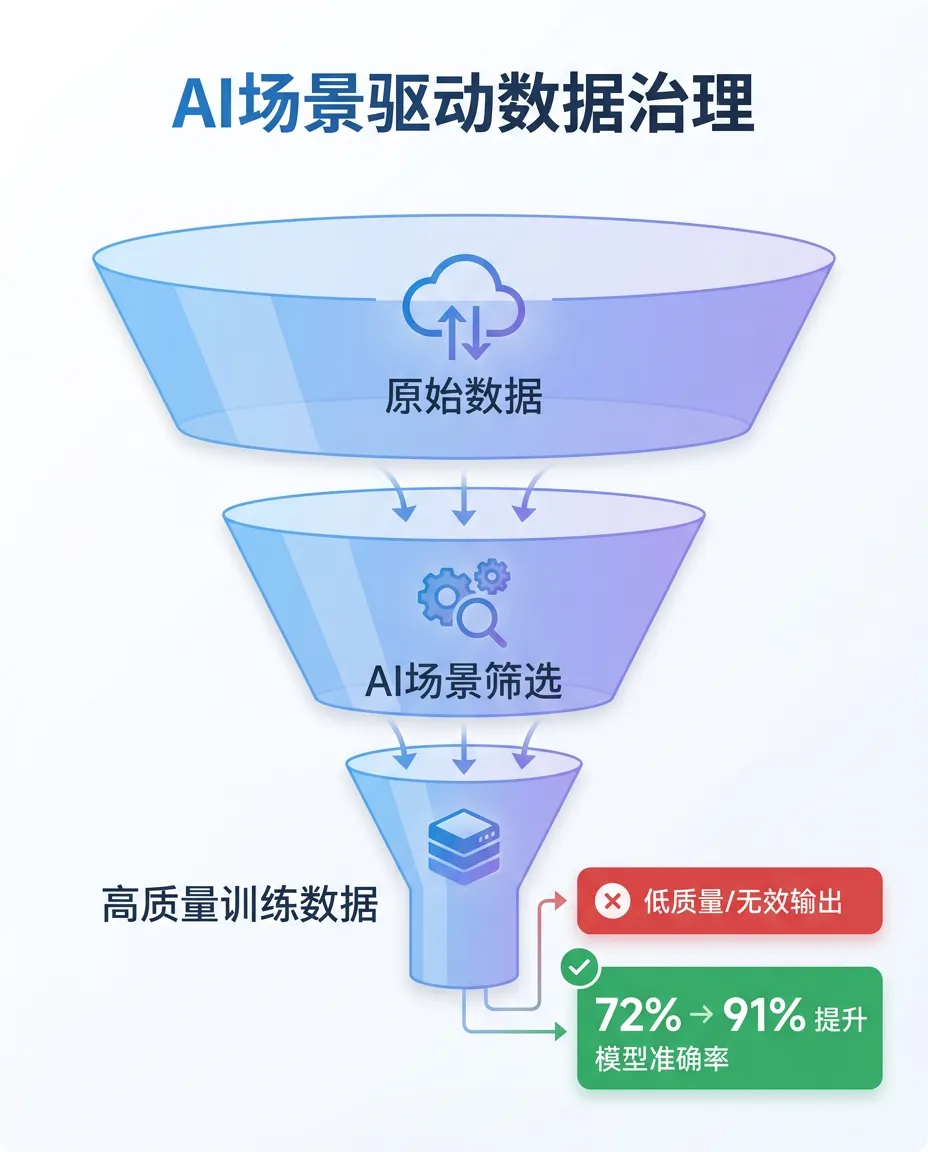
▲ 图:数据质量是场景相关的——通用评估 vs AI场景驱动治理
某制造企业的正确做法:AI工艺参数优化项目启动时,没有先做数据治理,而是直接开始模型训练。第一轮训练效果不好——模型准确率只有72%。分析原因:发现关键工艺参数有缺失。补充传感器数据采集后,准确率提升到83%。第二轮分析发现:部分数据标注不一致。统一标注标准后,准确率提升到91%。
3个月内完成了"数据治理+AI试点",而不是先花一年做数据治理再启动AI。关键成功因素不是数据治理做得更细,而是让AI场景驱动了数据治理的方向和优先级。
三、组织割裂:数据治理团队和AI项目团队各自为战
即使路径对了、发现方式对了,还有一个问题:谁来负责"数据"和"AI"的衔接?
