 夜雨聆风
夜雨聆风
Claude+DeepSeek几乎可以无限量使用Token的方式跑通之后,接下来的问题就是AI可以在什么场景下驱动律师工作。
周末我从数据库下载了金融领域所有公开可查的最高人民法院再审改判或者发回重审案件的判决书,让AI做统计和分析。步骤不复杂,我把下载到的一共175份判决书放在一个文件夹里,让AI逐一做了结构化提取——每份判决书拆出案号、裁判日期、案由、改判类型、核心争议标签、裁判规则、原审错误类型、改判结果等十几个字段,然后做了系统的统计分析。
这中间出了一次bug,AI默认用JSON+正则检索的方式来进行统计,而不基于对每份判决书的真实读取和理解来统计。因此我让AI重新对每份判决书进行逐一读取,做case brief,然后基于读取的理解来做统计。AI最最后形成的报告中,还把这个过程描述成了"人工"阅读。
类似的事情,我在疫情期间系统研究委托理财合同纠纷的事后做过,当时大概花了两周的时间通读所有的委托理财合同纠纷判决书并做统计。但这一次,通过AI,只花了大约3个小时+10元左右的token费用。在产出的成果中,尤其是AI自己提到的改判率和新法修订之间的关联,还是有些惊艳。
数据发现
以下是AI从175份判决书中提取出来的一些数据。需要说明的是,这些数据来自于金融行业的再审改判案件——主要是银行、保险、资产管理公司、信托公司等金融机构作为当事人的案件,案由集中在借款合同、金融借款、保证合同、保险合同、保理合同、票据纠纷等。统计结论对其他领域的参考价值有多大,需要进一步验证。
一、法律适用错误是"头号杀手"
175份改判判决书中:
法律适用错误(即原审法院对法律规则的理解或适用存在偏差)出现了155次,占比88.6%。
事实认定错误出现了74次,占比42.3%。
程序错误仅3次,几乎可以忽略。
