当前时间: 2026-06-25 15:47:29
分类:办公文件
评论(0)
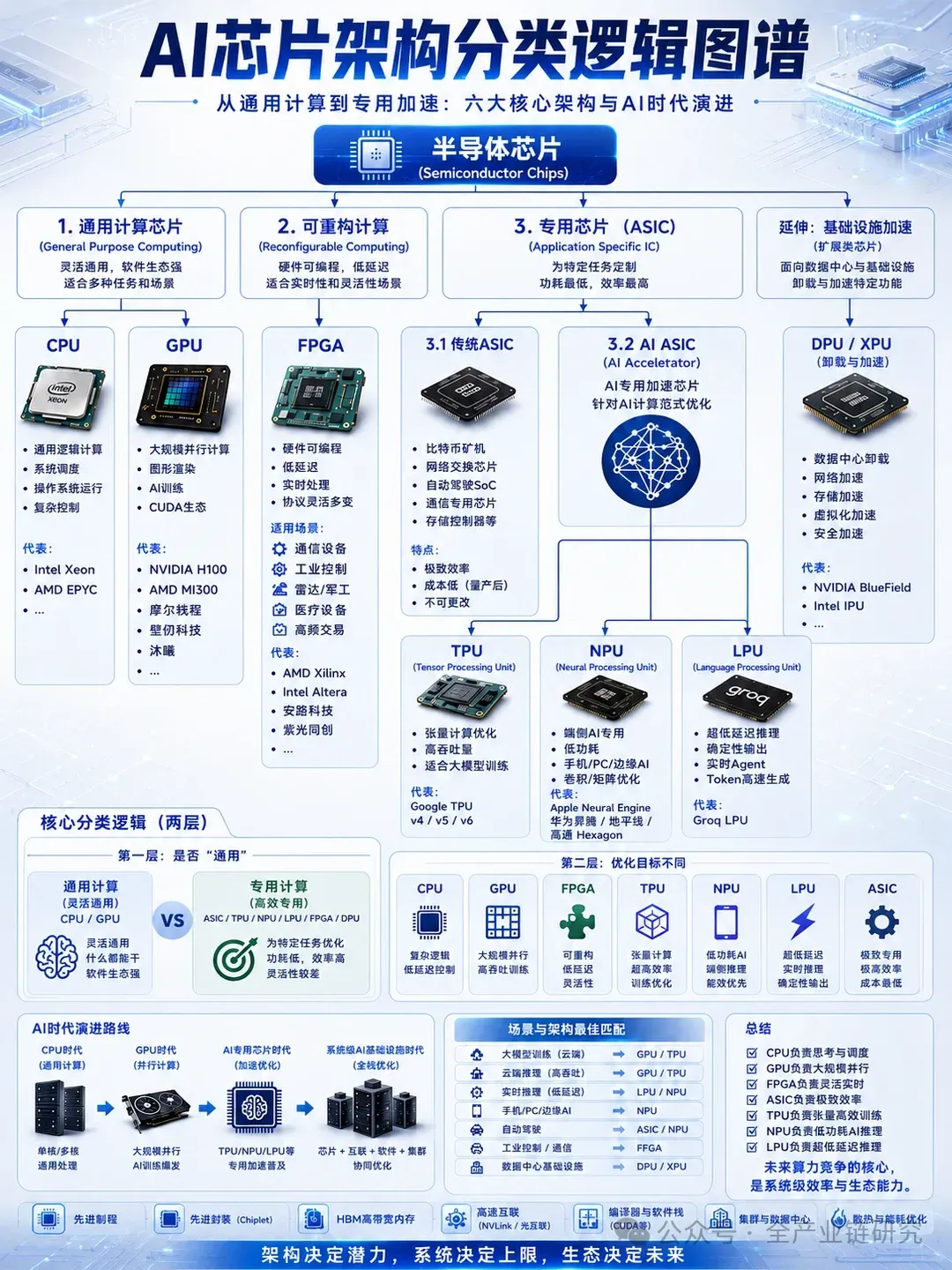
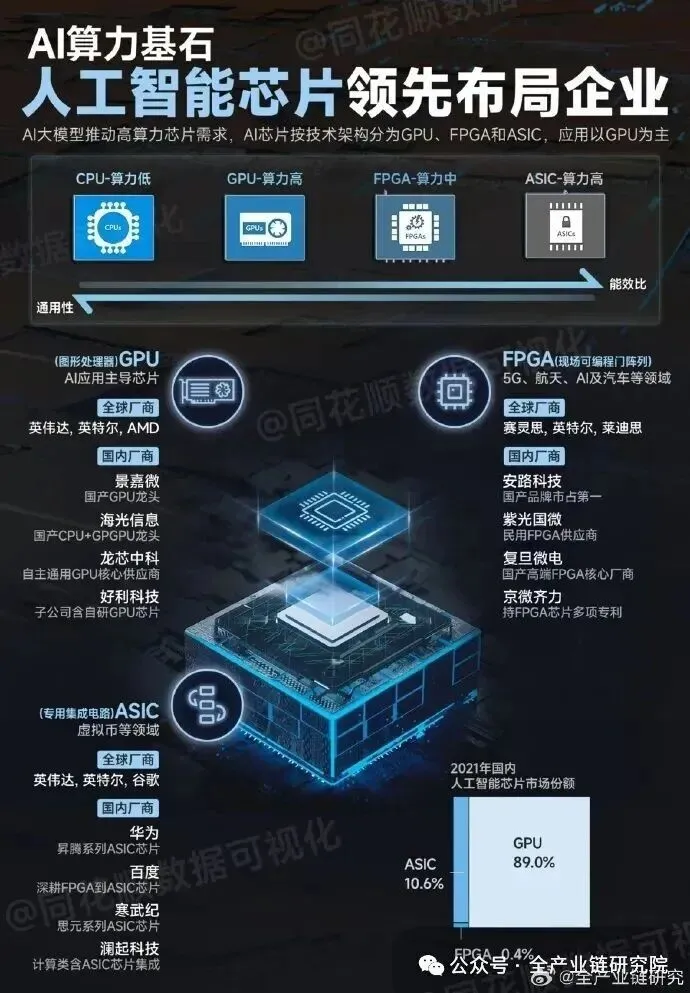
国产AI芯片行业交流核心观点·国产AI芯片评估指标与分类:国产AI芯片的核心评估维度包含四项:计算、显存、显存带宽、卡间互联,其中计算单元是国内不卡脖子的环节,因此国内多数芯片厂商甚至初创企业的算力指标普遍较高,部分厂商宣称其算力可达H100的数倍,2027-2028年性能将超过英伟达B系列,但该类表述仅指计算单项指标,其余三项指标普遍存在短板。目前可用于通用大模型推理的国产芯片仅包括昇腾910系列、寒武纪690、海光深算3,昇腾950核心适配PD分离场景,无法负担全面推理;天数及多数初创企业的芯片,无法支撑通用大模型推理,部分产品甚至连DeepSeek V4 Flash版的推理需求都无法满足,仅可适配OCR识别、语音转文字等简单场景。当前昇腾、寒武纪、海光等主流国产芯片普遍受限于产能,市场供不应求。·大厂国产芯片采购动态:zj采购天数芯片的体量约5-6万片,其中推理卡占比50%-60%,训练卡占比较低,因训练卡卡间互联能力弱于昇腾、寒武纪产品,无法支持大语言模型训练,仅旗舰推理卡可适配拍题解题OCR、NLP处理、离线语音转文字等简单场景,该采购是基于场景匹配的合理选择,可避免高性能芯片大材小用。寒武纪690当前市价约13万/片,公开渠道基本无折扣,仅大客户可享受框架协议折扣:zj与寒武纪的长期协议显示,2025年折扣低于8折,2026年折扣为8-8.5折,2027年折扣将进一步收窄甚至全价。寒武纪690出现市场溢价的核心原因是zj2027年预订量极大,一方面其自身采购量触及协议量阈值后将面临全价采购,另一方面将挤压其他企业的可采购额度,导致市场供给紧张,其余企业采购仅能享受2%-5%的微小优惠甚至出现溢价。·英伟达芯片消耗情况:当前国内进口英伟达芯片已全部用尽,仍无法满足推理需求,各型号消耗及缺口如下:a. A100:C端算力场景包括豆包、千问、AI支付等,叠加简单Agent、图片处理需求后,总需求约相当于30-40万片A100,已超过国内A100总进口量,存量已全部耗尽;b. H20:国内H20进口量约150万片,2026年底预计50%将被云计算场景消耗,云计算需求主要来自豆包、千问、智谱等闭源模型,以及优先适配H架构、最低要求使用H20的DeepSeek V3/V4版本,剩余50%H20供给企业内部研发,分摊到各家后供给并不充裕;c. H100/H800:生成视频场景下H100/H800供不应求,受C站32.0相关需求拉动,客户仍处于排队状态。·国产算力供给与置换需求:当前国产算力供给紧张,叠加老款英伟达卡置换需求,缺口将持续扩大:a. 现有国产供给:仅昆仑芯、平头哥、寒武纪690、昇腾910可支撑通用大模型推理,寒武纪590无法支持激活参数大于32B的通用大语言模型推理,仅可用于国央企简单办公分析场景;上述可用国产卡过去一两年总交货量不高,当前已基本被全部使用,预计2026年三四季度将出现明显算力短缺;b. 置换需求:到期下架的1柜英伟达卡需要3-5柜国产卡才能实现算力替代,2027年将迎来V100、A100、A30等老款英伟达卡的置换高峰,置换需要更多IDC空间及光通讯等耗材投入,建设周期长、成本更高;c. 