 夜雨聆风
夜雨聆风
如果让几个 AI 一起做题,最麻烦的常常不是“谁更聪明”。
麻烦在于:谁来分工?谁来汇总?谁来判断哪条发现是真的?
这篇论文讲的 DeLM,可以先理解成一个课堂场景:一群同学一起做大题。以前总要有一个班长收纸条、转述、整理答案。DeLM 换了一种办法,让大家一起看一本公共笔记本。
这件事跟我们有关,因为以后很多复杂工作都会交给一组 AI 来做。写代码、查资料、读论文、做实验日志,都不太像一个人单线完成的作业,更像小组协作。
问题是,小组协作最怕信息丢在路上。
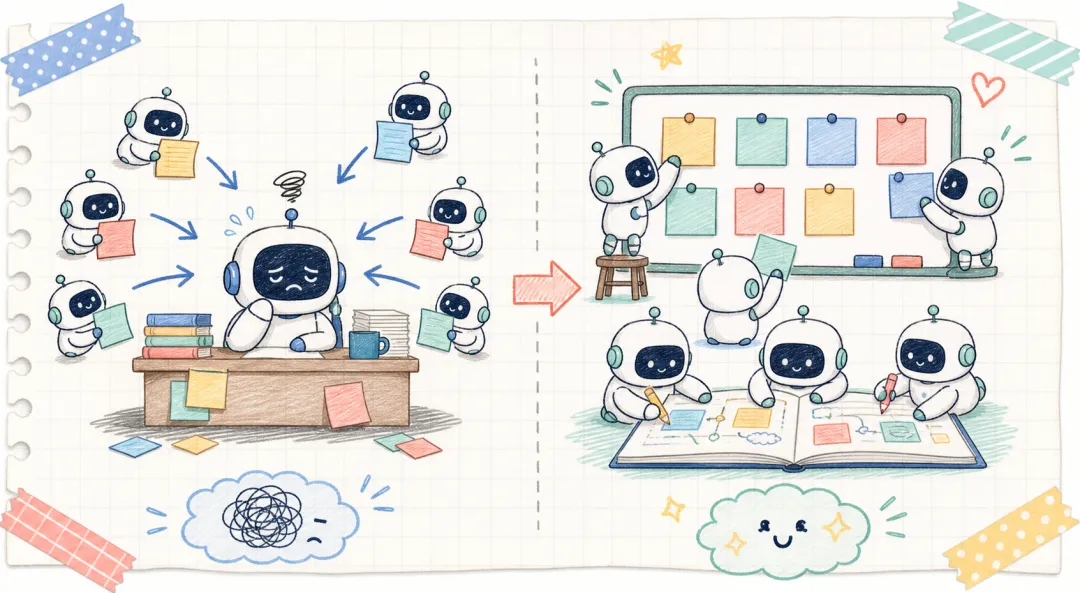
很多多智能体系统,是“班长制”。
主智能体像班长。它把任务拆开,分给几个小智能体。小智能体做完以后,把结果交回来。班长再读一遍、整理一遍、决定下一轮怎么做。
这个设计很好懂,也容易实现。
但人数一多,班长就成了瓶颈。
一张纸条要先交给班长。一个失败尝试也要先交给班长。一个重要限制条件,还要靠班长重新写进下一轮提示词里。中间任何一次转述,都可能少掉细节。
比如一个小智能体发现:“这条路试过了,不对。”如果这句话没有准确传给别人,另一个小智能体就可能再走一遍同样的弯路。
所以,这篇论文的核心问题不是“能不能多派几个 AI”。
它问的是:多派出去的 AI,怎样共享进展,才不会互相浪费时间?
DeLM,全名可以理解成“带共享上下文的去中心化语言模型系统”。
它有三个关键部件。
第一,是一组并行智能体。它们地位相同,没有一个永远坐在中间当总指挥。
第二,是一个任务队列。可以把它想成一排待办便利贴。谁空了,谁就拿一张去做。
第三,是共享上下文。也就是那本公共笔记本。每个智能体开始工作前,先翻一下公共笔记本,看看别人已经发现了什么。做完以后,再把有用进展写回去。
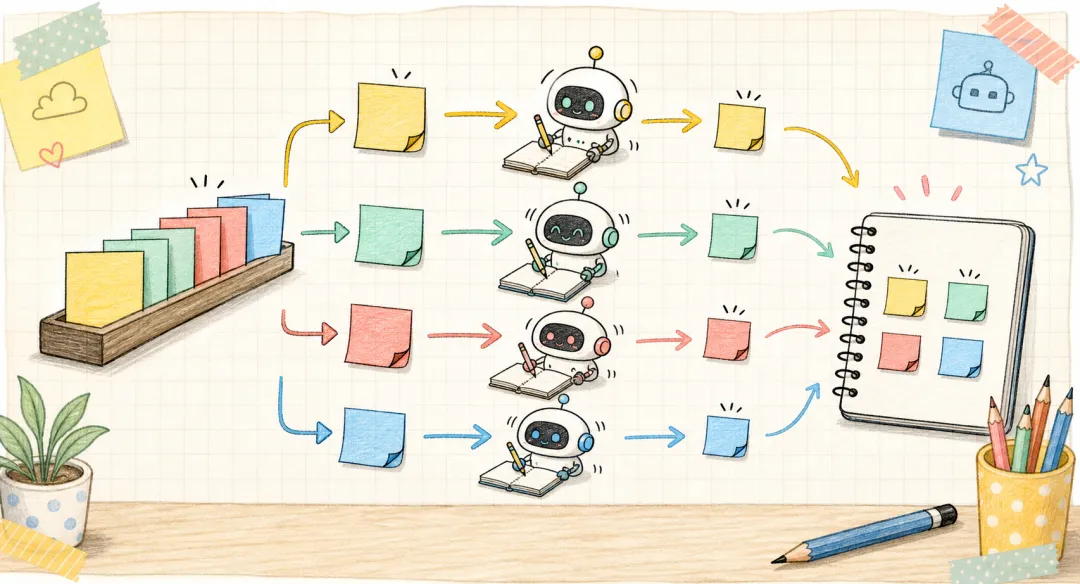
这听起来像普通协作文档,但 DeLM 多了一条关键规则:写进去的内容,必须先压缩,再验证。

