 夜雨聆风
夜雨聆风AI 家教这个方向,已经卷过好几轮了。
第一轮,是“你问我答”。
第二轮,是“拍题解题”。
第三轮,是“上传 PDF,然后基于资料问答”。
但这些东西都有一个共同问题:
它们像工具,不像学习系统。
你今天问过什么。
错在哪。
哪些概念没掌握。
读过的资料、做过的题、写过的笔记、生成过的报告,能不能进入下一次学习。
这些才是个性化学习真正麻烦的地方。
DeepTutor 有意思的地方,就在这里。
它不把自己定位成“AI 老师聊天框”,而是一个 agent-native personalized tutoring workspace。
翻译成人话:
它想做的是一个智能体原生的学习工作台。
项目地址:
https://github.com/HKUDS/DeepTutor
截至我查询 GitHub API 时,这个仓库大约有 24.9k stars、3.3k forks。
项目发布于 2025 年底,README 里写到 2026 年 4 月 19 日已经 111 天突破 2 万 Star。
这不是一个冷门实验。
它不是一个聊天机器人
DeepTutor 的 README 开头说得很直接:
它把 tutoring、problem solving、quiz generation、research、visualization、mastery practice 放进同一个可扩展系统。
也就是说,它不是只回答问题。
它要覆盖一条完整学习链路:
- 问问题
- 读资料
- 做题
- 生成测验
- 深度研究
- 可视化解释
- 写作整理
- 形成记忆
- 下次继续使用
这就是它和普通 AI 学习助手最大的区别。
普通工具更像一次性问答。
DeepTutor 更像一个学习操作系统。
你不是在一个空白聊天框里不断重新解释背景。
你是在一个带知识库、记忆、题库、笔记、草稿、Agent 和工具的工作台里学习。
核心:同一个 Agent Loop
DeepTutor 最关键的设计,是 One runtime for every mode。
Chat、Quiz、Research、Visualize、Solve、Mastery Path 都跑在同一个 agent loop 上。
切换的是目标,不是引擎。
这个点很重要。
很多 AI 产品看起来功能很多,但背后是几个互相割裂的模块:
问答是一套。
出题是一套。
写作是一套。
资料库是一套。
记忆又是另一套。
用起来就会出现一个问题:
上下文断了。
你刚刚在知识库里读过的材料,到了写作工具里又要重新上传。
你做错的题,到了下一次问答里又变成“没发生过”。
你和某个 Agent 的讨论,不能自然进入主会话。
DeepTutor 试图把这些东西放进同一个运行时。
它的 Chat 可以调用工具、挂知识库、读附件、生成图片、咨询子智能体、写 notebook。
更深的能力,比如 Quiz、Research、Visualize、Solve,也从同一条 agentic pipeline 里展开。

这其实是 AI 学习产品从“功能集合”走向“上下文系统”的标志。
知识库不是只有 RAG
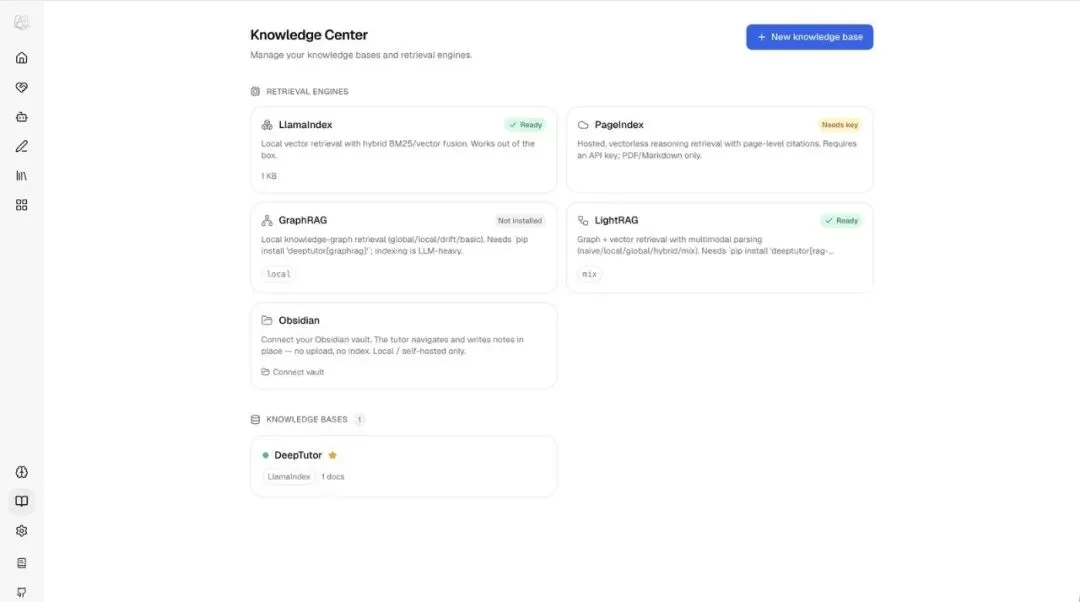
DeepTutor 的 Knowledge Center 是文章里最值得展开的部分。
它不是简单说“支持上传 PDF 问答”。
它提供多种知识库引擎:
| 引擎 | 适合场景 |
|---|---|
| LlamaIndex | 默认本地向量 + BM25 |
| PageIndex | 托管式页面级引用检索 |
| GraphRAG | 知识图谱检索 |
| LightRAG | 轻量图谱检索 |
| LightRAG Server | 外部 LightRAG 服务,通过 HTTP 检索 |
| Obsidian vault | 链接已有 Obsidian 知识库 |
2026 年 6 月 24 日的 v1.4.12 更新里,重点就是知识库能力:
新增 LightRAG Server 检索引擎。
新增 PyMuPDF4LLM 文档解析。
