 夜雨聆风
夜雨聆风2026 年 6 月 24 日,旧金山一场没有彩排过头的发布会上,博通 CEO Hock Tan 把一块刚出炉的工程样片亲手递给了 Sam Altman 。芯片有一个不太正经的名字——Jalapeño,西班牙语里的"小辣椒"。

这枚指甲盖大的硅片背后,是 9 个月的研发周期、台积电 3nm 工艺的最大光罩尺寸、 10 吉瓦的部署承诺,以及超过一万亿美元的资本开支叙事。作为这个星球上最大的英伟达买家之一, OpenAI 正式宣布——它要自己造铲子了。
消息出来当天,博通股价没动多少,市场显然在等更多细节。但圈内人都明白:这不是一颗普通的芯片,这是一家软件公司正式踏进上游硬件深水区的物理证据。
一、被 Azure 电费账单逼到墙角的三年
要讲清楚 Jalapeño 为什么是 2026 年 6 月而不是 2024 年或者 2028 年,得回到三年半以前。
2022 年 11 月 30 日, ChatGPT 上线。五天破百万用户,两个月破亿。这件事的影响有两层:第一层人人都看见了,叫"生成式 AI 元年";第二层藏在 Altman 和 Greg Brockman 心里,他们看见的是另一个数字——账单。
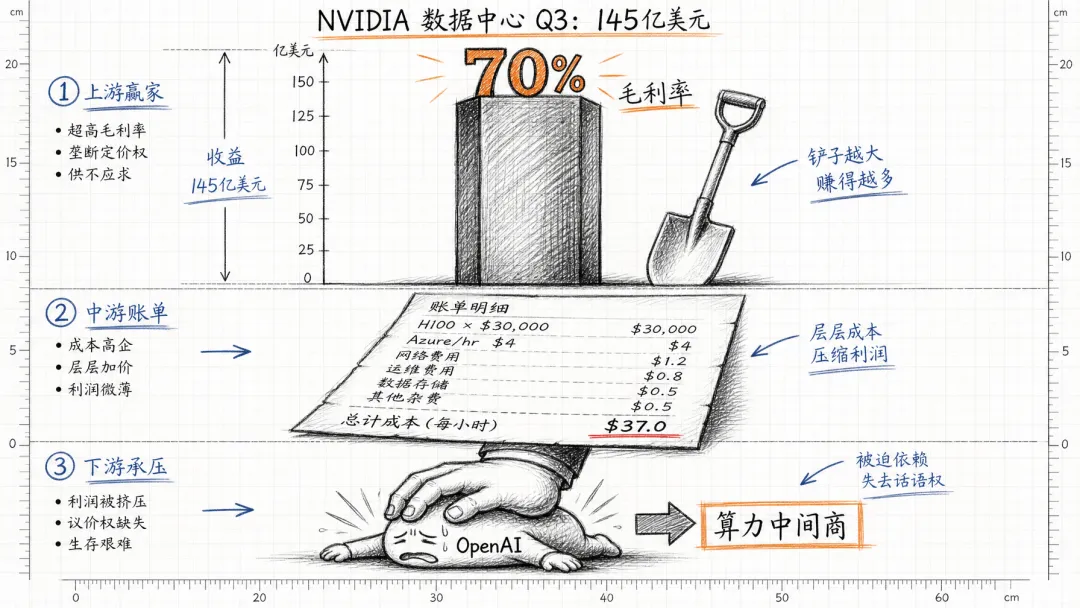
ChatGPT 每回答一个问题,背后是 Azure 数据中心里一组英伟达 A100 、后来是 H100 在跑推理。 OpenAI 当时几乎所有的 GPU 都向微软 Azure 租用,而 Azure 又向英伟达买。每张 H100 采购价 3 万美元起,到了云上一小时租金能到 4 美元上下。用户曲线在涨,推理调用量在涨,账单也在涨——而毛利率却被英伟达这个"算力中间商"按在地上摩擦。
英伟达 2023 年 Q3 的财报数据给了答案:数据中心业务季度营收 145 亿美元,毛利率超过 70%。一句行业黑话开始流传——"AI 淘金时代,英伟达是卖铲子的,而且是唯一一家卖铲子的"。 OpenAI 是当时最大的铲子买家之一。
这种结构性的不舒服,催生了 2024 年初那则震惊全球的传闻。
2024 年 2 月 8 日,《华尔街日报》披露: Altman 正在中东、亚洲、北美四处奔走,试图为一个"重塑全球芯片产业"的项目募集5 万亿到 7 万亿美元资金。这个数字大得近乎荒诞——7 万亿超过日本一年的 GDP ,相当于全球半导体行业年产值的十倍以上。
翻译一下,这就是 Altman 第一次公开把"自己搞芯片"摆上台面。当时舆论几乎一边倒认为是疯狂念头: Scott Alexander 在 Astral Codex Ten 上写了篇长文,说这本质上是想把全球芯片供应链一次性中央集权化重做; CSET 、 CNBC 、《福布斯》几乎都在唱衰。
