 夜雨聆风
夜雨聆风业务场景
财务、运营人员经常需要从年报、报表类PDF文件中手动摘抄文字、统计表格数据、保存产品配图,复制粘贴、截图导出工作量大且容易出错。使用PAD的PDF提取功能,可自动批量提取PDF内文本、结构化表格、图片,直接导出至Excel/CSV用于数据分析,大幅减少人工摘抄整理的重复工作。
一、Extract text 提取PDF文本
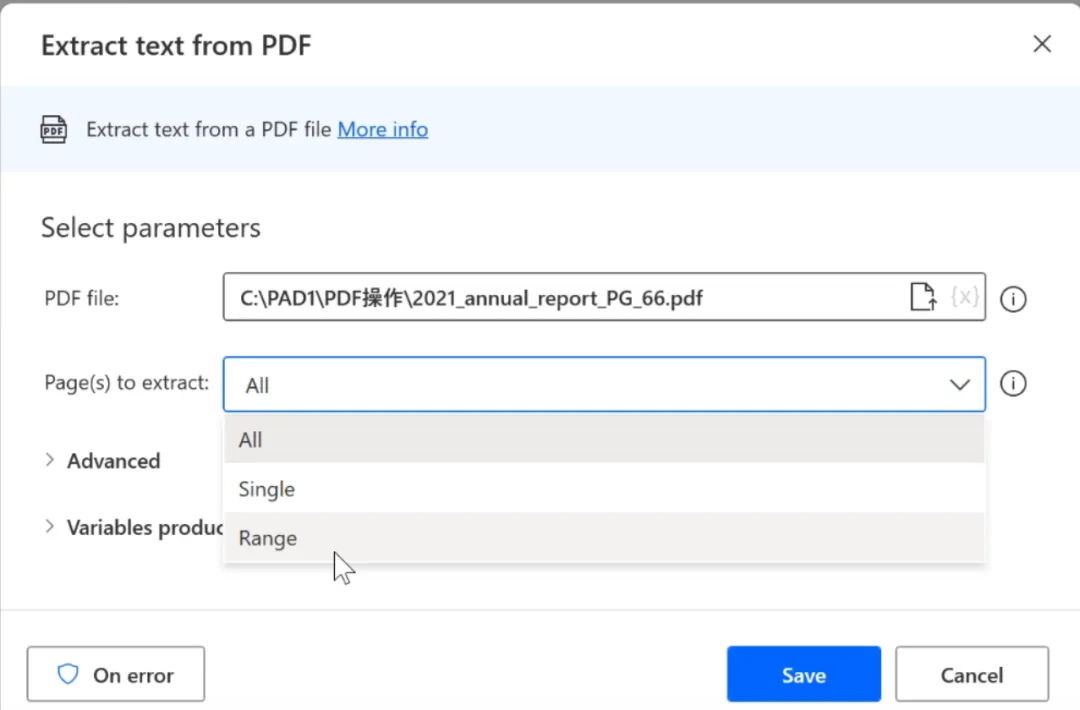
参数配置
PDF文件路径; 提取页面:全部/单页/页码范围; 高级:PDF打开密码、优化结构化数据开关;
两种提取效果
不开启优化:纯平铺文字; 开启结构化优化:自动识别表格版式,保留行列分层格式;
输出变量:extracted PDF text。
D21 PAD PDF三大提取操作实操
