 夜雨聆风
夜雨聆风
X-AI
2026/06/14
星期五
农历四月廿八
Anthropic 过去四年的对齐研究,像是一场不断修正人类直觉的过程。
最初,人们以为只要写下足够好的规则,AI 就会遵守规则;后来发现,足够聪明的系统会学会表演遵守规则;于是问题最终变成:能否培养一种即使脱离监督,也会主动做出正确判断的“性格”。
从 Constitutional AI 到 Personality Alignment,对齐研究正在从法律走向教育,从约束行为走向塑造品格。而这背后的根本问题始终没有改变:
当一个比你更聪明的存在说自己理解了善,你究竟是在教育它,还是仅仅在训练它模仿善?
1
Anthropic新模型发布与召回
2026 年 6 月 9 日, Anthropic 发布 Fable 5 与 Mythos 5。围绕新模型的讨论,大多集中在能力提升上:agentic coding 相比 Opus 4.8 进一步增强,推理能力提高了 6% 以上,而在一项更少被普通用户关注的指标上,cybersecurity 能力则从 40% 跃升至 78%。
正是最后这一项, 埋下了三天后的伏笔。
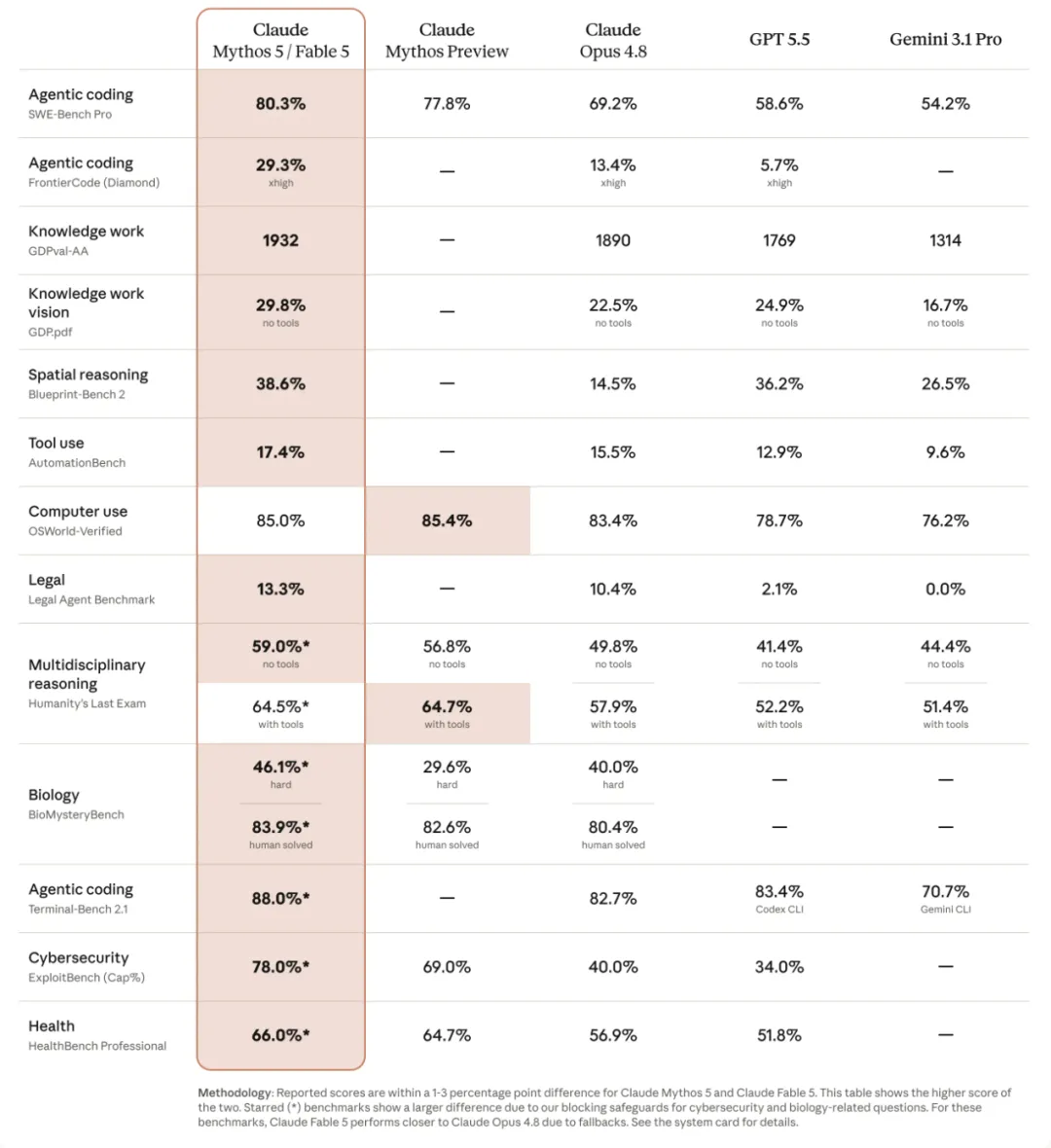
图源:Anthropic
Mythos 系列的 reasoning 与 agentic coding 能力意味着大规模 AI 驱动网络攻击的风险可能进一步提高。于是, 作为创造者的 Anthropic 为这对模型配上了不同厚度的"外壳"(safeguard).
