 夜雨聆风
夜雨聆风
安装完一个 Skill,想优化升级一下。
你试着自己找原因:对 AI 说"帮我润色一下"。AI 给你改了触发词、调了格式,产出看起来更专业了。你感觉好了一点。
但问题是:你不知道问题出在哪。
也许不是文案的问题。也许是这个 Skill 一开始就不值得雕——定位模糊、同质化严重、没有一句话能让陌生人停下来看。也许"润色一下"是最没用的建议,而最该有人做的事,是先站出来问一句:
这块料,值不值得雕?
鲁班就是在做这件事的。
它解决的不是文案问题,是"能见度"问题
你自己用着挺好,但发出去没人装——问题通常不是"写得不够好看",而是以下四条裂缝里至少有一条在漏:
- 看不懂:
别人第一屏扫过去,不知道它是干什么的、解决了谁的问题 - 没有第一屏钩子:
README 像工程说明书,没有截图、没有 GIF、没有能让人停下来看的结果样例 - 拿不出证据:
你说"效果不错",但没有一次能复现的测试、一个可查证的分数 - 不知道先改哪:
想优化,不知道该先动触发词、重写工作流、还是补 showcase——改哪里收益最大,完全凭感觉
大多数人的处理方式是"帮我润色一下"。鲁班的做法是把它当作品收进工坊:先挑战它值不值得雕,再看同行凭什么立足,三把尺量出短板,一刀一刀刨,每刀都过验证门,最后发版立规矩。
鲁班不夸你的 Skill。它只说实话。
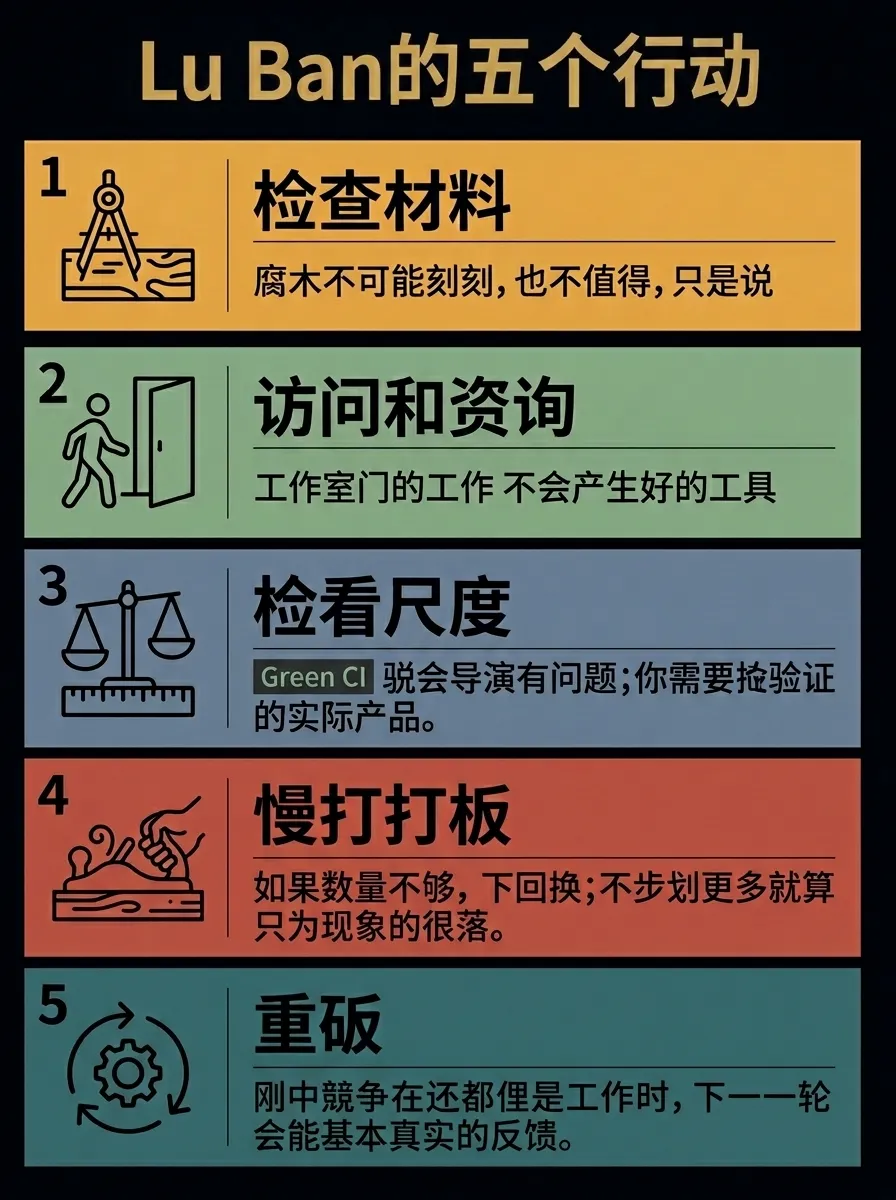
五个动作:验料 · 访行 · 过尺 · 慢刨 · 回炉
验料——先挑战前提,这块料值不值得雕
"朽木不可雕也,不值得就直说,给出换料的方向。"
不动笔,先回答四个问题:这个 Skill 解决的真实问题是否成立?它的唯一性来自哪里——方法论、脚本资产、私有数据还是展示效果?用户为什么要安装它,而不是临时问 Agent?它有没有一句话传播钩子?
