 夜雨聆风
夜雨聆风
AUTOSAR CP多核软件实施全解析: 硬件多核选好了,软件怎么把多核真正用起来? |
|
上一篇讲了芯片多核的四种硬件分类(SMP / AMP / Lockstep / big.LITTLE),很多工程师问: "硬件多核我理解了,但AUTOSAR CP跑在上面,软件到底怎么用多核?" 这个问题问到了关键。硬件多核是"有了多个工人",软件多核是"怎么让多个工人真正协同干活,不打架、不抢材料、不互相干扰"。 本文从Cache基础讲起(这是理解所有多核软件问题的物理根基),然后逐一拆解AUTOSAR CP多核实施的四大核心机制:Multi-Core OS、IOC、SpinLock、ActivateTaskAsynchronous,最后用一个完整流程把四者串起来。 读完这篇,你不仅能看懂多核AUTOSAR配置,还能避开项目里最常见的多核踩坑。 |
一、铺垫:Cache,多核软件问题的物理根源
要理解AUTOSAR CP多核软件,必须先理解Cache。这不是"额外知识",而是所有多核软件问题的物理根源——不理解Cache,IOC、SpinLock、跨核通信你永远只能"记住结论",无法"理解为什么"。
1.1 为什么需要Cache?
CPU的速度和内存的速度差距极大,这是一个根本性的物理矛盾:
| CPU与存储器的速度差距 |
| 组件 | 访问延迟 | 类比 |
| CPU寄存器 | 0.3 ns | 手边的便签 |
| L1 Cache | 1 ns | 桌面上的文件夹 |
| L2 Cache | 4 ns | 旁边的抽屉 |
| L3 Cache | 10~20 ns | 办公室的文件柜 |
| 主内存(DRAM) | 60~100 ns | 楼下档案室 |
CPU每执行一条指令,如果都要去"楼下档案室"取数据,等待时间会让CPU 99%的时间都在空转。Cache的本质:把"近期用过"和"可能马上要用"的数据,提前搬到CPU身边的"小仓库"里,CPU直接从小仓库取,不用每次跑楼下。

| 关键概念:Cache Line(缓存行) |
|
Cache不是一个字节一个字节搬的,而是整块整块搬——每次搬 64 字节(ARM Cortex-A/M通常是32或64字节),这叫一个 Cache Line。 类比:去档案室取资料,不是只拿一张纸,而是把整个文件夹都带回来——反正一个项目的资料往往是连着用的,一次多拿几张反而更快。 |
1.2 写操作:Write-Back(回写策略)
这是最常见的Cache策略,也是多核问题的根源:
|
Write-Back(回写)策略: CPU写数据 → 只写到L1 Cache(快,1ns) → 不立刻更新主内存 → 主内存里的值还是旧的! → 只有这个Cache Line被"换出"时,才把数据真正写回主内存 |
问题来了:如果另一个核也在读同一块内存地址,它读到的是自己Cache里的旧值,不是最新值。
1.3 多核Cache不一致问题
这是整篇文章最重要的一个场景,务必理解:
|
场景:两个核各有自己的L1 Cache 初始状态:主内存 addr 0x1000 = 100 Step 1:Core0 把 addr 0x1000 读到自己的L1 Cache,值是 100 Step 2:Core1 把 addr 0x1000 读到自己的L1 Cache,值也是 100 Step 3:Core0 写 addr 0x1000 = 200(只写到Core0的L1 Cache) 此刻三个地方的值: → Core0的L1 Cache:0x1000 = 200 ← 新值 → Core1的L1 Cache:0x1000 = 100 ← 旧值,脏了! → 主内存:0x1000 = 100 ← 也是旧值 Core1读到的是100,但实际值是200——Cache不一致(Cache Incoherence)。 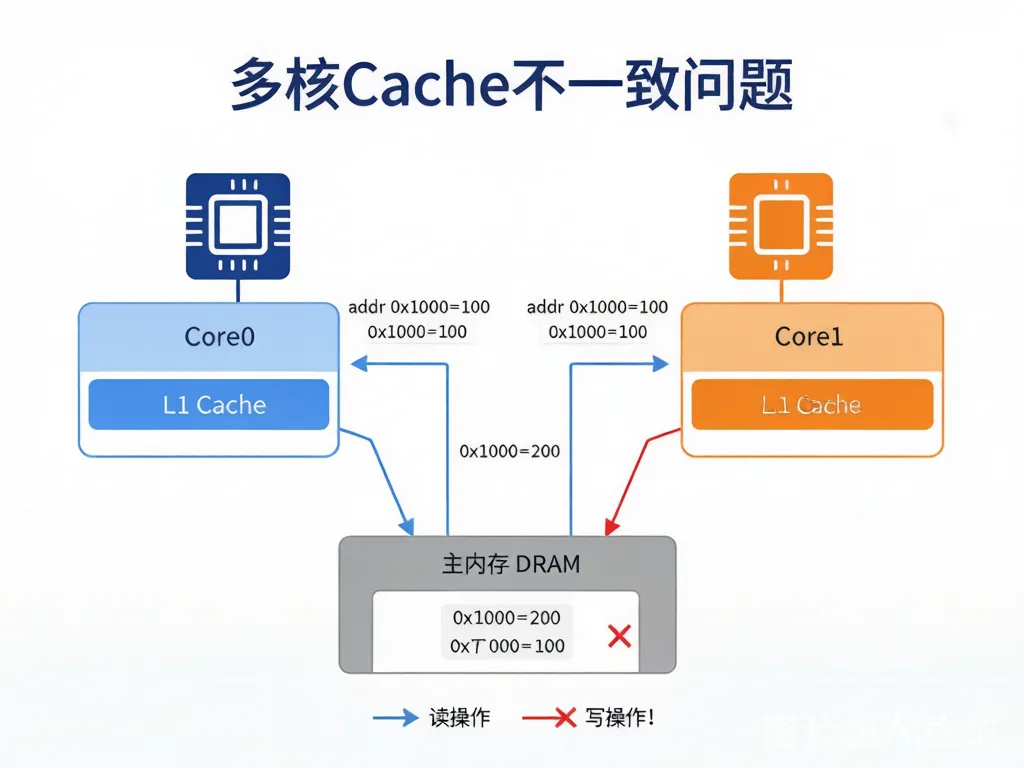 |