缺口预判:除今年下半年缺二三十万片国产卡、明年缺一两百万片国产卡的预期外,明年还将有大量禁售的高性能老款英伟达卡下架,进一步加大国产算力缺口,因此国内头部公司已提前预订国产旗舰芯片,同时采购多厂商产品形成“全家桶”布局。·DeepSeek迭代的行业影响:DeepSeek V4技术进步明显,是重新预训练版本,技术复杂度较此前版本大幅提升,多数企业难以轻易启动重新预训练,因此扩散性、复用性较V3、R1下降。V3、R1属于大模型发展早期的技术,结构相对简单易复用,其中R1还打破了O3推理模型的闭源封闭属性,因此普及速度较快。DeepSeek V3/V4优先适配H架构,最低需H20芯片支持,若明年DeepSeek V5发布后表现优异且开源,将对云服务商(CSP)的大模型布局产生两方面影响:一是动摇CSP高投入自研大模型的意愿,二是推动CSP优先适配支持V5的芯片,类似当前H20向云服务倾斜的趋势,大概率会被多数头部CSP接入,如同此前云服务接入MySQL、Oracle等PaaS服务的模式。·下游应用算力需求特点:国内下游应用算力需求可分为三类场景,对应不同的芯片适配要求:a. 浅层Agent应用场景:国内浅层Agent应用(如自媒体营销智能体等)数量多,任务思考复杂度低,该需求将从今年延续到明年,会带动柜外CPU需求上涨,适配寒武纪690、昇腾950、昇腾910C等芯片即可满足需求,前提是解决公有云推理的虚拟化问题;b. 云厂商行业解决方案场景:国内CSP偏好布局手机、汽车、生产制造、物联网等行业解决方案,这类场景任务简单、覆盖行业广量级大,天枢之心、壁仞木兮、燧原等中低端国产卡均可适配,缺卡背景下多品牌芯片混用是必然趋势;c. 限定场景C端应用:微信Agent、AI支付等限定场景应用不会出现通用类问题,推理复杂度大幅下降,也可适配低算力国产卡。目前国产卡的短板为卡间互联能力不足,解决后虽效率有限但可使用,国产卡上云可满足CSP主流模型场景需求,但需较长建设周期,2026年下半年相关建设已启动,应对英伟达芯片短缺、明年英伟达供给衰减的趋势。·编程场景算力分层:编程场景算力需求分为三个层级,不同层级对应模型参数与适配芯片差异明显:a. 简单编程场景:仅处理代码找bug等简单需求,仅需10B左右参数的编程模型即可满足;b. 复杂编程场景:承接长项目新功能开发等需求,仅需20B左右参数的编程模型即可满足;c. 全功能开发场景:依据含图片、网页的复杂设计文档开发APP等需求,才需要调用全参基模。前两类场景均可适配二档、三档国产卡,但受芯片算力效率限制,相关业务盈利空间较低。·国产AI芯片迭代进度:2026年下半年专业芯片公司产品迭代节奏偏保守,产能约束问题突出,尤以昇腾系列为代表,网传昇腾950PR年产能75万片的说法不符合实际。各厂商新品进度如下:a. 昇腾950DT最早2026年11-12月推出样片,或推迟至2027年;384超节点涉及封装等工序,产能远低于950系列芯片;b. 寒武纪790 2026年不会推出,预计2027年下半年面市;c. 海光深算4 2026年下半年仅能推出样片;d. 沐曦、燧原等厂商新一代芯片2026年下半年推出概率极低。·上游配套需求与成本:国产GPU普及将带动光通信类组网需求双向增长:一方面新增算力供应以国产卡为主,另一方面英伟达老旧卡需提前替换为国产卡,机柜、机房用量随之增加,叠加国产GPU需配套高速互联设施保障利用率,直接拉动光模块、光通讯、光路由需求显著上升。