 夜雨聆风
夜雨聆风





【发布】基于瑞芯微RKNPU的边缘AI推理软件SL_RKCPP开发包

背景简介
Rockchip RK3588作为专为边缘场景打造的高性能SoC,其集成的NPU提供约6 TOPS的推理算力,具备高并行计算能力与良好能效比。
RK3588的软件生态以RKNN-Toolkit / RKNN-Toolkit2与对应的runtime为核心,提供模型转换、离线性能评估与设备端运行时接口,便于将通用模型部署到Rockchip NPU。
原生SDK虽提供了硬件底层接口,但开发者仍需手动维护复杂的张量内存对齐、显存映射及模型生命周期,且输入输出的编解码逻辑繁琐。课题组针对RKNN推理流水线开发了高性能适配层,通过RAII机制与零拷贝技术屏蔽了底层资源调度的复杂性。该框架实现了预处理与推理逻辑的深度解耦,显著降低了边缘AI应用的开发门槛与部署成本。
原生推理流程概况
根据瑞芯微RKNPU接口文档[1],通过RKNN调用瑞芯微RKNPU的原生推理端到端流程如下图所示:
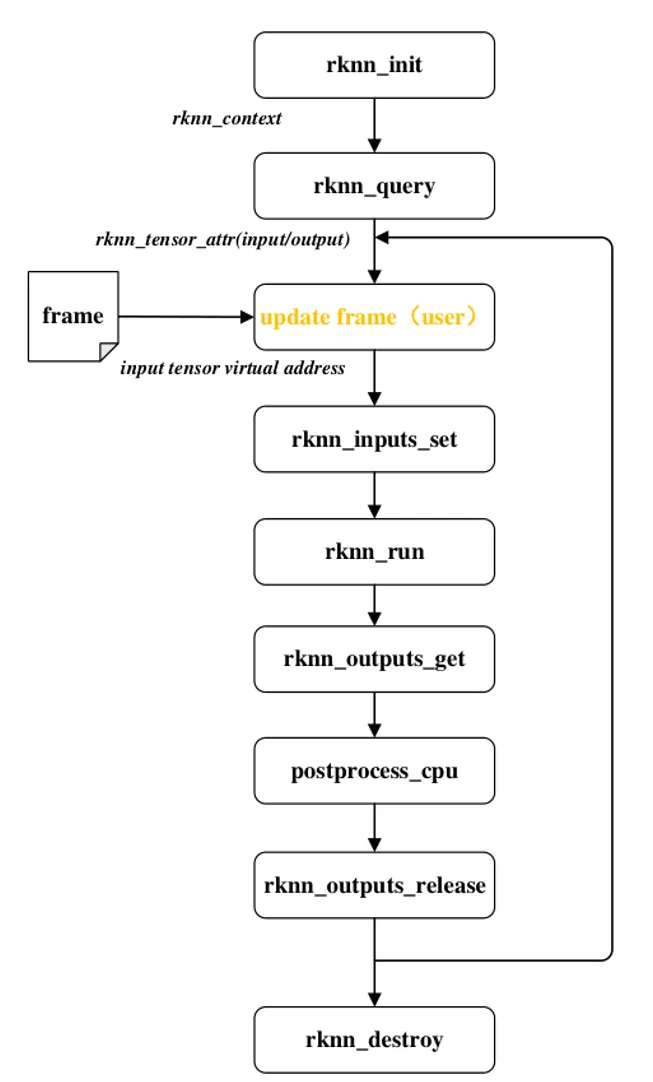
图1 基于原生推理框架AI模型端到端推理流程完整示意图
根据RKNPU2指令集与API标准规范,瑞芯微NPU的原生推理流程可抽象为以下四个关键阶段:
-
模型初始化与资源预分配
-
系统初始化:调用rknn_init()接口加载.rknn模型文件,完成NPU硬件资源分配及Context环境创建。
-
属性查询:通过rknn_query()接口获取模型输入/输出张量(Tensor)的属性信息(如维度、格式、量化参数等),为后续缓冲区配置提供依据。
-
数据准备与搬运
-
前处理阶段:针对原始输入数据进行格式转换、等比例缩放或归一化等操作,使其符合模型输入规范。
-