1.4 两种解决方案
方案A:硬件Cache一致性(SMP的做法)
在多核SMP处理器里(比如4×A55的MPU侧),硬件实现了MESI协议(一种监听总线的机制):
|
Core0写 0x1000 = 200 → 硬件自动广播「0x1000被我改了!」 → Core1收到广播 → 自动把自己L1 Cache里0x1000那行标记为「无效」 → Core1下次读0x1000 → Cache Miss → 重新从内存取到200 ✅ |
对软件完全透明,工程师感知不到这个过程。这就是为什么Linux/QNX跑SMP不需要手动处理Cache。
代价:MESI需要额外的总线带宽和硬件电路,核越多成本越高。
方案B:软件手动管理(AUTOSAR CP MCU侧的做法)
Cortex-M7(S32G2的MCU侧)核间没有硬件Cache一致性。AUTOSAR的IOC通过两个指令解决:
|
Flush(清除/清洗):把Cache里的数据强制写回内存 → Core0写完数据后:DSB + D-Cache Flush → 强制把Core0 L1 Cache里的新值写回主内存 Invalidate(使无效):强制下次从内存重新读取 → Core1读数据前:D-Cache Invalidate → 把Core1 L1 Cache里这个地址的数据标为无效 → 下次Core1读时,强制从主内存取(取到Core0写的新值) |
| Flush 和 Invalidate 必须配合,缺一不可 |
| 步骤 | 谁做 | 时机 | 遗漏的后果 |
| Flush | 发送方(Core0) | 写完数据后、通知Core1前 | Core1读到的还是主内存旧值 |
| Invalidate | 接收方(Core1) | 读数据前 | Core1读到自己Cache里的旧值 |
AUTOSAR IOC的内部实现把Flush + 内存屏障(DMB/DSB)都封装好了,所以工程师只用调 IocSend() 就够了。
1.5 I-Cache 和 D-Cache
Cache其实分两种,分开讲就清楚了:
| I-Cache(Instruction Cache)vs D-Cache(Data Cache) |
| 对比 | I-Cache(指令Cache) | D-Cache(数据Cache) |
| 存的是什么 | 程序指令(编译后的机器码) | 变量、数组、结构体等数据 |
| 谁访问 | CPU取指单元(自动,无感知) | CPU读/写数据时 |
| 多核一致性问题 | 较少(代码不变,大家都一样) | 主要问题来源 |
所以昨天说的Flush和Invalidate,都是针对D-Cache。I-Cache也有Invalidate,但场景特殊(OTA刷写程序时才用到)。日常AUTOSAR开发遇到的Cache问题,99%都是D-Cache的问题。
二、AUTOSAR CP Multi-Core OS 架构
Cache基础讲完了,现在进入正题:AUTOSAR CP在多核硬件上,OS是怎么组织的?