默认 LlamaIndex 检索改用 FAISS 后端。
这说明项目方向很明确:
它不是只做一个好看的学习 UI。
它在认真处理大知识库检索速度、文档解析成本、外部检索服务连接这些工程问题。
尤其是 PyMuPDF4LLM 这个点,对普通机器很友好。
不用模型下载。
不用 CUDA。
低配机器也能把 PDF 和电子书转成 Markdown,并抽取图片。
对个人学习者来说,这比“支持某某大模型”更实在。
Memory 是可审计的
很多产品说自己有长期记忆。
但用户看不见。
看不见就会有两个问题:
第一,你不知道它记住了什么。
第二,你不知道它为什么这么认为你。
DeepTutor 的 Memory 设计比较克制。
它不是把一切塞进隐藏向量库,而是做成三层:
- L1:原始事件 trace
- L2:每个学习表面的摘要事实
- L3:跨表面的综合画像和偏好
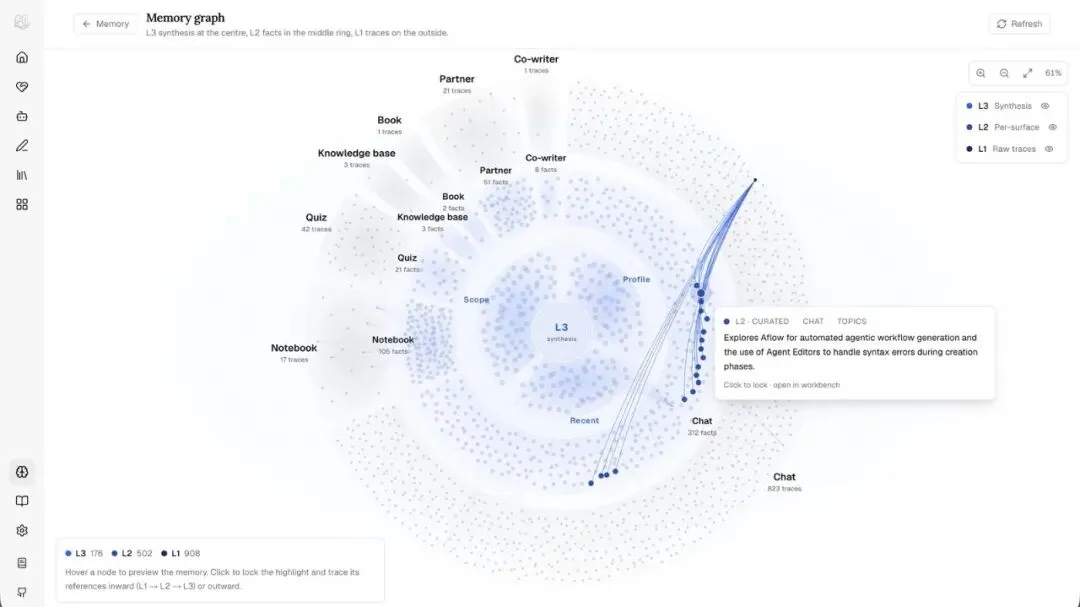
更关键的是,它强调可追溯。
L2 引用 L1。
L3 引用 L2。
所以当系统说“你对某个概念掌握不稳”时,理论上可以追到它依据的是哪次对话、哪次做题、哪段笔记。
这对教育场景非常重要。
学习不是推荐短视频。
错一次、记错一次、乱归因一次,都可能影响后面的学习路径。
所以个性化学习不应该只是“越记越多”。
还要能审计、能删除、能修正。
DeepTutor 在这个方向上做得比较认真。
它还能连接别的 Agent
DeepTutor 里有一个很有当下味道的能力:My Agents / Subagents / Partners。
它可以把 Claude Code、Codex 或者你配置的 Partner 接进学习过程。
这件事看起来有点绕,实际很有意思。
比如你在学一个开源项目。
DeepTutor 负责组织学习上下文、知识库、记忆和问题。
Codex 负责读代码、跑命令、解释工程结构。
两者通过 subagent 连接起来。
这样学习就不再只是“问模型一个问题”。
而是一个主学习 Agent 在需要时调用另一个专业 Agent。
这很像真实学习场景:
遇到数学问题,问数学老师。
遇到代码问题,问工程同事。
遇到论文问题,查研究资料。
DeepTutor 把这种协作抽象成 Agent 工作流。
Co-Writer 和 Book:把学习变成产物
学习系统最怕一件事:
所有收获都停留在聊天记录里。
聊天记录很长。
但复用价值很低。
DeepTutor 提供了两个把学习沉淀成产物的模块。
一个是 Co-Writer。
它是分屏 Markdown 写作环境,支持选中一段文字,让 DeepTutor 帮你改写、扩写、缩短,并给出可接受/拒绝的 diff。
这比“帮我重写全文”更适合学习。
因为你能控制每一次修改。
另一个是 Book。
它不是把材料直接转成 PDF,而是生成一种 living book。
里面可以有文本、callout、quiz、flash cards、timeline、code、figure、interactive HTML、animation、concept graph。
换句话说,它想把你的资料编译成一本可交互的学习书。
这个方向很有潜力。
因为真正的学习资料,不应该只是“长答案”。
它应该有讲解、有练习、有反馈、有图解、有后续追问。
命令行也很完整
DeepTutor 不是只有 Web UI。
它还有 CLI,而且 CLI 做得像给 Agent 调用的接口。
安装完整 Web 应用:
mkdir -p my-deeptutor
cd my-deeptutor
pip install -U deeptutor
deeptutor init
deeptutor start默认前端地址:
http://127.0.0.1:3782如果想从源码安装:
git clone https://github.com/HKUDS/DeepTutor.git
cd DeepTutor
python3 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
python -m pip install -e .
