很多数仓开发同学都有个共同的痛点:需求来了,先对着几百张表理血缘,再对着表述不清的需求文档反复和产品经理确认口径,最后写完SQL还要和调度打配合,哪个环节出了问题都得人工排查。
但现实是,大多数团队连数据质量都还没治理好,更别说搞什么AI了。
这就导致了一个尴尬的局面:AI+数仓的讨论满天飞,真正落地的案例少得可怜。很多同学甚至分不清"AI辅助开发"和"AI替代开发"的区别,一头扎进去研究大模型,结果发现生产环境根本跑不起来。
这篇文章不讲概念,不讲情怀,直接从数仓开发的核心环节切入,建模、ETL、调度、数据质量,告诉你AI在每个环节能做什么、不能做什么、怎么落地。
01 AI+数仓的全景架构,别上来就上大模型
先看全局。AI+数仓不是一个"接个API就完事"的事情,它需要一套完整的架构支撑。
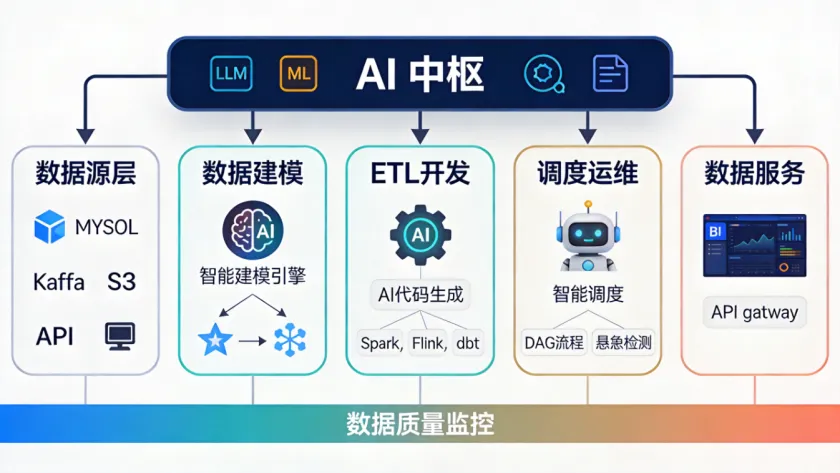
这张图把AI在数仓中的介入点梳理得很清楚:AI中枢作为统一能力层,向下对接各个开发环节,而不是每个环节各自为战接入不同的模型。为什么强调统一能力层?因为真实生产中,你的建模需要理解业务术语,你的ETL需要遵循建模规范,你的调度需要感知数据质量状态,这些环节之间存在强依赖关系。如果每个环节单独接一个AI服务,就会出现术语不一致、规范冲突、上下文断裂的问题。
落地建议:先建业务知识库,再谈AI赋能。没有统一的业务口径和元数据体系,AI生成的SQL再漂亮也是错的。02 智能数据建模,从"对着需求写DDL"到"AI推导表结构"
数仓建模是整个开发流程的起点,也是最耗时的环节之一。传统的做法是:需求分析师给文档,建模工程师对着文档画ER图,然后手写DDL,再和业务方反复确认字段含义。
AI介入后,这个流程可以发生质的变化:
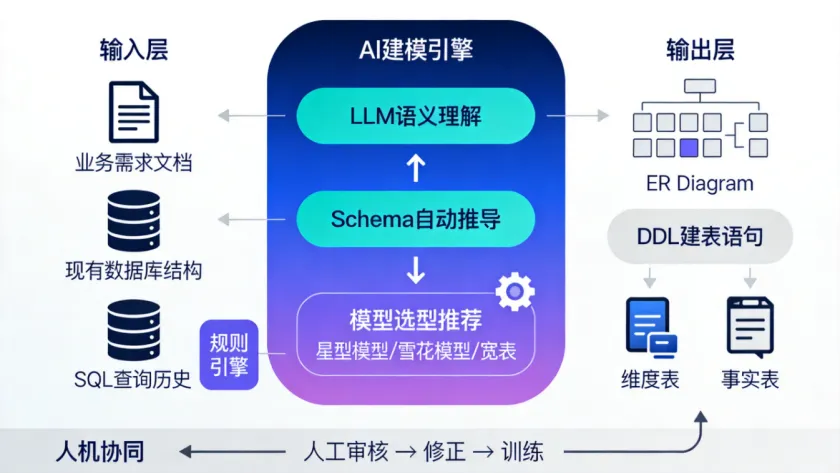
核心思路是:AI不替代建模工程师的判断,而是把"从需求到表结构"的翻译工作自动化。
第一,语义理解与推导。把业务需求文档(PRD、会议纪要、指标定义文档)作为输入,通过LLM提取其中的实体、关系、指标定义,自动推导出维度和事实表的候选结构。比如需求文档里写"要统计每个门店每天的GMV和订单量",AI能推导出需要一个"门店维度表"和一个"日粒度销售事实表"。第二,基于现有库结构的增量建模。很多情况下你不是从零开始,而是要在现有数仓基础上加表、加字段。AI可以读取现有的Hive Metastore或Information Schema,理解当前表结构和血缘关系,在已有模型基础上推荐新增表的结构,确保和现有模型的一致性。第三,模型选型推荐。根据查询模式(是分析型查询为主还是明细查询为主)、数据量级、更新频率,推荐使用星型模型还是雪花模型,哪些维度做退化维度,哪些字段做冗余。这里有个关键点:AI生成的模型方案必须经过人工审核。审核的重点不是"AI写得对不对",而是"AI是否理解了业务上下文"。因为需求文档里很多隐含的业务规则(比如"退货订单不计入GMV"这种口径),AI不一定能从文本中准确提取。落地的具体做法:
- 先把业务术语表、指标定义文档整理成结构化格式(推荐用Markdown或YAML),喂给AI作为上下文
- 用Prompt模板固定输出格式,要求AI输出"表名、字段名、字段类型、业务含义、来源表"的结构化建模文档
- 人工审核后,再用代码生成工具把审核通过的模型转为DDL
03 AI辅助ETL开发,从"手写SQL"到"需求即代码"
ETL开发是数仓工程师日常工作中最"卷"的环节。同样的需求,有人写500行,有人写50行;同一条SQL,有人写的要跑3小时,有人优化后30分钟出结果。
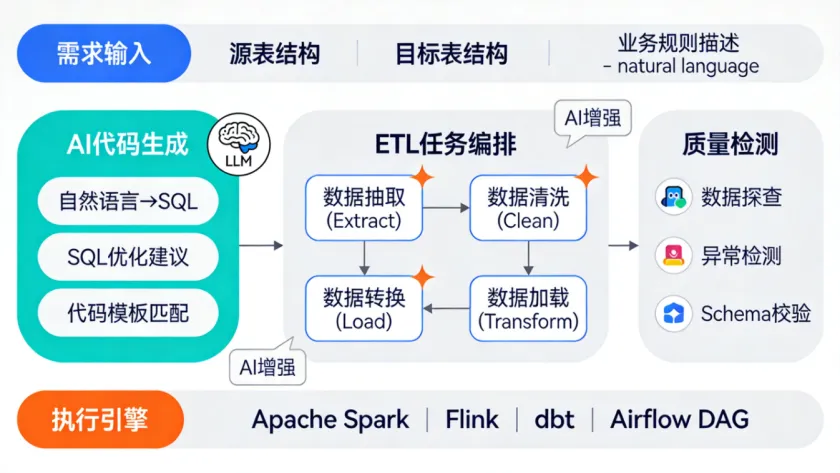
AI在ETL开发中的价值,不是"帮你写完所有SQL",而是把那些机械重复的、模式化的工作自动化,让工程师把精力放在业务逻辑的校验上。来看AI辅助ETL开发的三个落地场景:
场景一:自然语言生成SQL。这是最直观的应用。你输入"把用户表中最近7天注册的用户和订单表做关联,统计每个渠道的新增用户数和首单金额",AI生成对应的SQL。这个能力GPT-4和Claude已经做得不错了,但生产环境直接用的风险在于,AI不了解你的表名规范、字段命名规则和分区策略。所以落地的关键是在Prompt中注入三层上下文:表结构Schema、命名规范文档、相似历史SQL作为Few-shot示例。这三层信息准备好了,生成的SQL"直接可执行且结果正确"的比例可以从30%提升到70%以上。
场景二:SQL智能优化。已经写好的SQL,AI可以做性能分析和优化建议。具体包括:识别缺少分区过滤条件的查询、建议Join策略优化:小表用broadcast join减少shuffle,大表关联时优先过滤再join,避免全量笛卡尔积、识别可以合并的重复子查询、推荐更高效的窗口函数写法。这个能力的实现不一定依赖LLM,很多规则化的优化(比如分区裁剪、谓词下推)用传统的规则引擎更稳定。LLM更适合处理那些需要理解业务语义的优化,比如"这个聚合条件可以用物化视图替代"。
场景三:ETL任务模板化。大部分ETL任务的模式是相似的:ODS增量同步→DWD清洗转换→DWS聚合→ADS输出。AI可以识别你现有ETL代码中的模式,生成标准化的任务模板,新需求来了只需要填参数就能生成完整的ETL脚本。一个实操建议:别指望AI一次写出生产级SQL。正确的用法是AI生成初稿→人工校验业务逻辑→CI/CD自动跑数据质量检测→通过后合入主干。把AI当成一个"写代码很快但不懂你业务的实习生",审核环节不能省。04 智能调度与运维
数仓调度和运维是被严重低估的环节。很多团队的状态是:白天写SQL、晚上跑任务、凌晨告警、爬起来看日志、手动重跑。这种"人肉运维"的模式,任务量一上来根本扛不住。
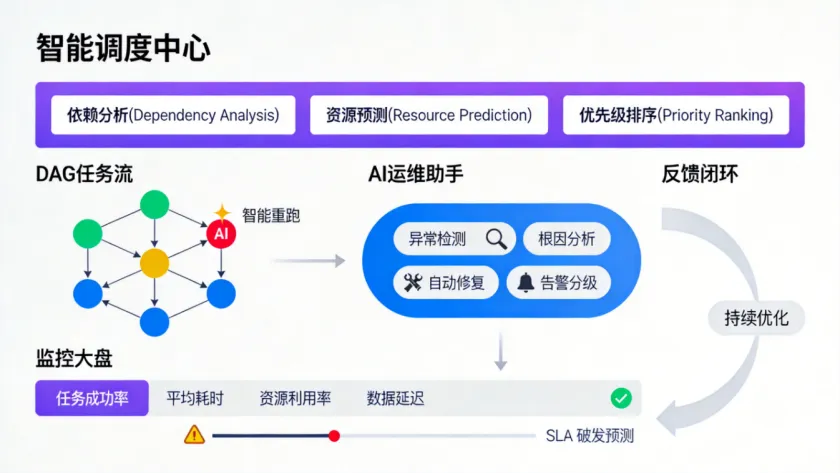
AI在调度运维领域的落地,是目前技术成熟度最高、ROI最明确的环节。原因很简单:运维数据本身就是结构化的,非常适合ML模型处理。三个核心落地场景:
智能依赖分析与调度优化。复杂的数仓任务可能有几百个节点、上千条依赖关系。人工梳理DAG既痛苦又容易出错。AI可以做两件事:一是从SQL代码和表血缘中自动推导任务依赖关系,替代人工配置DAG;二是基于历史运行数据预测每个任务的实际耗时,智能调整调度顺序和并行度,缩短整体产出时间。实测下来,一个200+节点的数仓项目,AI辅助优化调度后整体产出时间(从首个任务启动到全部任务完成)可以缩短15%-25%。
异常检测与根因分析。这是运维中价值最大的场景。传统的告警是"任务失败了",你需要自己去查日志、查上游、查数据量变化。AI可以做的是:任务失败时自动分析最近一次变更(代码变更、数据量突变、上游延迟),定位最可能的根因,并给出修复建议。具体实现思路:收集每次任务运行的特征(执行时间、输入数据量、输出数据量、CPU/内存峰值、最近24小时是否有代码变更(布尔特征)、数据量环比变化率),训练分类模型。当任务失败或性能异常时,模型根据特征匹配历史相似案例,输出根因概率排序。
SLA预测与预警。不等任务超时了再告警,而是在任务运行过程中,基于已完成阶段的耗时和当前资源使用情况,预测是否会超出SLA。如果预测会超时,提前触发扩容或降级策略。落地优先级建议:先把监控和告警做好,再做智能分析。没有完善的监控数据,AI分析就是无源之水。确保每个任务的执行日志、资源指标、数据质量指标都被完整采集,存在时序数据库或数据湖中,这是AI运维的基础设施。加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!
05 数据质量治理,从"事后补救"到"事前预防"
数据质量问题从来不是技术问题,而是业务问题。数据错了,下游的报表就错了,决策就错了,信任就崩了。
传统的数据质量治理是"打地鼠"模式:业务投诉了→排查原因→修数据→加校验规则→下一个问题又冒出来。这种被动响应的模式永远治标不治本。
AI可以把数据质量治理从"事后补救"变成"事前预防":
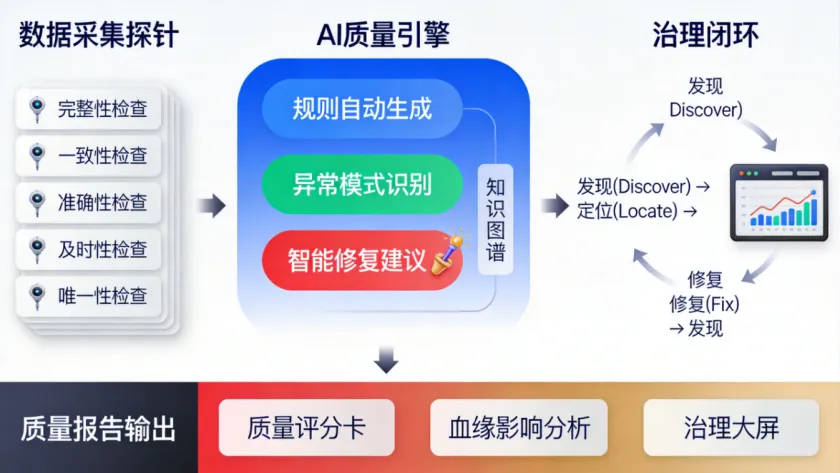
规则自动生成:这是AI在数据质量领域最实用的能力。传统做法是质量工程师根据经验手动编写校验规则,效率低且覆盖不全。AI可以通过分析历史数据分布、参照行业标准、学习已有规则,自动生成校验规则。举个例子:AI分析"订单金额"字段的历史数据,发现99.5%的值在1-50000范围内,但最近两天出现了大量0.01的订单。AI会自动生成一条规则:"当订单金额小于0.1且订单渠道为某特定推广渠道时,标记为疑似刷单数据"。这种规则靠人工写,可能要等问题暴露很久后才会想到。
异常模式识别:有些数据质量问题不是单字段能看出来的,而是字段之间的组合异常。比如"发货地址是北京但收货地址是海南,且物流状态是同城配送",这种跨字段的逻辑异常,传统阈值规则很难覆盖。ML模型通过学习正常数据的分布模式,可以识别这类组合异常。智能修复建议:发现问题只是第一步,AI还能给出修复方案。比如检测到某个ODS表的数据量今天突然下降了30%,AI可以结合血缘分析告诉你:不是源系统数据丢了,而是上游增加了一个过滤条件。修复建议:检查上游表最近24小时的查询逻辑变更(SELECT条件、JOIN关联是否被修改)。一个关键认知:数据质量治理的核心不是技术,是"数据质量意识"的组织化。AI能帮你发现更多问题、更快定位问题,但"谁来修""怎么防止再犯"这些流程问题,还是需要管理制度来支撑。落地路径建议:
- 先把核心业务表(营收、用户、订单)的完整性、一致性、及时性指标梳理出来
- 用AI基于历史数据生成初始校验规则,人工审核后纳入质量平台
- 建立质量问题分级机制:P0阻断下游任务、P1发送告警、P2记录日志
写在最后
AI+数仓这件事,说到底不是"用AI替代数仓工程师",而是用AI放大数仓工程师的生产力。建模阶段,AI帮你快速生成候选方案,你负责审核业务合理性;ETL阶段,AI帮你生成SQL初稿和优化建议,你负责校验业务逻辑;调度阶段,AI帮你预测风险和定位故障,你负责制定应急预案;质量阶段,AI帮你发现隐藏问题,你负责推动治理流程。
能落地的AI能力有一个共同特点:它们都建立在完善的数据基础设施之上。元数据管理、血缘追踪、日志采集、质量监控,这些"苦活累活"才是AI赋能的根基。如果你的数仓连这些基础都没做好,先别急着上AI,先把地基打好。
如果你担心自己的项目与经历不够硬核,亦或对AI、智能体对工作的冲击感到彷徨,或者不知道如何将普通项目包装出亮点, 不要慌 !为了帮助大家顺利通过 2026 年严苛的大数据面试,华哥联合多位大厂资深专家,整理了《 2026 大数据最新面试题库 》。仅仅获取题库还不够,简历才是敲门砖。很多人的技术没问题,但简历写得太烂,连面试机会都没有!同理,工作想提升却苦于无人指导,一个人死磕终究不是办法。站在前人的肩膀上,才能走的更快、行的更远。华哥是这么过来的,其中的痛只有自己最清楚。即日起,加入我们的【大数据陪伴营·星球】,你将获得《2026 大数据最新面试题》完整版下载
重磅福利:每位新入星成员,可获得一次 1 对 1 简历诊断与优化指导、或职场答疑与辅导都可(至少 60 分钟语音/视频通话)!
资深专家亲自把关:由阿里/字节背景的资深数仓专家一对一辅导。
深度挖掘项目亮点:帮你从平凡的工作中提炼出高光时刻。
逐字逐句修改简历:从排版、措辞到逻辑结构,全方位优化。
模拟面试演练:提前适应高压面试环境,规避露馅风险。
原价 499 元的简历指导服务,现在加入星球直接免费送!名额有限,仅限前 3 名加入者!👇 立即行动,拿下高薪Offer 或 升职加薪!华哥私人微信:bba80108别让一份糟糕的简历、亦或没有跟上AI的潮流,埋没了你优秀的技术实力 。 2026,让我们一起冲击大厂,薪资翻倍 !互动时间:1. 你所在团队的数据仓库,目前处于哪个成熟度阶段?是"手工数仓"还是已经进入"智能数仓"?2. 数仓建设过程中,你遇到过最头疼的问题是什么?是分层设计、建模规范、还是ETL维护?评论区聊聊3. 想获取《智能数据仓库与智能分析手册》v2.0 完整版?关注公众号 + 转发本文到朋友圈,截图发后台即可获取完整手册PDF!(排队领取哦)我们下一期见! |
 夜雨聆风
夜雨聆风