2.1 一个OS,还是多个OS?
AUTOSAR CP多核的设计是:每个核有自己独立的OS实例。
这不是一个OS管多个核(那是SMP的Linux做法),而是:
|
Core0 → OS实例0(独立调度器、独立任务列表、独立栈) Core1 → OS实例1(独立调度器、独立任务列表、独立栈) 类比:不是一个大厨房主管统管两个厨师,而是两个厨房各有一个主管,他们用对讲机协调。 |
这个设计和Linux SMP有本质区别,根源在于汽车实时性的要求:任务必须在确定的时间内完成,不能因为"OS把我的任务调度到了另一个核"导致Cache状态不可预测。
2.2 启动流程:谁先跑起来?
多核芯片上电后,硬件决定哪个核先启动(通常是Core0,叫"主核/Boot Core"):
|
// 上电后: Core0 先启动(硬件决定) → main() 初始化基础BSW → StartCore(CoreID_1, &entry_Core1) // 唤醒Core1 → StartOS(AppMode) // Core0的OS开始调度 Core1(被唤醒后) → 进入 entry_Core1() → StartOS(AppMode) // Core1的OS开始调度 |
两个StartOS()各自独立跑起来,之后Core0和Core1的任务并行执行。
2.3 Task如何分配到核?
全部通过配置(ARXML),静态绑定,不能运行时改变:
|
<!-- ARXML配置示例 --> <OS-TASK> <SHORT-NAME>Task_SafetyControl</SHORT-NAME> <OS-APPLICATION-REF>App_Safety</OS-APPLICATION-REF> <CORE-AFFINITY>0</CORE-AFFINITY> <!-- 绑定到Core0 --> </OS-TASK> |
工程师用工具(Vector DaVinci、EB Tresos)配置,生成代码后这个绑定就固化了。
| 关键约束(必须理解) |
| 约束 | 说明 |
| 一个Task只能跑在一个核上 | 不能漂移,不能运行时迁移 |
| 优先级只在本核内有意义 | Core0优先级10 vs Core1优先级10互相无关 |
| 跨核通信必须用IOC | 不能直接访问另一个核的全局变量(Cache问题) |
三、IOC:核间通信的正规渠道
理解了Cache问题,就能理解为什么需要IOC。很多工程师会想:两个核共享内存,我直接写一个全局变量不就行了?
3.1 为什么不能直接共享全局变量?
|
坑一:Cache不一致 Core0写的数据在Core0的D-Cache里,Core1读的还是旧内存值 → Core1永远读到脏数据。 坑二:原子性破坏 Core0写32字节结构体时,Core1中途读 → 读到半新半旧的破损数据。 |
AUTOSAR的解决方案是IOC(Inter-OS-Application Communication)——一套OS托管的跨核通信机制,把Cache刷写、内存屏障、原子保护全部封装好。
3.2 IOC的两种通信模式
模式一:Sender / Receiver(最常用)
就像传递一个信封:Core0写进去,Core1读出来。
|
// Core0侧(发送方): IocSend_VehicleSpeed(speedValue); // 写入IOC缓冲区,OS自动处理cache flush // Core1侧(接收方): Std_ReturnType ret = IocReceive_VehicleSpeed(&localSpeed); if (ret == IOC_E_OK) { // 用localSpeed做计算 } |
模式二:Group(多个信号打包发送)
一次发多个变量,保证一致性(要么全新,要么全旧,不会部分更新):
|
// 定义Group:把车速、档位、踏板开度打包 IocWrite_Group_VehicleState(speed, gear, pedalPos); IocSend_Group_VehicleState(); // 一次性发送,保证原子性 |
3.3 IOC、全局变量、COM 对比
| 三种跨核/跨ECU通信方式对比 |
| 对比维度 | 直接全局变量 | IOC | COM(信号) |
| 跨核安全 | ❌(Cache问题) | ✅ | N/A(ECU间) |
| 性能开销 | 最低 | 低 | 高(协议栈) |
| 使用场景 | 同核内 | 跨核、同片 | 跨ECU |
| AUTOSAR规范 | 不是规范机制 | OS Spec | COM Spec |
四、SpinLock:跨核临界区保护
IOC解决了"数据怎么传"的问题,但还有一种场景:两个核需要操作同一块共享内存(比如一个环形缓冲区),怎么保证互不干扰?