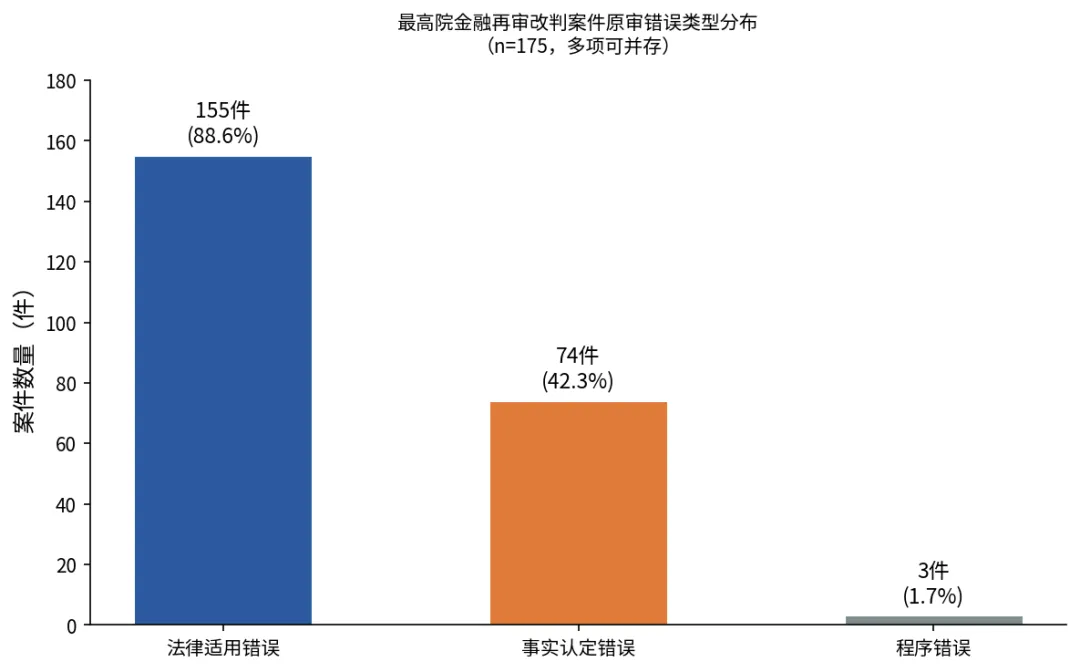 原审错误类型分布
原审错误类型分布
如果再细看错误类型的组合结构,纯法律适用错误(不涉及事实认定错误)的案件有100件,占57.1%。也就是说,过半数的改判不是因为原审事实没查清楚,而是规则适用出了偏差。事实认定与法律适用同时存在问题的案件有55件,占31.4%。纯事实认定错误(不涉及法律适用问题)仅有18件,占10.3%。
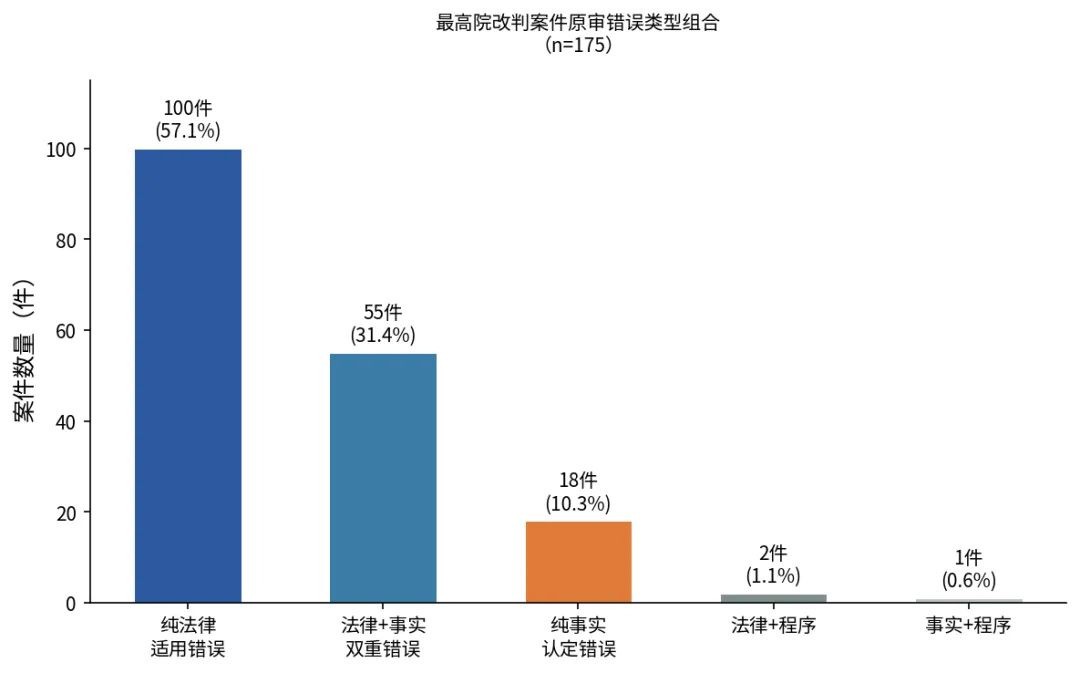 错误类型组合
错误类型组合
这个比例结构很有意思。很多律师在准备再审申请时,会把大量精力放在挖掘新证据或攻击事实认定上。但数据告诉我们,在金融案件中,最高院改判的核心驱动力是法律适用纠偏,而非事实纠错。
二、最高频的争议标签:利息、保证、合同效力
每份判决书我们都打了"核心争议标签"(一份判决书可以有多个标签),频率最高的几个是:
- 利息/违约金计算:132件(75.4%)
- 保证责任认定:107件(61.1%)
- 合同效力认定:101件(57.7%)
- 违约损害赔偿范围:64件(36.6%)
- 抵押登记效力:57件(32.6%)
- 刑民交叉:37件(21.1%)
- 不良债权转让:36件(20.6%)
- 最高额担保:36件(20.6%)
- 执行异议之诉:32件(18.3%)
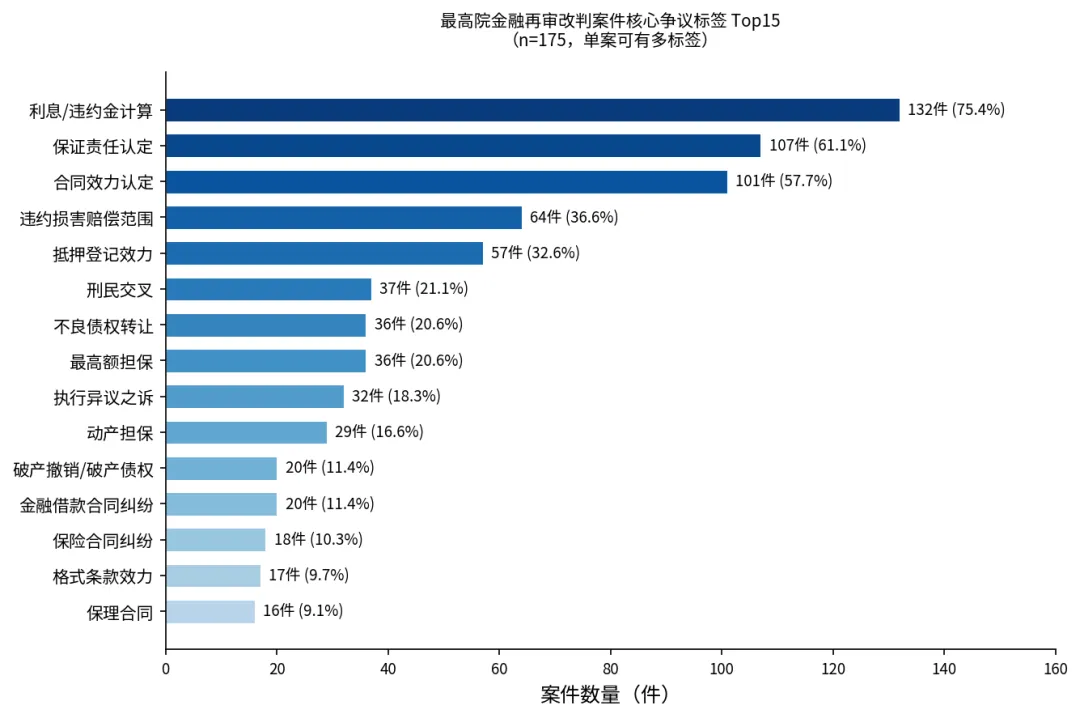 核心争议标签Top15
核心争议标签Top15
利息/违约金计算排第一,这恐怕不让人意外。利息计算涉及本金认定、计息起止时点、利率标准、复利是否支持、违约金是否过高、能否并用等多个层次的法律判断,实践中各地法院的掌握尺度差异很大。一个案子一审二审走下来,利息部分算错是再常见不过的事。