但这个 7 万亿没有完全落地不代表它无意义。 Altman 的风格一向如此,先把最大的那个气球放出去,再回过头落地能落的。
二、从 Google 挖来的关键先生
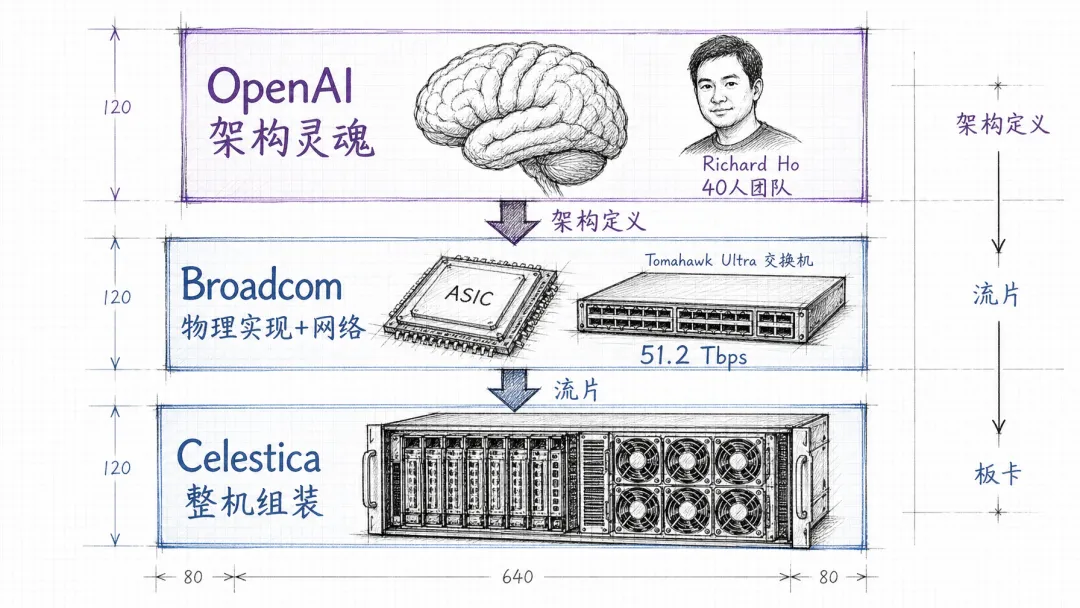
2023 年底, OpenAI 悄悄做了一件更具体的事:招 Richard Ho 。
Ho 在芯片圈分量很重。加入 OpenAI 之前,他在 Google 主导了 TPU v4 和 v5 的设计,更早还在 Lightmatter 做过资深副总裁,再往前是 Cadence 的研发总监。 Google 的 TPU 项目从 2013 年 Jeff Dean 那张"如果每个用户每天和 Google 说三分钟话, CPU 数据中心就要翻倍"的餐巾纸演算开始,到 2016 年 TPU v1 部署,再到今天 TPU v6 Trillium 成为 Gemini 的核心算力底座——这条十年路径, Ho 亲历了大半段。
把 Ho 挖来,等于把 Google 十年 TPU 经验直接复制了一份关键拷贝。 Reuters 在 2025 年 2 月披露 Ho 领导着 OpenAI 内部芯片团队,团队规模约40 人。到 2025 年 8 月, DCD 报道 OpenAI 又挖来一位 Google TPU 校友。
这里有个细节值得展开:40 人——按行业标准是非常小的。英伟达一个 GPU 项目通常上千名工程师, Google TPU 团队也有数百人。 40 人能搞定一颗对标 Blackwell 的推理 ASIC ,这件事本身就说明两件事:一是 Ho 带来的方法论极度精简高效,二是 OpenAI 从一开始就没打算自己包圆所有环节,而是要找一个"外科手术式"的合作伙伴来补齐工程化能力。
这个伙伴,就是博通。
很多人第一反应会觉得"OpenAI 造芯片应该找台积电"或者"找美满电子"。选博通其实是个非常精明的判断。
博通在 ASIC 定制业务上有一段相当低调但极其重要的历史。Google 的 TPU——从 v1 到 v5——背后的物理实现合作方就是博通。 Meta 的 MTIA 、字节的某些自研芯片,背后也有博通的影子。更关键的是网络。 AI 推理芯片不是单卡跑,是几千上万卡组网跑。博通的 Tomahawk Ultra 做到了 51.2 Tbps 的交换容量、 250 纳秒单跳延迟,专门为 AI scale-up 场景打造。
OpenAI 选博通,等于一次性买到"ASIC 实现+网络配套"的全套能力,避免了和多家供应商分别谈再做集成的工程地狱。
合作的正式落地分两步走。 2025 年 9 月初,博通在财报电话会上披露了一笔"100 亿美元的神秘客户订单",业内分析师立刻猜是 OpenAI ,当时博通管理层一度否认,制造了一点烟雾弹。一个月后, 2025 年 10 月 13 日, OpenAI 和博通正式联合公告——双方将合作部署 10 吉瓦的 OpenAI 自研 AI 加速器。