业务场景
财务、运营人员经常需要从年报、报表类PDF文件中手动摘抄文字、统计表格数据、保存产品配图,复制粘贴、截图导出工作量大且容易出错。使用PAD的PDF提取功能,可自动批量提取PDF内文本、结构化表格、图片,直接导出至Excel/CSV用于数据分析,大幅减少人工摘抄整理的重复工作。
一、Extract text 提取PDF文本
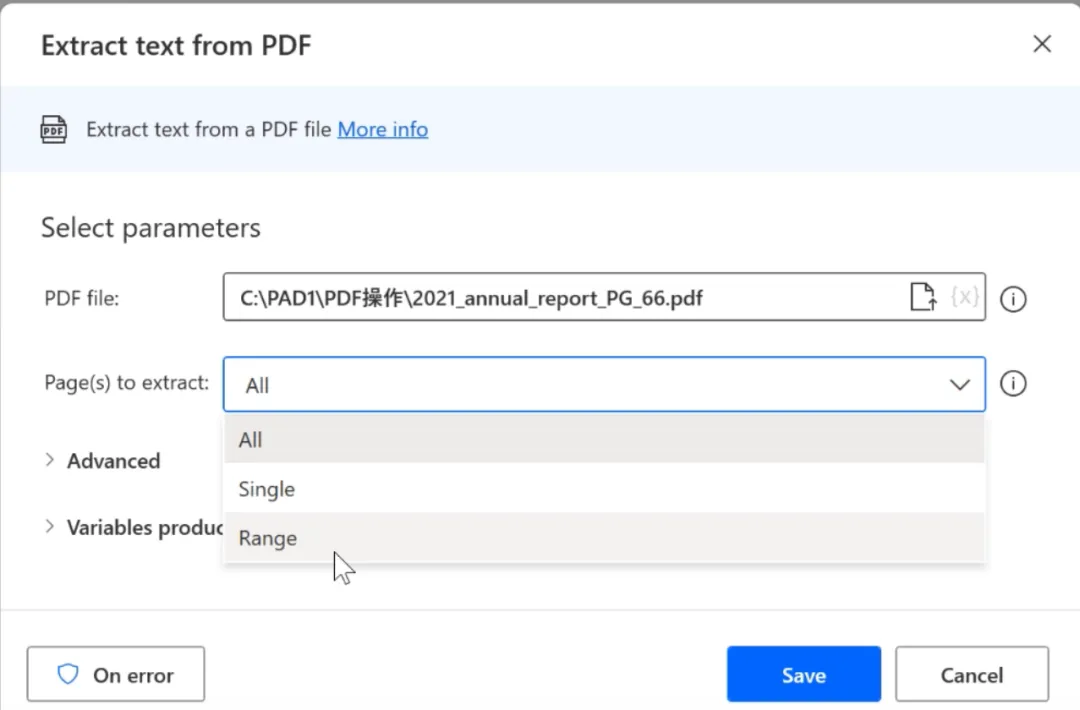
参数配置
PDF文件路径; 提取页面:全部/单页/页码范围; 高级:PDF打开密码、优化结构化数据开关;
两种提取效果
不开启优化:纯平铺文字; 开启结构化优化:自动识别表格版式,保留行列分层格式;
输出变量:extracted PDF text。
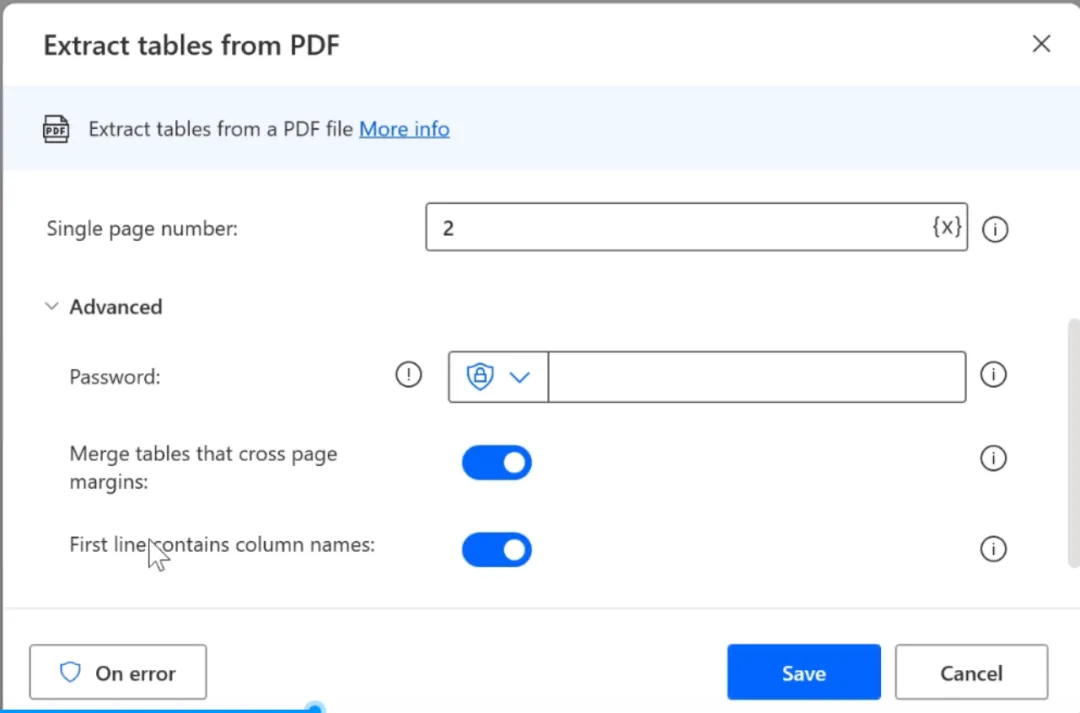