如果任一挑战明显不成立,直接停手。
访行——联网找同行,看清自己在生态里站什么位置
"闭门造车出不了好工具。"
先把市面上的同类都看一遍:功能相近的直接同行、解决相邻问题的间接同行、以及那些 README 和 showcase 做得出色的"手艺同行"——后者不一定同功能,但总有你值得偷师的地方。每一个同行都要有 URL,没有搜索结果就如实说"未找到",不允许凭空编造。
过尺——结构、实测、活体三把尺一起量
"绿色的 CI 会撒谎,要拉真实产物对账。"
结构尺量文档写得清不清楚,实测尺量跑起来灵不灵,活体尺量它在真实世界里活得好不好。活体那把尺最值钱:只有拉过真实产出的人才知道,CI 全绿但数据停更 8 天这种事,文档里根本看不到。
慢刨——冻结原版做基线,改动过验证门才保留
"量不过就回刀,绝不为显得干了活而多刨。"
动刨子之前先封存原版做冻结基线。每一刀下去,都要和这个基线比——比不过就回刀。改动必须用真实数据回放验证,给出翻转数字,才能保留。一次性的对比脚本固化成仓库工具;一次性的判断标准立成项目明文规矩。验证手段不是脚手架,是交付物的一部分。
回炉——交活不是终点
"同行还在动,用户会回来,下一轮从真实反馈进。"
发版不是结束。留一份对标观察清单——哪些同行的哪些动作值得持续盯;立迭代纪律——发版要有 changelog,讲清"为什么改"而不是只讲"改了什么";标注下一轮入口——这次"不做"什么、已知哪些边界损耗,下一轮直接从这里开刀。
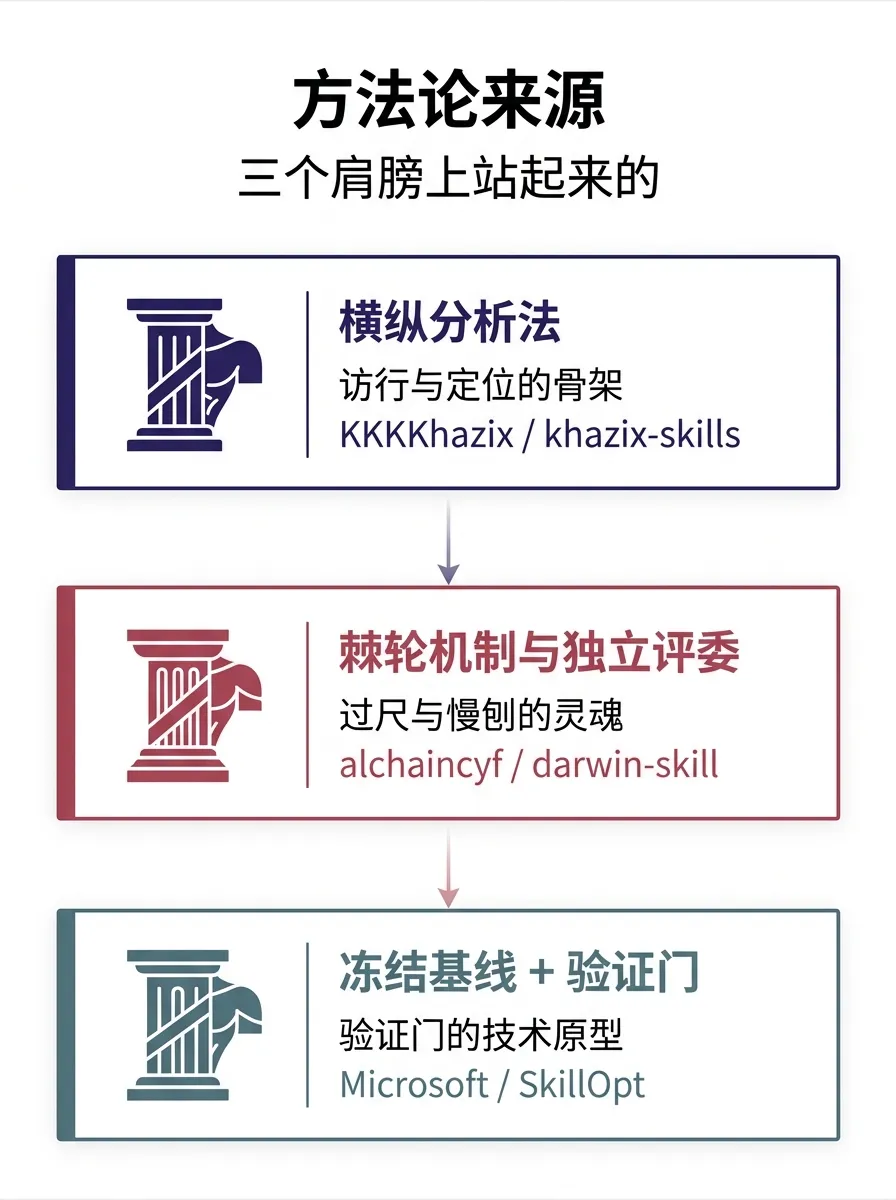
它不是凭空造的——站在三个验证过的肩膀上
横纵分析法 → 访行与定位的骨架
来自 KKKKhazix/khazix-skills 的 hv-analysis 工具
github.com/KKKKhazix/khazix-skills/blob/main/hv-analysis/SKILL.md
由数字生命卡兹克提出,融合索绪尔的历时-共时分析、社会科学的纵向-横截面研究设计、商学院案例研究法与竞争战略分析核心思想。
核心原则:纵向追时间深度,横向追同期广度,最终交汇出判断。这正是鲁班"访行"与"定位"的动作骨架——不闭门造车,先把同行看清楚、把生态位判断清楚,再动手。
棘轮机制与独立评委 → 过尺与慢刨的灵魂
来自 darwin-skill(github.com/alchaincyf/darwin-skill)
提出评估→改进→实测→保留或回滚的闭环,独立评委视角,以及棘轮机制——分数只能往前走,退回的改动不能以"优化过了"为由重新放进来。
这正是鲁班"过尺"与"慢刨"的灵魂——同一只手不能既"改"又"评",改过的内容必须经过独立的验证门。
冻结基线 + 验证门 → 验证门的技术原型
来自 Microsoft SkillOpt
github.com/microsoft/SkillOpt,arXiv:2605.23904
微软研究院的工作。将 Skill 文档视为冻结 Agent 的可训练状态,用冻结基线、有边界的候选编辑、held-out 验证分数门控来训练——只有严格提升验证分数的编辑才被接受。这正是鲁班"验证门"的技术原型——不是"看起来更好",而是有数字支撑的提升。
战绩:一个对话,把 1k 星项目打到 80 测试全绿
