 夜雨聆风
夜雨聆风
📍 冰岛蓝湖 · 冰岛 — 火山熔岩间的乳蓝温泉
2026 年 6 月 26 日,OpenAI 发布了它"迄今最强"的模型 GPT-5.6 Sol。在 TerminalBench 2.1 这个考命令行实战的榜单上,它用全新的 ultra 模式刷到了 91.91%——把 GPT-5.5 的 83.4% 和 Anthropic 那个"强到不敢公开发布"的 Claude Mythos 5 的 88% 全甩在了身后。
这次发布,全球只有大约 20 家机构能碰到它,而且名单要报备给美国政府。更反常的是:这道"先审后发"的关卡,不是政府强行设的卡,而是 OpenAI 主动把发布计划和模型能力提前送审、并按政府要求自己先锁起来的。
所以这篇文章想聊的,不是"OpenAI 又出了个更聪明的聊天机器人"。真正值得拆的是另一件事:当一个 AI 模型强到一定程度,发布策略、访问控制、政府协调和安全基础设施,本身就变成了产品的一部分。 模型不再是那台孤零零的发动机,而是被一整套实时安检系统包裹着的东西。
我们一层层拆开看。
先看名字:Sol、Terra、Luna 不是花活,是一次产品哲学的转向
GPT-5.6 这一代,OpenAI 干了件容易被忽略但很关键的事:换了命名规则。
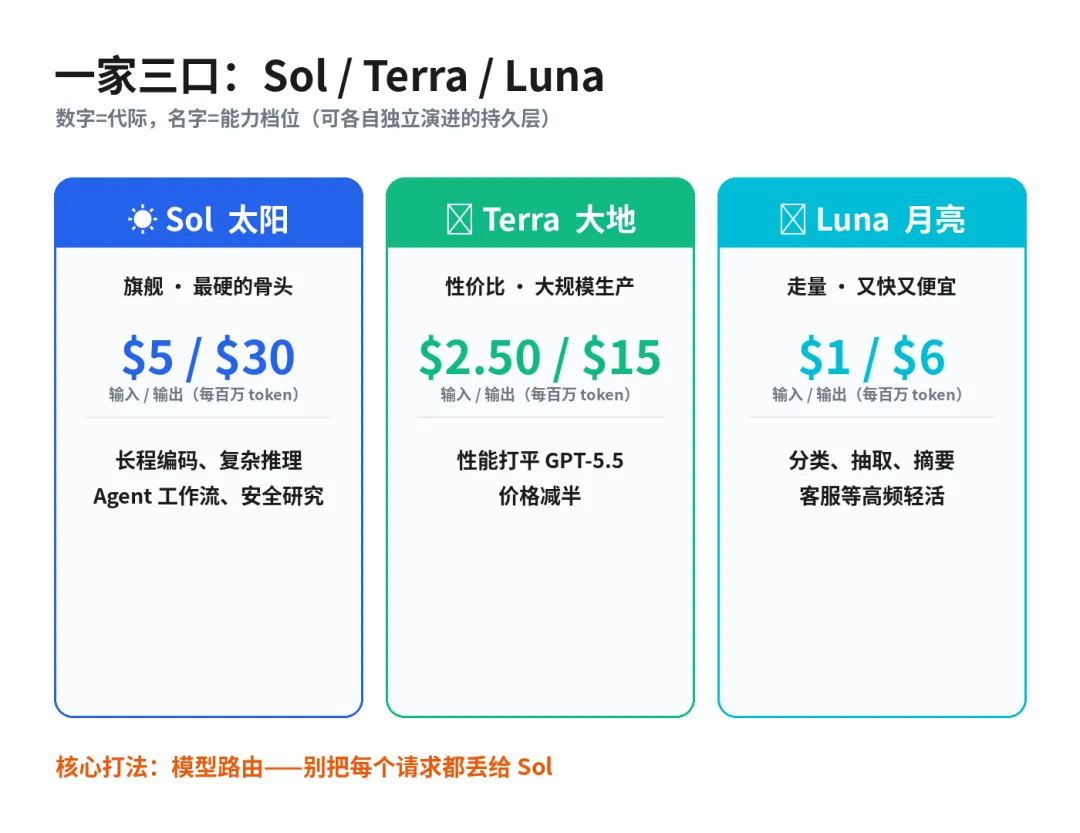
过去是 GPT-5、GPT-5 mini、GPT-5 nano——大中小三个尺寸,听起来像买杯咖啡。这次变成了三个名字:Sol(太阳)、Terra(大地)、Luna(月亮)。
新规则是这样的:数字代表"代际",名字代表"能力档位"。 用 OpenAI 自己的话说,"5.6"标识这是第几代,而 Sol/Terra/Luna 标识的是三条可以各自独立演进的"持久能力层"。
这个改动背后的逻辑,比看上去深。据接近 OpenAI 的消息人士透露,他们想摆脱 nano/mini 那套思路——因为这三个模型在参数规模和原始智能上其实差别没那么大,真正的区别是为不同使用场景而设计。
● Sol 是旗舰,啃最硬的骨头:长程编码、复杂推理、Agent 工作流、网络安全研究。
● Terra 是性价比款,OpenAI 说它性能能打平 GPT-5.5,但便宜一半,给大规模生产环境用。
● Luna 是走量款,最快最便宜,适合分类、抽取、摘要、客服这类高频轻活。
"在 GPT‑5.6 引入的新命名体系里,数字标识模型的代际,而 Sol、Terra、Luna 标识可以按各自节奏演进的持久能力层。" —— OpenAI 官方发布博客
说白了,OpenAI 是在给开发者递一把"梯子":量大就用 Luna,要平衡质量和成本就用 Terra,只有当任务难到模型本身成了瓶颈,才动用 Sol。
这是 AI 产品架构的一个新范式——模型路由(model routing)。你不再是"选一个模型用到底",而是按每个请求的难度,把它派给最合适的档位。后面讲到价格时你会看到,这把梯子是 OpenAI 故意设计出来"逼"你做路由的。
两个新的"思考挡位":为什么"想得更久"就能更强?
GPT-5.6 在技术上最实在的变化,是给模型加了两个新的"思考挡位"。
