 夜雨聆风
夜雨聆风


壹
一个正在发生的变革
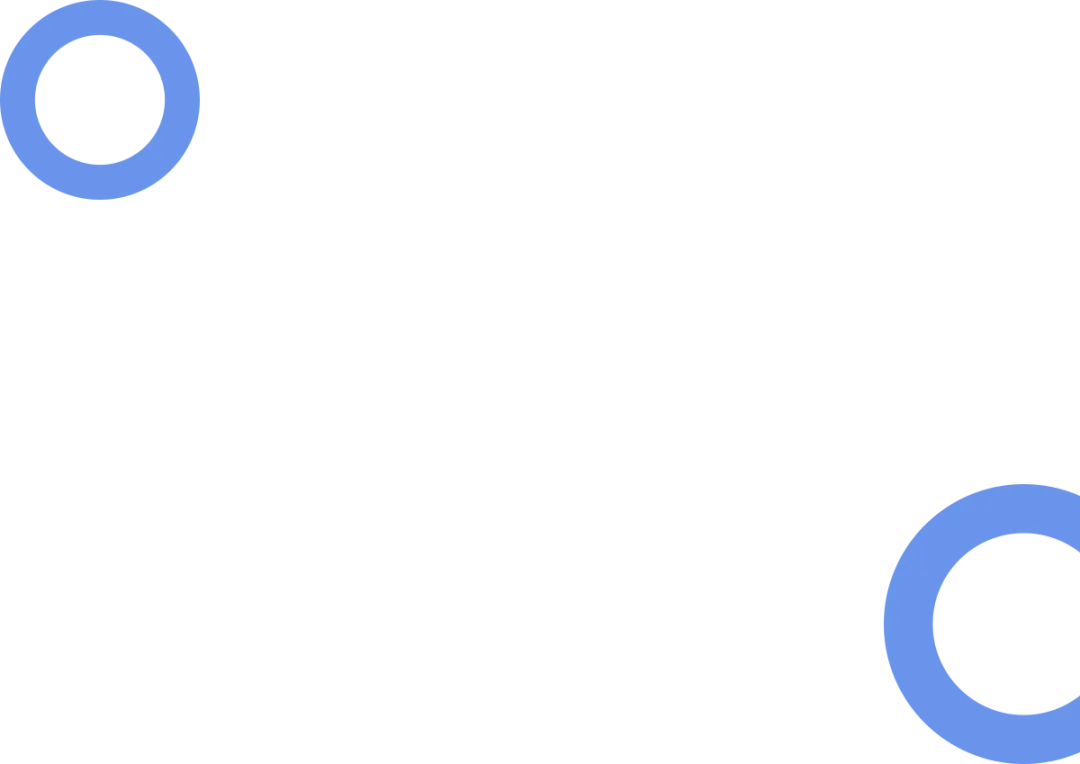
你有没有发现这些场景变化——
在银行柜台:客户说“定期转活期”,系统自动查账户、发起转账。
在政务大厅:市民说“续办居住证,地址没变”,系统自动调取历史材料。
这背后是一个极简且稳定的AI Agent通用架构:
交互入口(文字/语音/图片/动作) → 大模型(意图分析+工具选择) → 业务工具(API/数据库) → 结果反馈
💡 本文将直接提供可运行的语音版智能助理,供各位参考。
贰
从指令到行动
关键点:大模型不做最终回答(避免幻觉),只决定调用哪个工具,由工具返回准确数据。
叁
为什么这个架构长期有效
痛点 | 解决思路 |
大模型会变 | “理解意图→选择工具”的职责不会变 |
交互方式会变 | 文字、语音、脑机接口,本质都是输入意图→调用工具 |
业务系统复杂,架构封装复杂 | 业务只需暴露API |
类比互联网时代的“客户端-服务器”模型,所有落地系统都离不开这个架构。
肆
“意图分析+工具选择”怎么工作?