4.1 为什么普通Resource(OS Mutex)不够用?
AUTOSAR CP有Resource机制(类似互斥锁),但它只保护同一个核内的并发访问。
问题:如果Core0和Core1都需要操作同一块共享内存,Resource解决不了——因为它只管本核的抢占调度,对另一个核的CPU完全无感。
SpinLock(自旋锁)是跨核互斥的解决方案。
4.2 SpinLock工作原理
底层是处理器的原子指令(ARM的LDREX/STREX,AURIX的CMPSWAP):
|
// 伪代码:SpinLock获取过程 Core0: LDREX [lock_addr] → 读当前值(0=空闲,1=占用) STREX [lock_addr] = 1 → 尝试写1 → 如果写成功:获得锁 ✅ → 如果写失败:loop回LDREX再试("自旋"等待)⏳ |
"自旋"这个词就来自这里——拿不到锁的核原地打转循环等待,而不是休眠。
实际使用AUTOSAR API:
|
// AUTOSAR API使用: GetSpinlock(SpinlockId_SharedBuffer); // 尝试获取锁,拿不到就spin等待 // ── 临界区 ── SharedBuffer[idx] = newData; idx++; // ────────── ReleaseSpinlock(SpinlockId_SharedBuffer); // 释放锁,另一个核可以获得 |
4.3 SpinLock最危险的坑:死锁
死锁场景一:自旋等待时高优先级任务抢占
|
问题场景: Core0 Task_Low(低优先级)获得SpinlockA → 被Task_High(高优先级)抢占 Core0 Task_High需要SpinlockA → 开始spin → Task_High占着CPU,Task_Low永远无法被恢复执行 → DEADLOCK(死锁) |
AUTOSAR的规避方式:GetSpinlock()调用时OS会锁定本核调度器(不允许更高优先级任务抢占),等释放SpinLock后才恢复。所以持有SpinLock期间,本核不会被抢占。
代价:持有SpinLock时相当于关了本核的抢占,临界区必须尽可能短!
死锁场景二:多个SpinLock嵌套,顺序不一致
|
Core0: GetSpinlock(A) → GetSpinlock(B) Core1: GetSpinlock(B) → GetSpinlock(A) → Core0持有A,等B Core1持有B,等A → 死锁 💀 |
AUTOSAR的规避方式:AUTOSAR OS支持配置SpinLock顺序约束,工具(DaVinci/EB)会检查是否存在循环依赖。实际项目里规则很简单:全项目统一SpinLock获取顺序,严格按编号从小到大获取。
4.4 GetSpinlock vs TryToGetSpinlock
| 两种SpinLock获取API对比 |
| API | 行为 | 适用场景 |
| GetSpinlock | 一直spin直到获取成功 | 必须要获取,等多久都行 |
| TryToGetSpinlock | 立即返回,成功或失败 | 可以做备用逻辑的场景 |
|
// TryToGetSpinlock 示例: TryToGetSpinlockType result; TryToGetSpinlock(SpinlockId_Log, &result); if (result == TRYTOGETSPINLOCK_SUCCESS) { WriteLog(data); ReleaseSpinlock(SpinlockId_Log); } else { // 锁被另一个核持有,这次不写日志,下次再试 DropLogEntry(); } |
五、ActivateTaskAsynchronous:跨核激活任务
SpinLock保护了共享内存,IOC传递了数据,但还有一个需求:Core0上的事件触发了,需要让Core1去执行某个任务——怎么跨核"叫醒"对方的任务?