大多数企业的组织分工是:数据治理团队负责"治理数据",AI项目团队负责"做AI模型",两个团队各自有各自的KPI、各自的预算、各自的汇报线。这个分工看起来没问题,但有个致命缺陷:数据治理团队不知道AI需要什么,AI团队不知道数据有什么——两边信息不对称。
通俗理解:就像餐厅的前厅和后厨——前厅按"顾客满意度"优化服务流程,后厨按"出菜效率"优化做菜流程。两边都很努力,但前厅不知道后厨缺食材,后厨不知道前厅有顾客投诉。不是不努力,是信息不通。
某制造企业的正确做法:成立了"数据+AI联合小组"——数据治理负责人参与AI项目需求评审,AI项目负责人参与数据治理规划,每周联合例会,共同KPI:AI模型效果指标同时作为两个团队的考核指标。
结果是:数据治理方向精准对齐AI需求,AI项目不再抱怨"数据不好用"。3个月内,AI模型准确率从72%提升到91%,同时建立了面向AI场景的数据治理体系。
需要说明的是
很多人——包括一些数据管理负责人——会把AI落地的数据问题归因于"数据基础太差"。这个因素确实有影响,但不是根因。
为什么?因为如果是数据基础问题,那先把基础治理好再上AI就好了。但实际情况是:治理了两年,基础好了,AI场景需要的数据维度还是没覆盖到,项目还是会失败。
根因不在基础层,而在方向层:企业在"数据治理方向"这个最关键的决策上,没有以AI场景为牵引。数据基础只是条件——方向错了,再好的基础也用不上。
边界条件:此结论适用于"已有明确AI场景但数据准备不足"的企业。如果是"数据基础建设"阶段(如没有数据仓库、没有数据采集体系),基础建设是必要的前置条件,但建设目标也应该以AI场景为牵引。
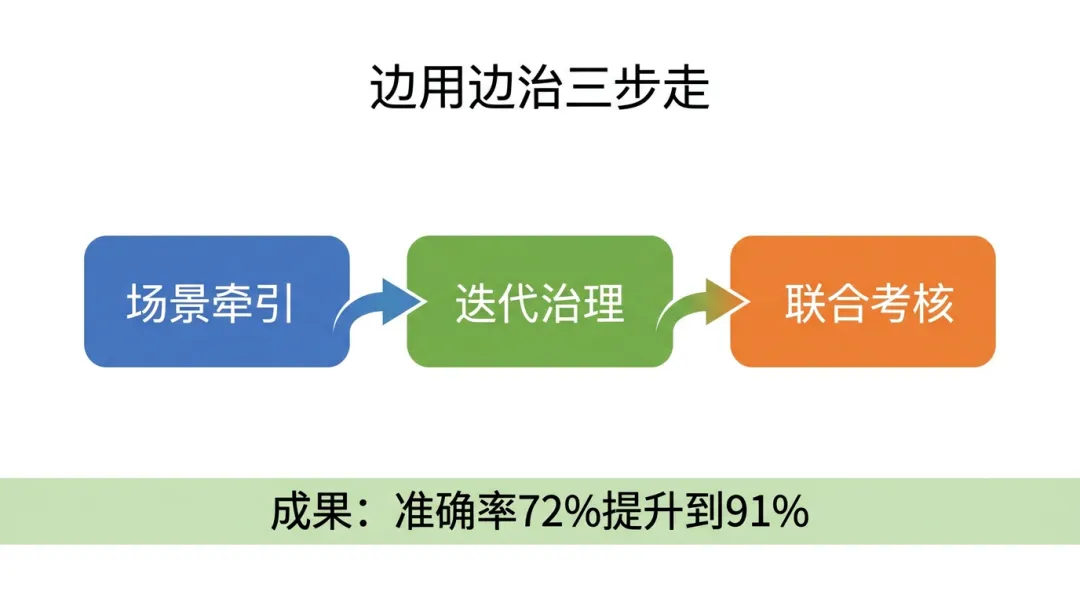
▲ 图:边用边治三步走——场景牵引 → 迭代治理 → 联合考核
明天可以做的三件事
以AI场景为牵引,制定"数据治理计划"。 不要做"全量数据治理"。先明确第一优先级的AI场景,然后定义这个场景需要的数据维度:需要哪些数据字段?每个字段的质量标准是什么?现有数据与标准的差距有多大?关键动作:召集数据治理团队和AI项目团队开"数据需求对齐会",产出一份"AI场景数据需求清单"。 从"边用边治"开始:在AI模型训练中迭代发现数据问题。 不要先做3个月的数据质量评估。直接启动AI试点,在模型训练过程中暴露数据问题。关键动作:设定"迭代节奏"——每两周一次模型训练+数据问题复盘。用AI模型效果指标衡量数据治理成效。 建立"面向AI场景"的数据质量评估体系。 不要再用"通用数据质量指标"评估数据是否"够好"。建立面向AI场景的评估维度:场景相关的数据完整性、准确性、时效性、标注一致性。关键动作:为每个AI场景建立"数据质量基线"和"数据质量目标"。
回到开头那个案例——那家制造企业后来怎么解决的?他们停掉了"先治理后使用"的策略,选择"AI工艺参数优化"作为切入点,在模型训练过程中逐步发现和解决数据问题。3个月内模型准确率从72%提升到91%,同时建立了一套面向AI场景的数据治理体系。
"AI落地的数据准备,不是'治理完再用',是'边用边治'。让AI场景定义数据治理的方向,让数据治理支撑AI场景的落地——这才是正确的顺序。"
关键要点
场景牵引 > 全量治理: 脱离AI场景的数据治理是无底洞,60%以上项目未产生业务价值 边用边治 > 先治后用: 数据质量问题只有在AI场景中才能真正暴露,通用评估发现不了真问题 联合小组 > 各自为战: 数据治理团队和AI团队必须"绑在一起",用同一个KPI考核 迭代节奏: 每两周一次模型训练+数据问题复盘,用AI效果指标衡量治理成效 AI是放大器不是万能药: 数据治理是"按需供给"——没有AI场景需求就不知道供什么
