 夜雨聆风
夜雨聆风高速互联,大模型的血管
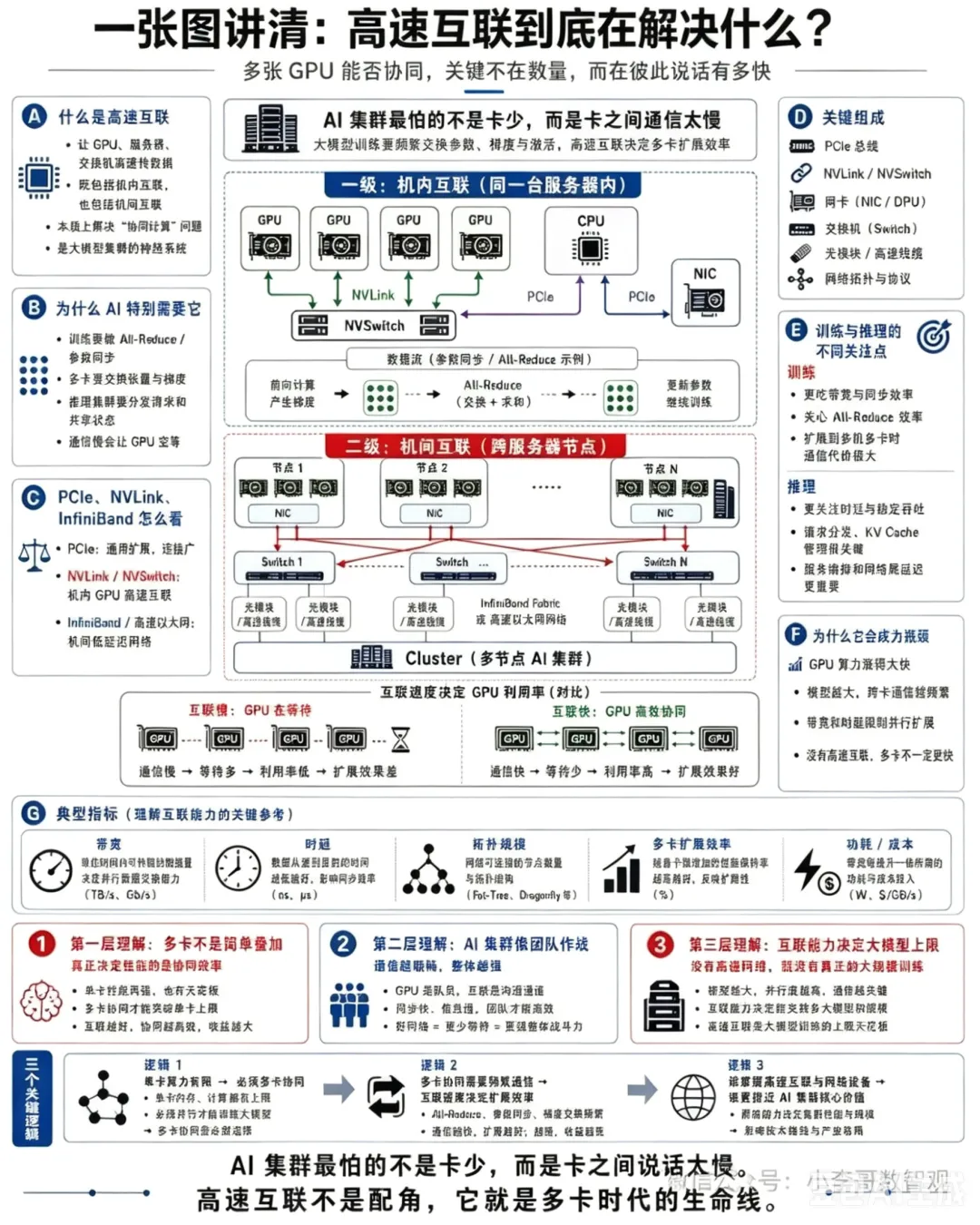
一、先讲核心梗:GPU再多,聊天慢全白搭
你可以把每一块GPU当成工厂里干活的工人,算力就是工人干活速度。
就算你雇100个顶尖技工,大家干完活要互相交换数据、核对进度,结果互相传话全靠蜗牛跑腿,工人大部分时间只能站着等消息,根本没法持续干活。
这张图讲的高速互联,就是给工人们搭专属高速互通通道,让大家秒传数据,不摸鱼不等待。
二、两层通道:车间内部互通 & 跨厂房互通
1. 一级·机内互联(同一台服务器=一个车间)
车间里好几块GPU工人,靠NVLink/NVSwitch专属专线聊天,不用挤普通慢通道PCIe。
好比车间内部装了内部对讲机,不用走大门绕路传话,传递梯度、数据毫秒级完成,干活效率直接拉满。
CPU相当于车间主管,只负责统筹,不参与工人之间的数据交换。
2. 二级·机间互联(多台服务器=多个厂房)
大模型训练光一个车间不够,要几十个厂房一起开工。
厂房之间靠InfiniBand高速网线连接,相当于厂房之间修专属高速路,普通网线带宽不够,跑大批量数据直接堵车。
一堆服务器拼在一起,就是完整AI算力集群。
三、三条“聊天通道”通俗对比
• PCIe:小区普通马路,通用啥设备都能走,但是慢,大批量数据容易堵,日常够用,大模型训练扛不住。
• NVLink/NVSwitch:车间内部专属快速通道,只给GPU之间传数据,速度拉满,单台服务器内部互通天花板。
• InfiniBand:厂房之间专属高速,跨服务器远距离传输,延迟极低,做大集群必备。
四、训练机和推理机,需求完全两码事
• 训练机(造模型阶段):
每天要来回交换海量梯度数据,相当于几百工人天天互相核对报表,最吃带宽,通信慢直接全员停工,必须顶配高速互联。
• 推理机(对外服务阶段):
模型已经训练完成,只需要快速接收用户请求、返回结果,不用大规模数据交换,更看重稳定低延迟,不用堆顶级互联设备。
五、为啥高速互联是AI最大隐形瓶颈?
GPU算力年年暴涨,模型越做越大,卡与卡之间要交换的数据呈爆炸式增长。
如果互联速度跟不上,GPU大部分时间都在原地等数据,算力白白浪费,堆再多高端显卡也发挥不出实力。
简单一句话:算力是拳头,高速互联是血管,血管堵了拳头再硬也使不上劲。
六、三层底层逻辑总结(通俗版)
1. 第一层:显卡不能单打独斗,必须互相传数据,通信快慢直接决定实际性能。
2. 第二层:多卡集群是团队,GPU是队员,高速互联是沟通渠道,沟通顺畅团队战力才强。
3. 第三层:高速互联决定大模型规模上限,没有好的互通网络,根本跑不了超大模型。 趣味收尾段子
趣味收尾段子
很多人卷着买高端GPU,却忽略通信通道,等于花百万请顶尖工人,却不给配通讯设备,纯纯花钱让显卡摸鱼。高速互联不是配件配角,是多卡AI时代的生存底线! last one
last one  拥抱未来
拥抱未来  any way
any way