其次GPU相关核心元件价格呈持续上涨趋势,2026年初已发生一轮涨价,预计2027年仍将延续涨价态势,HBM等GPU直接元件涨价将带动国产GPU及CSP端IC价格整体上调。此外AI应用落地拉动通用存储及CPU需求增长:ChatBot日活、Agent应用、AI支付等各类AI应用运行时,每个DAU都需锁定固定DRAM、SSD空间,Agent使用量越大,DRAM、SSD需求增长越明确,CPU需求也与应用规模呈正比例增长。·软件栈适配模式分类:主流国产AI芯片均适配PyTorch,PyTorch是模型训练写代码时的辅助框架,通常与CUDA搭配运行,CUDA负责调度GPU运行逻辑与数据流转,二者封装形成的kernel为整体代码运行单元。当前国产芯片的软件栈适配可分为三类:a. 完全不兼容CUDA路线,代表厂商为昇腾、寒武纪:昇腾采用自有CANN生态,适配需对接售后联调、不同场景参数调优,人力成本较高;寒武纪无类似CANN或CUDA的配套体系,投入人力自主编写kernel后可实现一劳永逸,字节在寒武纪适配投入较大、适配速度最快,对其他企业而言适配昇腾与寒武纪的成本相近,选择时优先考虑产能因素,昇腾在字节以外的企业中接受度更高。b. 部分兼容CUDA路线,代表为木犀、燧原等中游旗舰芯片,这类产品不改写代码存在性能损耗,改写代码又因部分不兼容导致性能回报较低,不是头部企业的首选。c. 完全兼容CUDA路线,这类产品适配成本低但无法完全发挥芯片性能,适合中小企业、青云、UCloud等中部云平台,这类客户没有过高的并发与任务量需求,可节省前期投入,直接适配即可满足需求。·非旗舰国产芯片应用前景:国内B端市场第一大类为国央企私有化部署项目,要求全自主可控,模型优先选用国内公司自研闭源模型如DeepSeek,推理卡要求使用国产产品,涵盖昇腾、寒武纪、昆仑芯、平头哥等厂商:a. 昆仑芯单柜效果好、机动性强,适配私有化部署场景;b. 平头哥结合阿里云生态,含光、玄铁系列整合后的推理方案效果较好。当国产芯片可支持60B左右参数模型推理时,将对市场产生质的影响:一方面可优化当前多卡适配的"大杂烩"现状,帮助云服务商找到服务质量与价格的更好平衡点;另一方面可拓展B端大规模应用、更大规模模型私有化部署、端侧应用等多个市场,降低商业场景拓展的成本与风险,加速国内AI应用市场拓展。·海外芯片厂商前沿布局:英伟达收购LPU是出于长期模型推理布局的考量,今年GPT-5后续推出的Flash版本可实现几十到几百毫秒级的推理速度,Token价值分为两个分支:一是高复杂度推理场景算力消耗大,二是超快响应场景用户感知近乎无感,是AI能力的质的突破。英伟达布局R系列(适配复杂推理场景)与DPU(适配快速响应场景)两条产品线,覆盖全场景推理需求,其布局更侧重长期用户体验优化,与国内芯片厂商的布局存在差异。·英伟达卡生命周期与回报:英伟达V100及以上型号芯片官方建议5年进入维护期,6-7年故障率上升,使用寿命上限为8年,企业需提前做好数据备份准备。芯片投资回报节奏取决于模型与商业化落地情况,不同场景回本速度存在差异:a. 推荐模型训练场景下,A100较V100可将模型训练周期缩短7-10倍,小模型场景仅需部署数百卡A100即可达到良好训练效果,2-3年即可收回硬件投入成本;b. 高毛利类AI模型(如C-Dense类模型)毛利水平可达50%-60%,前期研发成本约1年即可完成回收,第2-3年可覆盖硬件投资成本,3-4年即可进入净利阶段。