 夜雨聆风
夜雨聆风一个扎心的现状
做技术的朋友应该都有过这种经历:
产品经理甩过来一份Word模板,说“以后每周按这个格式出报告”。你打开python-docx文档,翻了半天发现它连表格里插入图片都费劲。换成COM调Word吧,Windows上跑得挺好,一到Linux服务器直接歇菜——Office都没装,谈什么自动化?
Excel那边更热闹。openpyxl能写数据,但公式算不了;xlwings要装Excel;想生成个透视表?要么自己拼XML,要么劝产品“要不咱别要了”。
PPT?坦白说,能用python-pptx改个文字已经是福报了。
这不是某个库的错,而是这些库诞生的时代,根本没想过AI会以今天的方式介入办公流程。
三套旧方案,各有各的痛
第一类:纯Python读写库
代表:python-docx、openpyxl、python-pptx
优势:轻量、跨平台、不依赖Office
硬伤:
读写能力严重不对称。能写数据,但读回来就变味儿了——样式丢了、图表变图片了、公式变静态值了
格式覆盖残血。docx里但凡有个文本框、页眉里的表格、内容控件,python-docx基本当没看见。openpyxl想读个图表数据?抱歉,办不到
各自为政。三个库三个API,写Word是一种写法、写Excel是另一种,想统一封装一层,封装完发现比业务代码还长
真实场景:你让AI生成一份带图表的周报,python-docx写不了图表,openpyxl算不了公式,最后只能让AI生成数据、你用pandas处理、再用openpyxl填数、前端生成图表截图贴进来——一套操作下来,代码量能写满三屏。
第二类:COM/OLE自动化
代表:win32com、AppleScript
优势:能调用Office原生全部能力,要啥有啥
硬伤:
必须装Office。服务器上装Office?许可证怎么算?IT部门第一个不同意
Windows only。想跑在Linux CI/CD流水线上?别想了
慢得离谱。启动一个Word实例的耗时够跑一百次python-docx
不稳定。COM对象挂了,整个进程跟着殉葬,毫无优雅降级可言
真实场景:有人在Jenkins里挂了台Windows Agent专跑Office自动化,动不动就因为Office进程没杀掉把Agent搞崩了,每周重启一次,运维都快疯了。
第三类:LibreOffice无头模式
代表:soffice --headless
优势:免费、跨平台、支持读写多种格式
硬伤:
太重了。完整安装几百兆,依赖一堆系统库,Docker镜像直接胖两圈
转换链路长。想读内容?先转PDF或HTML,再解析——信息在转换中丢了一半
格式兼容有坑。复杂的.docx/.xlsx打开和MS Office有肉眼可见的差异,图表排版经常错位
真实场景:用LibreOffice把文档转HTML喂给AI,结果AI说“这份报告看不懂”——打开一看,表格全散了,公式变乱码了。
旧方案的共同盲区
这三类方案有一个共同的盲区:它们都不是为AI设计的。
AI智能体操作文档,需要的能力跟人操作文档完全不同:
AI需要什么 旧方案给不了什么
先“看懂”文档长什么样 只能读写数据,没有“渲染视图”能力
结构化元素定位(第3页第2个表格) 只有行/列/段落索引,改了内容索引就乱了
确定性JSON输出,便于function calling 各自有自己的对象模型,AI学起来费劲
反馈失败后可程序化重试 报错就是抛异常,智能体不知道怎么修
批量处理时不依赖GUI环境 COM依赖窗口句柄,LibreOffice依赖X11
简单说:旧方案是人操作Office的工具,不是AI操作Office的工具。
一个为AI重写的方案
OfficeCLI做的事其实很朴素:把Office文档操作重新定义为对AI友好的原语。
它不是某个Python库的替代品,而是在更高维度上解决了问题——把文档操作抽象成CLI命令 + JSON数据流。
核心理念:分层渐进
它的设计思路非常清醒——让AI从最安全的层级入手,逐步深入:
L1 视图层 → AI先"看"文档(输出文本/HTML/截图)
L2 DOM层 → AI按路径操作元素(增删改查)
L3 XML层 → 只有极端情况才触碰原始OOXML
这个设计的精妙之处在于:每一层的输出都是上一层的输入,但每一层都有独立的稳定抽象。 AI不需要一上来就理解XML命名空间,从L1看懂文档结构就够了。
元素寻址:路径即坐标
告别“第3段第2行”这种脆弱索引,改用稳定路径:
officecli pptx query "/slide[1]/shape[@name='title']"officecli docx query "/body/table[1]/row[2]/cell[1]"officecli xlsx query "/sheet[1]/cell[contains(@value,'总计')]"