10 吉瓦意味着什么?一座典型核电站的输出功率大约是 1 吉瓦, 10 吉瓦相当于十座核电站全力运转喂给这些芯片。同日博通股价暴涨 10%以上,市值单日增加 2000 亿美元上下。
三、九个月,那条压缩到极致的曲线
从 2025 年 9 月底正式启动设计,到 2026 年 6 月 24 日宣布拿到工程样片——9 个月。
这个数字必须放进语境才能看出它的疯狂:
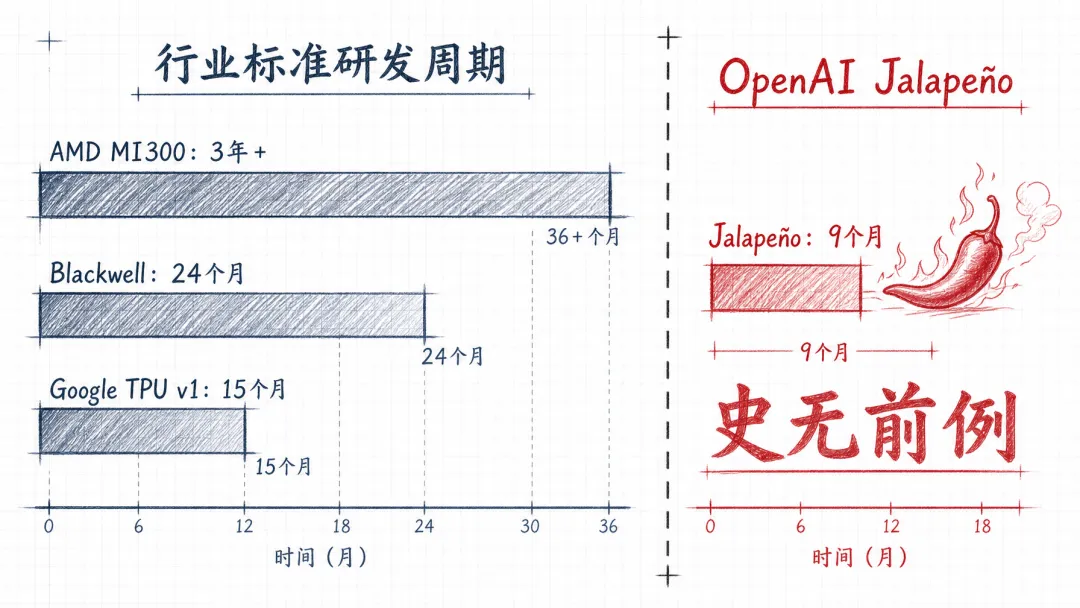
9 个月里要塞进去的活包括:架构设计、 RTL 编写、验证仿真、物理实现、设计签核、流片、首硅测试。任何一个环节卡住一周都会把整体推迟。
OpenAI 怎么做到的?发布稿里给出了一个很有意思的回答——他们用自己的 AI 模型加速了芯片设计过程。 Ho 在公开访谈里没透露具体细节,但行业里有迹可循: Codex 这类代码生成模型在 Verilog/SystemVerilog RTL 生成、测试用例生成、约束文件编写上能极大加速。 Cadence 和 Synopsys 的 EDA 工具链这两年都集成了大模型, OpenAI 自己显然把这个闭环用到了极致。
这件事本身就是 Jalapeño 叙事最有冲击力的一部分:AI 设计芯片,芯片运行 AI。 Tom's Hardware 评测时用了一个词——reticle-sized ASIC ,满光罩尺寸的芯片,这是台积电 3nm 工艺下物理可能的最大单芯片面积,意味着 OpenAI 从一开始就把芯片做到了硅片极限。
发布稿里还有个细节容易被忽略:早期样片"已在实验室稳定运行GPT-5.3-Codex-Spark"。这个模型名称之前没在任何 OpenAI 公开渠道出现过。从命名规律看,应该是 GPT-5.3 系列的代码专用衍生版——mini 是小模型、 turbo 是高吞吐、 Spark 从字面理解可能是低延迟轻量版。
Jalapeño 首先在 Codex 类工作负载上验证,逻辑是清楚的:代码生成对延迟最敏感(程序员要实时补全),对吞吐量要求高(一次补全要吐几百 token ),对成本压力最大(专业用户日调用量动辄上千次)。如果 Jalapeño 能把 Codex 的单 token 成本砍下来, OpenAI 在开发者市场的定价权就会被彻底重塑——这是直接面对 Anthropic Claude Code 、 Cursor 等竞品的最锋利武器。
至于晶圆代工, 36 氪和多家媒体确认是台积电 3nm 工艺。三方分工大致是: OpenAI 负责架构定义和"灵魂"部分,博通负责物理实现和网络,加拿大 Celestica 负责板卡、机架、整机系统的最后一公里组装。

四、四强争霸:算力世界的战国时代