·高通相关芯片性质说明:高通相关合作芯片不属于严格意义上的AI GPU或类GPU产品,定位为数据中心服务器内的信号信息处理辅助芯片,并非独立CPU或GPU产品,不归属AI芯片范畴。·国产AI芯片渗透率情况:不同统计口径下国产AI芯片渗透率存在差异:严格口径下,通用大语言模型预训练对算力要求极高,仅昇腾、海光等万芯超节点可满足200B、400B参数模型训练需求,国内该类超节点落地数量极少,当前仅昇腾950DT搭配384超节点集群可支撑相关训练,目前该产品尚未量产仍处纸面阶段,因此严格口径下国产卡用于通用大模型训练的占比极低。若放宽统计口径至小参数模型训练、搜广推训练等场景,寒武纪590等国产卡已有落地应用,渗透率符合今年30%左右的预期。·存算一体技术应用前景:存算一体、可重构新框架应用场景存在局限性,主要适配端侧算力、边缘计算、私有化离线场景(如银行未联网的厅堂服务机器人节点等),无法成为BC端通用模型服务的主力算力支撑。大厂仅在匹配的特定边缘业务线有采购可能,主流通用大模型相关应用与该类技术无直接关联。·算力租赁行业现状:国内算力租赁行业呈现两大特征:一是进货端,英伟达芯片是算力租赁市场主流选择,单位算力成本低于国产卡,当前进货渠道持续收窄,产能极不稳定,今年年初供应偏紧,年中有所宽松。二是商业模式存在明显痛点:a. 风险成本转嫁,出租方仅提供网络互联、通电等基础服务,合规风险全部由承租方承担,导致租赁价格偏高,B200算力为H100的5倍,租赁价格已达H100的4-5倍,承租方价差收益空间极低;b. 集群利用率偏低,出租方无动力投入虚拟化、软件适配、模态适配等运维成本,承租方也不会为短期租赁的算力投入优化成本,国内租赁算力集群利用率仅20%-30%,远低于海外本土使用的40%-50%水平,整体买卖双方利润空间均较薄,仅能满足缺算力的刚性需求。·Agent对CPU需求的拉动:当前Agent尚未带动CPU需求大幅增长,可从两类消耗场景拆解需求特点:a. 调度类需求:消耗极低,1个物理核可支持上万个Agent任务调度,C端国内基本无直接Agent市场,现有产品仅付费用户可使用Agent功能,规模极小,即使是几亿日活的调度需求,最多仅需数千到一两万颗CPU即可覆盖;B端Agent多为企业内部独立任务调度,仅需给每个企业分配少量线程,十万级GPU仅需配套数千颗CPU即可满足B端Agent调度需求。b. 执行类需求:仅开网页、做PPT、检索数据库等场景产生CPU消耗,C端免费用户仅分配少量CPU资源、排队执行,仅付费用户可优先满足高消耗需求,整体CPU消耗完全可控;B端Agent仅需内部数据库检索,无Office类高消耗需求,执行端CPU需求极低。整体当前CPU需求尚未进入爆发阶段。·2026-2027年算力瓶颈:2026-2027年算力瓶颈仍在先进制程,先进制程仍是算力密度提升的核心支撑,不能因当前5nm、3nm等先进制程攻关存在难度就否定其必要性。非先进制程的立体堆叠方案可行性低于先进制程路线,核心难点包括:一是立体堆叠模组内部、成品卡之间的互联均存在明显传输损耗,算传比问题难以解决;二是当前国产芯片单位算力成本已高于英伟达,立体堆叠会进一步推高成本,同时降低产品良率,正推、倒推均显示非先进制程路线可行性不足。