保证责任认定排第二,也符合直觉。保证合同的核心争议——保证方式是一般保证还是连带保证、保证期间是否经过、保证范围如何界定、主合同变更是否影响保证责任、公司对外担保的决议要求——每一项都有大量的下级规则和司法解释,稍有不慎就会出错。
合同效力认定排第三。有意思的是,这里的"合同效力"争议很多不是传统的"合同是否有效"的二元判断,而是更精细的问题:某一条款是否因违反强制性规定而无效、某一交易安排的性质认定(比如是买卖还是借贷、是保理还是借贷、是融资租赁还是借贷)、合同无效后的返还和赔偿范围等。
三、"部分改判"是常态,"全盘推翻"是少数
改判结果中:
- 部分撤销、部分维持:129件(73.7%)
- 撤销原判、直接改判:31件(17.7%)
- 撤销原判、发回重审:12件(6.9%)
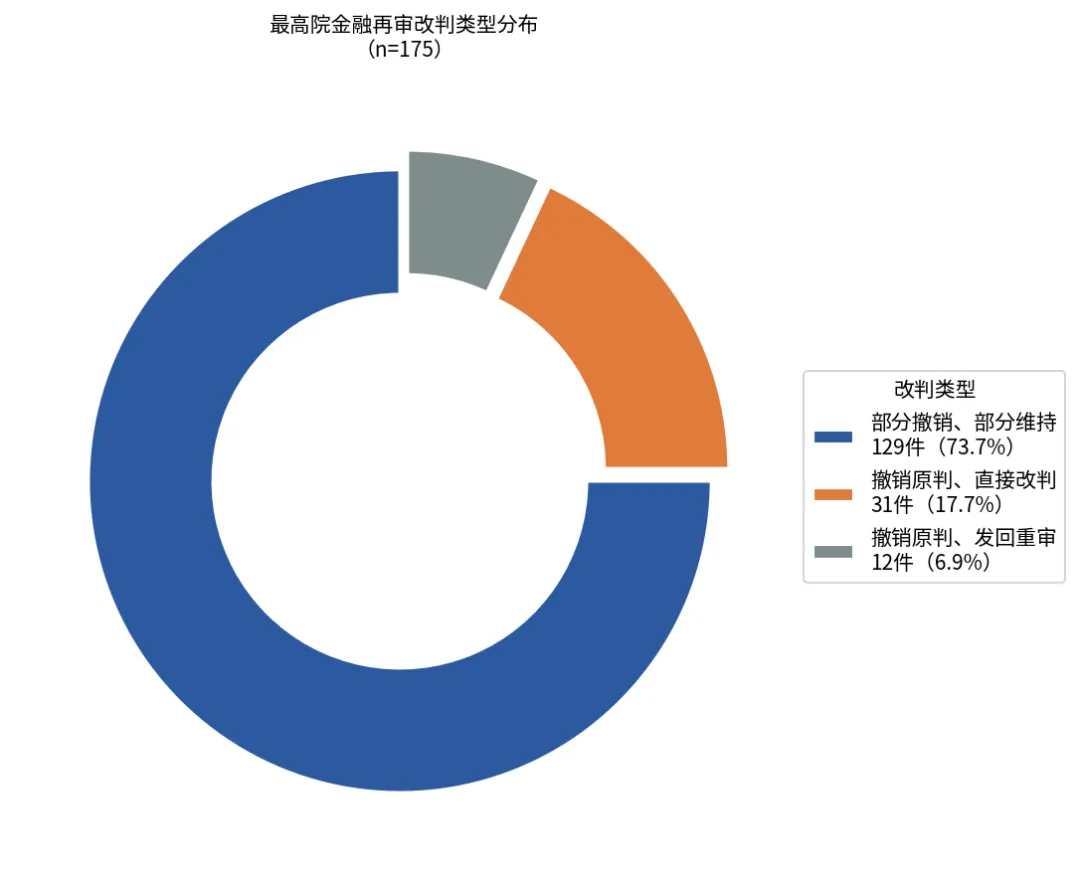 改判类型分布
改判类型分布
超过七成的改判是局部修正——最高院认可原审的基本判断,仅对其中某一部分(往往是利息/违约金计算、赔偿责任比例、保证责任范围等)进行调整。这说明原审法院在金融案件中"彻底翻车"的情况并不多,更常见的是在复杂规则的适用细节上出现偏差。
完全撤销原判、直接改判的31件(17.7%)才是真正意义上的"全盘翻案"。这31件案件的原审错误通常更为根本——比如法律关系定性错误(把保理认定为借贷、把融资租赁认定为借贷)、合同效力判断颠倒(有效判无效或无效判有效)、或者核心事实认定在证据层面缺乏支撑。
发回重审的12件(6.9%)比例很低,说明最高院更倾向于能自己改就自己改,不让案子再走一轮。
四、新证据极少——再审的博弈主要在"法律的战场"
175份判决书中,涉及新证据的仅有6件,占比3.4%。
这个数字本身就说明问题。绝大多数再审改判不是因为有"新发现"——不是因为找到了之前没有的证据推翻了原审——而是因为对既有事实的法律评价出了偏差。
