 夜雨聆风
夜雨聆风系列:Coach 别跑!AgentScope 源码拆解本篇:第 3 课 · Context 撑爆了?它选择压缩前情:第 2 课我们翻遍了 Memory 抽屉,发现每次 reply() 都往里塞两条消息
① 「教练,抽屉快撑爆了」
徒弟盯着屏幕,突然回过神:
等等,上节课你说 context 是个 Python list,每聊一轮往里塞两条。那聊 100 轮不就 200 条了?聊 1000 轮呢?大模型的上下文窗口又不是无限的!
教练放下茶杯:问得好。你猜 AgentScope 会怎么做?
徒弟想了想:
教练:选 C。而且它做得比你想象的更聪明。
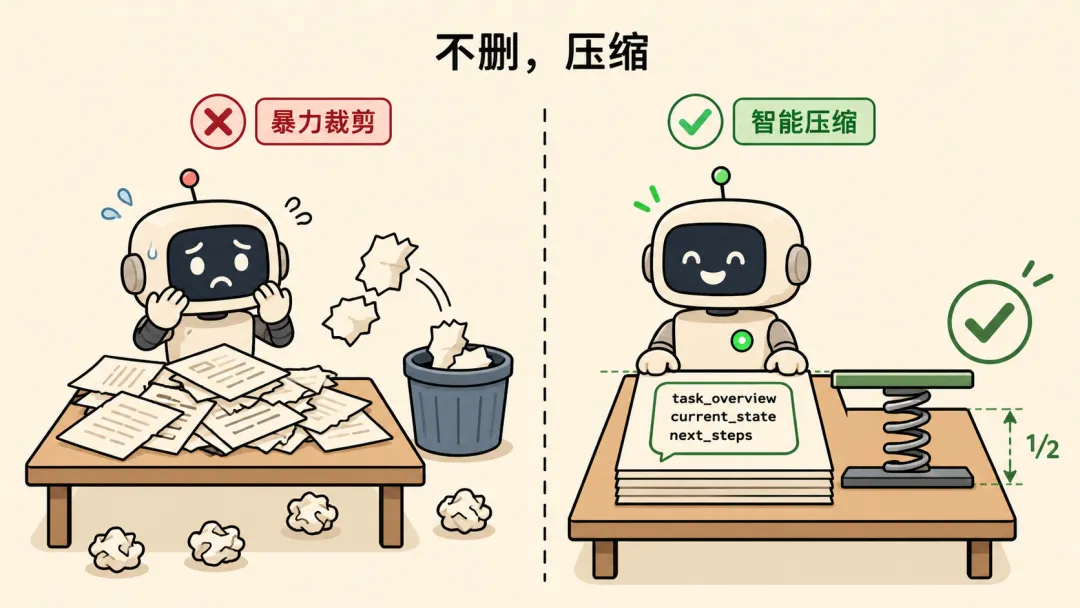
② 「它不是删,是『压缩』」
徒弟:压缩?用 zip 那种压缩吗?
教练:不是文件压缩,是让大模型自己写摘要。
你看这段源码,在 _agent.py 第 256 行:
async def compress_context(self, context_config=None): # 1. 数一数当前 context 有多少 token estimated_tokens = await self.model.count_tokens(...) # 2. 超了 80% 的窗口?触发压缩 if estimated_tokens < 阈值: return # 没满,跳过 # 3. 把旧对话喂给大模型 # 让大模型生成结构化摘要 res = await model.generate_structured_output( messages = 系统提示 + 旧对话 + 压缩提示词, schema = 摘要模板, ) # 4. 用摘要替换掉旧内容 self.state.summary = res.content self.state.context = 最近的消息.保留()教练敲了敲桌子:每次 Agent 要回复你之前,它会先看一眼——「我抽屉里的 token 有没有超过窗口的 80%?」,超了就压缩。
徒弟恍然大悟:所以它是在 _reply() 的入口处检查的?
教练:对,第 535 行。每次回复前先 compress,再推理。
③ 「看看它是怎么切的」
徒弟:那它是把整个 context 都拿去压缩吗?最近说的话会不会也丢了?
