夜雨聆风
夜雨聆风
1、物理AI模型端核心要点
·核心模型定位差异分析:物理AI是大语言模型、多模态大模型之后的发展方向,与现有多模态模型应用场景存在显著差异:现有多模态模型多在手机端供人通过屏幕使用,物理AI脱离屏幕,应用于真实生活空间,核心服务对象为机器人等各类自主智能设备,核心作用是解决3D空间内物理世界相关现象(力、光、运动等)的感知、深层理解与决策问题,支撑机器人完成复杂任务。
当前物理AI领域核心包含三类模型,功能定位差异如下:a.VLM即视觉语言模型,融合视觉、语言信息支撑机器人感知所处环境、完成与人的交互,人类86%的外部信息来自视觉,约10%来自听觉,约2%来自触觉,嗅觉和味觉占比不足1%,当前VLM已实现视觉、语言融合,触觉等传感数据融合仍在发展中;b.VLA即视觉语言动作模型,在VLM的感知理解能力基础上新增动作决策能力,支撑机器人输出移动、操作等自主行为完成对应任务;c.世界模型通过大量物理世界数据训练而成,类似物理世界的仿真/数字孪生,能够预测机器人动作带来的物理世界变化(物体移动、位置变化、形变等),支撑机器人完成动作推理。三类模型对构建通用物理AI系统均不可或缺,其中世界模型是理解物理世界的核心大脑,VLM负责场景感知理解,VLA负责执行层面的动作输出。
·模型厂商商业模式:物理AI模型厂商对外输出服务时有两种可行收费模式,分别为按tokens收费、按订阅费收费(类似特斯拉FSD的收费模式)。收费模式的选择核心取决于供需双方的ROI测算结果,本质属于商业定价策略问题:对模型服务提供商而言,需要结合前期预训练投入、持续算力消耗、模型迭代升级成本确定对应定价策略;对机器人企业或终端使用者而言,需要结合自身使用需求与成本核算选择付费方式。
2、物理AI算力产业发展现状
·训练侧算力需求:大语言模型实现智能涌现的参数拐点为八千亿,这一结论来自工程实践,超出早期理论认知范围。当前物理AI(世界模型)所需参数规模暂无法准确预测,可能达到大语言模型的10倍甚至两到三个数量级,可确定其遵循scaling law规则,需足够多参数完成物理世界表征及参数间关联的权重计算。同等参数量级下,物理AI模型需融合听觉、触觉等多维度数据,算力消耗远高于大语言模型及二维图片、视频类模型。目前全球科技巨头均在争夺物理AI大模型的技术突破,行业整体算力需求尚未见顶,仍处于持续上升通道。