“压缩”的意思,是不把整段聊天记录、命令输出、推理过程都贴进去。系统只留下对别人有用的小纸条。
比如:
“这条假设已经失败。”
“真正出错的文件在这里。”
“这个约束不能放松。”
“这个补丁方向已经通过了复现实验。”
这样,每个智能体不用读一大堆原始记录,也能快速知道当前局面。
任务队列像一排待办事项。
传统做法里,班长常常要等一批人都回来,再汇总,再发下一批任务。这叫同步的“分发和收集”。慢的人没回来,下一轮就卡住。
DeLM 的做法更像自习室。
有任务,就放进队列。空闲的智能体自己取任务。做完以后,把结果写进公共笔记本。队列空了,最后完成的人会看一下:是不是还缺东西?如果缺,就再生成新的任务。如果够了,就整理最终答案。
这让协作更像流水线,而不是一次次开大会。
这背后的好处很朴素。
一个人发现的失败,马上变成大家都能看到的路标。一个人定位到的关键文件,后面的人可以接着用。一个人确认过的限制条件,不用等班长重新解释。
并行不只是“同时干活”,而是“同时积累公共进展”。
共享上下文如果太厚,也会出问题。
想象一个班级公共笔记本,里面把每个人的草稿纸都贴上去了。它当然信息完整,但谁也翻不动。
所以 DeLM 把信息分成三层。
最上层,是很短的要点。论文里叫 gist,可以理解成“便利贴摘要”。大家默认先看这一层。
中间层,是更完整的摘要。它记录这个要点来自哪段资料,关键限定是什么。
最底层,是原始证据。比如原文片段、代码运行结果、详细轨迹。
这就像你复习时,先看目录,再看课堂笔记,最后才翻教材原文。

这层设计很重要。
只看短摘要,容易漏掉条件。每次都看原文,又太贵。DeLM 让智能体先用短摘要导航,发现需要细节时,再展开到更细的证据。
论文里的长文本问答实验,正是靠这个办法提高准确率。系统先建立一份经过验证的文档地图,再让智能体按需展开细节。
公共笔记本有一个危险。
如果一条错信息被写进去,后面所有人都会看到它。它看起来像“公共事实”,其实只是某个智能体的误读。
所以 DeLM 不让结果直接入库。
每条新笔记都要经过验证。对于长文档摘要,系统会检查摘要有没有被原文支持。对于智能体的推理结果,系统会检查小纸条有没有忠实保留原来的发现、失败、约束或证据。
通不过,就重写或丢掉。

这个设计解释了论文里的一个实验现象。
在 LongBench-v2 多文档问答上,去掉“入库前验证”,准确率会明显下降。原因不神秘:错笔记一旦进入公共本,后面的人就会把它当真。
这对我们平时用 AI 也有启发。
让 AI 长期记东西,不难。难的是只让它记“查过的东西”。记忆如果没有来源和检查,就会从助手变成误导。
论文主要测试了三类任务。
在 SWE-bench Verified 这类真实软件修复任务上,DeLM 让不同尝试之间能共享失败、发现和补丁摘要。论文报告,在 Gemini 3 Flash 作为基础模型时,DeLM 的平均一次成功率达到 65.7%,Pass@4 达到 77.4%,同时每题成本约 0.12 美元,约为一些强基线的一半。
在 LongBench-v2 多文档问答上,DeLM 在四个模型家族上取得最高平均准确率。论文给出的解释是:共享上下文先把文档群整理成一张可信地图,后续智能体再按需查细节。
在 OOLONG 这种更像表格统计的任务上,单独的 DeLM 反而不如 RLM。因为那类题需要精确计数、筛选和聚合,代码执行更可靠。但把 DeLM 和 RLM 结合以后,效果最好,成本也更低。
这说明 DeLM 不是万能外壳。
它更像一层协作协议:谁发现了什么,谁验证过什么,谁已经试错过什么,应该怎样进入公共状态。
可以把它记成一句话:
多智能体真正需要扩展的,不只是人数,而是公共笔记本。
这个笔记本要短,大家才愿意读。它要能展开,细节才不会丢。它要先查证再入库,后面的人才不会被错信息带偏。
所以,下次看到“一群 AI 协作”的系统,不妨先问三个问题:
它们是不是都要通过一个主控来转述?
失败尝试会不会被后面的人复用?
写进共享记忆的内容,有没有先查证?
这三个问题,比“开了几个智能体”更重要。