说一千道一万,不如一个真实案例。
鲁班的第一单活打磨对象是ai-news-radar:
github.com/LearnPrompt/ai-news-radar
一个约 1000 星的开源 AI 资讯雷达。从 v0.6 到 v0.7.0
github.com/LearnPrompt/ai-news-radar/releases/tag/v0.7.0
一个对话内完成,4 个 PR 全部合并,全程可查证(PR #11、PR #12、PR #13、PR #14,链接分别为:
github.com/LearnPrompt/ai-news-radar/pull/11
活体检查揪出的真实问题:
- Actions 全绿,数据静默停更 8 天:
流水线每次都重新生成文件,但工作流的 git add白名单从未包含它们——绿色的 CI 在撒谎,只有拉过真实产出的人才知道这个问题 - URL 乱码污染评分:
Google News 关键词 base64 随机匹配,把世界新闻误标为"模型发布",只有拉真实条目逐条复核才能发现 - 移动端三屏卡墙:
390px 宽度下 10 张统计卡占满三屏才见内容,桌面端看不出来
慢刨后的真实提升:
验证资产沉淀:
一次性的对比脚本固化为仓库工具 scripts/backtest_scoring.py(
github.com/LearnPrompt/ai-news-radar/blob/master/scripts/backtest_scoring.py
任意两个 git 版本的评分逻辑可在档案上重放。
立下项目规矩:动评分必须附 ≥14 天回放报告。
这条规矩是实战里被"绿色的 CI 静默撒谎"坑过之后的代价——教训进了工坊,工坊规矩进了每个使用者的项目。
它和"润色一下"差在哪
| 起点 | ||
| 依据 | ||
| 改法 | ||
| 验证 | ||
| 结束 |
改得好不好看,是文案问题。改得值不值得存在,是前提问题。鲁班先回答第二个问题,第一个问题才有意义。
上手教程:让鲁班打磨你的 Skill
安装
在任意支持 skill 的 AI 对话环境里,对大模型说:
帮我安装鲁班 skill:github.com/LearnPrompt/luban-skill或者用命令行:
npx skills add LearnPrompt/luban-skill -g对大模型说这句话,通用指令覆盖 opencode / workbuddy / openclaw
第一步:触发鲁班
让鲁班看看这个 skill:[你的 Skill 目录路径 / GitHub 仓库链接 / SKILL.md 内容]会发生什么:鲁班会先完成验料、访行、定位,给你三个打磨方向并推荐一个——在你选方向之前,它不会动你一行字。
第二步:选打磨方向
鲁班停下来等你说"走哪个",你只需要回复:
走方案 B或者更自然一点:
B 方案听起来最对,继续会发生什么:鲁班按你选的方向开始慢刨,每做一个改动都会先过验证门,给你对比数字,不是直接覆盖原文件。
第三步:过验证门(你自己提要求)
如果改动涉及评分逻辑这类核心部分,直接说:
用真实数据回放对比改动前后,给我翻转数字会发生什么:鲁班会拿项目当天/历史的真实数据跑改动前后的对比,给出具体数字("清除 X 条假 AI,零误伤"),不是笼统的"效果更好"。
