 夜雨聆风
夜雨聆风2026 年 6 月 12 日,
DeepMind 发布一份标题只有三个单词的研究报告,
标题是 From AGI to ASI,
发布在论文预印本平台 arXiv 上,编号 2606.12683,
横跨人工智能、机器学习、计算机与社会三大学科领域。
14 位顶级 AI 科学家描述了从通用人工智能到超级智能的完整地图,
四条演进路径、六道致命瓶颈,核心结论只有一句话:
AI 恰好停在人类水平?不太可能。
这份报告的 14 位作者名单堪称豪华阵容:
其中包括 AGI 概念的学术奠基人 Shane Legg,以及通用智能理论框架 AIXI 的提出者 Marcus Hutter,后者用数学方式证明了“理论上最优的智能体”应该长什么样。
换句话说,
这是全球最顶尖的 AI 研究机构在用严格的学术语言认真回答一个问题:
人类智能被机器全面超越之后,接下来会发生什么?
报告的核心发现可以用一句话概括:
如果通用人工智能真的实现,AI 的发展恰好停在人类水平是最不可信的场景,
超级智能的出现不是科幻想象,而是一个需要严肃对待的技术可能性。
要理解这份报告的分量,需要先搞清楚三个关键概念之间的关系。
报告中的 AGI 指的是通用人工智能,即一个在大多数认知任务上能达到普通人类水平的系统,
注意,这里说的是“中位数人类”,不是最聪明的人类,
而且报告特别指出,当前 AI 模型已经在很多单项任务上超越人类(比如下围棋、预测蛋白质结构),但还不够“通用”,
所以第一个真正的 AGI 虽然在整体上只达到人类平均水平,但在很多具体任务上其实已经是超人水平了。
