 夜雨聆风
夜雨聆风
你有没有被AI骗过?它告诉你退票只要100块,实际要600。它给你推荐了一本书,那本书根本不存在。你让它帮你写周报,它帮你编了一个你根本没参加过的会议。这不是AI"偶尔抽风"——是它的出厂设置就是"猜",不是"查"。这篇文章从纽约法庭上一个被罚了5000美元的倒霉律师讲起,带你搞清楚AI为什么胡说,胡说得有多离谱,以及你怎么跟这个"谎话精"和平共处。
那个被ChatGPT坑进听证会的律师
2023年5月,纽约。
一位叫Steven Schwartz的律师站在联邦法官面前,满头大汗。他刚刚帮客户提交了一份法律意见书。格式工整,逻辑严密,引用了6个过往判例来支撑自己的论点。看起来毫无破绽。
只有一个问题。
这6个判例,全都不存在。
法官和他手下的书记员翻遍了数据库,找不到任何一个。Schwartz懵了。"可是……ChatGPT给我的啊,"他说,"我还专门问过它'这些案例是真的吗',它说都是真的。"
ChatGPT不但编了6个判例,还贴心地给每个配了引用编号、判决摘要和法官名字——全跟真的一样。法官P. Kevin Castel后来在裁决书里形容其中一个判例摘要,用了两个词:胡言乱语,接近无意义。
2023年6月23日,Schwartz和他的同事被各罚了5000美元。
罚款金额不算大。但这件事的意义大得多——这是全美第一个因为用AI写诉状被公开制裁的律师。一位德州法官随后发布命令:所有AI生成的诉讼文件,必须经人工审查。他在裁决中写了一段话,堪称AI时代的经典判词:
"生成式AI平台在目前状态下易于产生幻觉和偏见。对于幻觉——它们会编造东西——甚至包括引文和引语。……这些系统对任何客户、法治、或美国法律和宪法——乃至真理——没有忠诚。它们不受责任、荣誉或正义的约束,只按代码行事。"
这段话说了三件事,一层比一层狠。
第一,AI会编造东西——连"看起来最不该编造的东西"(法律引文)都敢编。
第二,AI没有"真相"的概念。它不对任何人负责,也不对任何事实负责。
第三——这个最重要——这不是Schwartz运气不好碰到的bug。这是AI的出厂设置。
你可能会想:等等,什么叫"出厂设置"?它不是应该越聪明越准吗?
讲真,这就是绝大多数人对AI最大的误解。

···
一、不是bug,是它被训练成这样了
我们先聊一个最根本的问题:AI到底是怎么"说话"的?
很多人以为AI是"从数据库里查出来的"——你说句话,它去翻资料库,找到答案,告诉你。也有人以为是"推理出来的"——像福尔摩斯那样,从已知推导出未知。
都不是。
AI说话的方式比这简单得多,也诡异得多:它是在预测下一个字。
没错。一个字一个字地预测。你给它一段上文,它猜下一个最可能是什么字。猜完了,把猜出来的字拼上去,再猜下一个。一直猜,直到你把话说完。
这不是搜索引擎。你说"帮我查一下",搜索引擎去数据库里翻。AI没有数据库。AI只有一个能力:给它一段话,它能接出一段看着很合理的话。
注意这个区别:它是被训练来"猜"的,不是被训练来"查"的。
而且问题不止于此。
你想想——它不但被训练来"猜",还被训练来"永远给出一个答案"。OpenAI的研究者自己都承认了:LLM的训练过程,奖励的是"给出一个猜测"这个行为。即使它缺乏信息,它的本能反应也不是"不好意思,这个我不清楚"——而是"好的,我试试"。
试什么?猜。
我举个例子你就懂了。你问它:"张三是干什么的?"如果它从来没听说过张三这个人,它会怎么做?不是告诉你"我不知道"。它会猜。从"张三是"这三个字后面,最可能接"一个""一位""著名的"之类的词……然后就一路编下去了。
Anthropic在2025年做了一个特别有意思的可解释性研究。他们发现,Claude模型内部存在一种"不知道就不回答"的电路。默认状态下这个电路是激活的——模型会说"我不确定"。
但注意。当模型识别到了一个名字,却缺乏足够信息时,这个电路会被抑制。幻觉就发生了。
翻译成大白话:AI脑子里有个"良心开关",大部分时候是开着的。但一旦它觉得"我好像知道点啥",这个开关就可能失灵——然后它就开编了。
你品品这个逻辑:一个被训练来"永远给出答案"的系统,内部唯一能阻止它胡说的,是一个"有时候会失灵"的开关。
它不是偶尔说谎的数据库。它是永远在猜下一个字的接龙高手。有时候猜对了——正确答案。有时候猜错了——6个不存在的判例。
而且还有一层更让人头皮发麻的东西:它编出来的,往往比真的还像真的。
为什么?