把镜头拉远, 2026 年中的 AI 芯片市场已经不是"英伟达一家独大"了。它正在变成一个"一霸三强多元"的格局——英伟达依然是绝对老大,但围绕它的 Google 、 AWS 、 Meta 、 Microsoft 、现在加上 OpenAI ,每家都在用自研芯片啃下英伟达的某一块肉。
英伟达 2026 年中的主力是 Blackwell 系列,下一代 Rubin 据传 2026 年底亮相。它有 CUDA 二十年生态、最完整的软件栈、最大规模的部署案例。 GB200 NVL72 机柜把 72 颗 GPU 用 NVLink 连成一台"超级 GPU",单机柜推理性能比 H100 集群高 30 倍。一位行业人士在 LessWrong 上估算,OpenAI 内部至少有 40 万颗 GB200 在跑。
但抱怨也不少。 Reuters 在 2026 年 2 月报道, OpenAI 对 Nvidia 最新一代芯片在某些推理场景下的表现"并不满意",特别是 coding workloads ,这成为 Jalapeño 立项的直接导火索之一。
注意,我们没有否认英伟达 Blackwell 的强大,只是陈述一个客观存在的事实: B200 要服务所有 AI 客户的所有 workload ,必然要在通用性和专用性之间妥协,而 OpenAI 对自家 workload 的理解比任何外部芯片厂商都深。
Jalapeño 有一个"前世镜像",那就是 Google TPU 。 TPU 项目的起源在 2013 年,到 2026 年已经进化到 v6 Trillium 。重要的反讽是:Jalapeño 的总设计师 Richard Ho 恰好出自 TPU 团队,相当于"TPU 毕业生"在 OpenAI 做了一个 TPU 2.0。
AWS 的 Trainium 走的是另一条路。 2025 年 10 月, Anthropic 承诺到年底使用100 万颗Trainium 芯片。 2025 年 12 月, AWS 激活了"Project Rainier"——专门为 Anthropic Claude 训练打造的 50 万颗 Trainium2 集群,号称世界上最大的非英伟达 AI 集群。说白了就是, AWS 靠 Anthropic 这个外部锚客户撑起规模效应, OpenAI 靠自家 ChatGPT 、 Codex 的内部需求撑起出货量。
Meta MTIA 走的是"快、广、深"路线。 2026 年 3 月 Meta 一次性官宣四代芯片——MTIA 400 、 450 、 500 。 Meta 是"广撒网",覆盖推荐、广告、 Llama 推理多个场景; OpenAI 是"单点突破", Jalapeño 只做 LLM 推理。两家策略差异背后是业务结构差异:Meta 有多类 AI workload , OpenAI 业务相对单一。