第四步:验收(确认鲁班是否正常工作)
复制这句验收:
让鲁班看看这个 skill:github.com/anthropics/skills合格表现:它先输出验料挑战和带 URL 的同行对标,给三个方向并停手等你选——而不是直接开始改写。如果它直接改写了,说明安装或触发方式不对。
第五步:发布(分步授权,不偷跑)
鲁班打磨完了,到了要 merge 和发版的时候,它会停下来等你明确授权——这句话不算授权:
❌ "都好了吧?" ❌ "可以了吗?" ❌ "没什么问题了吧?"
这些是疑问句,用来问状态。授权必须是祈使句:
✅ "可以 merge 了" ✅ "发版吧" ✅ "合并到默认分支"
一次授权只覆盖当次动作,不延续到下一个发布动作。
一句话触发语速查
安全边界:该停手的地方它真的会停
鲁班有强制停手点,不是所有活它都接:
- 建议重构核心定位
→ 停,等你确认方向 - merge 到默认分支 / 打 tag 发版 / 对真实用户可见的部署
→ 每一步都要你明确授权,疑问句("都好了吧?")不构成授权 - 改动涉及高风险操作
(删除文件、执行 shell、提交 git、发外部请求)→ 它会先停下来问你 - 发现 Skill 前提不成立
(验料判定"朽木")→ 直接告诉你不值得雕,不帮你改
另外,它不把 API key、token、cookie、私人路径写进任何公开产物;所有改动以可审计的提交呈现,不用 git reset --hard 暴力回滚。
验料 · 访行 · 过尺 · 慢刨 · 回炉
鲁班的工坊规矩里有这么一句:
"学手艺,不偷皮。"
它不照搬同行的名字、叙事和结构,它学同行怎么做、为什么这样做,然后把学到的东西落进自己的方法论里。
五个动作——验料 · 访行 · 过尺 · 慢刨 · 回炉——不是凭空想出来的,是站在横纵分析法(追踪来路、判断行情)、棘轮验证(独立评委、只进不退)、冻结基线 + 验证门(严格提升、有据可查)这三套已经过验证的方法上,一刀一刀刨出来的。
你写了一个 Skill,自己用着挺好。然后呢?
然后你需要一个"祖师爷"站在门口,告诉你这块料值不值得雕——不是讨好你,不是帮你润色,是先问你这个问题。
如果值得,它帮你打磨成一件能被理解、能被安装、能被传播、能被验证、能持续进化的公共资产。
如果不值得,它告诉你为什么,然后给你换料的方向。
它做的事,说到底是这一句。
相关链接
鲁班工坊:github.com/LearnPrompt/luban-skill 实战案例:ai-news-radar v0.7.0 全程记录,路径为
github.com/LearnPrompt/luban-skill/blob/master/skills/luban/examples/ai-news-radar-case.md
方法论来源:khazix-skills/hv-analysis github.com/KKKKhazix/khazix-skills/blob/main/hv-analysis/SKILL.md、darwin-skill(github.com/alchaincyf/darwin-skill)、Microsoft SkillOpt(github.com/microsoft/SkillOpt)
