夜雨聆风
夜雨聆风“ 多模态文档处理需要同时考虑技术复杂度和成本问题。”
在RAG场景中文档处理一直是重点也是难点,很多特别是以PDF为主的多图表文档处理起来特别麻烦,然后效果也不太好。
作者在之前的业务场景中,大都是以OCR技术为主要处理方式;但以技术文档为例,其包含大量的结构图,架构图,流程图等内容,使用OCR技术会导致结构图失去其本身的意义,得到的只是一堆没啥用的混乱内容。
而最近在网上社区中看到了一种新的处理思路,特此记录一下。
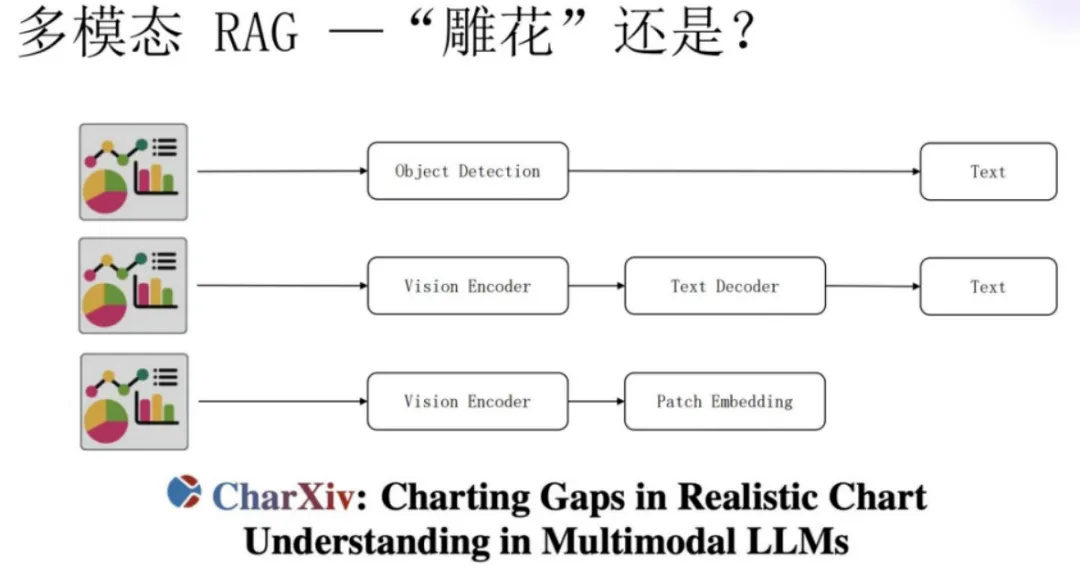
图表结构处理思路
在RAG文档处理中,业务场景要求文档内容的完整性和准确性,这里的完整性包括逻辑完整,还有结构完整;但是目前市面上很多技术处理都会丢失结构完整性,特别是结构图/架构图这种类型的内容。
结构图一旦失去其结构关系,那么结构图就失去了其本身的意义。
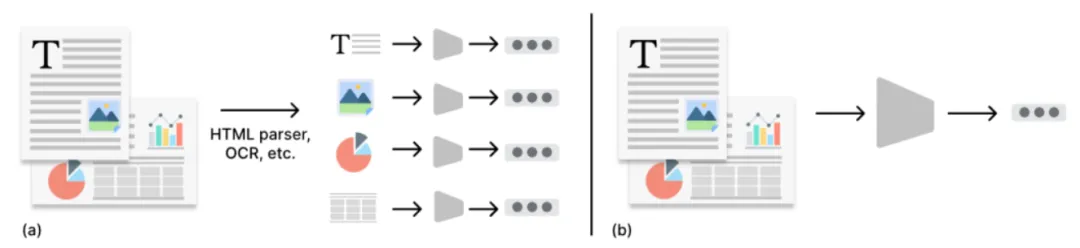
而这个新思路是先对文档进行内容提取,提取出其中的文字,图片,表格和结构图;然后使用多模态模型对图片和结构图进行内容提取,变成文字说明,之后再把这段文字说明插入到结构图所在的位置,这样整篇文档就从一个复杂文档变成了一个纯文本文档。
这样就可以按照普通文本文档进行处理,切片,向量化入库,大大降低了文档处理的复杂性。
然后在保存结构图并记录元数据,图片的URL,所在位置,内容描述等元数据信息,保存到关系性数据库中。
这样,当在检索阶段就可以根据切片的内容关联到对应的结构图,既保证了检索的准确性,又保证了文档完整片段的可溯源,从而提升RAG系统的质量。
我每天会免费回答3个AI开发相关的具体问题。你可以截图这篇文章,扫下方二维码加我微信,直接发问题。不一定马上回,但24小时内一定会给思路。