 夜雨聆风
夜雨聆风
01
引言
在开始数据分析之前,我们首先需要把外部数据文件读入R语言中。前面我们已经讲解了R语言导入csv表格数据详解。这一节我们将继续讲解R语言如何导入Excel表格数据。它和csv表格是我们日常使用最多的数据格式。
02
教程
在开始导入之前,有必要先搞清楚这两个后缀名的区别。
| 对比维度 | .xls(旧版) | .xlsx(新版) |
|---|---|---|
| 诞生时间 | Excel 2003及以前版本 | Excel 2007及以后版本 |
| 核心结构 | 复合文档类型的二进制格式 | 基于XML的压缩格式(本质是一个ZIP文件) |
| 文件体积 | 较大 | 更小(经过压缩) |
| 最大行数 | 65,536行 | 1,048,576行 |
| 最大列数 | 256列(IV列) | 16,384列(XFD列) |
| 兼容性 | 旧版专用 | 向下兼容,可打开.xls文件 |
简单来说,.xlsx 是更现代、更高效的文件格式,支持更大的数据量,且文件体积更小。在实际工作中,如果条件允许,建议优先使用 .xlsx 格式。
无需外部依赖:不像
xlsx包那样需要安装Java环境,安装和使用都非常简单。跨平台:在Windows、macOS、Linux上均可稳定运行。
同时支持 .xls 和 .xlsx:底层分别通过
libxls和RapidXML库解析两种格式。
首先安装并加载该包:
# 公众号【廿年一觉】演示所用# 安装 readxl(只需执行一次)install.packages("readxl")# 加载 readxllibrary(readxl)
readxl 包的核心函数是 read_excel(),用法非常直观——只需传入文件路径即可。
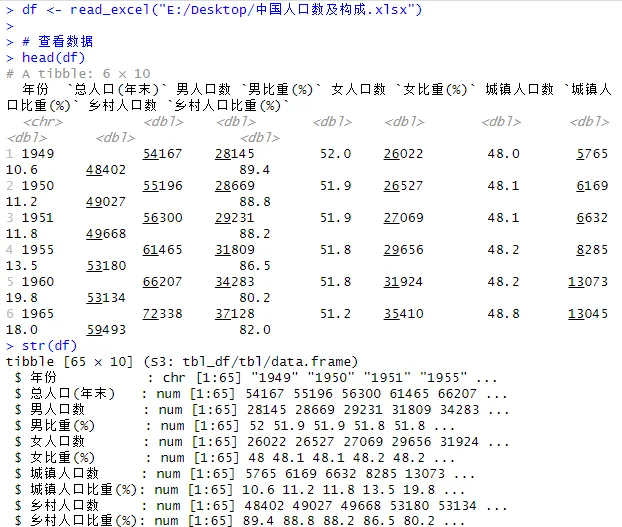
# 公众号【廿年一觉】演示所用# 导入整个Excel文件(默认读取第一个工作表)df <- read_excel("E:/Desktop/中国人口数及构成.xlsx")# 查看数据head(df)str(df)
read_excel() 默认将第一行作为列名,并自动推断每列的数据类型。返回的是一个 tibble(一种增强版的data.frame)。
1.指定工作表(Sheet)
Excel文件可能包含多个工作表。read_excel() 通过 sheet 参数指定要读取的工作表,可以使用工作表名称(字符串)或位置编号(整数,从1开始)。
# 公众号【廿年一觉】演示所用# 按名称指定df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", sheet = "Sheet1")# 按位置指定(第一个工作表)df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", sheet = 1)
2.指定读取范围(Range)
如果只想读取Excel文件中的某一块区域(而非整个工作表),可以使用 range 参数。
# 公众号【廿年一觉】演示所用# 读取指定单元格区域(类似Excel中的选区)df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", range = "A1:F20")# 也可以包含工作表名称df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", range = "Sheet1!A1:F20")
3.处理非标准表头
有些Excel文件的表头不在第一行,或者有多行表头。这时可以用 skip 跳过前面的行,或者用 col_names = FALSE 不让第一行作为列名。
# 公众号【廿年一觉】演示所用# 跳过前2行,从第3行开始读取df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", skip = 2)# 不将第一行作为列名,后续自行设置df <- read_excel("E:/Desktop/中国人口数及构成.xlsx", col_names = FALSE)
4.手动指定列类型
当自动类型推断不准确时(例如日期被识别为数字、数值被识别为文本),可以用 col_types 手动指定。
# 公众号【廿年一觉】演示所用# 手动指定每列的类型df <- read_excel("E:/Desktop/中国人口数及构成.xlsx",col_types = c("text", "numeric", "date", "skip", "guess"))# "skip" 表示跳过该列不读取# "guess" 表示让R自动推断
"skip"、"guess"、"logical"、"numeric"、"date"、"text"、"list"。tidread_excel() 提供了丰富的参数来控制导入行为,以下是几个最常用的:
sheet | 指定工作表(名称或编号) | sheet = "Sheet1" |
range | 指定读取的单元格范围 | range = "A1:C10" |
col_names | 是否将第一行作为列名 | col_names = TRUE(默认) |
col_types | 手动指定每列的数据类型 | col_types = c("text", "numeric", "date") |
na | 指定哪些值视为缺失值 | na = c("", "NA", "-") |
skip | 跳过前几行再开始读取 | skip = 2 |
n_max | 最多读取多少行数据 | n_max = 100 |
trim_ws | 是否去除单元格内容首尾空格 | trim_ws = TRUE(默认) |
readxl | 无外部依赖,简单易用 | 首选推荐,适合绝大多数场景 |
openxlsx | 支持读写,可保留格式信息 | 需要保留Excel格式(颜色、样式等)时 |
xlsx | 功能强大,但依赖Java环境 | 处理复杂格式,但需配置Java |
# 公众号【廿年一觉】演示所用# 安装并加载install.packages("openxlsx")library(openxlsx)# 读取Excel文件df <- read.xlsx("E:/Desktop/中国人口数及构成.xlsx", sheet = 1)
03
总结
首选方法: readxl包无需Java环境、跨平台、简单易用,是导入Excel数据的首选。核心函数:
read_excel(),只需传入文件路径即可完成导入。常用参数:
sheet(指定工作表)、range(指定区域)、col_names(列名设置)、col_types(列类型)、skip(跳过行)。数据查验:导入后立刻用
head()、str()、summary()检查数据是否正确。


本文为原创文章,版权归本公众号所有。转载请注明来源。