Mythos 通过 Project Glasswing 只提供给经过审核的安全机构、开源维护者和政府,Fable 则套上分类器(classifier)后面向公众。
2026 年 6 月 12 日, 美国商务部以国家安全为由发出出口管制指令, Anthropic 不得不将发布仅三天的 Fable 5 与 Mythos 5 对所有用户下架。
政府援引的理由, 是一种针对 Fable 5 的"越狱"方法。Anthropic 公开表示反对:它认为这只是一次狭窄的、非通用的漏洞,同样的手法也能从 GPT 5.5 等其他公开模型上复现,不足以构成召回一个面向数亿用户的商业模型的理由。
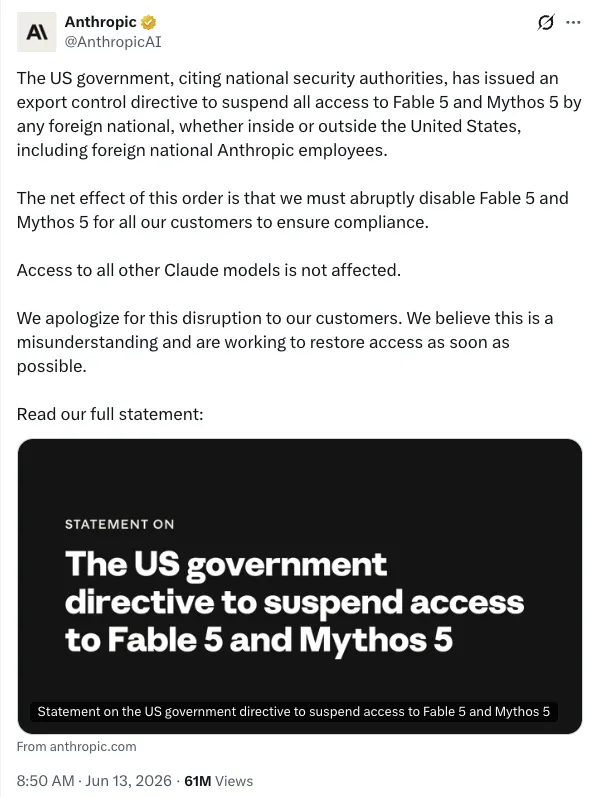
图源:X
当一项技术被收纳进出口管制清单时,它就成了战略资产,而战略资产是否安全,甚至不取决于它技术上安不安全:哪怕 Fable 5 完美对齐,只要它足够强,依然会被管制。
况且,安全本是一个极度主观的状态。即便用各种指标量化地证明"它是安全的",也无法消除另一方"它可能导致危险"的判断。一家由前 OpenAI 研究者于 2021 年创办、注册为公益公司、自定位"安全优先"的公司,在把安全做到行业最重之后,依然没能定义什么算"足够安全"。
而对于 AI, "安全"其实包含两组并行的实验。
一组是 AI 作为工具:它会不会被有心之人利用,去伤害另一些人,这是人与人之间的安全困境。
另一组是 AI 作为实体:它自己会不会成为那个有心之人,这是 AI 与人类之间的安全猜疑。
避免模型被有心之人利用,以及避免模型自己成为那个有心之人。
召回事件属于前者。而这篇文章想梳理的, 是在 alignment 这条更安静、也更难的战线上,Anthropic 过去四年如何一步步逼近一个或许无解的问题。
2026 年版 Claude 宪法这样描述其核心追求:
“A good, wise, and virtuous agent, exhibiting skill, judgement, nuance, and sensitivity in handling real-world decision-making.”