大模型不调用工具,只输出结构化的“工具调用指令”。
四步流程:
1. 定义工具菜单(例如:天气查询需要城市参数)
2. 把用户问题和工具菜单发给大模型
3. 大模型返回应该调用哪个工具以及参数(如{"name":"get_weather","arguments":"{\"city\":\"北京\"}"})(大模型自动完成了意图分析和工具选择的工作)
4. 你的代码根据返回调用相应函数
大模型只做“判断”,你的代码负责“执行”。
伍
手把手10分钟:搭建AI语音助理
你需要一个麦克风。系统用阿里云智能语音(NLS) 识别你说的话,DeepSeek 理解意图并调用工具,再用阿里云TTS 播报结果。
1
技术选型(免费额度说明)
环节 | 方案 | 免费额度 / 说明 |
语音识别 | 阿里云NLS(通过百炼平台) | 新用户90天内免费10小时ASR + 1万字符TTS |
大模型 | DeepSeek | 基础版包含每日50次调用 + 每月100万tokens免费额度;V4系列另有独立免费政策 |
语音合成 | 阿里云NLS(同上) | 与ASR共用90天免费套餐 |
💡 注意事项:
阿里云NLS(通过百炼平台)
① 免费额度通过阿里云百炼新加坡地域提供,有效期为90天,适合学习测试。
② 新用户免费包含:10小时语音识别 + 1万字符语音合成。
③ 额度耗尽后会转为按量计费,建议在控制台开启“免费额度用完即停”功能,避免意外扣费。
DeepSeek:
① 网页版对话永久免费。
② API新用户可获得一定额度的免费调用次数和tokens。
③ 超出免费额度后按量计费。以DeepSeek-V4-Pro为例,最新价格为:输入3元/百万tokens,输出6元/百万tokens;缓存命中时输入仅需0.025元/百万tokens。
④ 免费额度和价格以DeepSeek官方最新公告为准。
两者(阿里云NLS和DeepSeek)是独立服务,需分别注册开通。
2
环境准备
本文以DeepSeek大模型和阿里云的智能语音为例。
bash命令:(安装本次程序运行所需要的依赖)
pip install pyaudio requests openai -i https://pypi.tuna.tsinghua.edu.cn/simple
① 获取 DeepSeek API Key:
访问 platform.deepseek.com 注册,完成实名认证后可获赠10元余额。在控制台创建 API Key(复制保存)。
② 开通阿里云智能语音(NLS)并获取凭证:
访问 阿里云百炼控制台(首次使用需开通)
开通后会自动获得90天免费试用套餐(含ASR 10小时 + TTS 1万字符)
在左侧“智能语音交互”或“项目管理”中获取 AppKey
在“令牌管理”中获取 AccessToken(首次会自动生成)
3
完整代码(约120行)
将下面的完整代码保存为 voice_agent.py,需要替换三个值为YOUR_开头的配置项。示例代码如下:
import pyaudioimport waveimport requestsimport jsonfrom openai import OpenAI# ========== 1. 配置(需要替换)==========DEEPSEEK_API_KEY = "YOUR_DEEPSEEK_API_KEY"ALIYUN_APPKEY = "YOUR_ALIYUN_APPKEY"ALIYUN_TOKEN = "YOUR_ALIYUN_TOKEN"client = OpenAI(api_key=DEEPSEEK_API_KEY, base_url="https://api.deepseek.com")# ============= 2. 工具定义 ============tools = [{ "type": "function", "function": { "name": "get_weather", "description": "查询天气", "parameters": { "type": "object", "properties": {"city": {"type": "string"}}, "required": ["city"] } }}]def get_weather(city): url = f"https://wttr.in/{city}?format=%C+%t" return requests.get(url).text.strip()# ======= 3. 语音识别(阿里云ASR) =======def listen(): FORMAT = pyaudio.paInt16 CHANNELS = 1 RATE = 16000 CHUNK = 3200 RECORD_SECONDS = 5 p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("🎤 请说话...") frames = [stream.read(CHUNK, exception_on_overflow=False) for _ in range(int(RATE / CHUNK * RECORD_SECONDS))] stream.stop_stream(); stream.close(); p.terminate() with wave.open("temp.wav", "wb") as wf: wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) url = "https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/asr" with open("temp.wav", "rb") as