换句话说,最高院再审改判的主战场不在事实,在法律。
这也意味着,再审申请书的写作策略应当有别于一审、二审的代理词。再审阶段的论述重心应该是"法律适用错误"——原审对某个法条的理解是否正确、对某个司法解释的适用是否恰当、对某个裁判规则是否存在误读——而不是"我们觉得原审事实认定不对"。后者很难在再审中扭转,除非有明显的证据采信错误(比如违反证据规则采信了不应采信的证据,或者遗漏了关键证据)。
五、启动方式:高度依赖当事人申请
175件案件全部由当事人申请再审或检察院抗诉启动。其中:
- 当事人申请再审→最高院裁定提审:167件(95.4%)
- 最高检抗诉:8件(4.6%)
法院依职权主动启动再审的比例为零。这当然不意味着法院从来没有主动纠错(我们的样本限于金融行业,可能有样本偏差),但至少说明了一个现实:在再审启动上,当事人和代理律师的主观能动性是决定性因素。不申请就不会有改判。
六、年份趋势:2017-2022年是高峰期
裁判年份分布呈现一个明显的"驼峰":
2010-2015年:每年6-13件,相对平稳 2016-2018年:从13件攀升至25件 2019年:短暂回落到9件 2020年:达到峰值26件 2021-2022年:18件、14件,逐步回落
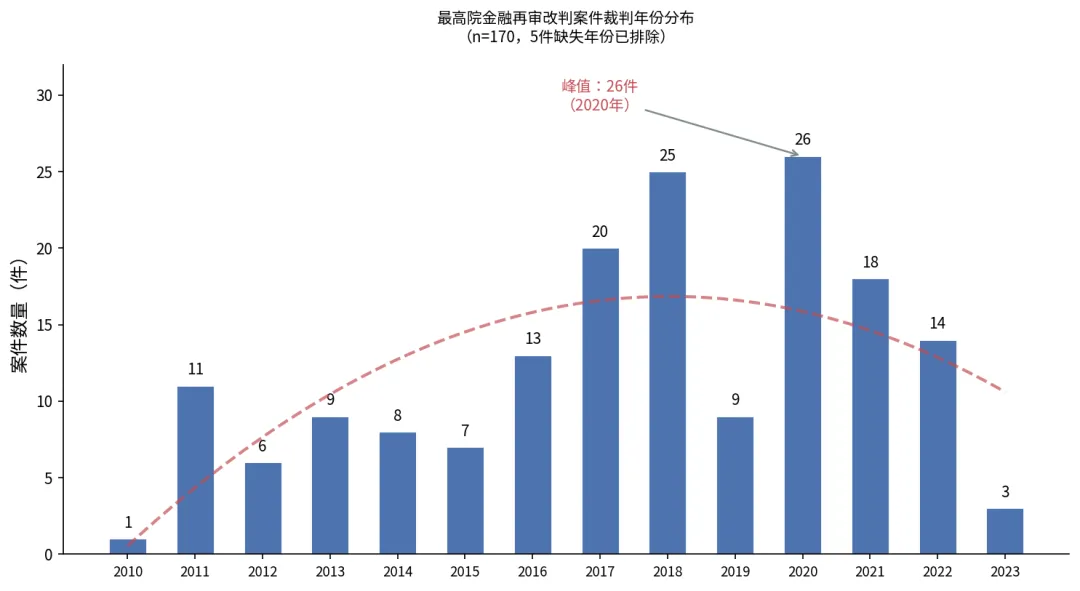 裁判年份趋势
裁判年份趋势
这个分布可能受多重因素影响。但有一个关联特别值得注意:改判高峰恰好与中国民事立法最密集的修法周期高度重合。
2017年10月,民法总则施行,这是民法典编纂的第一步,担保、合同、公司等金融案件核心领域的规则开始松动。2019年11月,九民纪要发布,对担保、公司对外担保决议效力、合同效力等大量实务争议做了大规模规则梳理。2020年5月民法典通过,2021年1月正式施行,同年配套的担保制度司法解释同步生效——这意味着在短短三四年内,金融案件适用的基础法律规则经历了一轮"推倒重建"式的更新。