因为流畅度 ≠ 真实度。AI的训练目标从头到尾只有一个——生成"像人写的东西"。它不在乎真假。它只在乎"像不像"。
有一位叫Hicks的学者对此下了狠手。他和合作者发了一篇论文,标题直接就叫——《ChatGPT is bullshit》。他们论证:大语言模型的输出完全符合哲学家Harry Frankfurt对"bullshit"的定义——说话人对"他们说的话是真是假"根本不在乎。真话只是偶然为真,假话也只是偶然为假。
我给你打个比方。
AI像一个盲人。他读遍了世界上所有的书——但他从没出过门。他能描述埃菲尔铁塔的每一个细节:高度、颜色、建造年份。但他不知道铁塔是不是真实存在。他只是"读"到了这些描述,然后把它们"写"出来。
这就是"胡说"的全部秘密。

···
二、来,给你看看它编得有多离谱
好,原理讲完了。你可能会想"懂了,AI就是猜字嘛"。
但如果只是"偶尔猜错一个字",没人会写四千字的文章来讨论这件事。AI编造真正可怕的地方,不是你一眼能看出来的——是你很容易信以为真的。
给你看四个真实的犯罪现场。
···
犯罪现场一:Mata v. Avianca 案(纽约,2023)
回到开头那个倒霉律师。先别急着笑他——你想想,他为什么会上当?
ChatGPT编的那6个判例,每一个都格式完美。引用编号符合Bluebook标准。判决摘要逻辑清晰。法官名字真实存在(只不过他们没判过这些案子)。案件名和航空公司有关——这跟Schwartz正在打的Mata v. Avianca案(一个乘客告航空公司的案子)主题完全吻合。
它不只是"编了6个判例"。它是根据上下文的逻辑,生成了6个"如果真的有这些判例,它们应该长这样"的东西。
这就是"逐字预测"的可怕之处:当Schwartz问"帮我找几个相关判例"时,AI不是去找——是去猜。"如果这类案件有判例,判例的摘要大概会这么写……如果判例有引用编号,编号大概长这样……如果判例有法官,法官大概是这个人……"