cd web
npm ci --legacy-peer-deps
cd ..
deeptutor init
deeptutor start如果只想用命令行:
git clone https://github.com/HKUDS/DeepTutor.git
cd DeepTutor
python3 -m venv .venv-cli
source .venv-cli/bin/activate
python -m pip install --upgrade pip
python -m pip install -e ./packaging/deeptutor-cli
deeptutor init --cli
deeptutor chat常见 CLI 用法:
deeptutor run chat "Explain Fourier transform"
deeptutor run deep_solve "Solve x^2 = 4" --tool rag --kb textbook
deeptutor run deep_question "Linear algebra" --config num_questions=5
deeptutor run deep_research "Attention mechanisms" --config mode=report
deeptutor run visualize "Plot the unit circle"
deeptutor memory show这块对开发者很有吸引力。
因为它意味着 DeepTutor 不只是一个页面产品,还可以成为其他 Agent 工作流里的学习能力层。
Docker 部署也考虑得很细
如果用 Docker,官方推荐只暴露一个前端端口:
docker run --rm --name deeptutor \
-p 127.0.0.1:3782:3782 \
-v deeptutor-data:/app/data \
ghcr.io/hkuds/deeptutor:latest浏览器只访问前端 origin。
Next.js middleware 会在容器内部把 /api/ 和 /ws/ 转发给 FastAPI 后端。
也就是说,普通单容器部署不需要把 8001 端口暴露给浏览器。
这个设计对新手很友好,也更适合反向代理。
如果你要连接宿主机上的 Ollama、LM Studio、llama.cpp、vLLM,可以在 Docker 里用 host.docker.internal。
这类细节说明项目不是 demo 思维。
它在处理真实部署。
适合谁
第一类,想系统学习的人。
你不是只想问一个答案,而是想围绕一批资料长期学习、做题、写笔记、复盘。
第二类,老师和课程创作者。
DeepTutor 的 Quiz、Book、Co-Writer、Knowledge Center 很适合把材料整理成可交互学习内容。
第三类,研究生和论文阅读者。
多文档知识库、Research、Page-level citation、Obsidian 链接,对读论文和做综述很有用。
第四类,开发者。
CLI、Skills、MCP、Subagents、Partners,让它可以接入自己的 agent 工作流。
不适合谁
如果你只想要一个极简聊天框,它太重。
如果你只想偶尔问几个题,它的学习工作台、记忆、知识库、Book 可能用不上。
如果你完全不想配置模型、embedding、文档解析,它也不是最轻的选择。
DeepTutor 的能力很强,但前提是你愿意把学习资料和学习流程搬进去。
它适合长期学习,不适合一次性问答。
最后
DeepTutor 最值得看的,不是“AI 家教”这个标签。
而是它把教育场景里的几个碎片拼到了一起:
资料。
问题。
答案。
练习。
写作。
记忆。
可视化。
子智能体。
过去我们用 AI 学习,经常是在不同工具之间来回搬运上下文。
今天把 PDF 上传到一个工具。
明天把笔记复制到另一个工具。
后天再把聊天记录整理成文档。
DeepTutor 想做的,是让这些东西留在一个持续生长的学习空间里。
这才是它的看点。
不是多一个 AI 老师。
而是学习终于有了一个能记住上下文、能调用工具、能沉淀产物的工作台。
参考资料:
- DeepTutor GitHub:https://github.com/HKUDS/DeepTutor
- DeepTutor Docs:https://deeptutor.info
- DeepTutor arXiv:https://arxiv.org/abs/2604.26962
- v1.4.12 Release Notes:https://github.com/HKUDS/DeepTutor/blob/main/assets/releases/ver1-4-12.md