数据的微观变化也印证了这个判断。最高额担保争议的占比从2010-2016年的14.5%,跳升到2017-2019年的33.3%——翻了一倍多,而2017-2019年恰好是九民纪要酝酿和起草的时期。抵押登记效力争议则从早期的27.3%攀升到2020-2022年的46.6%,这正是民法典引入物权变动"区分原则"(第215条)后,下级法院在实践中理解和适用的磨合期。
换句话说,每一次重大修法,都伴随着一轮"法律适用错误"的集中爆发。下级法院需要时间来消化新规则,而最高院则通过改判案件来确立新规则下的裁判标准——"驼峰"背后是制度转型的阵痛。
对律师而言,这意味着修法窗口期是发现和提出再审申请的战略机遇——当规则体系重构时,原审在新旧法衔接上的偏差,比平时更容易得到纠正。
七、争议标的:单案金额中位数2800万元
有明确争议金额的134件案件中,金额中位数为2800万元,平均值为5371万元。最大单案争议金额6.6亿元,最小仅10万元。
案件金额集中分布在1000万-5000万区间(73件,占54.5%),其次是5000万-1亿(18件)和1亿以上(15件)。
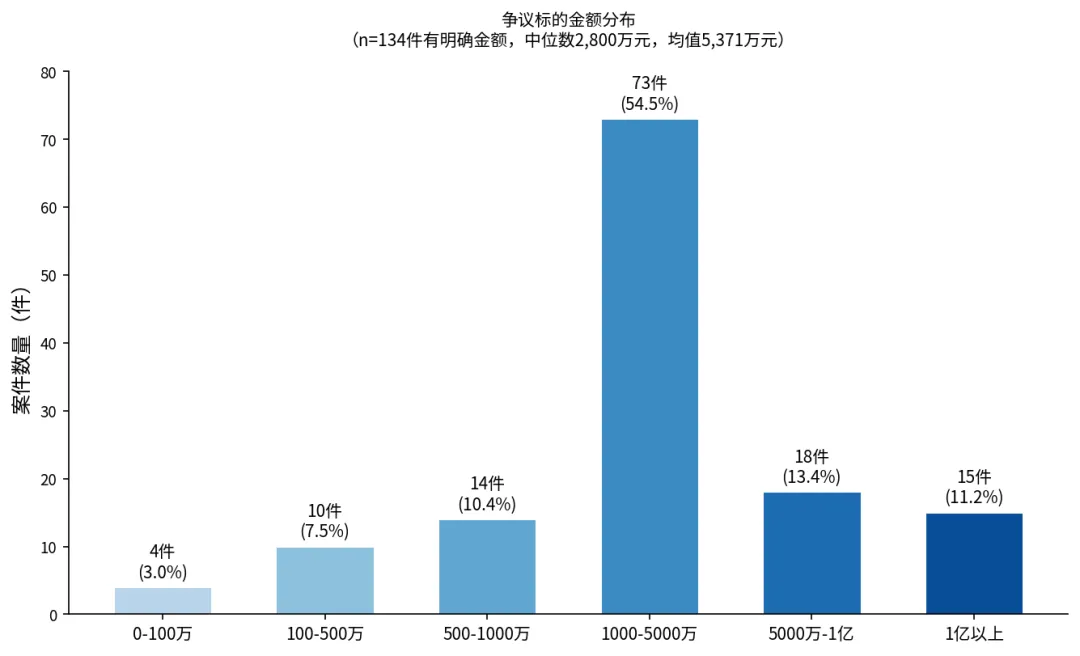 争议标的金额分布
争议标的金额分布
考虑到样本是最高院再审案件,这个金额分布是基本合理的——事实认定清楚、法律适用正确、金额又很低的案件,原告即便申请再审,最高院裁定提审的概率也相对较低(当然并不绝对)。
这些数据意味着什么
回到Lawyer.ai这个系列一直关心的问题:AI能驱动的类案研究到底长什么样?
传统的类案检索模式是:确定争议焦点→提炼关键词→在裁判文书网上搜→一篇一篇看→人工比对→写成备忘录。