·端侧推理算力需求:当前汽车、人形机器人厂商的端侧推理主流配置为2-4颗Orin芯片,英伟达主推的Jetson Thor性能较Orin提升3倍,但未来可实现类人快速感知、决策、动作的人形机器人,即便配置Jetson Thor也可能无法满足算力需求。当前通用物理AI大模型尚未落地,端侧推理需实现环境感知、本体控制、自主动作生成等功能,且需具备泛化能力适配多类任务,现有芯片通用性尚未得到验证。同时端侧推理有严格时延要求:若响应超过2秒用户无法接受,因此响应时间需控制在500毫秒以内,当前主流配置算力仍存在明显不足。
·国产算力芯片前景:当前国产端侧AI芯片与海外主流产品存在技术代差,以华为310边缘推理芯片为例,性能较英伟达同类产品仍有差距。国产车规级芯片厂商如地平线等已在汽车领域与海外厂商展开竞争,但车规级芯片向机器人场景适配存在明显难点:汽车仅需在平面场景下完成加减速、转向等有限动作的推理决策,而机器人需要更强的3D空间感知能力,且大量决策需在端侧完成以保障低时延,对芯片适配要求更高。目前地平线、地坤、环摩尔等国产厂商均在尝试从车规级赛道向机器人端侧算力芯片拓展,但在机器人场景应用较少,尚未得到大型机器人企业的规模化采用,整体发展任重道远。
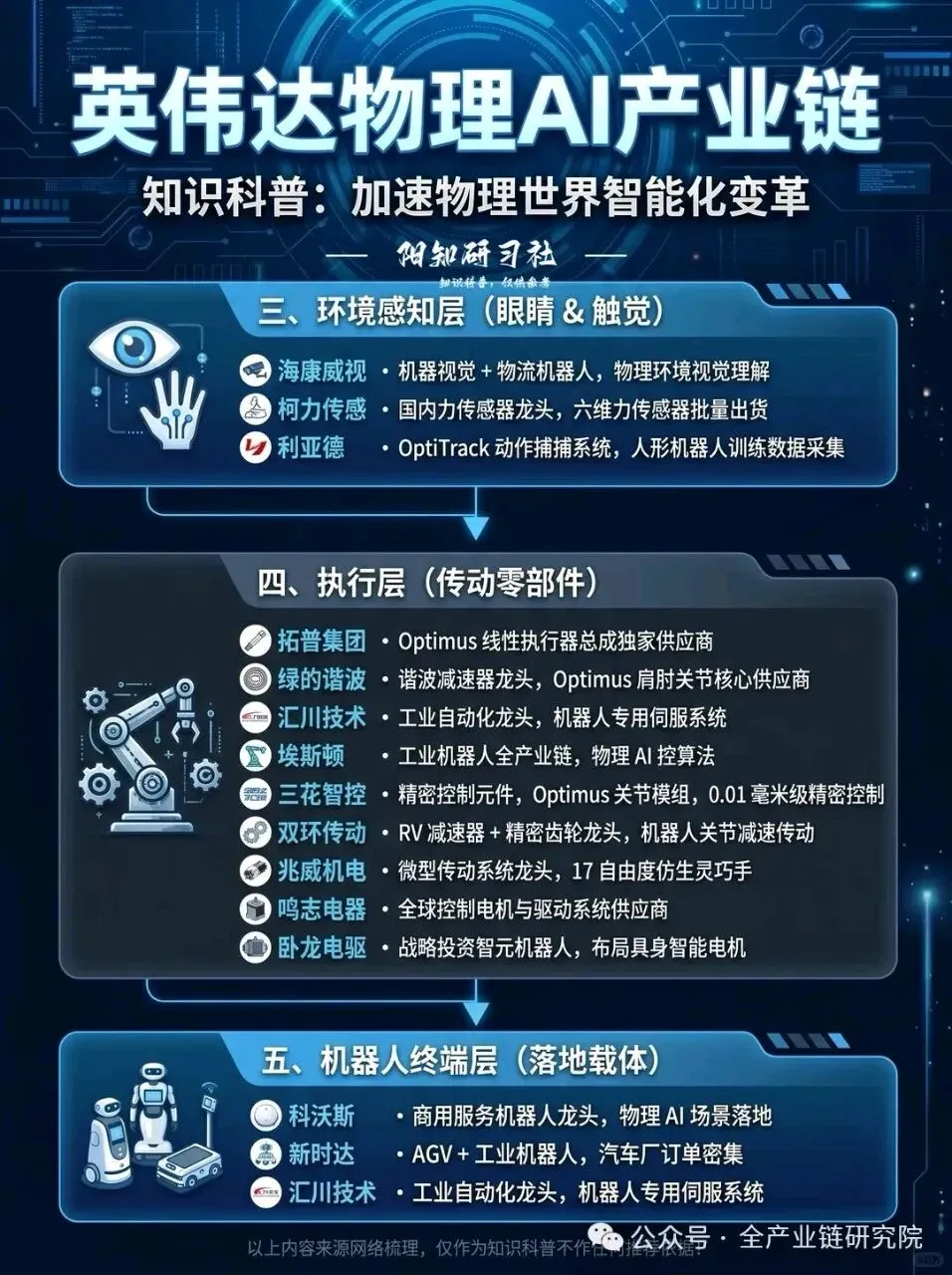
3、物理AI硬件端发展机遇
·感知硬件需求分析:机器人场景对感知硬件的核心要求是能够对物理世界的目标物、环境实现精准感知,国内在感知器件领域具备较强的研发和制造能力。从不同感知硬件的优先级与适用场景来看:机器人86%的外部信息来自视觉,3D RGB-D深度相机是最核心的感知硬件,相关产业空间较大;其次力觉、触觉传感器及电子皮肤是未来机器人的必备配置,当前力觉力矩传感器已应用于机器人关节,后续机器人末端、皮肤还需配置触觉传感器,目前国内相关布局厂商包括传统制造厂商及以电子皮肤、灵巧手为核心方向的新兴厂商,发展速度较快;激光雷达属于场景选配硬件,根据机器人形态及应用场景决定是否配置。
·核心零部件发展方向:零部件是物理AI将算法指令转换为物理动作的核心环节,不同品类的产业成熟度、增长空间存在明显差异。从增量需求方向来看,减速器、电机等产品技术相对成熟,国内布局厂商数量较多,部分产品精度可达2丝,已满足人形机器人基本需求,未来需求将随机器人整体出货量提升同步增长。以丝杠为主的线性关节、灵巧手属于物理AI驱动下的新增需求赛道,目前处于产业发展初期,增长空间更大,当前该类产品仍需在操作精细度、成本可控性、耐用性三个维度优化提升,是当前硬件端的核心突破方向,相关布局厂商未来成长弹性更高。
