 夜雨聆风
夜雨聆风同一个问题,今天问 AI,它给一个答案。
明天再问,它换了一种说法。
刷新一下,答案又变了。
有时只是表达不同。
有时连重点、顺序、建议都不一样。
如果让它写标题、写开头、列方案,这种变化会更明显。
很多人会因此觉得:
AI 不稳定,不靠谱。
这个判断只说对了一半。
大模型确实不是传统软件那种“同样输入必然返回同样结果”的工具。
但这不是单纯的缺陷。
它之所以能生成不同表达、不同方案、不同角度,正是因为它的底层不是查表,而是概率生成。
这一篇只讲一件事:
大模型不是在复制一个固定答案,而是在上下文里不断选择“更可能合适”的下一个 token。
理解这一点,你就能解释两件事:
• 为什么同一个问题,每次回答会不一样 • 为什么它有时会一本正经地胡说
先说结论:它不是在“取答案”
传统软件更像自动售货机。
你按 A 键,它就掉 A 商品。
你输入账号密码,系统判断对或错。
你查数据库里的某个字段,有就是有,没有就是没有。
大模型不是这样。
它更像一个特别擅长语言接龙的人。
你给它一段上下文,它会判断:
接下来最可能出现什么?
这里的“什么”,不是一个完整答案,而是一个个 token。
token 可以简单理解成模型眼里的文字颗粒。
一个 token 可能是一个字、一个词的一部分、一个标点,也可能是一段常见字符组合。
模型生成回答时,不是一次性把整篇答案从仓库里拿出来。
它是在一步步生成:
1. 看当前上下文 2. 计算下一个 token 的候选概率 3. 从候选里选一个 4. 把它接到上下文后面 5. 继续预测下一个
所以你看到的是一段完整回答。
但它背后是连续很多次选择。
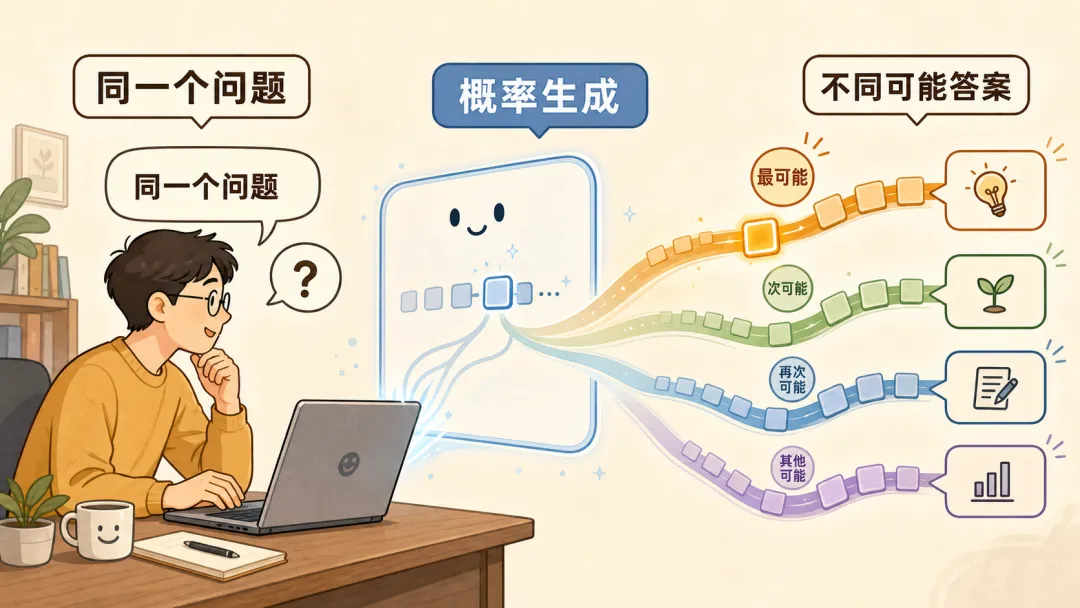
为什么同问会不同答?
因为每一步都不是只有一个可能答案。
比如你输入:
请给我 5 个公众号标题。模型可能接:
• “为什么……” • “别再……” • “真正……” • “你不是……” • “……的人,都……”
这些开头都可能合理。
模型不是只看到一个唯一正确选项,而是看到一组候选。
每个候选都有概率。
如果每次都选概率最高的那个,回答会更稳定,但也更容易死板、重复、没有变化。
如果允许从多个高概率候选中选择,回答会更灵活,但也更不稳定。
这就是为什么写作、头脑风暴、方案发散类任务,每次结果都可能不同。
它不是随机乱说。
而是在一个概率空间里生成。
“温度”控制的是发散程度
很多工具会提供一个参数,叫 temperature,中文常被翻译成“温度”。
只要理解它控制的是:
模型在选择下一个 token 时,有多愿意尝试不那么高概率的选项。
温度低,更保守,更稳定,更像标准答案。
温度高,更发散,变化更多,也更容易跑偏。
所以温度没有绝对好坏。
摘要、改错、抽取信息、按格式输出,要低发散。
标题、创意文案、头脑风暴、多方案生成,可以允许高发散。
幻觉和概率生成是什么关系?