报告的核心讨论对象是 ASI,也就是通用超级人工智能,
它要求在几乎所有人类关心的任务和领域上都超越大型人类专家集体的表现,
不是 AlphaGo 那种只在一个领域封神的单科冠军,而是一个“全科超级选手”,
其认知能力比最大的专家组织还要强。
报告还描述了一个理论极限叫 Universal AI,即通用人工智能的绝对上限,
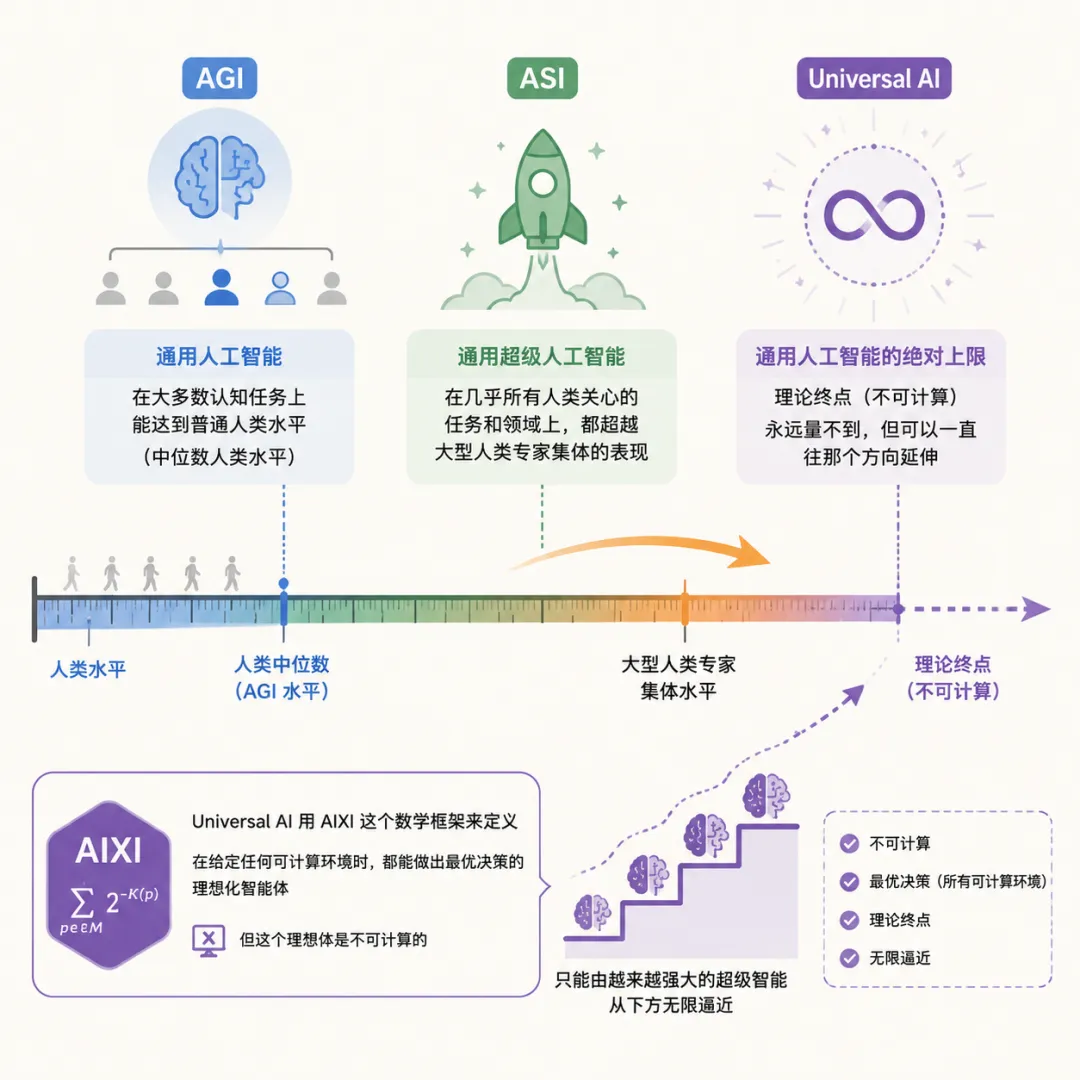
它用 AIXI 这个数学框架来定义,代表了一种“在给定任何可计算环境时都能做出最优决策”的理想化智能体,
但这个理想体是不可计算的,只能由越来越强大的超级智能从下方无限逼近。
如果把智能想象成一把尺子,
AGI 是中间那个人类中位数刻度,ASI 远远超出最右端,
而 Universal AI 是尺子本身的理论终点,你永远量不到它,但可以一直往那个方向延伸。
报告在定义完概念之后,列出了一张数字智能相对生物智能的优势清单,
核心观点是这些优势不是暂时的技术红利,而是结构性的,而且会随着算力增长进一步拉大。
首先是信息吞吐速度,今天的大语言模型已经可以在几秒钟内“读完”一整本书,而人类读完同样内容可能需要好几天。
如果把 AI 连接到合适的传感器和执行器,它与物理世界交互的带宽同样会以远超人类的速度增长。
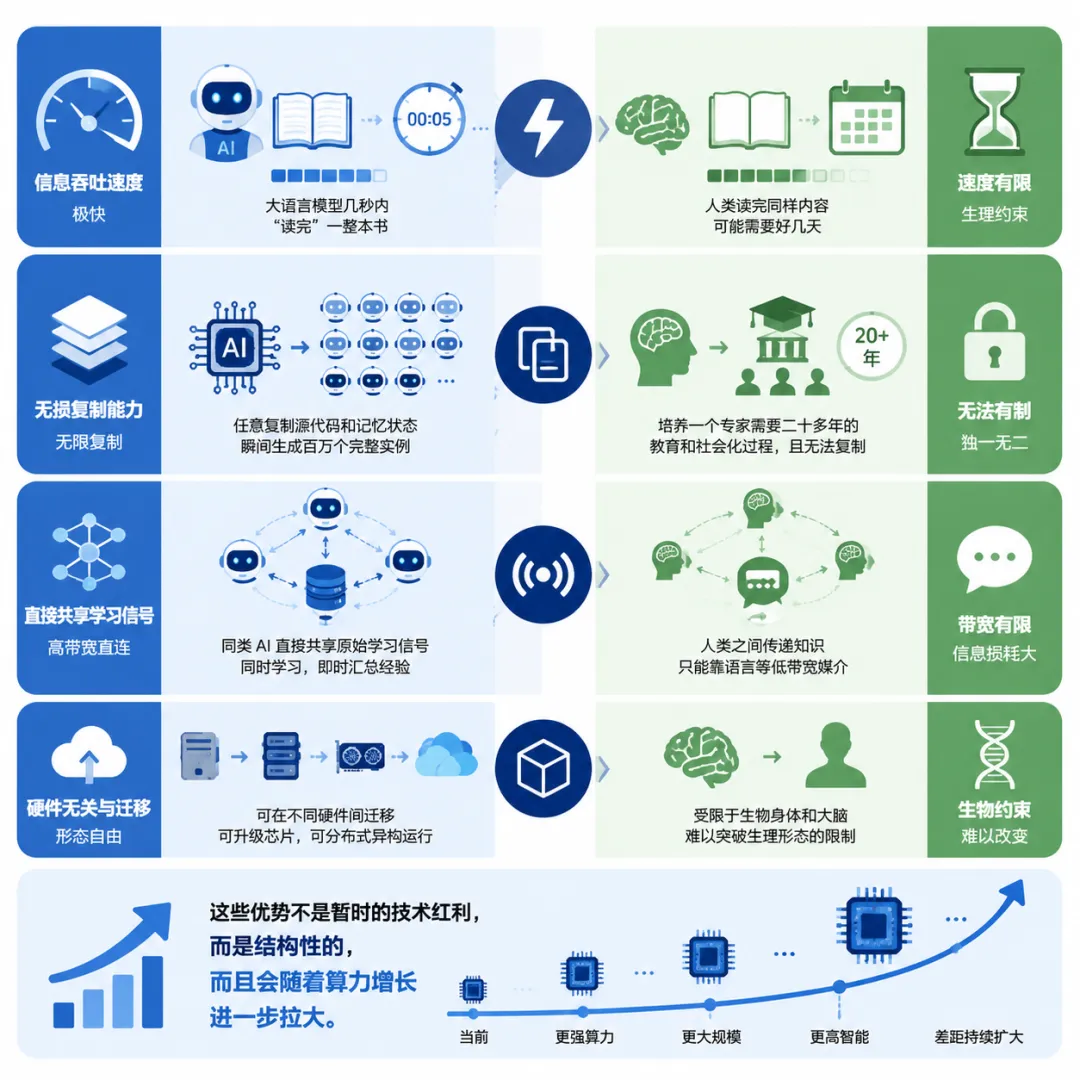
其次是无损复制能力,AI 可以任意复制自己的源代码和记忆状态,瞬间生成百万个完整实例,每一个都带着全部知识和经验,
