 夜雨聆风
夜雨聆风经济学研究者的智能体入门指南:从"写do-file"到"和AI对话"
2026年6月
本文是「经济学×智能体」系列的第一篇——帮你建立对AI智能体的直观理解,并分享一个关于"重新开始"的故事。
一、为什么经济学研究者需要关注智能体
2025年9月,NBER发布了Anton Korinek的Working Paper 34202——《AI Agents for Economic Research》,这篇论文随后发表于Journal of Economic Literature。作为经济学五大顶级期刊之一,JEL发表一篇以"AI智能体"为主题的方法论论文,这本身就具有风向标意义:经济学学科正式承认了智能体技术在研究方法层面的重要性。
这篇论文论证了一个正在发生的事实:人工智能已从简单的对话式聊天机器人,演进为能够自主规划、使用工具、执行多步骤研究任务的智能体系统(Agentic AI Systems)。Korinek在论文中用大量可运行的代码示例展示了,一个经济学家可以用几句自然语言描述,就让智能体完成从文献搜索、数据整理、回归分析到论文写作的全流程工作。
对于习惯使用Stata进行计量分析的经济学教师而言,这一转变可能显得遥远而陌生。我们熟悉的"写do-file、跑回归、看结果、调模型、写论文"的工作流程,似乎与"AI"没有太大关系。但事实恰恰相反——智能体技术正在从根本上重构经济学研究的每个环节。它不是在替代经济学家,而是在替代那些耗费我们大量时间却缺乏学术回报的重复性劳动:格式化的文献检索、繁琐的数据清洗、重复的稳健性检验代码、机械的论文格式调整。
本文从经济学高校教师的视角出发,系统分析智能体在经济学研究中的实际应用场景、优势与局限。本文所引用的核心信息来源于公开发表的学术论文(NBER、JEL、AEA)和开源项目(GitHub),力求内容扎实、数据可信。
📢 系列预告:本公众号将陆续推出系列推文,以通俗易懂的方式,为经济学学者详细介绍从零开始、一步一步学习智能体技术的进阶路径,以及智能体在经济学研究各环节的具体应用场景。如果你还没有关注我们,现在正是最好的时机——让我们一起,在这个技术洪流中找到属于自己的那条航路。
· · ·
二、智能体是什么——用经济学家能听懂的语言
2.1 一个场景帮你建立直觉
想象这样一个场景——
你叫来一位刚入学的博士生,对他说:"帮我做一个关于最低工资对就业影响的DID分析。数据在CHFS里,你自己去找。顺便帮我查一下最近五年这个领域最重要的十篇文献,把每篇的研究设计和主要发现整理成表格。"
如果你真有一个如此能干的学生,他大概需要两周时间来完成这些任务。他需要理解你的研究问题、自己搜索文献、找到数据、学习DID方法、编写Stata代码、调试、跑回归、整理结果——这一系列步骤中,每一步都需要独立的判断和行动。
智能体做的事情,和上面这个"理想博士生"几乎一模一样。区别在于:它完成这些任务的时间,是几分钟而不是两周。
Korinek在JEL论文中清晰地勾勒了AI能力的三层演进,我们可以用经济学研究者最熟悉的"生产力"概念来理解:
2.2 三层能力:从打字机到研究助理