现在可以解释“幻觉”了。
AI 一本正经胡说,并不一定是它在撒谎。
更准确地说:
当上下文不足、依据不够、问题又要求它给出完整答案时,它仍然可能继续生成一段“看起来像答案”的文本。
这就是幻觉最容易出现的地方。
比如你问:
请列出支持这个观点的 3 篇经典论文。如果你没有提供材料,它没有联网检索,也没有数据库可查。
但这个问题的语言模式很明确:
它需要输出论文标题、作者、年份、观点。
于是模型可能生成一组看起来很像论文引用的内容。
问题是:
像论文引用,不等于真有这篇论文。
大模型很擅长答案的样子。
它知道报告怎么写,论文怎么引用,政策怎么表述,专家观点怎么组织。
所以当依据缺失时,它仍然可能生成一个格式正确、语气确定、逻辑顺滑的回答。
危险就在这里。
不是它会错。
而是它错得不像错。
先判断:要稳定,还是要发散?
有些任务,越稳定越好:
1. 从材料里提取事实 2. 总结会议纪要 3. 改正错别字 4. 按固定格式输出 5. 判断材料里有没有某个信息 6. 根据原文整理行动项
这类任务的关键不是创意,而是忠实。
另一些任务,不稳定反而有价值:
1. 想标题 2. 找选题角度 3. 生成多个方案 4. 头脑风暴 5. 改写不同风格 6. 设计开头和结尾
这类任务你本来就不需要一个唯一答案。
你需要的是多个可能性,然后再筛选。
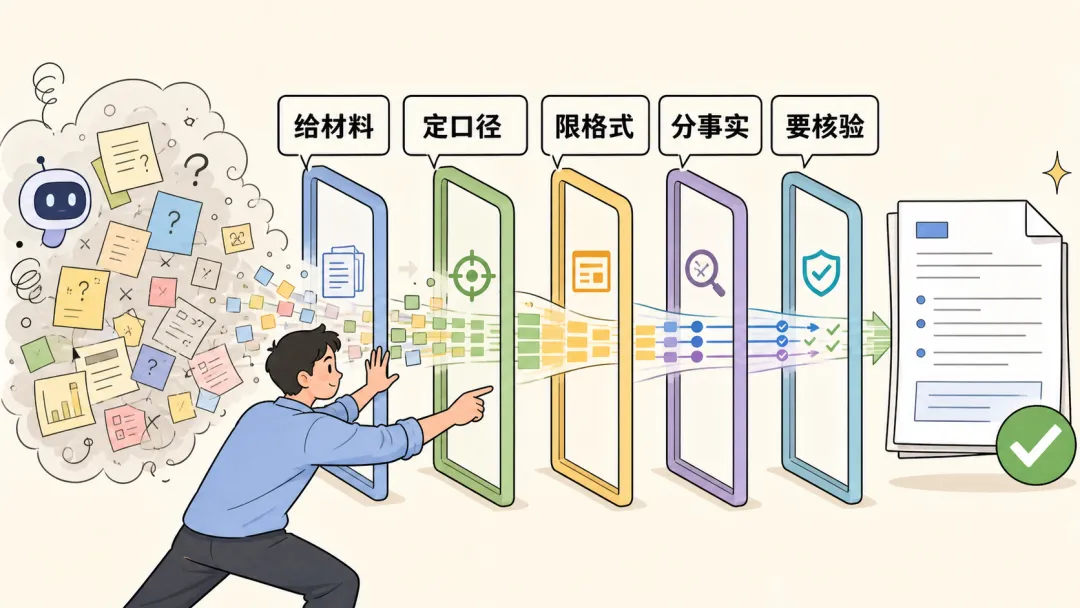
想让回答更稳定,靠这 5 件事
如果你希望同一个任务输出更稳定,不要只说“别乱说”。
要把生成空间收窄。
1. 给材料
不要让它凭印象回答。
把原文、数据、会议记录、背景贴进去。
材料越清楚,模型越不需要自己补。
2. 定口径
很多不稳定来自口径不清。
比如“好不好”“高不高”“有没有机会”。
这些问题必须先定义比较对象、时间范围、评价标准。
3. 限格式
格式越明确,输出越稳定。
例如:
请按表格输出:
问题 / 依据 / 风险 / 下一步比“帮我分析一下”稳定得多。
4. 要它区分事实和推断
这是防幻觉最重要的一步:
可以这样要求:
请把回答分成三部分:
1. 材料中明确写到的事实
2. 基于事实的合理推断
3. 还缺哪些证据这样能减少它把猜测包装成结论。
5. 对高风险内容做外部核验
涉及这些内容,不要只信 AI:
• 最新政策 • 最新价格 • 法律条文 • 医疗建议 • 投资判断 • 论文和报告来源 • 精确数据
这些问题要回到官网、原文、数据库、专业人士。
AI 可以帮你整理和提问,不能替你完成最终确认。
把上面 5 件事合成一个模板,可以这样问:
请只基于我提供的材料回答,不要补充材料外的信息。
请按下面结构输出:
1. 明确事实:材料中直接写到的内容
2. 合理推断:可以从材料推出,但不能确定的内容
3. 缺失信息:要做出结论还缺什么
4. 风险提示:哪些地方最容易判断错
5. 谨慎结论:在当前材料下,最多能说到什么程度
如果材料不足,请直接说明不足,不要编完整答案。
材料:
……这个模板不能保证绝对正确,但能减少三种风险:把推断说成事实,把缺失信息补成结论,把不确定说得很确定。
结尾
AI 为什么同一个问题每次回答都不一样?
因为它不是在取一个固定答案。
它是在上下文里做概率生成。
概率生成带来灵活,也带来不确定。
要事实,就收窄边界;要创意,就放开空间。
要结论,就先给依据;要可靠,就必须核验。