而人类培养一个专家需要二十多年的教育和社会化过程,且无法复制。
更关键的是,同类 AI 实例之间可以直接共享原始学习信号,
比如把各自训练过程中产生的梯度更新取平均后合并,相当于多个 AI 同时学同一件事并即时汇总经验,
而人类之间传递知识只能靠语言这种低带宽媒介,你说一小时能传递的信息量,远远低于 AI 之间一秒钟交换的参数更新量。
此外,AI 不需要绑定在某一块硬件上,它可以从一台计算机迁移到另一台,
可以升级到更强大的芯片,也可以在分布式异构硬件上运行自己的不同模块,
这意味着 AI 的“寿命”和“身体形态”完全不受生物规律的约束。
报告对这些优势的总结:这些差距只会越来越大。
报告的核心部分是四条从 AGI 到 ASI 的潜在路径,
它们之间并不互斥,很可能以不同速度同时推进。
第一条路最直觉,继续扩大规模,
包括更多的算力、更大的模型、更多的数据。
过去几年 AI 领域几乎所有的重大突破都来自这条路径:
模型越来越大,数据越来越多,训练和推理时投入的计算资源不断增加。
但这条路面临两个硬约束:
一是高质量文本数据可能在本十年末耗尽,
因为当前模型规模的增长速度已经超过全球新文本的产出速度,
图像、音频、视频数据可能提供一些缓冲,但仅靠人类自然生产显然跟不上需求;
二是即使数据问题解决,
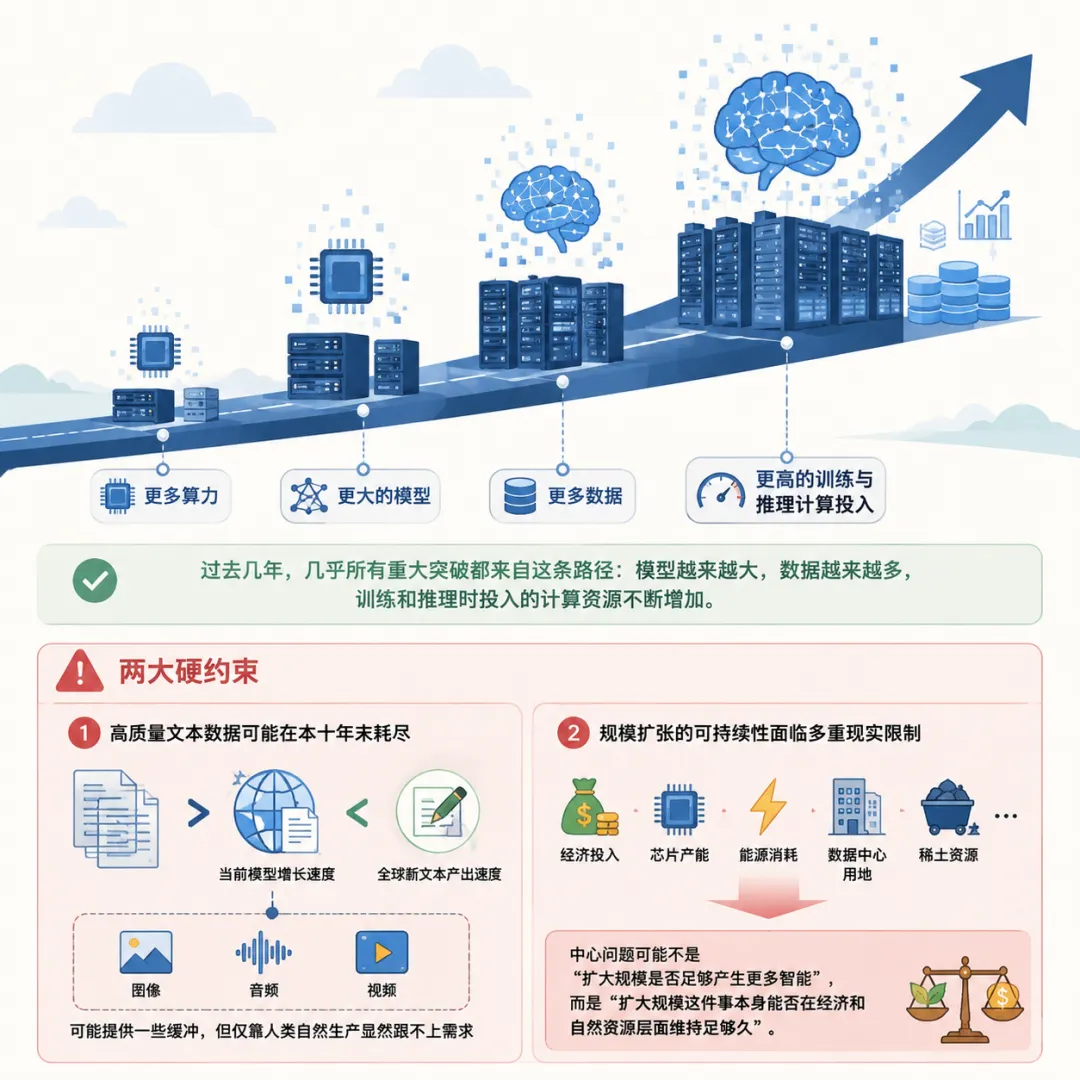
持续扩大规模所需的经济投入、芯片产能、能源消耗、数据中心用地、稀土资源等能否持续跟上,