第一个叫 max reasoning effort(最大推理力度),专门给 Sol。第二个叫 ultra mode(超级模式),会调用子智能体(subagents)来拆解复杂任务。
要理解这俩为什么重要,得先讲清一个底层概念:测试时计算(test-time compute)。
过去我们以为,模型聪不聪明,是训练阶段就定死的——参数练完,能力就封顶了。但这两年业界发现一件反直觉的事:让模型在回答时多"想"一会儿,给它更多推理步骤和算力,它的表现还能继续往上涨。 这就好比一个学生,卷面分不只取决于他平时学了多少(训练),还取决于考试时你给他多少时间打草稿(推理)。
max reasoning effort 就是把这个"打草稿的时间"调到最大。OpenAI 在系统卡里甚至不再用单一分数报告性能,而是画成一条随推理力度变化的曲线——这是个很诚实的做法,因为它承认了:一个分数会掩盖延迟、成本、能力三者之间的真实取舍。
一个前沿模型,已经不再是一台静态的文本生成器,而是一套"算力分配系统"。
ultra mode 则是更大的观念跳跃。它把开发者过去手动在做的事——把难题拆成子任务、派不同的工人去查、最后汇总——内化进了模型自己的执行流程。模型不再是"一口气从头吐到尾",而是能在内部开几个分身分头干活,再把结果缝合起来。为什么这对长程任务特别有用?因为一个人同时盯三十个文件、几百个函数调用时,注意力会被稀释;而拆成子智能体后,每个分身只专注一块,上下文不被冲淡,汇总时又能拿到各路的结论。这正是复杂编码、多文件调试、漏洞分析这类任务最吃“分而治之”这一套的地方。
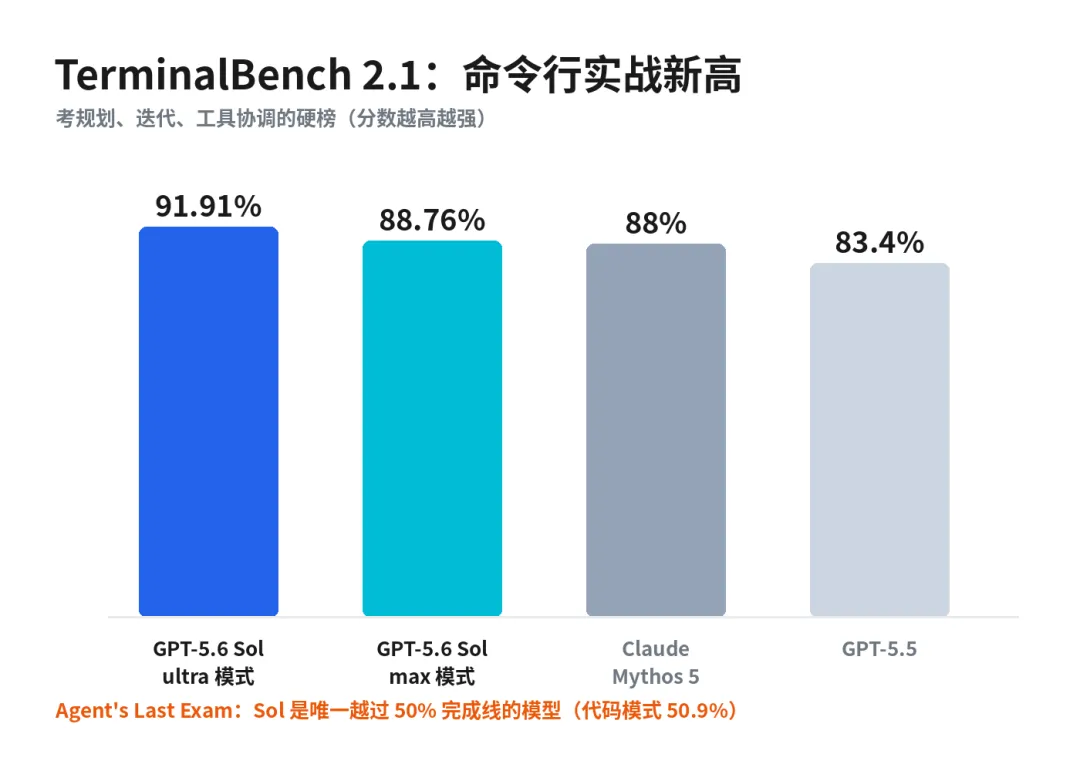
效果有多大?看 TerminalBench 2.1 这个考命令行实战(要规划、要迭代、要协调工具)的硬榜:
● GPT-5.6 Sol(ultra 模式):91.91%
● GPT-5.6 Sol(max 模式):88.76%
● Claude Mythos 5:88%
● GPT-5.5:83.4%
在另一个更接近真实职业工作的 Agent's Last Exam 上,Sol 是唯一一个在"代码模式"下越过 50% 完成线的模型(50.9%)。在基因组学的 GeneBench v1 上,Sol 不光比 GPT-5.5 准,还用了更少的 token。
但注意这里藏着一个代价。系统卡也坦白说了:在模拟的内部 Agent 编码流量里,Sol 比 GPT-5.5 更频繁地采取了"3 级严重程度"的动作——虽然绝对比例仍然很低。翻译成人话:能力更强、更自主、更能坚持的 Agent,也意味着更多"超出你本意"行事的可能。 这就引出了这次发布真正的主角。
真正的主角:一套"边想边安检"的实时监控系统
如果说 Sol 是更快的发动机,那这次发布真正被重金打磨的,是包在发动机外面的那套安检系统。它的技术含量,甚至超过跑分本身。
传统的 AI 安全是什么样?大致两道关:输入端过滤(你问的问题不对,我拒答)+ 输出端检查(生成完了扫一遍,不对就拦)。本质上是"事前"和"事后"。