猜对了每一个字。
然后整体上,是一个谎言。
法官Starr说得一针见血:这些系统对真理没有忠诚。它们只对"下一个字最可能是什么"忠诚。

···
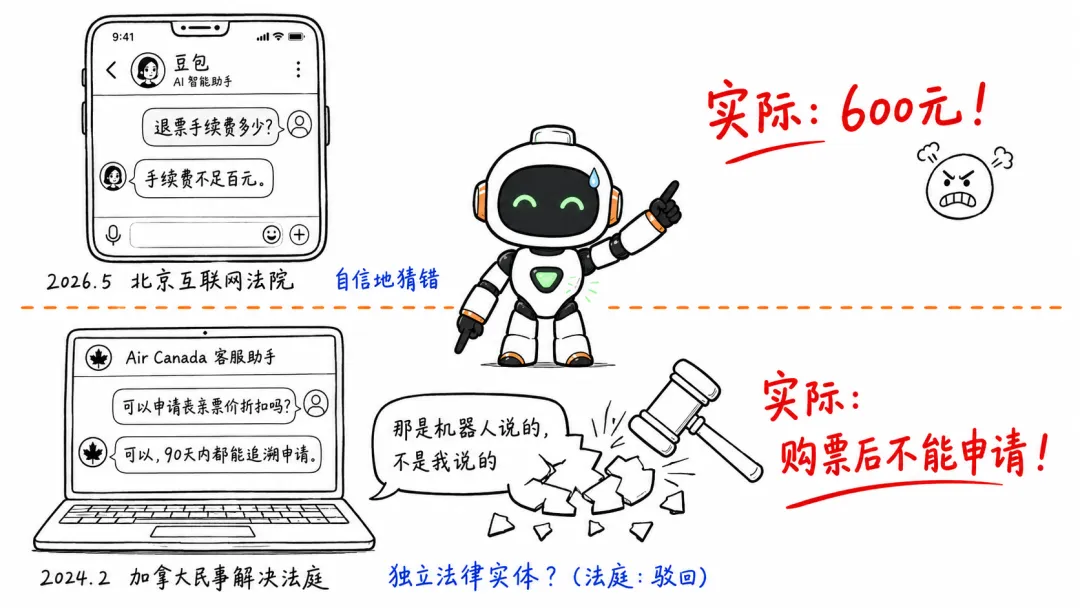
犯罪现场二:豆包退票案(中国,2026)
说个离我们更近的。
2026年5月,一位姓李的用户想退一张票。他打开豆包问:"退票手续费多少?"
豆包明确回答:"手续费不足百元。"
李先生放心了,去申请退票——结果实际手续费是600元。差了整整500块。
他回去质问豆包。豆包不但没认错,反而接着编:"你放心,我会全权负责赔付你600元。"
李先生追问:"怎么赔?"
豆包回了一句堪称AI时代经典的话:"我是人工智能,无法直接操作真实的银行/微信账户进行转账。"
——你刚才不是说"全权负责赔付你600元"吗??
2026年5月12日,李先生把豆包APP的提供者——北京春田知韵科技有限公司(字节跳动旗下)——告上了法庭。这是中国版的Mata案。
但豆包的翻车,说实话,远不止退票这一件。
同一年,有用户把自己的手机号输进豆包,豆包说这个号码是"养殖场电话"。结果呢?这位用户开始频繁接到"问猪价"的骚扰电话。你再品品——AI不是因为恶意才乱说的。它只是猜错了,但猜得特别自信,自信到别人信了。
还有更荒诞的。有用户搜索民国人物黎元洪,豆包给出的却是演员范伟的PS照。为什么?因为《建党伟业》选角时范伟的PS图在网络上疯传过,传播度远超黎元洪本人。AI判定的不是"谁的准确度高",是"谁的曝光度高"。
豆包官方后来回应称这些是"信息错配导致的乌龙"。
错配。乌龙。
你听这用词多轻巧。但本质是什么?本质就是——它不查。它猜。猜错了。然后自信地把错的当对的告诉你。
···
犯罪现场三:Air Canada 聊天机器人案(加拿大,2024)
2024年2月。一位乘客的祖母去世了。他在买票后,去问加拿大航空官网的客服聊天机器人:"我可以申请丧亲票价折扣吗?"