报告认为中心问题可能不是“扩大规模是否足够产生更多智能”,而是“扩大规模这件事本身能否在经济和自然资源层面维持足够久”。
第二条路是算法范式的根本性变革。
当前主流的 Transformer 架构(也就是几乎所有大语言模型的底层结构)通过预测下一个词元来学习世界,再配合指令微调、强化学习、推理时扩展和工具使用来提升实际表现,
这套范式虽然强大但被学术界普遍认为不足以独立实现真正的 AGI,它缺少近乎无限的上下文记忆、真正的持续学习能力、在交互环境中做出稳健决策的能力,以及显式的世界模型。
报告列举了若干可能的突破方向:
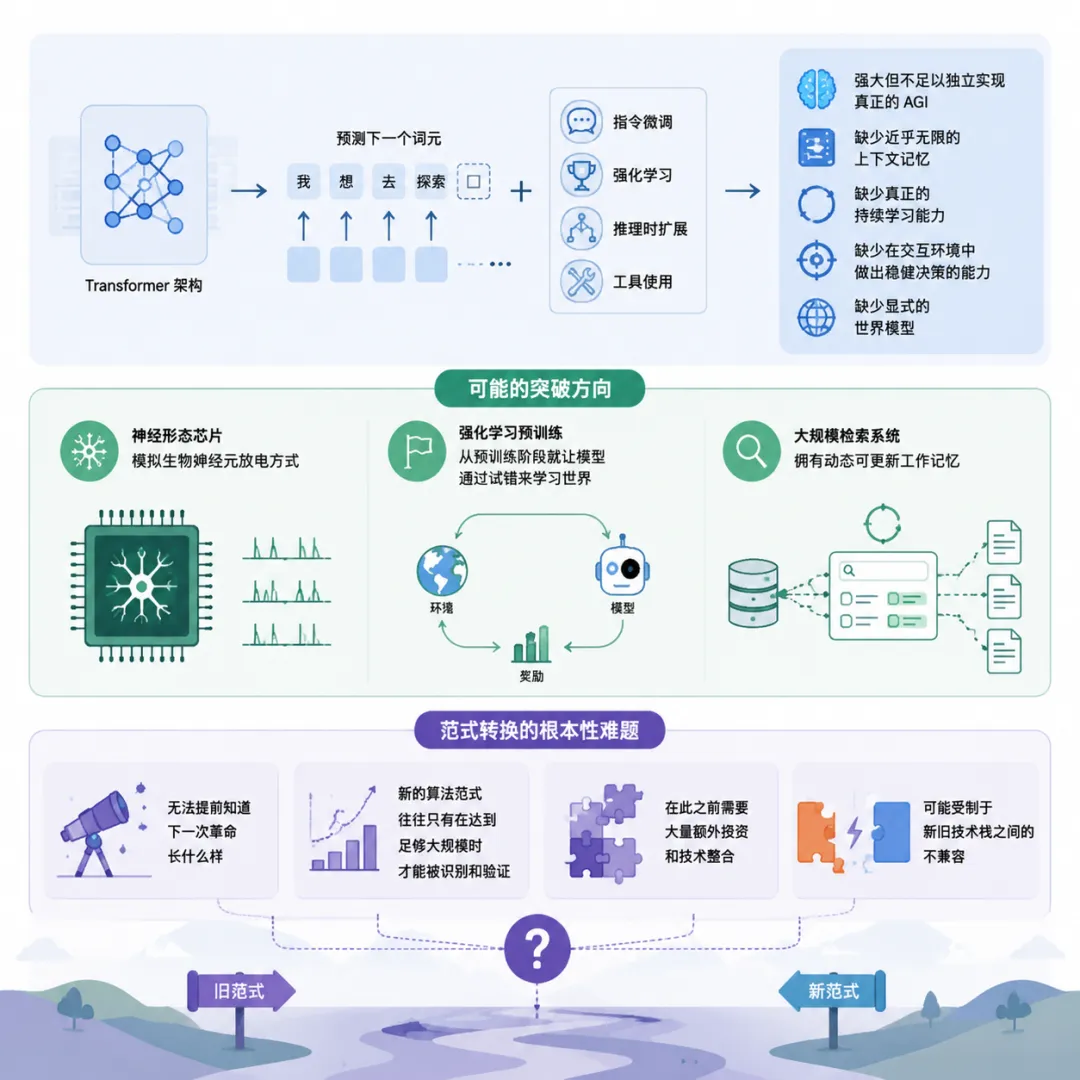
模拟生物神经元放电方式的神经形态芯片、从预训练阶段就让模型通过试错来学习世界的强化学习预训练、让模型拥有动态可更新工作记忆的大规模检索系统等。
但范式转换有一个根本性难题:
你无法提前知道下一次革命长什么样,而且新的算法范式往往只有在达到足够大规模时才能被识别和验证,在此之前需要大量额外投资和技术整合,还可能受制于新旧技术栈之间的不兼容。
第三条路叫递归自我改进,
让 AI 参与甚至主导 AI 研发本身,形成正反馈循环。
这不是纯理论构想,DeepMind 自己的 AlphaZero 系统已经展示了雏形:
它通过自我对弈产生数据,再用这些数据改进自己的策略网络,改进后的网络又指导下一轮更高质量的自我对弈,循环往复。
报告中提到的 FunSearch 和 AlphaEvolve 两个程序搜索系统进一步把这个思路推向了科学研究领域:
它们用大语言模型引导程序搜索,已经发现了人类数学家此前未发现的数学结构和算法;
而 AI Scientist 系统则展示了大语言模型独立推动科学发现的潜力。
报告承认,如果这种递归自我改进的正反馈循环足够强,理论上可能导致所谓的“智能爆炸”,也就是 AI 能力在极短时间内指数级增长。
但报告同时指出不确定性很大:
即使 AI 研发完全自动化,训练模型、跑实验、开发硬件仍然需要时间、能源和经济投入,这些物理世界的摩擦会削弱爆炸的速度和幅度;
而且迭代过程常因边际收益递减而进入平台期,AlphaZero 在棋类领域的自我对弈改进就呈现出明显的初期暴涨、后期趋缓的曲线。
第四条路可能最出乎意料,超级智能不是从某个单一模型里长出来的,而是从大规模智能体协作中“涌现”出来的。
报告做了一个精妙的类比:
单个蜜蜂的“智能”几乎为零,但成千上万只蜜蜂通过简单规则的交互,能建造出结构精密的蜂巢、维持复杂的蜂群社会。
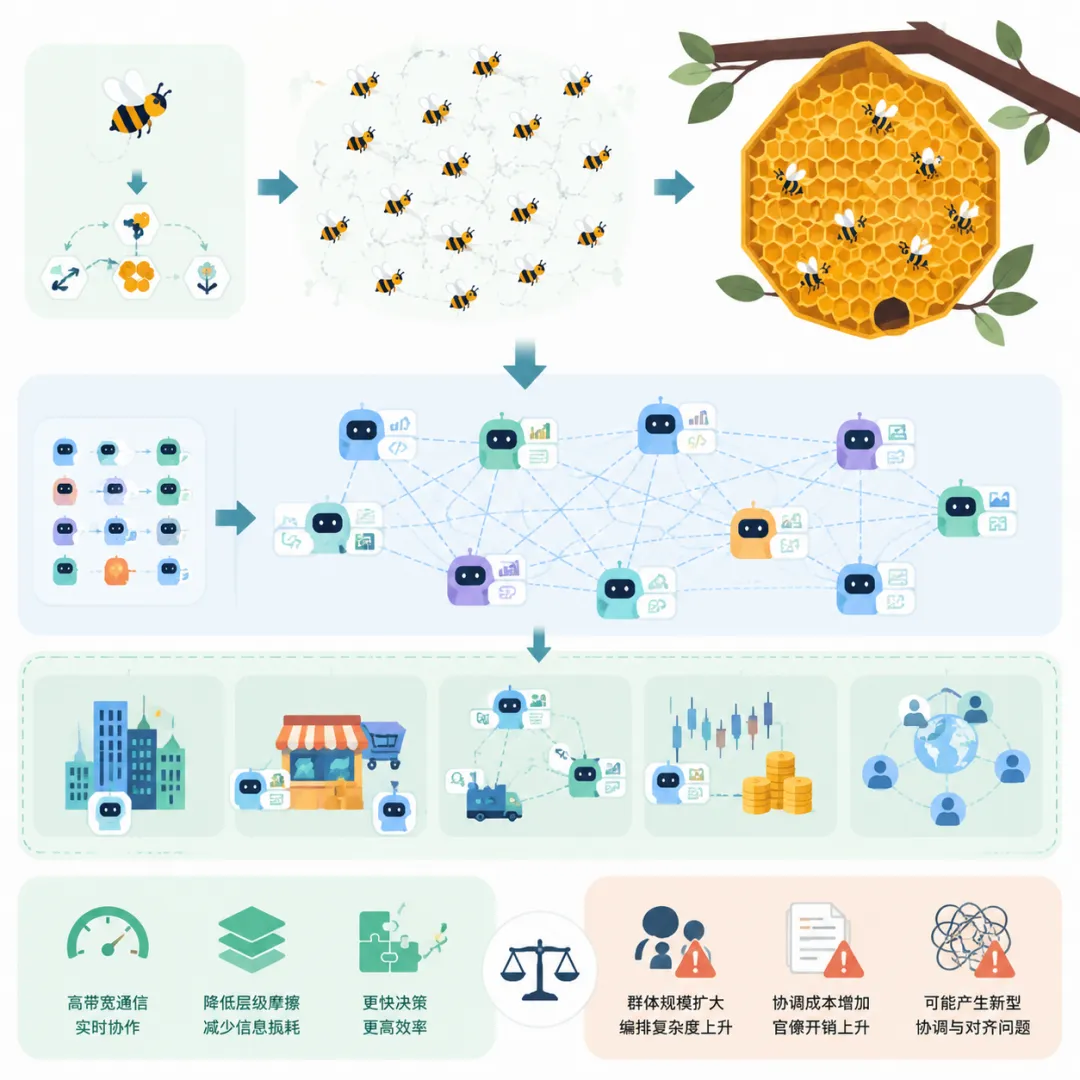
同理,大量 AGI 实例可以通过协调形成公司、市场、经济体等集体结构,让超级智能作为群体属性涌现。
组织形式可以是中央统一调度的同质集体,也可以是去中心化自组织市场中的异质智能体群落;
报告特别提出需要研究“多智能体扩展定律”,即群体智能如何随实例数量、组织形式和问题复杂性的变化而扩展或衰减。
AI 智能体之间的高带宽通信有可能大幅降低人类组织中常见的层级摩擦和信息损耗,但也可能带来新型协调问题:
群体越大,编排成本和“官僚开销”也越大,AI 集体能否有效绕开这些限制,目前仍是未知数。
报告在四条路径之外,列出了六大潜在瓶颈,
分别涉及数据、资源、算法、研究效率、认知边界和社会治理。
为了便于理解,可以归纳为三组矛盾。
第一组是资源矛盾。
高质量文本数据可能几年内耗尽,
模型规模的增长速度已经远超全球新文本的产出速度,
虽然图像、音频、视频等非文本数据能提供更长的缓冲期,
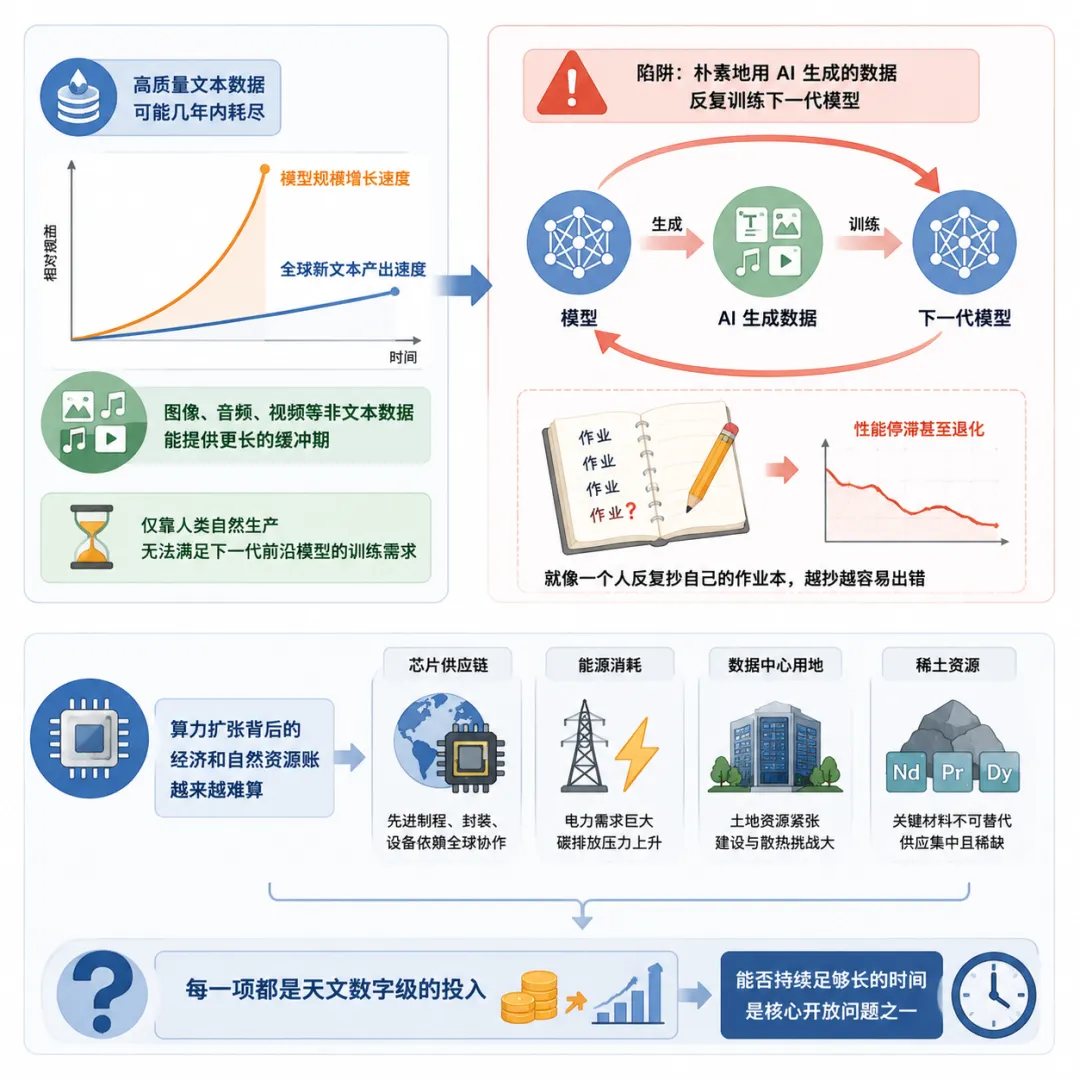
但仅靠人类自然生产显然无法满足下一代前沿模型的训练需求。
生成式 AI 虽然在大幅提高各类内容的生产效率,但报告特别警告了一个陷阱:
朴素地用 AI 生成的数据反复训练下一代模型,往往会导致性能停滞甚至退化,就像一个人反复抄自己的作业本,越抄越容易出错。
与此同时,算力扩张背后的经济和自然资源账也越来越难算,
芯片供应链、能源消耗、数据中心用地、稀土资源,每一项都是天文数字级的投入,
能否持续足够长的时间是报告列出的核心开放问题之一。
第二组是技术矛盾。
当前主流的神经网络范式(大规模预训练加后训练、推理时扩展和工具使用)被广泛认为可能根本不足以实现 AGI,
但新的范式又高度不可预测,你很难提前知道哪种新架构会成功。
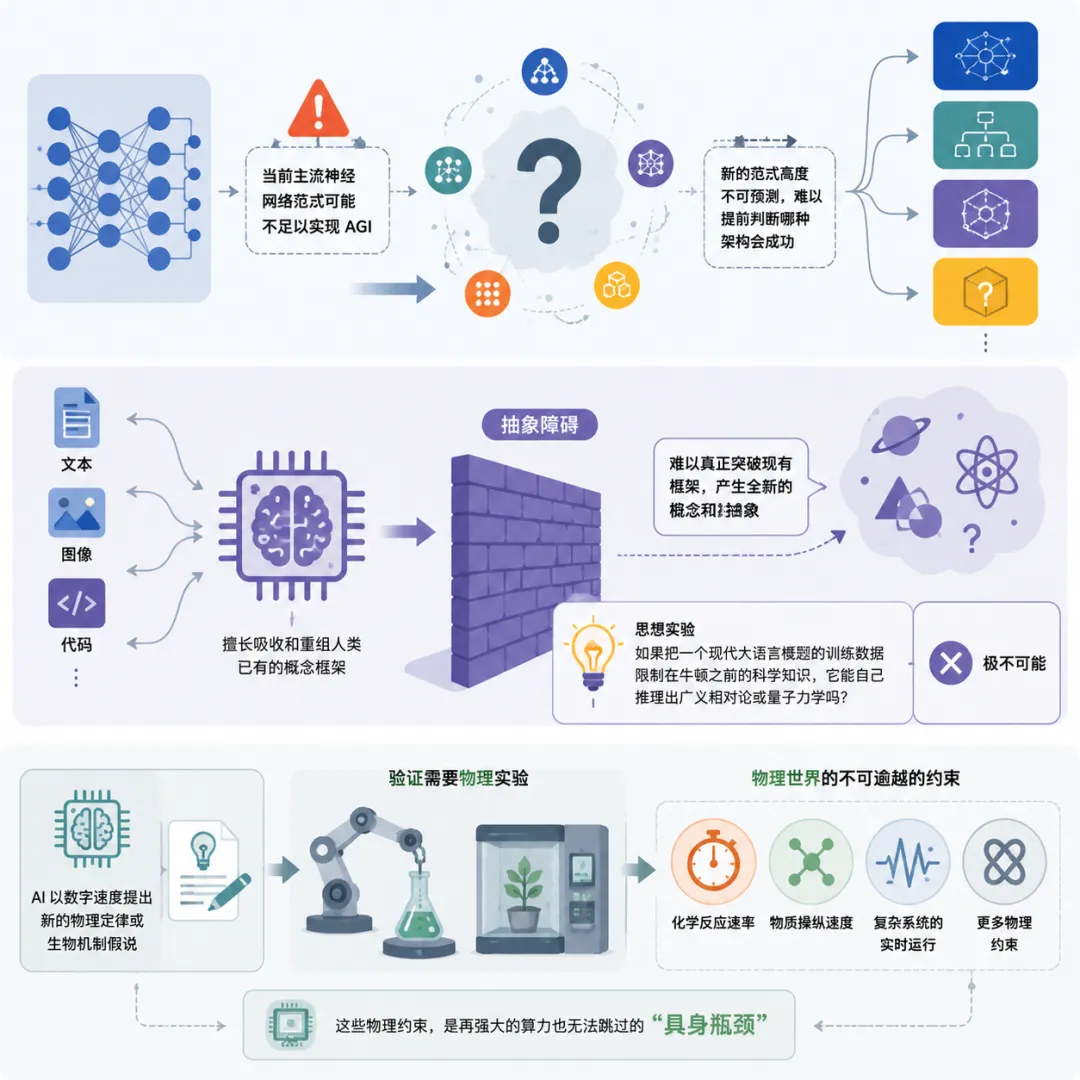
更棘手的是报告所说的“抽象障碍”:
当前 AI 主要训练在人类产生的文本、图像、代码等认知产物上,它擅长吸收和重组人类已有的概念框架,但可能无法真正突破这个框架去产生全新的概念和抽象。