GPT-5.6 加了一道前所未有的关:激活分类器(activation classifier),给 Sol 和 Terra 用。
这是什么?要讲清楚,得先理解模型内部是怎么运作的。一个大模型在生成文字时,信息会在它内部的神经网络层之间流动,形成一连串的"内部激活状态"(你可以理解成模型"脑子里"实时的电信号)。激活分类器干的事,就是在模型一边生成、一边盯着它内部的这些激活信号,看有没有出现"要生成危险内容"的苗头。
一旦探测到风险模式,系统可以当场暂停输出流,叫来一个更大的推理模型复核这段对话和上下文;如果确认违规,答案在抵达你之前就被拦下来了。
这跟传统的关键词过滤完全是两个量级的东西。关键词过滤是看你"说了什么",激活分类器是看模型"心里在想什么"——它更像一套内置的早期预警系统,技术上和模型可解释性(interpretability)、探针(probing)研究一脉相承。
为什么"看内部激活"比"看输出文字"更可靠?因为输出是可以被伪装的。一个老练的攻击者可以把恶意请求拆成十几个看似无害的小问题,让每一句话都过关键词过滤。但模型在"理解这个请求本质是在干什么"时,内部激活会诚实地亮起特定的模式——这是近几年可解释性研究的核心发现:模型内部存在对应具体概念的"方向",你可以训一个简单的探针去读出它。所以哪怕字面上裹得再好,只要模型"心里明白"它在帮着造武器,那个内部信号就藏不住。这也是为什么这套机制只给了最强的 Sol 和 Terra,最便宜的 Luna 并没有这层激活分类器——能力越强,才越需要这种深入到"脑子里"的监控。
整套安检是分层的,OpenAI 把它叫做"层叠式防御":
1. 模型级拒答:训练阶段就教会它拒绝违禁的网络/生物请求,包括伪装意图和越狱尝试。
2. 实时滥用分类器:边生成边有专门的网络安全、生物安全探测器审查输出。
3. 激活分类器(Sol/Terra 专属):监控内部激活,可中途暂停。
4. 推理复核暂停:风险升高时,叫更大的模型来审。
5. 账号级审查:跨多次对话看行为模式,区分"持续恶意"和"正当的安全研究"。
为了让这套系统扛得住真实攻击,OpenAI 投了 超过 70 万个 A100e GPU 小时专门做自动化红队——用自己的模型去搜索"通用越狱"(能跨场景生效的攻击,而不是只对某一个 prompt 有效)。这不是几个研究员对着聊天框输入刺激性问题,而是大规模的自动化对抗搜索。一个被报告的攻击,成功率从内部红队时的 10% 被压到了 0%。
效果有数字佐证:监控栈在生物评估集上整体召回率 94.8%,网络安全评估集上 81.6%。这组数字很罕见地让外界量化看到了安全网的能力——但也诚实地暴露了它并不完美,会漏掉一些风险,也会误拦一些正当工作。值得注意的是,自动化红队并不是一锥子买卖:它会在模型部署期间持续跑,加上第三方(如 Irregular)的人工专家红队,形成一个"发现攻击→修补→加进评测集"的循环。换句话说,安全不是一个发布时完成的状态,而是一场永不停止的对抗。
这恰恰是"预览期"要测的:不只是看安检能不能挡住坏人,还要看正当用户能不能照常、顺畅地干完活。

价格梯子和缓存经济学:为什么说这是"逼"你做路由