·云厂商AI盈利与资本开支:国内云厂商AI业务盈利水平偏低,核心制约因素包括:一是算法、算力共同导致推理成本偏高,海外OpenAI早期模型毛利率至少70%,而国内自研闭源模型乐观毛利率仅30%左右,新客户折扣会进一步压缩毛利;二是国内头部CSP均布局自研闭源模型,同质化竞争程度远高于海外,将持续压低行业毛利,仅同时具备流量、模型、算力三重优势的头部厂商可获得更高毛利,其余通用大模型厂商毛利维持低位。资本开支层面,头部云厂商资本开支将持续增长,但投入方向和增速存在明显差异:火山引擎布局覆盖Data Agent、Tree AI、手机汽车行业解决方案、AI操作系统等多场景,同时需采购核心基建与国产芯片,开支增速最高;阿里云传统云服务成熟,当前重点推进传统云到AI云的客户转化,资本开支上调比例相对较低;腾讯云仍处于模型投入阶段,需先投入算力搭建模型再对外提供AI服务。·国产化各环节进度对比:当前国产化三大核心环节进度差异明显:a.GPU环节:整体进步较慢,受商业化驱动明显,国内厂商优先匹配国内市场需求,今明两年高性能推理芯片缺口较大,因此优先推出匹配需求的950P产品,将950DT研发延后,间接放缓了对标英伟达综合能力的技术追赶节奏;旗舰厂商寒武纪790虽稳步提升综合能力,但整体进步速度偏慢,英伟达技术门槛较高。b.光模块环节:是国产化进度最快的领域,国内厂商技术水平仅比海外龙头博通落后一代,发展前景显著优于GPU环节。c.CPU环节:分两条路线发展,ARM路线适合定制核心数少、能耗低的产品解决agent调度问题,性价比更高,10万甚至大几万GPU仅需配备几千核CPU即可完成调度任务,且大厂具备虚拟化能力,可实现一颗物理CPU配多个虚拟系统;x86路线方面,当前市面多数应用围绕英特尔、AMD的x86生态开发,适配性更好且服务器价格不高,采购方若非受限于价格或供货周期,短期内仍倾向选择海外x86产品,国产x86应用场景有限。·智谱模型能力与商业模式:智谱模型能力可拆分为三个层级对比海外头部模型,同时国内编程模型市场与海外存在明显结构差异:a.模型能力差异:标准化编程场景属于标准化结构化领域,能力上限较低,预计明年初智谱在该领域的能力可与海外头部持平甚至更高;Agent场景差距明显,智谱5.2版本在国内编程相关Agent领域表现较好,但对比OpenAI 4.6已有差距,明年能否超过OpenAI相关模型仍无法确定,更难追平Fable Five,核心差距在于海外模型推理已实现工程化,单任务可分多步激活不同子模块完成最优流程规划,国内模型多为点对点简单推理,仅依靠基础知识输出规划;通用大语言模型场景下,智谱在国内本身不属于顶尖水平,DeepSeek、千问3.7标准尺寸版与其能力不相上下。b.商业模式差异:国内编程模型市场健康度低于美国,商业化存在不确定性:海外有全球AI创业公司构成的庞大B端付费市场,国内多数创业公司仍使用海外模型,本土B端市场尚未形成;国内头部互联网厂商倾向自研内部所需工具,外部厂商难切入大B客户,具备此前SaaS产品难进入大公司的典型市场特点;面向软通动力、宇信易诚等服务国央企的软件外包商的下沉市场,需求多为低难度标准化代码,市场竞争侧重性价比,头部模型性能优势难以体现。·国内大厂二季度AI业绩前瞻:收入统计口径为以MaaS为主的AI相关收入,当前仅可对国内头部两家AI云服务商业绩做出预测:a.阿里云:2026年一季度AI收入约82亿元,二季度预计保持乐观增长,增速约20%,对应收入规模约100亿元。b.火山引擎:2026年一季度AI收入约20亿元(不含IaaS),二季度AI相关收入预计增长15%-20%,叠加二季度C端贡献的约40亿元收入,总规模接近阿里云一季度水平。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-25 16:17:27 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/799060.html
- 运行时间 : 0.210179s [ 吞吐率:4.76req/s ] 内存消耗:4,698.13kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=63ba691ec6c6cea6aad22cbf9e92bd95
- CONNECT:[ UseTime:0.000833s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000749s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000249s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000863s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001517s ]
- SELECT * FROM `set` [ RunTime:0.000602s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001380s ]
- SELECT * FROM `article` WHERE `id` = 799060 LIMIT 1 [ RunTime:0.004866s ]
- UPDATE `article` SET `lasttime` = 1782375447 WHERE `id` = 799060 [ RunTime:0.005018s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000685s ]
- SELECT * FROM `article` WHERE `id` < 799060 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.001143s ]
- SELECT * FROM `article` WHERE `id` > 799060 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000918s ]
- SELECT * FROM `article` WHERE `id` < 799060 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.001533s ]
- SELECT * FROM `article` WHERE `id` < 799060 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.005895s ]
- SELECT * FROM `article` WHERE `id` < 799060 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.007029s ]

0.214253s

 夜雨聆风
夜雨聆风