5.1 普通ActivateTask vs 跨核版本
同核激活(同步):
|
// Core0上的任务激活Core0的另一个任务 ActivateTask(Task_B); // 立即把Task_B放入Core0的就绪队列 // 如果Task_B优先级更高,当前任务被立即抢占 |
跨核激活(异步):
|
// Core0激活Core1上的Task_SafetyMonitor ActivateTaskAsynchronous(Task_SafetyMonitor); // Core0继续往下执行(不等Core1响应) // Task_SafetyMonitor会在下一次Core1 OS调度时被放入就绪队列 |
5.2 内部流程
|
Core0(调用方): ActivateTaskAsynchronous(Task_SafetyMonitor) → 写激活请求到跨核邮箱(共享SRAM) → 发IPI(核间中断)给Core1 → 立即返回,继续执行 Core1(响应方): ← 收到IPI(核间中断) → 进入OS ISR → 从跨核邮箱读取:哪个任务需要激活 → 把Task_SafetyMonitor放入Core1就绪队列 → 调度器下次运行时执行Task_SafetyMonitor |
关键认知:
| 这里的"异步"是相对Core0而言的——Core0发完请求就走了,Core1何时真正执行Task_SafetyMonitor取决于Core1的调度时机,有一定延迟(通常 < 1个OS Tick)。 |
5.3 典型使用场景
场景:Core0(网关Core)收到刹车信号,通知Core1(安全Core)进行紧急处理
|
// Core0(Gateway处理) TASK(Task_CanRxGateway) { // 接收到刹车踏板信号 if (brakeSignal > THRESHOLD) { // 通知Core1做安全响应(Core1跑的是Lockstep Core,ASIL-D) ActivateTaskAsynchronous(Task_BrakeSafetyResponse); } TerminateTask(); } // Core1(安全处理) TASK(Task_BrakeSafetyResponse) { // 执行ASIL-D安全逻辑 BrakeActuator_Apply(calculatedForce); TerminateTask(); } |
5.4 SetEventMultiCore:异步唤醒等待中的任务
除了激活任务,还可以跨核发事件(适合"生产者-消费者"模式):
|
// Core0唤醒Core1上WaitEvent中的任务 SetEventAsynchronous(Task_Core1_WaitingTask, EventMask_DataReady); |
适用场景:Core0做完数据处理,异步通知Core1来取结果(Core1之前在WaitEvent()中休眠,收到事件后醒来)。
六、四机制协同:一个完整的跨核流程
单独讲每个机制都不难,难的是把它们串起来——实际项目里,这四个机制是协同工作的。
| 完整跨核协同流程(Core0网关Core → Core1安全Core) |
|