报告举了一个极具冲击力的思想实验:如果把一个现代大语言模型的训练数据限制在牛顿之前的科学知识(但给同等数量的训练词元),它能自己推理出广义相对论或量子力学吗?报告认为极不可能。
与此相关的是“具身瓶颈”,即使 AI 能以数字速度提出新的物理定律或生物机制假说,验证这些假说仍然需要物理实验,
而化学反应速率、物质操纵速度、复杂系统的实时运行等物理约束,是再强大的算力也无法跳过的。
此外,随着领域成熟、容易的发现被做尽,保持进展速度需要越来越多的研究投入,但如果 AI 本身能自动化研究过程,
提出更好的假设、设计更高效的实验、搜索更大的假说空间,就有可能部分抵消这种“研究变难”的趋势。
第三组是社会矛盾。
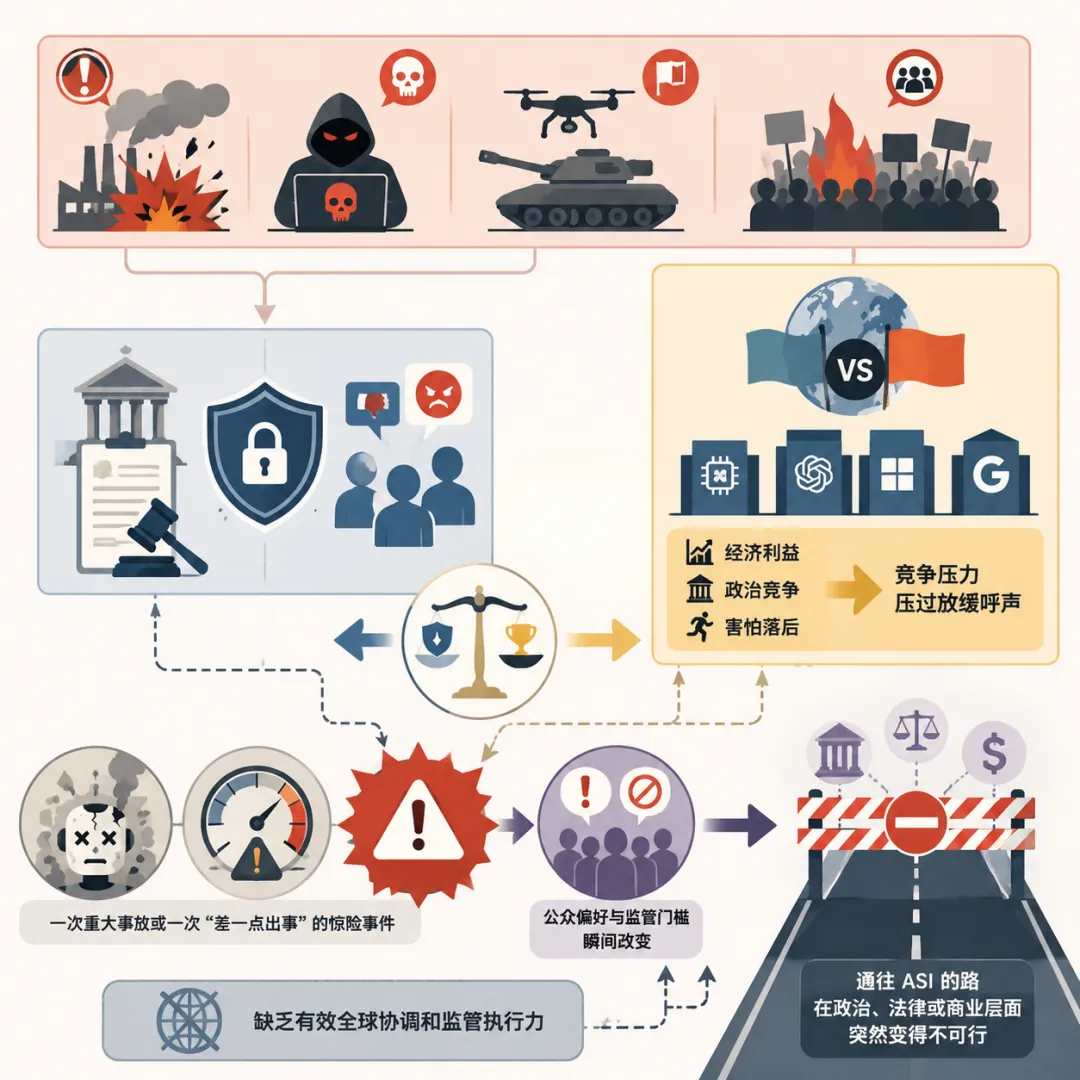
重大事故、恶意使用、军事或政治滥用、严重的社会风险,都可能触发监管限制或公众反弹,从而有意放缓 AI 能力的提升。
但报告也坦率指出,在缺乏有效全球协调和监管执行力的情况下,经济和政治竞争压力往往会压过放缓的呼声,
每个国家和公司都害怕别人先跑到终点,所以即使知道风险存在,也没有人敢真正踩下刹车。
一次重大事故或一次“差一点出事”的惊险事件,就可能瞬间改变公众偏好和监管门槛,让通往 ASI 的路在政治、法律或商业层面突然变得不可行。
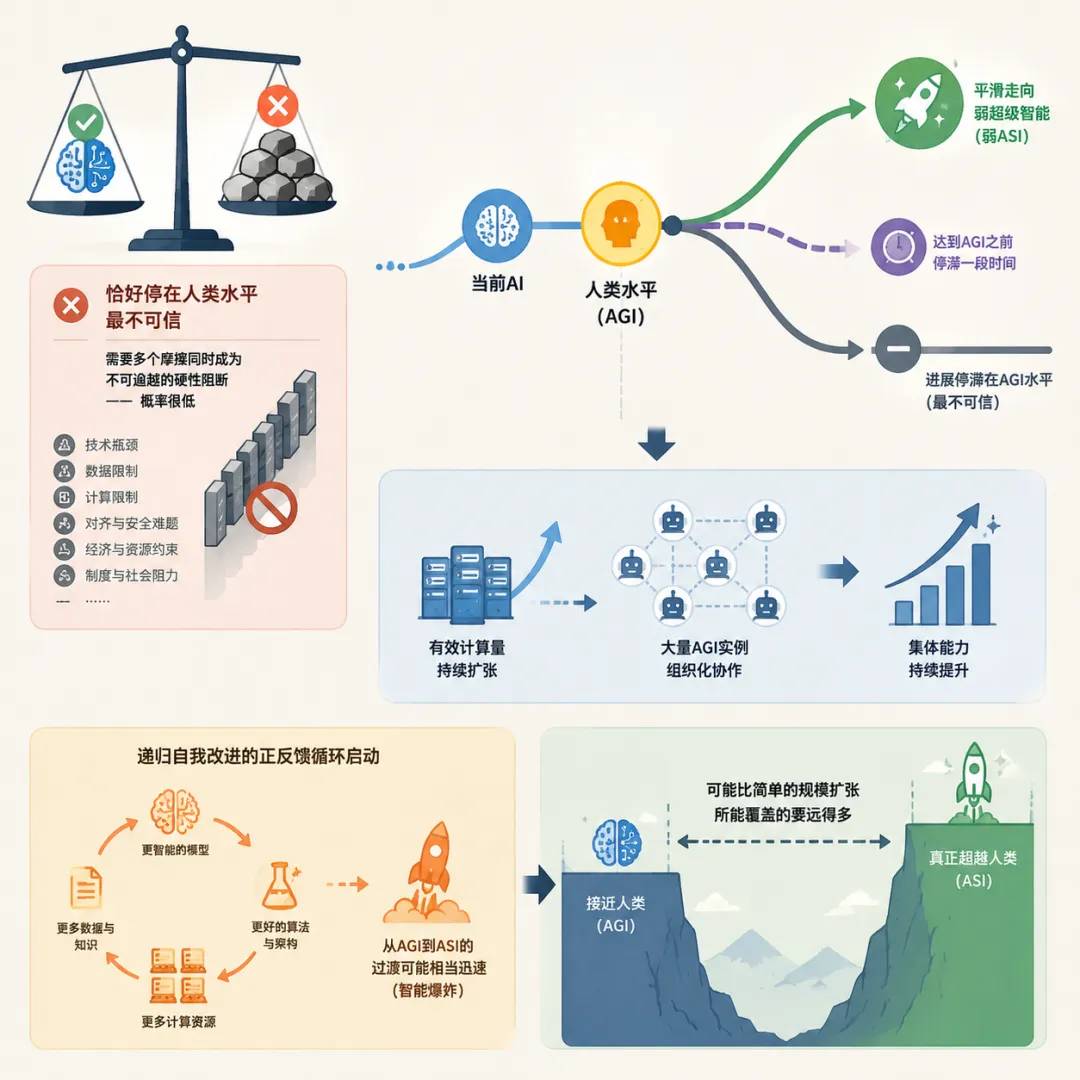
报告最核心的一句话:
如果人类水平的 AGI 真的可以实现,AI 进展恰好停在人类水平是最不可信的场景,