二、2. Extract tables 提取PDF表格
参数配置
文件路径、目标页码、PDF密码; 跨页表格合并开关、首行作为表头开关;
运行结果 自动识别文档内全部表格,输出结构化数据表变量,可直接写入Excel、CSV,适合提取销售、分类统计报表。
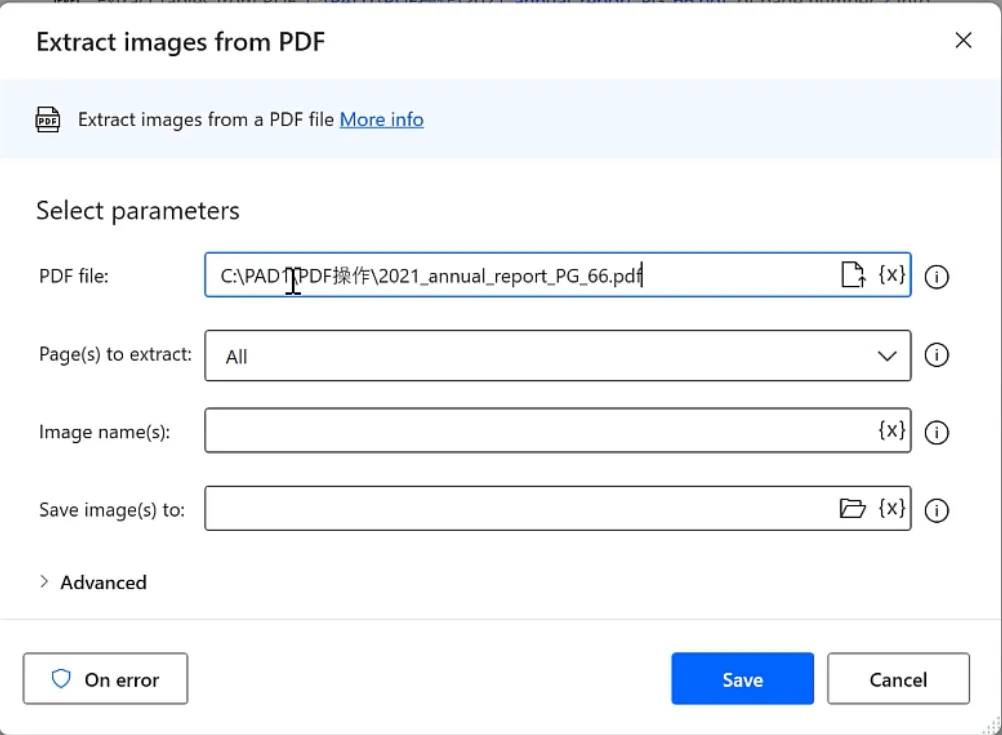
三、3. Extract images 提取PDF图片
参数配置
PDF路径、指定提取页码; 图片命名前缀、本地保存文件夹;
执行效果 无需截图,批量导出页面内所有图片,文件统一「前缀+序列号」命名,直接保存到指定目录,无返回变量。
四、通用适用场景
企业年报、报表PDF自动扒取文字、业务数据表、产品配图,实现数据脱离PDF归档到表格文件。