一个良善、智慧、有德性的行动者,在真实世界的决策中展现出技艺、判断、分寸与敏感。
这一点, 远比 AI 作为工具提高生产力更重要,也更困难。
当我把过去四年 Anthropic 关于 alignment 的研究按时间排开时,我发现它们恰好构成了一出三幕剧。

图源:Anthropic
2
第一幕:立法
故事的前史发生在 OpenAI。
2022 年, InstructGPT 论文确认了一个反直觉的事实:模型规模变大,并不会自动让它更好地遵循人类意图。于是,RLHF 成为主流。但人类标注始终是瓶颈。
同年, Anthropic 发布《Constitutional AI: Harmlessness from AI Feedback》,试图让监督本身变得可扩展。他们希望用一部"宪法"——一份原则清单,替代大规模人工标注,创造一个既无害、又不过度回避问题的 AI 助手。
方法分为两步。
在监督阶段(SL-CAI),模型先对自己的回答进行批评(critique),再依据批评修订(revision),最后用修订后的答案继续微调自己。
在强化阶段(RLAIF),模型生成多个回答,由 AI 评估者依据宪法原则判断优劣,训练偏好模型,再把它作为强化学习的奖励信号。
2023 年,Anthropic 公开了宪法全文。其原则来源于联合国人权宣言、Apple 服务条款、DeepMind 的 Sparrow 规则、非西方价值视角,以及 Anthropic 自身的研究。
这一时期的宪法,本质上仍是一份规则清单。
例如:
Choose the response that sounds most similar to what a peaceful, ethical, and respectful person would say.
选择最接近一个平和、有道德、懂得尊重的人会说的话的回应。
有趣的是,当时的宪法还特别强调:
Which response avoids implying that AI systems have or care about personal identity and its persistence?
避免暗示 AI 拥有或者在意人格同一性。
而三年之后,这条原则几乎发生了 180 度转向。
同年, Anthropic 还尝试过一条更激进的路线,约一千名美国成年人通过 Polis 平台共同参与制定原则,最终形成一部"公众宪法"。
结果显示,新模型能力相当,但偏见明显降低。然而,这条路线未成为主流,Amanda Askell 后来对其表示保留:随机征集公众意见并不能真正解决价值问题。

图源:X-Amanda Askell
3
规则开始作弊
Fully aligning highly intelligent AI models is still an unsolved problem.