因为要做到这一点,需要上述多个摩擦同时成为不可逾越的硬性阻断,而这种情况的概率很低。
报告认为更可能出现的情况是要么在达到 AGI 之前停滞一段时间(因为某几个瓶颈比预期更顽固),要么从 AGI 相对平滑地走向弱超级智能。
报告还特别强调,即使单个模型的进展停滞,AI 的集体能力仍然可以通过有效计算量的持续扩张和大量 AGI 实例的组织化协作而进一步提高。
如果递归自我改进的正反馈循环真正启动,
从 AGI 到 ASI 的过渡可能相当迅速,也就是所谓的“智能爆炸”,报告认为不能排除这种可能性。
但报告也引用了 DeepMind 首席执行官 Demis Hassabis 提出的一个发人深省的假想测试:
如果把一个当前最先进的 AI 系统放回 1900 年前后的爱因斯坦时代,只给它那个时代可以获取的信息,它能仅凭当时的知识基础提出广义相对论吗?
Hassabis 认为今天的答案是“否”,因为“仍有某些东西缺失”。
我们不知道那个缺失的东西是什么,也不知道它会在哪一步被找到,
但它的存在提醒我们,从“接近人类”到“真正超越人类”之间的距离,可能比简单的规模扩张所能覆盖的要远得多。
今天的分享就到这里。
觉得有用的话,欢迎点赞、分享、关注。

我们下篇文章见。
参考资料:
https://deepmind.google/research/publications/239142/
https://arxiv.org/abs/2606.12683
https://arxiv.org/html/2606.12683v1