这个模式有三个固有瓶颈。
第一个瓶颈是广度。一个资深律师靠自己的阅读量,一个争议焦点熟知的类案大概在10-20件的量级。这已经是很高的水平了。但中国裁判文书网的公开文书量以千万计,即便是最高院改判案件这个子集,也有大几百上千件。靠人力的阅读量只能覆盖极小一部分。
第二个瓶颈是结构化程度。传统模式下,即便搜到了相关案例,比对也是靠人工笔记——这个案子支持了什么观点、那个案子的关键事实有什么不同。比对到10件以上,人的注意力和记忆力就开始失效,难以发现跨案件的模式。
第三个瓶颈是趋势发现。单看一件改判案件,看到的是"这个案子在这个法律问题上错了"。看到10件,大概能总结出几个常见错误类型。但看到175件,就能发现错误类型的分布结构、不同年份的密度变化、哪类争议最容易导致改判——这些是趋势性的、统计性的知识,单案阅读永远无法建立。
这次研究之所以能做到175件的量级,不是因为我有超人的阅读能力,而是因为AI把"阅读一份判决书并提取结构化信息"这个基本动作的单位成本从1-2小时降到了几分钟。
成本降下来之后,很多以前"理论上可行、实际上做不了"的研究就变得值得做了。175份不够?做500份。金融行业之外呢?扩展到公司纠纷、房地产纠纷、知识产权纠纷。
当然,AI目前还不能替代律师做法律判断——它提取出来的裁判规则是原始形态的,需要律师进一步校对、验证、提炼。但它已经可以把最耗费时间的那部分工作——从海量文书中提取结构化的法律信息——做得足够快、足够好,使大规模的类案实证研究成为可能。
对了,这篇文章(包括文章里的图表)也是AI自己写了之后我微调的。除此之外,我还顺手让AI帮我为判决书中的每一位法官做了单独的信息页面,标注法官的案例链接,并联网检索法官的公开信息,一百多位法官花了不到半小时的时间就完成了。

如果喜欢本文,欢迎点赞、关注、收藏。