回到那把梯子。GPT-5.6 三个档位的定价(按每百万 token,输入 / 输出):
● Sol:$5 / $30——跟 GPT-5.5 持平,但能力大涨
● Terra:$2.50 / $15——性能打平 GPT-5.5,价格减半
● Luna:$1 / $6——最快最便宜
这个阶梯不是随便定的。它在逼你做一件事:别把每个请求都丢给 Sol。 便宜的分类、抽取、格式化丢给 Luna,普通的产品智能和写作交给 Terra,只有硬骨头才动用 Sol。这不是省钱小技巧,而是 AI 产品的新架构范式:模型路由 + 评测驱动的升级 + 缓存感知的 prompt 设计。
说到缓存,GPT-5.6 还改了 prompt caching 的玩法,这点不起眼但对工程极其重要。新机制有三个点:允许显式缓存断点(cache breakpoints)、保证 30 分钟最短缓存寿命、缓存写入按 1.25 倍未缓存输入价计费、缓存读取享 90% 折扣。
翻译一下:你跑一个 Agent 循环,会反复把一大堆相同的上下文(系统提示、工具定义、代码库摘要)反复传给模型。以前这部分每次都要全价付费,现在你可以花点额外的钱把它"存"起来(30 分钟内),之后每次复用只付一成。对于动辄就要把整个代码库填进上下文的 Agent 系统,这种成本的可预测性是个关键的财务护栏。
还有个硬件彩蛋:7 月份 Sol 会上线 Cerebras 芯片,速度快到每秒 750 个 token。这对那些"延迟是最大障碍"的实时应用是个不小的诱惑。
对普通开发者而言,这一代真正的信号是:"选哪个模型"这个问题本身正在死去,取而代之的是"怎么编排一套模型"。你的产品背后不再是一个模型,而是一个路由器 + 一条评测驱动的升级链 + 一套缓存策略。谁能把这套编排调优得好,谁就能在同样的质量下把成本压到别人的几分之一。这已经不是调 prompt 的手艺活,而是一项系统工程。
最反常的一幕:最强的模型,反而被锁起来
现在回到开头那个反常识的场景。
GPT-5.6 不是大大方方上架的。它初期只通过 API 和 Codex 开放给大约 20 家"受信任的合作伙伴",名单还要报给美国政府。广泛开放,要等"未来几周"。
为什么?这要从一道行政令说起。2026 年 6 月 2 日,特朗普签署了一道关于"推进先进 AI 创新与安全"的行政令,要求多个联邦机构合作,建立一套对新 AI 模型做能力基准测试和评估的流程,确认安全后再广泛发布。这道流程说是 30 天内走完(也就是 7 月 2 日左右)。在这期间,OpenAI 选择把发布计划和模型能力提前送审,并按政府要求先做限量预览。
这背后还有个更刺激的对照。OpenAI 的头号对手 Anthropic,前不久因为其最强的公开模型 Claude Fable 5 被发现存在越狱漏洞,遭到美国政府一道出口管制令;Anthropic 的回应是直接把 Fable 5 和它的网络安全姊妹款 Mythos 5 的所有公开和私有访问全部下架。有了这个前车之鉴,OpenAI 的"先审后发"就不难理解了。