路径是稳定的——你删了前面的段落,后面的元素路径不变。这对AI来说至关重要:AI只需要记住“目标元素的路径”,而不需要追踪“它现在挪到哪一行了”。
四大引擎,直击痛点
渲染引擎——让AI真正“看见”文档
多模态AI能看截图,但缺的就是“把文档转成截图”这一环。OfficeCLI把PowerPoint的渲染能力装进了二进制里:
officecli pptx view screenshot deck.pptx每一页生成一张PNG
officecli pptx view html deck.pptx生成独立HTML,无需Office
这意味着AI可以逐页“看”PPT的设计稿,然后精准定位要修改的元素——视觉理解和结构化操作终于打通了。
公式引擎——脱离Excel也能算
Excel自动化的最大痛点是:写进去的公式不会算。OfficeCLI内置了公式求值引擎,覆盖FILTER、UNIQUE、SORT、VLOOKUP、INDEX/MATCH等上百种函数:
officecli xlsx set data.xlsx "/sheet[1]/B2" --formula "=SUMIF(A:A,">100",B:B)"写入即求值,结果和公式都保留在文件里。不需要装Excel,不需要打开文件,公式自动算。更狠的是透视表也支持命令行生成:
officecli xlsx pivot data.xlsx --rows "产品" --values "销售额" --agg SUM以前写几十行pandas才能搞定的汇总分析,一条命令完事。模板合并——设计一次,生成N次
这是我觉得最实用的功能。流程极其简单:
第一步:用Word/Excel/PPT设计好版式(配色、排版、图表样式全定好)
第二步:把可变内容抽象成JSON数据结构
第三步:一条命令批量生成
officecli merge template.docx data.json --output report_*.docx占位符支持段落、表格单元格、形状文本、页眉页脚、图表标题。AI负责设计模板,CLI负责批量生产——这才是人和AI合理的分工方式。Dump往返——让AI学习你的排版
如果你有一份设计精美的参考文档,想让AI学会它的排版风格:
officecli docx dump template.docx --output structure.jsonAI分析JSON结构,理解排版规则
officecli docx batch structure.json --output new.docx
智能体通过结构化的JSON学习排版规范,而不是从OOXML的XML堆里大海捞针。
一张表看懂差距
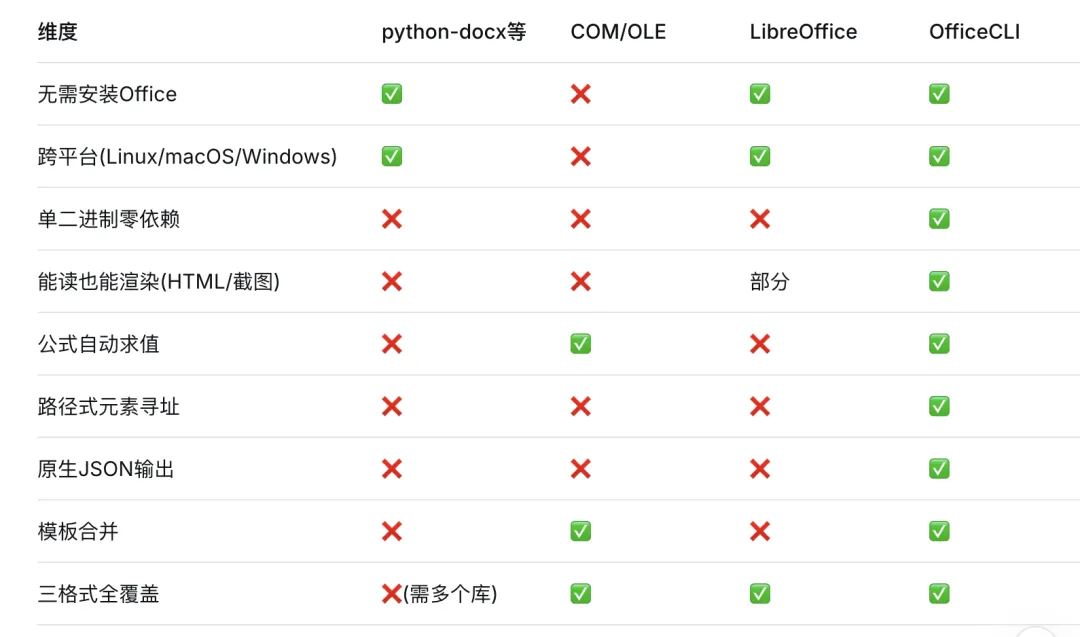
最打动我的是它在DevOps流水线里的表现。
以前:测试跑完 → JUnit XML → Python脚本解析 → 用python-docx写报告 → 样式全靠手写代码控制 → 格式调了三天
现在:AI设计好模板 → 测试跑完 → JSON数据输出 → officecli merge template.docx results.json → 报告自动生成
一行命令替代了三百行胶水代码。
同样的流程用在:数据库导出生成Excel周报、JIRA数据自动生成PPT项目复盘、合同信息批量填充Word模板……凡是“模板+数据=文档”的场景,都能套用。
谁说工具不能重新定义工作流
OfficeCLI最值得关注的地方,不是它“能做什么”,而是它重新思考了“AI应该如何与Office文档交互”这个命题。
它不是在一个旧框架里打补丁,而是提出了新的框架:
AI需要看见文档 → 它内置渲染引擎
AI需要定位元素 → 它引入路径寻址
AI需要结构化反馈 → 它统一输出JSON
AI需要批量生产 → 它设计模板合并
每个功能背后,都是一个对AI工作流的深度理解。
安装很简单,一个二进制搞定:
curl -fsSLhttps://officecli.ai/install.sh| bash
它不挑语言——Python、Node、Go、Shell,任何能调CLI的环境都能用。这意味着你可以把它嵌入任何AI智能体、任何自动化平台、任何CI流水线。
官网:https://officecli.ai
GitHub:https://github.com/iOfficeAI/OfficeCLI
题外话:这工具目前只支持OOXML格式(.docx/.xlsx/.pptx),旧版.doc/.xls需要先转换。
另外CLI操作对不熟悉命令行的朋友有点门槛——但它面向的主要是开发者和AI智能体,这个取舍可以理解。
