 夜雨聆风
夜雨聆风关注“每日英语听力丨双语精读”
双语精读不停更

当地时间周三,OpenAI发布了首款自研AI推理芯片,并表示其性能功耗比已优于当前部分主流方案。这款芯片由OpenAI与博通联合设计,旨在降低AI推理成本、优化模型运行效率,也被外界视为其减少对英伟达GPU依赖的重要一步。
双语原文

请输入

On Wednesday, OpenAI unveiled its first custom-built inference processor, designed and manufactured in collaboration with Broadcom.
周三,OpenAI发布了其首款定制推理处理器,该处理器由OpenAI与博通合作设计和制造。
Named Jalapeño, the new processor was designed specifically for the unique needs of OpenAI's inference systems.
这款名为Jalapeño的新处理器专为OpenAI推理系统的独特需求而设计。
OpenAI's own AI models assisted in the development of the chip, the company said.
该公司表示,OpenAI自身的人工智能模型也参与了芯片的开发。
While the chip is still being tested, OpenAI says early results show significantly better performance-per-watt than current state-of-the-art alternatives.
虽然该芯片仍在测试中,但OpenAI表示,早期结果显示其每瓦性能显著优于当前最先进的替代方案。
The partnership was officially announced in October, but OpenAI's chip plans have long been rumored as a way to reduce the company's dependence on Nvidia's GPUs.
双方的合作于去年10月正式宣布,但OpenAI的芯片计划早已被外界猜测,目的是减少该公司对英伟达GPU的依赖。
Google and Amazon have both built custom chips to serve a similar purpose, often called "AI accelerators" — silicon designed specifically to speed up machine learning workloads.
谷歌和亚马逊都曾为类似目的打造过定制芯片,这类芯片通常被称为“AI加速器”——即专门为加速机器学习工作负载而设计的硅片。
OpenAI president Greg Brockman explained the company's approach to chip development on its in-house podcast, shortly after the Broadcom partnership was announced.
在与博通合作宣布后不久,OpenAI总裁格雷格·布罗克曼在该公司的内部播客中解释了其芯片开发策略。
"We have a deep understanding of the workload," Brockman said in the episode.
“我们对工作负载有着深刻的理解,”布罗克曼在节目中说道。
"We've really been looking for specific workloads that are underserved, and asking how can we build something that will be able to accelerate what's possible?"
“我们一直在寻找那些未被充分满足的特定工作负载,并思考如何打造能够加速现有可能性的产品。”
Jalapeño is specifically designed for inference, the process of running pre-built AI models in response to user commands.
Jalapeño专为推理而设计,即运行预构建的AI模型以响应用户指令的过程。
In the announcement, OpenAI emphasized the chip's low operating cost when running real-time coding models.
在公告中,OpenAI强调了该芯片在运行实时编码模型时的低运营成本。
It's likely that more performance-intensive tasks like pre-training will still rely on Nvidia hardware, but even small reductions in inference costs could do a lot to improve the company's bottom line.
像预训练这样性能密集型任务可能仍将依赖英伟达硬件,但即便是推理成本的小幅降低,也能极大地改善公司的盈利状况。
Optimizing that inference system may prove to be a crucial factor in the economics of AI going forward — and it's likely to take place at every level of the stack.
优化推理系统可能被证明是未来人工智能经济学的关键因素——而且这种优化很可能发生在技术栈的每一个层面。
OpenAI is already building agentic products like Codex and the models that power them, as well as data centers to run those models.
OpenAI已经在构建Codex等智能体产品及其驱动模型,以及运行这些模型的数据中心。
Moving into purpose-built chips lets the company go even further in that process, as the company explained in its announcement.
正如该公司在公告中所解释的那样,涉足定制芯片让OpenAI在这一过程中走得更远。
"OpenAI is not only developing frontier models or building products on top of them; it is designing the infrastructure underneath them: chip architecture, kernels, memory systems, networking, scheduling, deployment systems, and product experience," the company wrote.
“OpenAI不仅在开发前沿模型或在模型之上构建产品;它还在设计模型之下的基础设施:芯片架构、内核、内存系统、网络、调度、部署系统和产品体验,”该公司写道。
"Because OpenAI operates across the stack, each layer can be optimized around the same goal: making its models faster, more reliable, and more affordable for users."
“由于OpenAI贯通整个技术栈,每一层都可以围绕同一个目标进行优化:让模型更快、更可靠、更易于用户负担。”
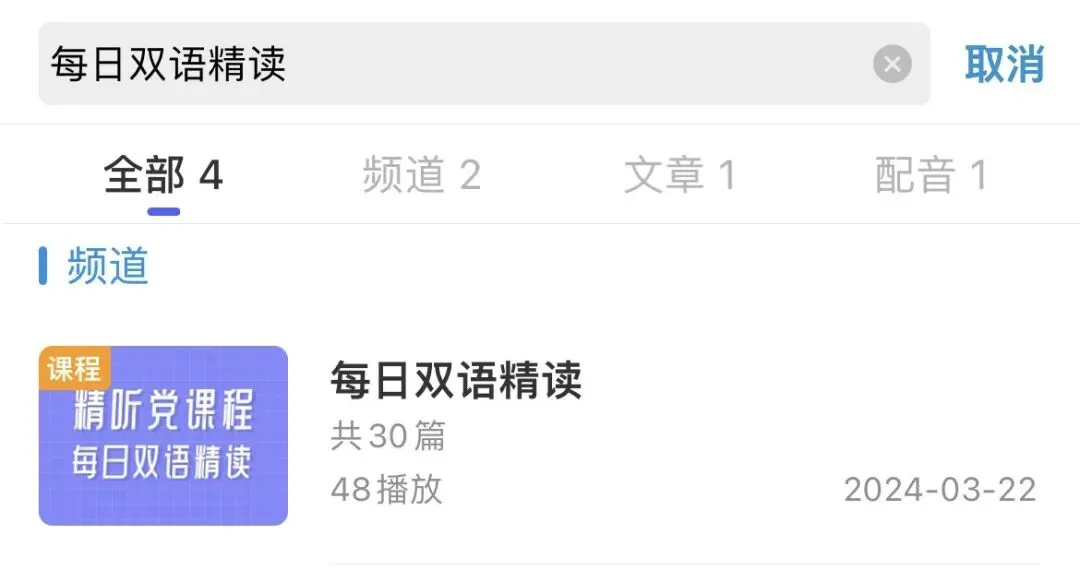
⭐️打开每日英语听力app
点击首页小图标【双语精读】
或搜索找到“每日双语精读”
报名课程
即可收听本篇完整版知识讲解,体验在线练习