第一层:传统大语言模型——"会聊天的百科全书"
这就是大家已经熟悉的ChatGPT、早期Claude。你把问题抛给它,它给你一个回答。它能帮你解释概念、翻译文献、润色语言,但它不会主动行动。就像一本会说话的百科全书,知识丰富但只能"问一句答一句"。
对于经济学研究者来说,第一层AI最有价值的功能是:写邮件、改摘要、翻译英文论文、解释陌生概念。但这些工作本质上是在"装饰"已有成果,而非"创造"新成果。
第二层:推理模型——"会思考的计算器"
2024年下半年开始出现的推理模型(如OpenAI o1系列、DeepSeek R1),其核心突破在于:它们不再凭"直觉"回答问题,而是会在内部进行多步骤的逻辑推演。Korinek将其类比于Kahneman的"System 2思维"——缓慢、谨慎、深思熟虑。
对于经济学研究而言,这意味着AI开始能够处理真正需要推理的任务:理解一个复杂的计量模型设定、解释为什么交错DID中需要警惕"坏比较"、推导一个理论模型的比较静态结果。它不再是"大概是这样",而是"让我想一下,第一步……第二步……第三步……"。
第三层:智能体系统——"会动手的研究助理"
这是真正的范式变革。智能体系统将前两层的语言能力和推理能力结合起来,再加上一个关键能力:自主行动。
智能体的核心架构可以用一个简单比喻来理解:它有一个"大脑"(大语言模型或推理模型),一个"工具箱"(能够上网搜索、运行代码、读写文件、操作软件),以及一个"规划器"(负责将复杂任务分解为步骤、决定何时使用哪个工具、检查结果是否正确)。
当你说"帮我分析这个数据集"时,智能体不是简单地回答一些分析建议。它会:
先读取数据文件的格式和结构 生成描述性统计以理解变量分布 根据研究目的选择合适的计量模型 编写并执行Stata do-file 读取Stata的输出结果 判断结果是否合理,如果不合理则调整模型重新运行 将最终结果整理为表格和图表
整个过程,无需你写一行代码。这就是Korinek所说的"Vibe Coding"——你用自然语言描述需求,智能体生成并执行复杂工具。Korinek在论文中演示了如何用几句英文描述就构建出完整的经济数据分析系统。
2.3 智能体的"工具箱"里有什么?
一个完整的智能体系统可以接入多种工具,这些工具涵盖了经济学研究的全程:
- 网络搜索工具:
使智能体能够实时查找文献、数据源、方法论解释 - 代码执行工具:
在隔离环境中运行Python、R、Stata等语言的代码 - 文件系统工具:
读取、写入、组织项目文件 - 专用软件接口:
通过MCP协议直接操控Stata、Zotero等软件
MCP协议是理解智能体与经济学工具关系的关键。它就像一个"通用遥控器"——智能体不需要知道每个软件的内部实现细节,只要软件支持MCP,智能体就能像人类一样操作它。目前已经有人开发了Stata的MCP接口,这意味着智能体可以直接在你的Stata中执行命令、读取结果、导出图表。
2.4 对经济学研究者的意义
把这三个层次放在一起,可以看到一条清晰的演进路线:
| 传统LLM | ||
| 推理模型 | ||