最尴尬的是 Microsoft Maia 。第二代代号 Braga ,原计划 2025 年量产,被 The Information 爆出延期到 2026 年。直到 2026 年 1 月才正式发布 Maia 200 。这里有个戏剧性的事实——Microsoft 是 OpenAI 最大的算力供应方和投资方,但 Microsoft 自己的 Maia 和 OpenAI 的 Jalapeño 在 Azure 数据中心里是并存关系。我用你的电、但跑我自己的芯片,这是 2026 年云厂商和大模型公司关系的新范式。
五家放在一起对比,最显眼的两个数字是:OpenAI 研发周期 9 个月,是 Microsoft Maia 200 研发周期的四分之一; OpenAI 是第 1 代, Google TPU 是第 6 代。
当前格局可以用一句话概括:英伟达 80%份额的山顶,加上五家自研芯片+一家挑战者 AMD 的山腰。摩根士丹利 2026 年初的报告估算,到 2027 年底,自研 ASIC 将占据数据中心 AI 推理算力部署的 30%以上。
Jalapeño 让格局更复杂的一点是:它是第一颗由"非云厂商"主导设计的大规模 AI 芯片。 Google 、 AWS 、 Meta 、 Microsoft 四家都同时是云服务商,自研芯片有现成的部署场景。 OpenAI 是纯模型公司,自己没有云,要靠租 Azure 、 Oracle 、 CoreWeave 的机房来部署 Jalapeño 。这种"上游往下游打"的姿态,可能会改变云厂商和 AI 公司之间的权力结构。
五、晚入场的玩家可以站在前人肩上
如果把五家放到同一条时间线上排:
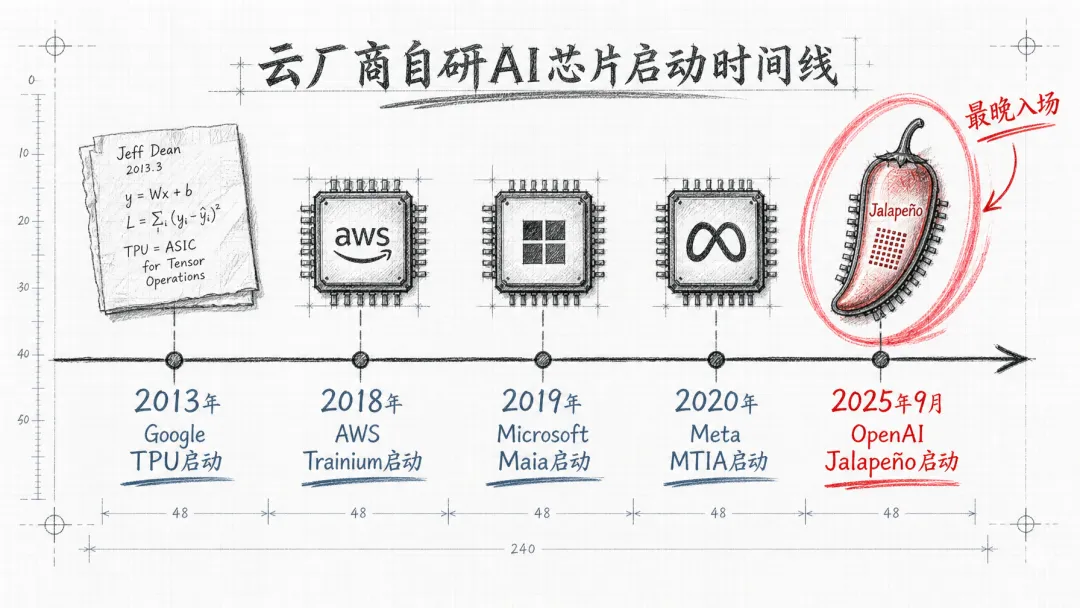
Google TPU 启动是 2013 年,比 OpenAI 早 12 年。 AWS Trainium 启动是 2018 年,早 7 年。 Meta MTIA 启动是 2020 年,早 5 年。 Microsoft Maia 启动是 2019 年,早 6 年。 OpenAI Jalapeño 启动是 2025 年 9 月。

OpenAI 是这场牌局里最晚入场的玩家。但反过来看,它也是研发周期最短的玩家——9 个月对比 Google 十年迭代到第 6 代。这背后的逻辑是清晰的:晚入场的玩家可以站在前人肩上。 Ho 本人是 TPU 团队出身,博通是 TPU 、 MTIA 的物理实现伙伴, 3nm 工艺已经成熟, HBM3/HBM4 已经量产, EDA 工具已经融合大模型——OpenAI 不需要走 Google 当年踩过的所有坑,可以直接跳到方法论的最先进版本。