教练:这就是巧妙的地方——它只压缩旧的,留最近的。
看分割逻辑(_split_context_for_compression,第 1630 行):
context = [旧1, 旧2, 旧3, ..., 最近1, 最近2, 最近3] ↑ 拿去压缩 ↑ 保留不动怎么切的?从尾巴往前数:
① 从 context 最后一条消息开始② 一条一条往前加③ 直到快占满「保留区」(默认 10% 的窗口大小)④ 前面的全部归入「待压缩区」而且边界消息的处理很细腻——如果一条消息里既有工具调用又有结果,它会按 content block 粒度切分,不会把工具调用和结果拆散。
徒弟:哦!这不就是「最近的事记得清,旧事记个大纲」嘛。
教练:就是这个道理。
④ 「那摘要长什么样?」
教练:压缩之后,抽屉里多了个东西——self.state.summary。
打开看看:
<system-info># Task Overview用户在学习 AgentScope 的 context 压缩机制# Current State已掌握:context 超 80% 触发压缩,旧对话被 LLM 浓缩成摘要# Important Discoveries1. 压缩不是裁剪,是用摘要替换旧对话2. 有 3 层兜底机制3. 边界消息按粒度拆分,保证 tool_call 和 result 成对# Next Steps可以继续探索 Offloader 或 ReAct 循环# Context to Preserve用户偏好师父带徒弟节奏,做笔记到 source-notes/</system-info>这个摘要按 5 个结构化字段生成:-task_overview— 用户在干嘛(300字)-current_state— 干到哪了(300字)-important_discoveries— 踩了啥坑、有啥发现(300字)-next_steps— 接下来干啥(200字)-context_to_preserve — 用户喜好、承诺(300字)
以后 Agent 的系统提示里会带着这个 <system-info> 标签,等于它知道「前面聊过啥,但不用一字不差地记住每句话」。
⑤ 「那万一压不成功呢?」
徒弟:如果……压缩本身失败了怎么办?比如摘要太长塞不进去?
教练:你问到关键点了。AgentScope 准备了三层兜底。
第一层:保留太多,压了个寂寞
# reserve_ratio 设得太高# 虽然超了 80%,但旧对话全在「保留区」里# → 自动把 reserve_ratio 降到 0第二层:摘要太长,塞不进窗口
# 估算摘要的 token 数# 如果放不下,从旧对话里一条一条扔# 直到能塞下为止for i in range(1, len(msgs_to_compress) + 1): messages = msgs_system + msgs_to_compress[i:] + ... if 估算token数 < 窗口大小 * 0.8: break # 够了!第三层:Offloader — 硬盘备份
# 如果有配置 offloader# 压缩掉的原始对话会存到硬盘# 以后 Agent 可以按需回头查if self.offloader: path = await self.offloader.offload_context( session_id, msgs=msgs_to_compress, )徒弟感叹:这三层兜底一看就是踩过坑的。
教练笑:开源项目嘛,都是被生产环境教育出来的。
⑥ 「那我怎么调这些参数?」
教练:ContextConfig 类暴露了所有旋钮:
trigger_ratio | ||
reserve_ratio | ||
tool_result_limit | ||
compression_prompt | ||
summary_template |
from agentscope.agent import ContextConfigmy_config = ContextConfig( trigger_ratio=0.75, # 75% 就压,早点清 reserve_ratio=0.15, # 多留点最近的对话 tool_result_limit=2000, # 工具结果超过 2000 token 就截断)agent = Agent( name="我的助手", model=model, system_prompt="...", context_config=my_config, # 👈 传进去就行了)徒弟:那如果模型窗口是 65536(deepseek-chat),80% 就是 52428 token 才触发压缩……实际上很少聊到这么多?
教练:是的,大多数场景几十轮对话就触发了。但遇到工具调用特别多的场景,一步推理可能产生几万 token 的工具结果,这个机制就救命了。
一图胜前言
⑦ 课后总结
徒弟整理笔记:
ContextConfig |
教练:完美。
番外篇预告:Context 压缩机制
本文已经把压缩机制讲完了。但在实际源码中,
compress_context()是在_reply()里被调用的——它是 ReActAgent 推理循环中的一个环节。下节课我们回到主线,拆解 ReActAgent「想一下→动一下→再想一下」 的核心循环。到时候你会看到:压缩是怎么插入在这个循环里的,以及它和工具调用、结果处理是怎么配合的。
本系列用师徒对话拆解 AgentScope 源码原理,欢迎转发给同样好奇的朋友。关注「黑夜向日葵」,每周拆一个源码零件。