4、物理AI仿真数据平台前景
·仿真平台产业现状:目前国产纯仿真引擎生态薄弱,多数厂商没有自主研发的引擎,普遍基于海外开源技术开发。引擎只是技术环节的一方面,若能积累足量数据,在数据层面开展更多工作,就能为未来世界模型训练打下基础。当前相关公司的布局方向主要分为两类,一类瞄准通用场景打造相关模型,另一类聚焦工业等特定场景落地。通用世界模型训练的投入、挑战均较大,除了数据储备外,还需要大量算力资源堆积。该赛道具备较高产业价值,若企业能成功打造成熟的通用视觉模型,未来可向其他机器人公司提供服务调用,毕竟并非每个机器人公司都有能力自主训练这类通用视觉模型,潜在发展空间广阔。
·数据采集投入分析:当前数据获取主要有人工采集、仿真生成两种路径,二者成本差异显著:人工采集针对性的机器人操作数据成本较高,需要部署大量数采机器人作为末端采集工具,同时需要人员通过遥操作配合采集,且人工采集的素材很难支撑通用世界模型的生成,因此海外厂商普遍不依赖人工数采,更倾向依托仿真平台、数字孪生平台完成数据生成。海外厂商也在探索联合共建的合作模式,比如谷歌推出的GTGTX项目由多家机器人公司贡献场景、数据,共同训练通用模型;英伟达Isaac Sim开源开放,支持各方贡献机器人操作场景、相关数据用于模型训练。当前仿真场景搭建的投入量级较高,以200-300平米的咖啡厅场景为例,仅自有算力卡运行就需要2天,后续还要对生成的场景进行物理属性标注等人工加工,整体投入量较大,素材与仿真赛道具备较大的想象空间。
5、物理AI边缘推理需求分析
·边缘推理必要性分析:不同AI应用场景对推理时延要求存在显著差异:传统编程类AI应用依托云端算力,即便推理耗时2-5分钟也可满足使用需求;但物理AI面向物理世界真实场景落地,以机器人应用为例,执行老人摔倒帮扶这类应急指令时,推理耗时若达到2分钟将完全不可用,低时延是物理AI落地的核心要求。
边缘/端侧推理是物理AI落地的刚需,可采用边端结合的部署模式补足云端算力短板:一种路径是在机器人本体配置端侧算力,支撑实时推理;另一种路径是搭建边缘算力系统,例如工厂可在本地部署专属边缘系统,所有端侧机器人接入局域网络内的边缘系统完成推理,可大幅提升响应速度,边端结合的模式可对云端算力形成有效补充,满足本地快速执行的场景需求。
