 夜雨聆风
夜雨聆风那么,这个过程究竟在“拆”谁的台?它又是如何帮CPU“减负”的呢?

解密卸载(Offload)机制
在智算中心的后台,长期存在着一种被行业戏称为“算力中心税”的现象。简单来说,就是服务器每处理100分的网络流量,CPU可能就要消耗30分甚至更多的算力去处理与网络通信相关的“杂活”。
智能网卡所谓的“卸载(Offload)”,拆的就是这些“杂活”的台,把CPU从这些低效的底层劳动中解救出来。
1. 拆的是谁的台?——从CPU夺回“管辖权”
在传统架构中,CPU既要跑业务逻辑(如AI模型训练),又要管“后勤”(如网络数据包检查、封包解包、存储协议转换、流量安全加密)。
智能网卡的“卸载”,其实就是把这些“后勤工作”从CPU那里强行接管过来。主要卸载的领域包括:
●网络协议处理(Network Offload):比如TCP/IP协议栈的解析。过去CPU要处理每一个数据包,现在智能网卡在硬件层面直接完成,CPU只需处理最终的有效载荷。
●虚拟化与交换(Virtualization Offload):在云服务中,物理机上运行着多个虚拟机,网络流量需要进行虚拟交换(vSwitch)。这一过程极度消耗CPU,智能网卡通过硬件加速,让数据在虚拟机与网卡间直接流动。
●安全与存储(Security & Storage Offload):数据加解密、存储协议处理(如NVMe-oF)。这些本该消耗大量计算周期的任务,现在由智能网卡内置的硬件加速引擎直接处理。
2. 解密“卸载”的核心逻辑:分而治之
我们可以把智能网卡的工作比作一个“智能分流器”:
●关键任务留给CPU:CPU现在的角色是“CEO”,它只负责发出决策指令,比如“把这批模型参数传给隔壁服务器”。
●杂务交给网卡处理:智能网卡就像是“执行经理”,它负责把这个指令拆分成无数个小的数据包,通过底层复杂的网络协议(如RoCE/RDMA)高速送达目的地。
为什么这种“拆台”能提升性能?
●专用硬件的高效性:CPU是通用处理器,处理网络包像“大炮打蚊子”;智能网卡内置的FPGA或ASIC是专用硬件,处理特定协议效率极高,且时延极低。
●消除“内存拷贝”瓶颈:通过RDMA(远程直接内存访问)技术,智能网卡能直接读取服务器内存数据并发送,完全绕过了CPU。这在AI集群中至关重要——数据不再需要经过CPU的寄存器,从而彻底消除了传输瓶颈。
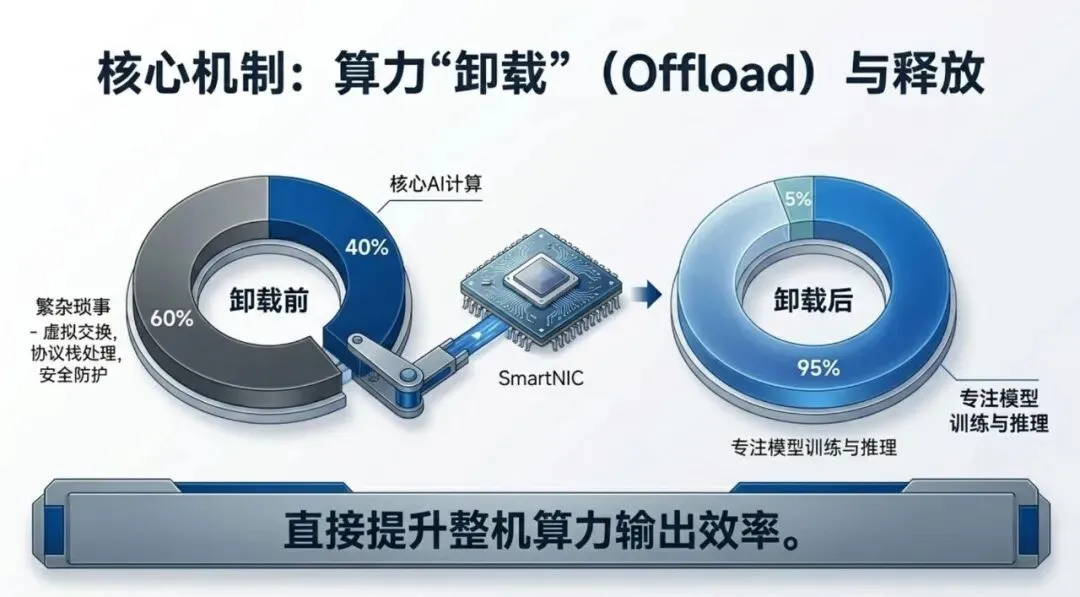
3. 卸载后的“算力增量”
当智能网卡把这些底层任务“拆”掉之后,最直接的收益就是:
1.CPU算力释放:原本被占用的30% CPU资源瞬间“空”了出来,这部分算力可以被用于处理更复杂的AI逻辑,或者在服务器上部署更多的虚拟机/容器,提升资源利用率。
2.集群通信加速:在大规模AI训练中,算力瓶颈往往不在GPU,而在网络通信。通过卸载,通信时延从毫秒级降至微秒级,这对于万卡级别的模型训练是质的飞跃。
“卸载”机制本质上是计算架构的重新解构。它通过将数据处理、网络协议、安全逻辑等底层功能“硬件化”,实现了CPU、GPU与网卡之间的分层协作。CPU不再是“全能苦力”,而是专注于算力的“大脑指挥官”。而智能网卡,则成为了连接智算集群的“高速物流总管”。

下一期预告:技术路线博弈——FPGA、ASIC与SoC,三种主流架构谁才是智算中心的“最终归宿”?