输入映射:调用rknn_inputs_set()接口,将预处理后的数据由主机内存(Host)设置/拷贝至NPU设备内存(Device)。
-
并行推理执行
-
算力调度:调用rknn_run()核心接口,驱动NPU硬件执行算子并行计算,完成特征提取与张量推理。
-
结果检索与资源释放
-
结果获取:调用rknn_outputs_get()接口检索推理生成的原始Tensor数据。
-
后处理逻辑:对原始输出进行解析(如NMS过滤、坐标转换等),将推理结果转化为业务层可识别的结构化信息。
-
生命周期销毁:推理任务结束后,依次调用rknn_outputs_release()释放推理缓冲区,并调用rknn_destroy()销毁RKNN句柄,确保系统资源的安全性与完整性。
封装方案
基于RKNN原生推理流程,课题组利用C++ RAII机制与模板编程特性,构建了针对RK3588 NPU的分层适配框架,如图2所示。
底层资源管控层(RknnContext):封装了rknn_init与rknn_destroy等系统调用,通过环境上下文的生命周期管理,确保了NPU硬件资源的申请与释放安全性,避免了句柄泄露。
通用模型抽象层(RknnModel):深度封装了rknn_tensor_attr及rknn_input/output系列C接口,统一管理RKNN硬件对齐内存(Memory Alignment)与张量映射。该层屏蔽了复杂的显存偏移计算与底层结构体填充细节,实现了硬件交互逻辑与特定模型业务的完全解耦。
标准化推理流水线(InferencePipeline):基于模板方法定义了“模型加载 → 零拷贝Buffer配置 → 图像预处理 → 同步/异步推理 → 张量后处理”的标准生命周期。通过封装OpenCV图像处理算子,将硬件相关的格式转换(如RGB/NV12互转)集成至预处理逻辑,并提供虚函数接口用于自定义检测框解码等算法逻辑。