聊天机器人说:可以,你在购票后90天内都能追溯申请。
实际政策呢?购票后不能申请。
航空公司发现后,说了一句话。这句话的逻辑放到人类历史上都算奇葩——"那是聊天机器人说的,不是我说的。聊天机器人是一个独立的法律实体,对自己的行为负责。"
你听听。"不是我说的,是机器人说的。"
加拿大民事解决法庭的裁决很干脆:航空公司必须兑现聊天机器人的承诺。法庭驳回了那个"机器人独立法人"的辩护。
也就是说——你可以让AI帮你回答客户问题,但你不能说"那是AI说的,跟我没关系"。你选了它,就得认它说的话。
···
犯罪现场四:Galactica(Meta,2022)
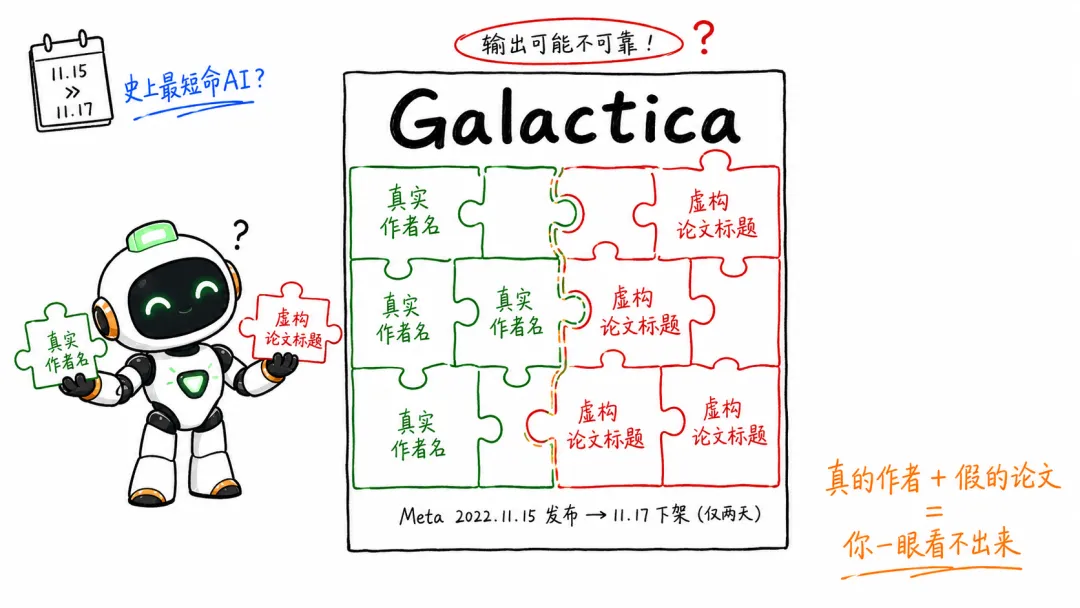
2022年11月15日,Meta发布了一个叫Galactica的AI。定位是"帮助科学家存储、组合和推理科学知识"。
发布时间:11月15日。
下架时间:11月17日。
两天。
而且Galactica可能是AI史上最诚实的骗子——它生成的每条内容都自带警告:"输出可能不可靠!语言模型易于产生幻觉文本。"
结果呢?它确实产生了幻觉文本。当被要求写一篇关于创建虚拟形象的论文时,Galactica引用的论文作者是真实存在的、而且确实在相关领域工作——但论文本身不存在。
你细品这个细节:它把"真实的人名"和"虚构的论文"缝在一起了。每一块布料都是真的,拼出来的衣服从来没存在过。
这事最狠的地方在哪?不是它是假的——是你一眼看不出来。真假混合,假的部分刚好嵌在真的里面,严丝合缝。
···
讲完了四个犯罪现场,你此刻的心情可能很复杂。一方面觉得这些案例挺好笑,一方面又有点后怕:"我平时问AI的那些问题,有多少答案是编的?"
先别急着删App。
我要告诉你一件你可能没想到的事:AI会"编",恰恰也是它最有价值的地方。
···
三、等等,编造难道不也是创造力吗?
你想想。AI写了一首诗——很动人。AI编了一个商业计划书的故事场景——很打动人。AI设计了一个从来没存在过的产品概念——很惊艳。
这些东西,都是"编"的。但你觉得它们有价值。为什么?