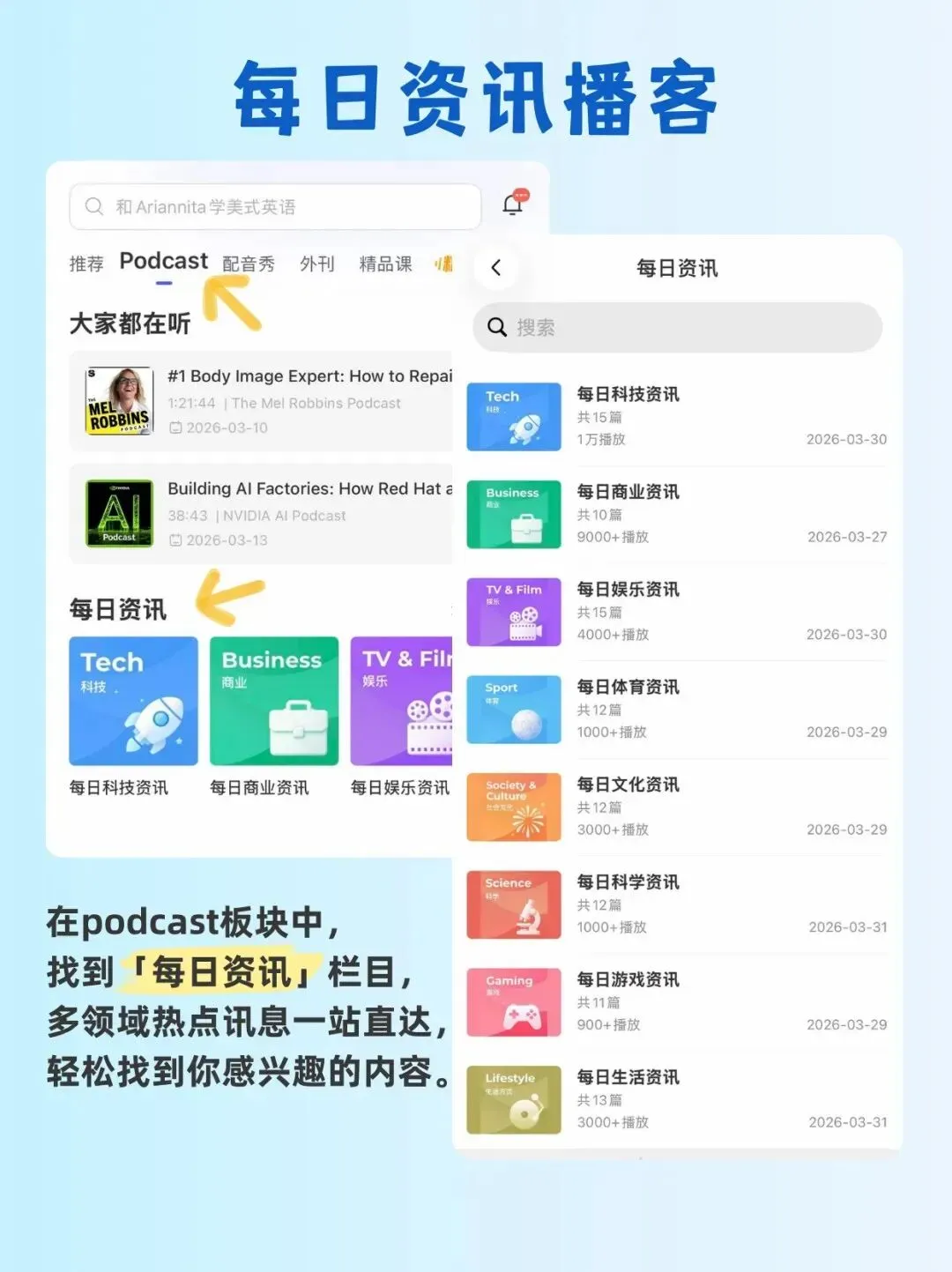
👉打开首页顶部【Podcast】板块
进入播客专区
即可免费收听【每日资讯】栏目
让你的一天收获翻倍~
软件下载

每日英语听力
精听细读,更好学英语

欧路词典
英语学习者的必备工具
你“在看”我吗?