当前边缘算力配置标准尚未明确,但边缘推理产业趋势确定性较强:目前物理世界大模型尚未完全跑通,也暂未落地到机器人端实现成熟应用,因此边缘侧需要配置何种规格的算力以支撑大模型推理还没有明确结论,但边缘、端侧算力并非伪命题,在机器人应用场景中属于必备要素,伴随物理AI逐步落地,边缘推理需求将明显提升,相关厂商有望受益。
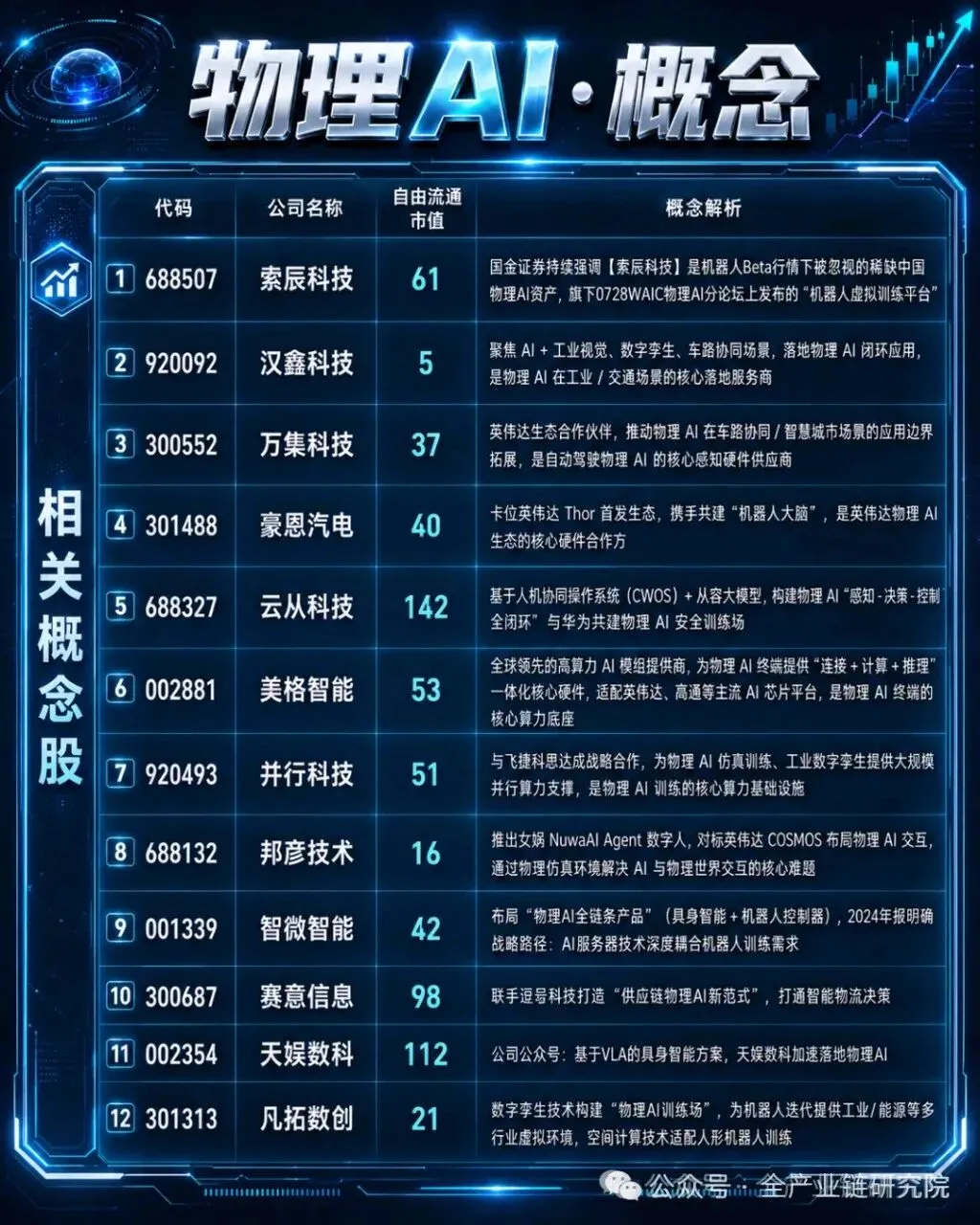
6、国内外物理AI进展对比
·国内外发展差异分析:物理AI领域面临与大语言模型相似的发展挑战,核心难点之一是对算力有较高要求。从全球发展格局来看,海外科技企业包括谷歌、亚马逊及多家头部机器人企业均在该领域投入大量研发资金。对比国内市场,当前布局物理AI赛道的市场主体数量较多,但行业集中度暂未呈现明确趋势。值得注意的是,物理AI属于资本密集、技术密集型产业,需要重资产投入支撑技术研发,当前国内布局机器人相关业务的企业普遍体量偏小,暂不具备独立研发世界模型的能力,后续相关企业若要实现技术突破,需要进一步开展融资,或与大型资本巨头达成深度合作,共同投入资源推进研发。
7、世界模型数据采集传感器要求
·数据采集核心传感类型:世界模型数据采集的核心数据类型涵盖视觉、触力觉、声音、关节运动数据四类,对应传感设备包括深度相机、六维力传感器、电子皮肤、麦克风等。当前仿真场景的仿真器逼真度极高,可模拟视觉、物理参数、运动参数等多维度信息,采集到的机器人感知数据与物理机器人的实际数据误差极小,也可采集机器人与外部交互产生的力、重量、摩擦等多类数据,和物理场景采集到的感知数据基本一致。物理场景下的数据采集则是通过机器人搭载的对应传感设备实现:视觉类数据通过景深相机采集,触力觉类数据通过六维力传感器、电子皮肤采集,声音类数据通过麦克风等设备采集,关节运动相关数据则通过对应传感设备采集,两类采集路径仅部署平台存在差异,核心采集的数据维度基本一致。
·视觉传感器方案选型:机器人场景下视觉传感器的核心选型为3D深度相机,是该场景区别于汽车等其他应用场景的核心配置,国内已有多家厂商布局3D视觉镜头模组、整机等相关产品。激光雷达并非机器人场景的必选传感设备,主要适用于轮式移动设备的行动避障场景,毫米波、超声波仅为个别有特殊需求的设备的选配传感设备。当前触力觉、电子皮肤类传感器的产业化进度较慢,尚未实现批量商业化落地,相关技术研发主要集中在研究机构及初创企业,距离大规模商业化应用还需要一定时间。