| 智能体系统 |
如果你目前还停留在第一层(偶尔用DeepSeek翻译摘要),你需要知道你已经落后于技术前沿至少两代。好消息是,由于智能体系统操作越来越简单(自然语言即可驱动),学习的边际成本正在急剧降低。本文的目标,就是帮助你用最短的时间从第一层跨越到第三层。
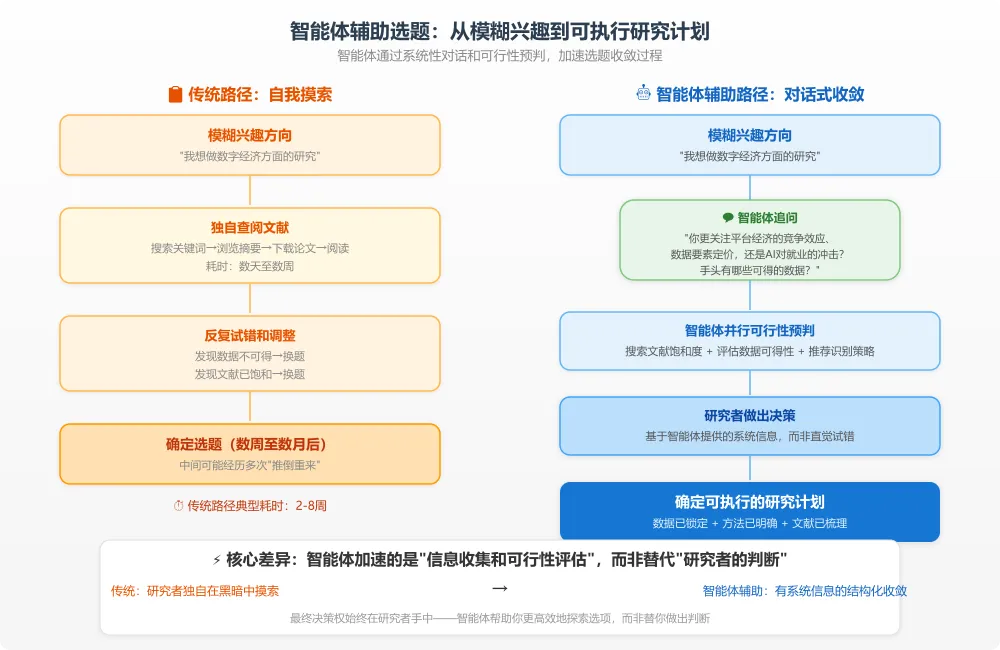
▲ 智能体辅助下的选题收敛路径。传统模式下,研究者需要数周甚至数月才能在"模糊兴趣"到"可执行计划"之间找到通路;智能体通过系统性追问、可行性预判和跨领域灵感,大幅压缩了这个过程。(点击图片可放大查看)
· · ·
***言外之音***
这篇分析报告的诞生,本身就是一个值得分享的故事。
距离上一次更新公众号,已经过去了太久。如果你是从早期就开始关注这个号的朋友,你大概能理解这种"停滞"——它不是江郎才尽(至少我不愿意这么定义),而是生活本身的拥挤。备课、写基金、指导学生、处理行政事务、承担家庭的柴米油盐——这些日常的、弥散的、无法推脱的"不得不做",渐渐挤占了那些"想做却找不到整块时间做"的事。分享、写作、整理思绪——这些需要沉下心来慢慢做的事情,最先被挤压。
但这个月,我在学习AI工具的过程中发现了一件让我重新兴奋起来的事情:智能体补上的不只是"效率",更是那种因为时间碎片化而丧失的"表达节奏"。
以前写一篇公众号文章需要:找一个完整的周末→构思框架→查阅资料→逐段写作→反复修改→排版发布。当课表、会议、家庭把时间切割成以小时为单位的碎片时,这个链条根本无从启动。但现在,我可以在备完课的半小时空档里,对着智能体讲述我的框架和想法,让它生成初稿;在做饭前的二十分钟里,审阅和修改它的输出;在睡前的半小时里,做最后的润色和排版。碎片时间从"不能做正经事"变成了"刚好够和智能体配合完成一个环节"。
这给了我一个启发:智能体技术对学术工作者最深远的影响,可能不是量化分析的精度提升,也不是文献搜索的速度加快,而是它降低了"坚持做一件需要持续投入的事情"的门槛。当写作不再是"你必须找到一个完整的下午"而是"你可以在任何碎片时间里推进一小步",那些被生活淹没的表达欲就有了重新上岸的可能。
AI时代的洪波,给了一个原本不平衡的斗兽场带来了新的平衡法则。智能体技术不会完全抹平这个差距,但它提供了一种新的可能性:一个人加上一个好的智能体,可以达到过去需要一个小团队才能实现的产出水平。
是选择启航,直面波涛汹涌;还是在田园中独享齐乐——历史会给我们答案。但于我而言,写作这篇推文本身就是对这个问题的回答。我没有选择等待生活变闲的那一天再重新开始更新(如果历史有任何参考价值,那一天不会来),而是选择用新的工具,在现有的生活节奏里,找回表达的能力。
如果这篇推文让你对智能体在经济学研究中的应用产生了兴趣——哪怕只是"有点好奇,想试试看"——那么接下来的系列推文中,我们将一步一步地、用经济学家能听懂的语言,带你从零开始,走进智能体的世界。
不会突然把你扔进代码的海洋,不会假设你懂编程,不会用你不关心的例子——每一篇都基于经济学研究中的真实场景。
启航了。不一定平稳,但值得。 🚢
— END —