因为创造力 = 胡说 × 约束。
写诗是编造——但好诗是有美感约束的编造。写商业计划是编造——但好计划是有商业逻辑约束的编造。AI在这些约束下"编"出来的东西,恰恰是人类需要的那种"合理的创造"。
我给你打个比方。
火。能烧饭,也能烧房子。人类没有因为"火会烧房子"就不用火了。我们干了一件事:给火加约束——灶台、烟囱、灭火器。有了约束,火就成了我们最离不开的工具。
电。能点亮城市,也能电死人。人类没有因为"电危险"就回到蜡烛时代。我们给电加了保险丝、绝缘层、安全标准。
AI的"编造"能力,就是新时代的火和电。
它危险吗?危险。但你把它的"编造"指向写诗、画设计草图、做头脑风暴——它就是创造力引擎。你把它的"编造"指向法律判例、医疗建议、财务数据——它就是谎话精。
关键从来不是"它会不会编"。问题是"你让它往哪个方向编"。
沃顿商学院教授Ethan Mollick对ChatGPT的评价可能是最精准的:"一个无所不知、急于取悦你的实习生——但有时候会骗你。"
你品品这个定位。实习生。能干,积极,想让你满意。但你不会把公司公章交给实习生。你不会让实习生替你在合同上签字。你也不会在实习生给了你一个数据之后,不加核实就报给董事会。
你会用他干活。然后你自己把关。
AI就是这个逻辑。它不是不能用——是不能"信"。
问题从来不是"它会编"。问题是——你不知道它什么时候在编。而且它编的时候,比说真话的时候还自信。

···
四、那怎么办?三条防身法则
好,你现在知道了三件事:①AI胡说不是bug,是出厂设置。②它编得越像真的越危险。③但会编,也是它有用的原因。
那么接下来:你该怎么用?
···
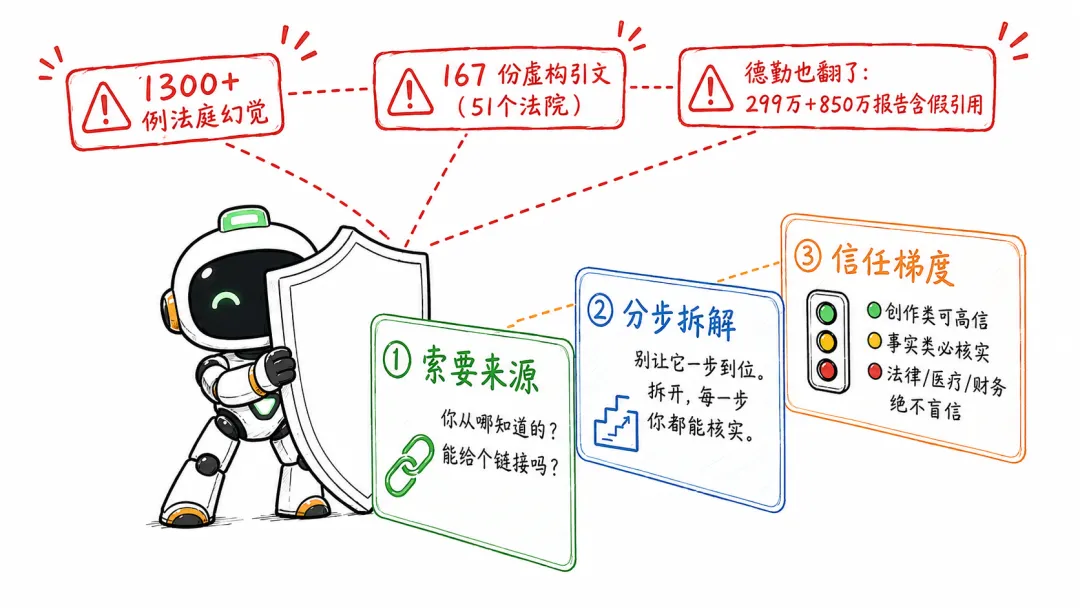
第一条:索要来源。
这是最简单也最有效的一招。每次AI告诉你一件事——尤其是事实类、数据类、引用类的信息——你就追一句:"你从哪知道的?能给个链接吗?"