f: audio_data = f.read() headers = {"X-NLS-Token": ALIYUN_TOKEN} params = {"appkey": ALIYUN_APPKEY, "format": "wav", "sample_rate": "16000"} resp = requests.post(url, params=params, headers=headers, data=audio_data) result = resp.json() if result.get("status") == 20000000: text = result.get("result", "") print(f"✅ 识别:{text}") return text else: print(f"❌ ASR错误:{result}") return ""# ====== 4. 大模型意图分析 + 工具调用 ======def run_agent(user_text): resp = client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": user_text}], tools=tools, tool_choice="auto" ) msg = resp.choices[0].message if not msg.tool_calls: return msg.content args = json.loads(msg.tool_calls[0].function.arguments) return get_weather(args["city"])# ====== 5. 语音合成(阿里云TTS) ======def speak(text): print(f"🔊 播报:{text}") url = "https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/tts" params = {"appkey": ALIYUN_APPKEY, "text": text, "format": "wav", "sample_rate": "16000", "voice": "zhiru"} headers = {"X-NLS-Token": ALIYUN_TOKEN} resp = requests.post(url, params=params, headers=headers) if resp.status_code == 200: with open("output.wav", "wb") as f: f.write(resp.content) import os os.system("start output.wav") # Windows # Mac: os.system("afplay output.wav") else: print(f"❌ TTS失败:{resp.text}")# ======= 6. 主循环(带继续询问) ========if __name__ == "__main__": print("🤖 AI语音助手启动(DeepSeek + 阿里云NLS)") while True: user_text = listen() if not user_text: continue if "退出" in user_text: speak("再见!"); break answer = run_agent(user_text) print(f"🤖 助手:{answer}") speak(answer) print("\n➡️ 是否继续?(y/n,默认继续)") if input().strip().lower() in ['n','no','否','不']: speak("再见!"); break
4
运行测试
bash命令:
python voice_agent.py
对着麦克风说“南京今天天气怎么样”,大模型会识别出你的查询意图,自动调用天气API获取真实数据,然后用语音播报结果给你。
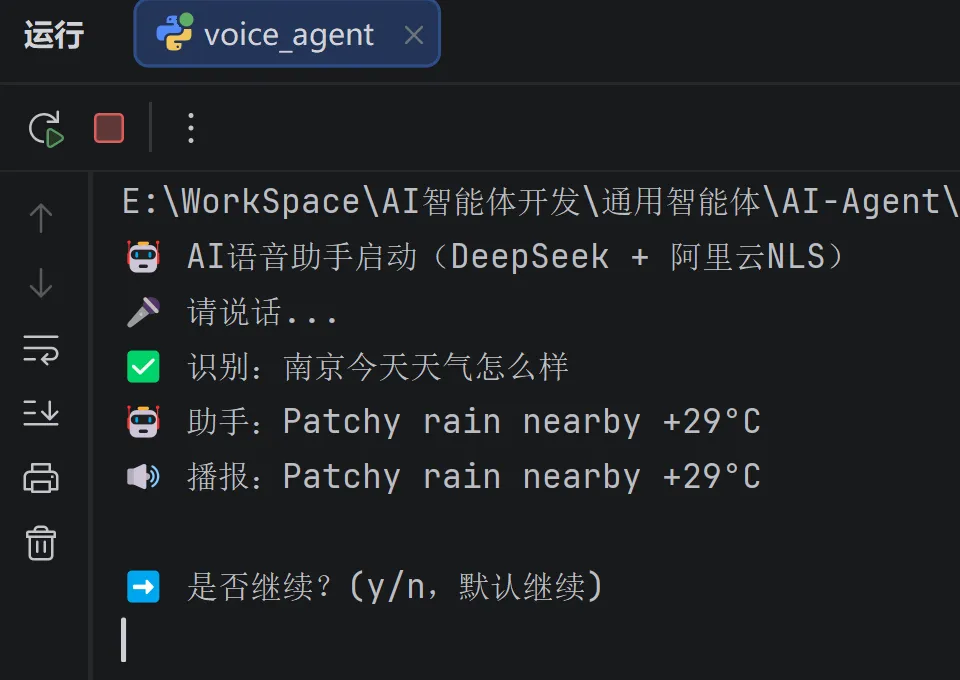
💡 首次运行会请求麦克风权限,请允许。识别不准确可调整 RECORD_SECONDS。
完成上述步骤,一个可以交互的AI语音助理就此诞生了!
陆
如何替换成你自己的业务工具?
两步完成:
增加工具定义(在 tools 列表中添加)
增加执行分支(在 run_agent 中添加 elif)
问:这个 elif 是不是人工配置意图识别?
答:不是。 它只是结果路由——大模型已自动完成意图判断和参数提取。你只需根据模型返回的名字调用对应函数即可。
其他代码一行不改——这就是通用架构的威力。
柒
避坑指南
问题 | 解决方案 |
ASR识别失败 | 检查 AppKey/Token,确认已开通百炼服务并处于90天免费期内 |
TTS 返回 401 | AccessToken 过期,重新在百炼控制台“令牌管理”中生成 |
麦克风无声音 | 系统要设置设置允许应用获取麦克风权限 |
pip安装慢 | 已使用清华镜像源,可换阿里源 |
DeepSeek API额度不足 | 网页版免费聊天不受影响;API可按量续费,价格极低 |
捌
技术展望:一个模型搞定所有?
本文是“ASR → 大模型 → TTS”三模块串联。
未来可用端到端语音大模型(如阿里Qwen-Audio、GPT-4o)直接语音进语音出,消除误差累积、感知情绪。
玖
写在最后
掌握“入口 → 意图 → 工具 → 反馈”这个通用架构,你就能快速搭建自己的AI语音助手。就现在,动手试试吧!
🤖 本文代码已在Windows 11 + Python 3.13验证,国内网络可用。
💬 欢迎在留言区交流分享。