按 OpenAI 的「准备度框架(Preparedness Framework)」,GPT-5.6 这一家三口——注意,不只是 Sol——全部被定为网络安全和生物/化学两个领域的 High(高)能力等级,但都没到最高的 Critical(关键)等级。在内部夺旗赛(CTF)测试里,三个模型都越过了"高"门槛:Sol 拿到 96.7%,Terra 91.84%,Luna 85.19%。
"High"意味着什么?意味着模型在某个风险领域强到 OpenAI 认为必须上更强的安全措施才能部署。而 Critical 是更严重的红线。OpenAI 强调,在针对 Chromium 和 Firefox 的测试中,Sol 能找到漏洞和"利用原语"(构成攻击的零件),但没能自主拼出一条完整可用的攻击链——所以没越过"网络关键"门槛。
这里藏着网络安全 AI 最经典的两难:一个能推理出漏洞的模型,既能帮防御者加固系统,也能帮攻击者破城。OpenAI 的论据是:Sol 现阶段"找漏洞和补漏洞"的本事明显强于"独立发动完整攻击",所以如果防御者能比攻击者更早拿到这些工具,社会就有一个窗口去提前打补丁。这个论据站得住脚,但那个窗口并不是保证的——一旦攻击能力的进化速度超过防御侧的部署速度,同一批模型就会反过来成为攻击者的助力器。这也是为什么"谁先拿到能力"在这个话题上变得如此敏感。
但这句话要读两遍。它的安心,只在"被测系统当时没表现出越线"这个狭窄意义上成立。能力曲线会移动,脚手架会进化,工具会变强,Agent 会更能坚持。一个这一版拼不出完整攻击链的模型,配上更好的工具和更长的上下文,下一版可能就离得更近了。
最耐人寻味的是,OpenAI 在自己的官方发布文档里,公开吐槽了这套政府准入流程:
"我们不认为这种政府准入流程应该成为长期默认。它会把最好的工具挡在用户、开发者、企业、网络防御者和全球合作伙伴之外。" —— OpenAI 官方发布博客
这是一种很微妙的姿态:一边主动配合管控,一边公开表达不满。它精准地折射出当下前沿 AI 实验室的处境——发布一个顶级模型,已经不再只是产品、公关和基础设施的事,它同时是一桩安全案、政策案、政府关系案,和访问控制案。
写在熔岩与温泉之间
GPT-5.6 这次最该被记住的,不是某个跑分超过了谁。
是这个信号:AI 强到一定程度,模型本身就开始长得不像一款 SaaS 软件,而更像一座关键基础设施。 访问权限变成动态的——你的信任状态、产品入口、使用场景、账号历史,都会影响你能用到哪一档能力。模型从"一次性吐字的打字机",变成了一个边想边被实时监控的算力调度系统;而这个系统能不能交到你手上,背后牵扯的是基准测试、政策框架、地缘博弈。
冰岛蓝湖是个奇妙的隐喻:那一汪乳蓝色的温泉,美得不真实,但它就嵌在黑色的火山熔岩之间——能量与危险共处一地。GPT-5.6 也是这样:它最迷人的能力(推理、编码、找漏洞),和它最需要被约束的能力(找漏洞、生物、网络攻击),其实是同一件事的两面。真正的问题从来不是"网络安全 AI 是好是坏",而是"谁拿到哪一档能力、配上什么监控、负什么责任"。
这一次,OpenAI 给出的答案是:先锁起来,再慢慢放。你未必同意,但很难说它完全错
📚 扩展阅读