更妙的是, OpenAI 还多了一个前人没有的工具:AI 自己。 Google 做 TPU v1 的时候没有 Codex , Meta 做 MTIA v1 的时候没有 GPT-4 。 OpenAI 在 2025 年做 Jalapeño 的时候手里有 GPT-5 系列。这是"AI 辅助造芯"第一次在主流硬件项目里被大规模、系统化地用上。
但同样的历史也埋下了劣势的种子。
英伟达有 CUDA 二十年积累, Google 有 JAX/XLA 十年积累, AWS 有 Neuron SDK 五六年积累。 OpenAI 完全没有外部开发者生态——Jalapeño 目前只跑 OpenAI 自己的模型。
Google 、 AWS 、 Microsoft 、 Meta 都是"芯片+云+模型"三位一体。 OpenAI 只有"模型+芯片",机房要靠 Stargate 新建或者租用。 Stargate 这个项目已经被 The Information 报道在 2026 年初未达到当初的 10 吉瓦目标,意味着 Jalapeño 的部署节奏可能受制于数据中心建设进度。
更深层的问题在财务模型上: OpenAI 虽然营收在涨( 2026 年达到月度 20 亿美元规模),但芯片+数据中心的资本开支承诺已经超过万亿。如果 AGI 到来时间晚于预期、或者推理需求增长不及预期、或者下一代 Rubin 大幅领先,财务模型会非常吃紧。
六、那张餐巾纸和这枚小辣椒
故事开始的时候我们提到, Jeff Dean 在 2013 年用一张餐巾纸算了一笔账,催生了 Google TPU 。
这张餐巾纸的逻辑是这样的:如果 AI 变成每个用户每天都在用的东西,传统硬件就撑不住,必须造新硬件。
2026 年 OpenAI 造出 Jalapeño ,遵循的是同一个逻辑——只是把"语音识别每天三分钟"换成了"ChatGPT 每天每个人聊一万个 token"。
13 年过去, AI 从"未来可能爆发"变成了"已经爆发并且账单太贵",而解决问题的方法论几乎一模一样:当软件足够普及,软件公司就必须自己造硬件。这个规律在 iPhone 时代( Apple 自研 A 系列芯片)、 AWS 时代( Graviton ARM CPU )、 Google 时代( TPU )反复验证。
Jalapeño 是这条规律的最新一次验证,也是最快的一次——9 个月,对比 Google TPU v1 的 15 个月、 Apple A4 的两年多。
但它可能不是最后一次。下一个被这条规律抓住的,可能是 Anthropic 、 xAI ,或者某家中国大模型公司。
OpenAI 最大的赌注从来不是这枚名字像玩笑的小辣椒芯片本身,而是它背后那个判断——算力将成为未来经济的核心驱动力。
如果这个判断对了, Jalapeño 只是一个开始。如果错了,那这条仓促的 9 个月时间表,会成为硅谷历史上最贵的一次试错。
软件吃掉世界的故事讲了十五年。现在轮到软件公司,掉过头来吃硬件了。