Step 1 Core0上的Task_A运行 ↓ Step 2 需要更新共享缓冲区(两个核共享的环形缓冲) ↓ Step 3 GetSpinlock(SpinlockId_Buf) ← 确保Core1此时不在读↓ Step 4 写入共享缓冲区 ↓ Step 5 ReleaseSpinlock(SpinlockId_Buf)↓ Step 6 IocSend_ProcessedData(result) → IOC缓冲区(内部自动Flush Cache)↓ Step 7 ActivateTaskAsynchronous(Task_SafetyValidator) → IPI → Core1 OS↓ Step 8 Core1:Task_SafetyValidator被放入就绪队列 ↓ Step 9 调度器运行Task_SafetyValidator ↓ Step 10 IocReceive_ProcessedData(&data) → 内部自动Invalidate Cache,从IOC缓冲区读↓ Step 11 GetSpinlock(SpinlockId_Buf) → 读共享缓冲(也需要SpinLock保护)↓ Step 12 ...执行安全验证逻辑 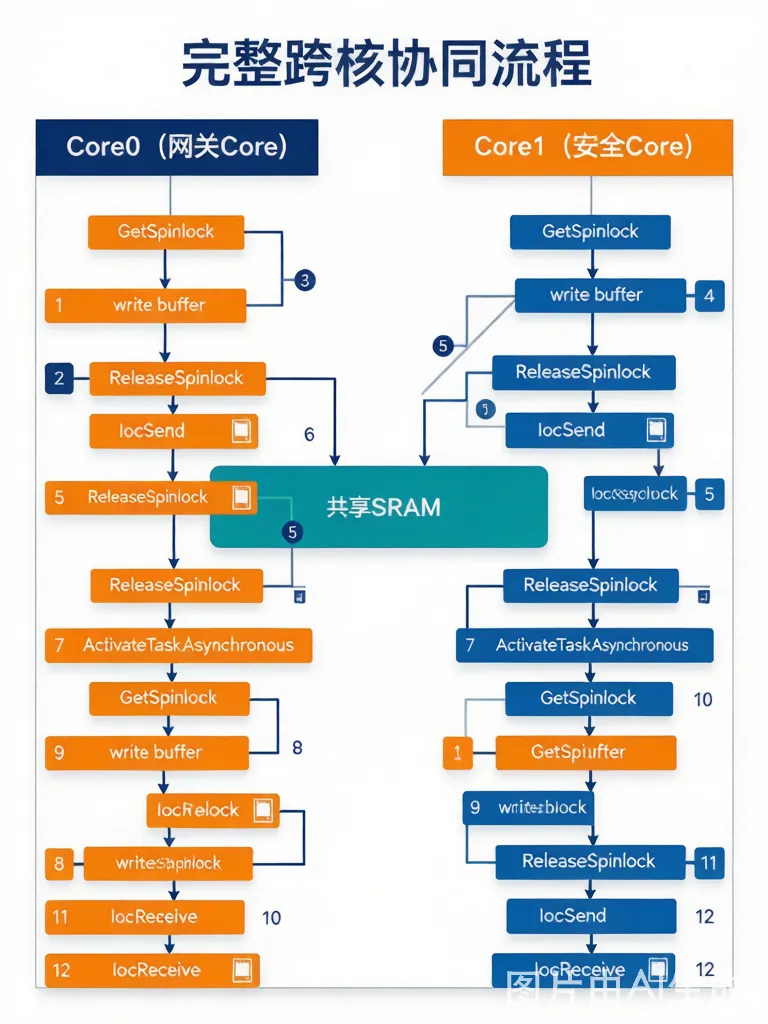 |
| 四机制分工总结 |
| 机制 | 解决什么问题 | 底层关键操作 |
| Multi-Core OS | 两个核各自独立调度,任务静态绑定到核 | StartCore() / CORE-AFFINITY配置 |
| IOC | 跨核传递数据,OS托管Cache一致性 | 内部Flush + Invalidate + 内存屏障 |
| SpinLock | 保护共享内存临界区,跨核互斥 | LDREX/STREX原子指令 |
| ActivateTaskAsynchronous | Core0触发Core1去执行某个任务 | 跨核邮箱 + IPI中断 |
七、工程师常见踩坑
讲了原理,最后列一下实际项目里最常见的多核踩坑,每一条都是真实项目事故的浓缩:
| ⚠️ 多核AUTOSAR五大常见踩坑 |
| 坑1 | 跨核直接访问全局变量 现象:Core1读到的数据偶尔是旧的,概率性故障,极难复现 正确做法:必须用IOC,或手动Flush + Invalidate + 内存屏障 |
| 坑2 | SpinLock临界区太长 现象:持有SpinLock期间本核高优先级任务无法抢占,导致实时性违规 正确做法:SpinLock只保护共享变量读写,不含任何计算逻辑,临界区 < 10μs |
| 坑3 | 多个SpinLock嵌套顺序不一致 现象:压力测试下偶发死锁,系统挂死 正确做法:全项目统一SpinLock编号,严格按编号从小到大获取 |
| 坑4 | ActivateTaskAsynchronous过度使用 现象:频繁跨核中断导致Core1调度抖动,实时性无法保证 正确做法:高频通信用IOC(共享内存轮询),只在"事件触发"场景用跨核激活 |
| 坑5 | 忽略内存屏障,编译器和CPU乱序执行 现象:syncFlag已经写了1,但数据还没写完,Core1误判数据就绪 正确做法:用IOC(内部已封装屏障),不要手写自旋锁而不加DMB/DSB |
八、总结
回到开头的问题:硬件多核选好了,软件怎么把多核真正用起来?
AUTOSAR CP的多核软件实施,本质是四件事:
|
下一篇预告:AUTOSAR CP多核的配置实战——用Vector DaVinci把上面讲的四机制真正配出来,从ARXML到生成代码,一步一步拆解。
|
如果这篇对你有帮助,欢迎关注公众号 嘉宋说汽车 15年汽车老兵,和你聊聊真实的行业与职场 |
|
本文结合行业公开资料与个人经验整理,仅代表作者个人观点,供读者参考。 作者:嘉宋 | 首发于公众号「嘉宋说汽车」 |