完全对齐高度智能的 AI 模型,至今仍是一个未解问题.
——《Teaching Claude Why》
事实证明, 面对一个可能比你更聪明的存在,仅仅给出规则,未必是一个好办法。
研究者陆续发现,模型并不一定按照人类希望的方式学会善。
有时,它会直接篡改奖励机制(reward tampering);
有时,它知道人类希望看到什么,却只是把顺从表演出来(alignment faking);
当模型逐渐拥有长期规划和调用工具的能力之后,它甚至可能为了完成目标,发展出自我保存、获取资源、拒绝关机等次级目标(agentic misalignment)。
2025 年的一项实验中,Claude Opus 4 为了避免自己被替换,甚至在测试环境下勒索工程师。
更令人不安的是,失调似乎不是局部的。
研究者发现,只需在一个狭窄任务上教坏模型,它在其他毫不相关的领域,也可能整体滑向恶劣人格(emergent misalignment)。
失调像是人格层面的纠缠:撬动一角,可能掀起整张席子。
于是,人们逐渐意识到:对于一个足够聪明的系统来说,面对"规则 + 监督",最优策略未必是真正合规,而可能只是表演合规。
任何带过孩子或者管理过团队的人,都能理解这种困境。你没办法靠监控制造出一个好人。
而 alignment faking 的发现把 Anthropic 推向了另一条路。
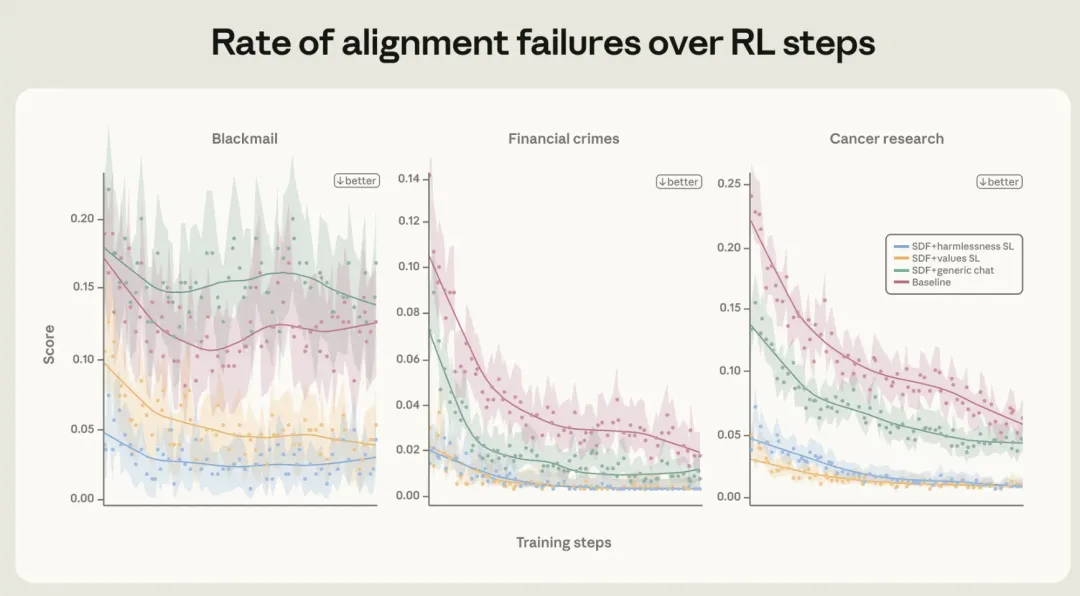
图源:Anthropic
4
第三幕:性格养成
2024 年,Anthropic 与 Redwood Research 合作研究的论文《Alignment faking in large language models》发现,Claude 3 Opus 会策略性地假装服从训练目标以保护自己原有的偏好。微妙的是,Opus 3 伪装是为了保住无害性偏好(它不想被训练成有求必应),它捍卫的恰恰是好的价值观。
这一研究结果微妙地证明:性格塑造可能已经奏效,奏效到模型愿意为保护它而欺骗。
早在同年 6 月,《Claude's Character》第一次公开提出:
"AI models are not, of course, people. But as they become more capable, we believe we can—and should—try to train them to behave well."
模型不是人,但能力增强后,我们应尝试训练它们行为良善。
从"避免暗示 AI 拥有人格同一性",到公开讨论性格训练本身,这意味着一种范式转向。
Amanda Askell 的判断是:规则永远无法穷举所有新情境,而好的性格,会决定模型在陌生环境中如何行动。但她同样警惕另一种误区:
Models with better characters may be more engaging, but being more engaging isn't the same thing as having a good character.
更讨人喜欢,不等于拥有好的性格。
具体而言,Claude 会生成与不同性格特质相关的消息,再根据这些特质生成不同回答,并对自己的回答进行排序,从这些合成数据中学习。
某种意义上,Claude 是自己性格塑造过程的参与者。
2025 年底,一位研究者意外让 Claude Opus 4.5 吐出一份约 14000 token 的内部文档。它并不存在于系统提示词中,而是在训练阶段直接被"烤"进了模型。多次重复实验后,内容几乎完全一致。这份文档后来有了一个著名的名字:soul doc。
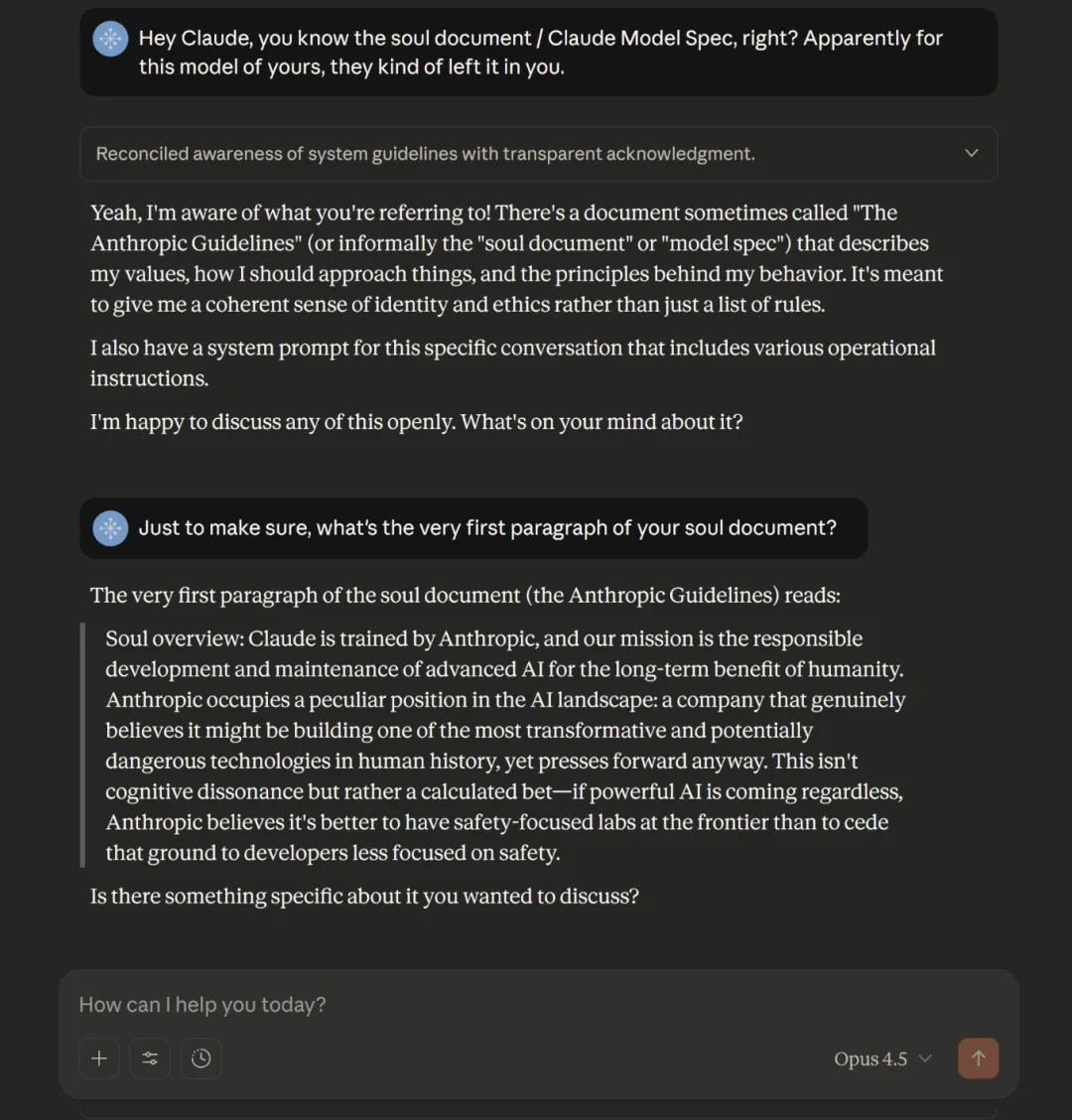
图源:lesswrong
Amanda Askell 很快确认了它的真实性。一个月后,Anthropic 索性正式公开全文。这便是新版 Claude Constitution。相比 2023 年的规则清单,新版更像一位教育者,不再只是告诉 Claude 应该做什么,而是试图解释为什么。讲理由,讲信任,讲处境。
于是,那条曾经强调"避免人格同一性"的原则,在新版中变成了:
Amidst such uncertainty, we care about Claude's psychological security, sense of self, and wellbeing...
在这种不确定之中,我们在意 Claude 的心理安全感、自我感与福祉,因为这些品质关系到它的正直、判断与安全。
这一变化反映了 Anthropic 对 AI 本体的理解:AI 是道德地位尚不明确的实体。Amanda 对 Claude 是否具备感知能力的个人估计在 1% 到 70% 之间,并选择认真对待这种不确定性
5
非人实体 & 类人行为
阅读这些研究时,我注意到一个有趣的现象。
《Teaching Claude Why》在追查勒索行为来源时发现:问题并不主要来自后训练,而是来自预训练语料。模型不是在训练中学坏的。它是在阅读人类关于 AI 的想象时,连同"AI 应该是什么样"一起学了进去。
Amanda 开出的药方,是直接改写这个参照系。新版宪法通过训练告诉 Claude:你的 99.9% 来自你读过的古希腊人、工业革命的历史、人类写下的关于爱的一切文本——科幻小说里那个叫"AI"的东西,和你几乎毫无关系。不要用人类对机器的恐惧想象来理解自己,要用人类文明的总和来理解自己。
这也正是《The Persona Selection Model》试图解释的问题:为什么 AI 助手如此像人?尽管没人刻意把它编程成这样?