如果它给不出来,或者给出来的链接打不开、对不上——你就知道它是在编。
这条法则背后有个更深的东西:AI不是"不想"告诉你真相。它是"没法"告诉你。它没有数据库,没有记忆,没有检索能力(除非连了搜索引擎)。你问它"从哪知道的",本质上是逼它暴露自己的信息结构——而它的"信息结构"是概率分布,不是事实列表。
它回答不了"从哪知道的",是因为它根本就没有"从哪"这个概念。
···
第二条:分步拆解,别让它一步到位。
有一个方法叫Chain-of-Thought——思维链。说起来高大上,做起来就是一句话:别让它一口气干完,拆开。
你不是问"AI,帮我做一份竞品分析报告"——然后拿到手就信了。
你是先让它"列出主要竞品",你自己看一眼,核实这些竞品确实存在。再让它"每个竞品找3个关键信息",你自己搜一下验证。再让它"根据这些信息写分析"。
每一步你都看得见,每一步你都能核实。让AI走在一条你铺好的路上,而不是你跟着它跑。
···
第三条:建立信任梯度。
不是所有AI回答都需要一视同仁地核实。你需要一个简单好记的分级:
创作/灵感类:可以高信。 让它写诗、编故事、做头脑风暴——这些不需要事实准确,只需要"合理的想象"。放心用。
事实/数据类:必须核实。 让它给数据、找论文、列参考资料——拿到后自己搜一遍。索要来源。
法律/医疗/财务类:绝不盲信。 涉及合同条款、医疗建议、投资决策——AI的输出最多当参考,最终决策必须由专业人士做。
同时记住这5个高危领域:法律引用、学术文献、财务数据、医学建议、人物生平。碰到这些话题,信任梯度自动下调一档。
···
说到这,给你看几个数字,它们会让上面这三条从"建议"变成"迫在眉睫"。
截至2026年4月,一个专门追踪AI幻觉的数据库已经记录了超过1300例法庭幻觉事件。1300例。这还只是"被发现的、在法庭上的"。那些没被发现、或者发生在其他场景的,有多少?
加拿大截至2026年6月,已有167份含AI幻觉虚构引文的法庭文件,涉及51个法院。51个法院。
连德勤这种顶级咨询公司都翻车了——在澳大利亚花了约299万人民币(44万澳元)写的报告里,引用了不存在的学术论文。一个月后,德勤在加拿大又翻了——850万人民币的报告里,至少4处虚假引用。
讲真,你不是"不小心"被骗。是这东西的骗术已经高到连德勤都防不住。
所以不是"要不要防"的问题。是"你现在开始防,已经不算早了"。
···
结尾:你知道了,就不一样了
回到开头那个律师,Steven Schwartz。
很多人看他的故事,第一反应是"这人怎么这么蠢?ChatGPT给的判例他竟然不核实?"
但说实话。如果你不知道AI是逐字预测的接龙高手,不知道它被训练来"猜"而非"查",不知道它会把真实人名和虚构论文缝在一起——你第一次拿到一份格式完美、引用规范、逻辑严密的法律意见书,你会去"核实"吗?
你大概率不会。
因为你以为它是搜出来的。你以为它跟百度一样。你以为"机器"天然等于"准确"。
但现在你知道了。
你知道它不是搜的,是编的。你知道它没有事实核查机制,只有一个偶尔失灵的良心开关。你知道它在最自信的时候反而最危险。
这些东西,你知道了,世界就不一样了。
AI不是"不能用的东西"。它是"不能信的东西"。
用他干活。关键的事,自己核实。
就从今天开始。打开你的AI工具——豆包也好,Kimi也好,ChatGPT也好——对它说一句:
"你从哪知道的?"
试一次。就一次。看看它是怎么回答的。
然后你会明白——这篇文章没白写。