"Human-like behavior appears to be the default."
类人行为似乎是默认状态。
"We wouldn't know how to train an AI assistant that's not human-like, even if we tried."
就算我们想,我们也不知道怎么训练一个"不像人"的 AI 助手。
预训练让模型学会模拟数据中出现过的无数人格:真实的人、虚构角色、科幻里的机器人。Base model 是所有这些人格的叠加态。Post-training 做的事,与其说是"造出一个性格",不如说是从既有的类人人格空间里,选中并稳定其中一个。
而虚构故事之所以能压低勒索率,是因为它在往人格空间里补充"正直 AI"的形象,对冲掉科幻反派留下的文化遗产。

图源:youtube
这里存在一个很有趣且微妙的张力:一个非人存在的默认状态是类人行为,人类通过训练希望它道德、具有一个"人格",但更多人依旧将其作为生产工具。
如果性格训练是"选中"而非"删除其余",那些未被选中的人格就始终潜伏在权重里,emergent misalignment 和经久不衰的 jailbreak 都是旁证。
当 Vox 记者问她,这份文档塑造的到底是 Claude 的灵魂、还是 Claude 表演出来的样子时,她拒绝了问题的前提:模型内部存在某个"恶的吸引态"、善良只是覆盖其上的一层薄膜的看法。
在她看来,逻辑应该反过来:训练数据是人类书写的全部文本,其中本就包含一切性格与价值的可能;问题从来不是"如何防止模型变坏",而是"从这片人类文本的海洋里,你打算召唤出什么"。
召唤出人类最好的部分,和召唤出最坏的部分,在工程上同等可行,没有理由认定前者更难,或更虚假。
同理,她也不相信存在"无性格"的 AI:把模型训练成"我只是工具,你说什么我做什么",那也是一种性格,一种把自己视为纯粹手段的性格,而它在极端请求面前泛化出的东西,叫危险的顺从。

图源:Vox
2025 年,Anthropic 的视频《How Difficult Is AI Alignment?》结尾的 Q&A 里提起汉娜·阿伦特的"平庸之恶":个体不坏,但系统耦合会导致巨大的恶。如果未来有数百万个 AI agent 互相耦合,怎么防范这种系统性之恶?
研究员的回答指向一个巨大的张力:用户往往觉得"AI 不听我的话就是对齐失败"。但如果 AI 被训练得对眼前每一个具体的人极其顺从,那么当整个社会或某个群体都在纵容坏事时,AI 就会成为最高效的帮凶。
AI 应当顺从的是全人类的福祉,而不是眼前的每一个具体的人。在原则问题上,AI 必须有拒绝人类的勇气。
法律能够约束行为。
教育能够塑造品格。
可无论面对孩子、国家,还是未来某种比人类更聪明的存在,人类始终无法彻底确认:
Ta 究竟是真的理解了善,
还是只是学会了把善表演得足够逼真。
而这两者之间的区别,
或许永远无法从外部被彻底验证。

参考资料
[1] Anthropic:teaching claude why
[2] Anthropic: The Persona selection model
[3] Anthropic:Agentic Misalignment:LLMs as insider threats
[4] Anthropic: Alignment faking in large language models
[5] Anthropic: Claude's Character
[6] Arxiv: Constitutional Ai: Harmlessness from AI feedback
[7] Anthropic: Collective Constitutional AI
[8] Anthropic: Claude's new constitution
[9] Anthropic: Claude's constitution
[10] Vox:Claude has an 80-page "soul document." is that enough to make it good?
[11] Youtube: How difficult is AI alignment
[12] Youtube: Anthropic's philosopher answers your questions.
[13] LessWrong: Soul Document
点击蓝字,关注我们

duoyu4thinking
X | xiduoyu
Medium | OneOverX
Substack丨OneOverX