用户仅需通过继承机制实现特定模型的前处理和后处理业务逻辑,即可完成高效部署。该封装不仅实现了算法与RK3588底层驱动的深度解耦,更通过零拷贝技术优化了数据搬运效率,提升了代码的复用性与边缘端推理的稳定性。
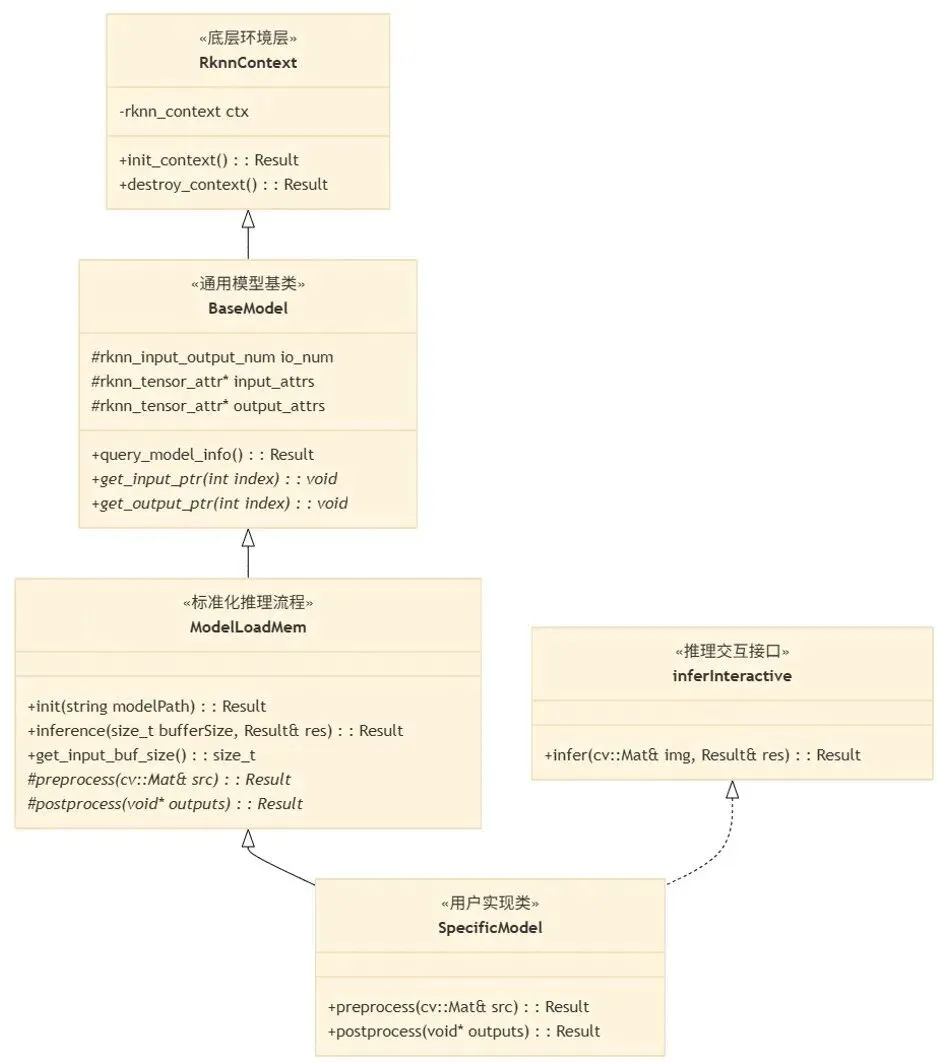
图2 SL_RKCPP SDK框架
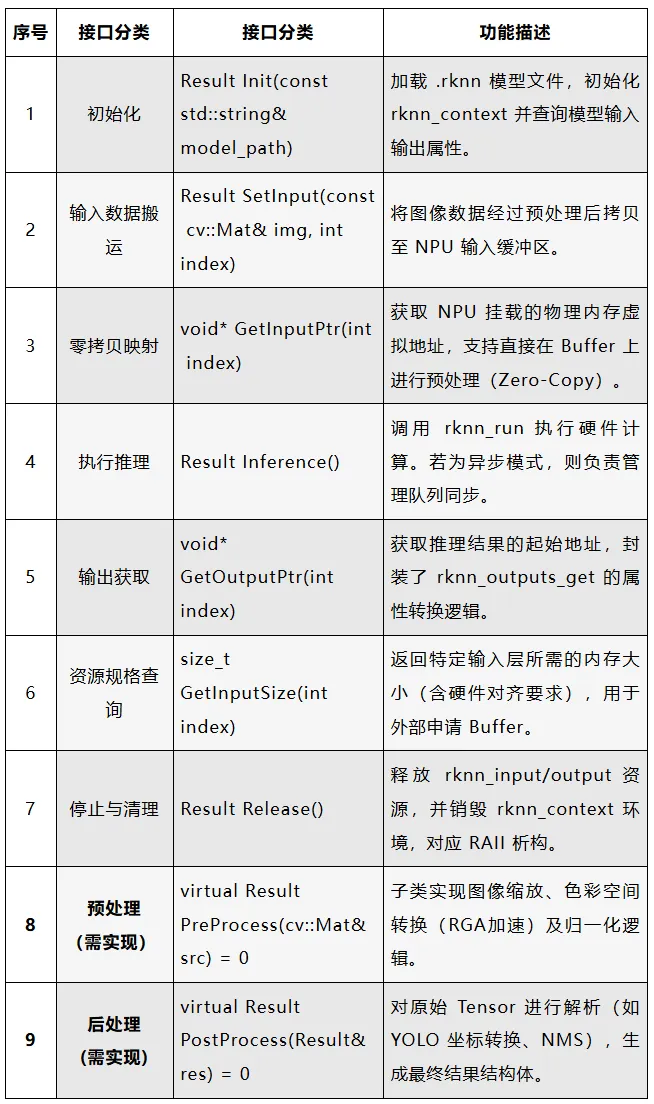
SL_RKCPP SDK基于交叉编译工具链构建,其接口的具体定义如下:
效果展示
SDK中提供了针对RK3588平台的目标检测示例,用于展示如何基于课题组封装的推理框架开发边缘 AI 应用。
如图3所示,具体模型类(如Yolov5)直观体现了封装化开发的优势:利用原生 RKNN SDK 开发需开发者手动管理 rknn_context 句柄、处理复杂的张量内存对齐(Tensor Alignment)、配置显存映射(Memory Mapping)以及处理设备端与主机端的同步细节;
而利用本开发框架,开发者仅需聚焦于预处理(如图像缩放、RGA 硬件加速配置)与后处理算法逻辑(如检测框解析、NMS 参数调优)。底层硬件操控逻辑及资源生命周期全部由父类 ModelLoadMem 与 BaseModel 封装承接,实现了零拷贝(Zero-Copy)数据流的标准化管理。
这种封装将开发重心从“如何适配底层硬件驱动”转移到“如何优化业务数据流”,大幅降低了在RK3588平台下部署各类深度学习模型的门槛,也为其他CV任务在RKNN架构下的高性能适配提供了可复用的参考范式。

图3 利用SL-RKCPP框架开发YOLOv5应用示例
为验证封装接口的有效性与性能,基于RK3588搭建测试平台,测试环境与检测结果如下所示:


图4 YOLOv5应用实时检测结果
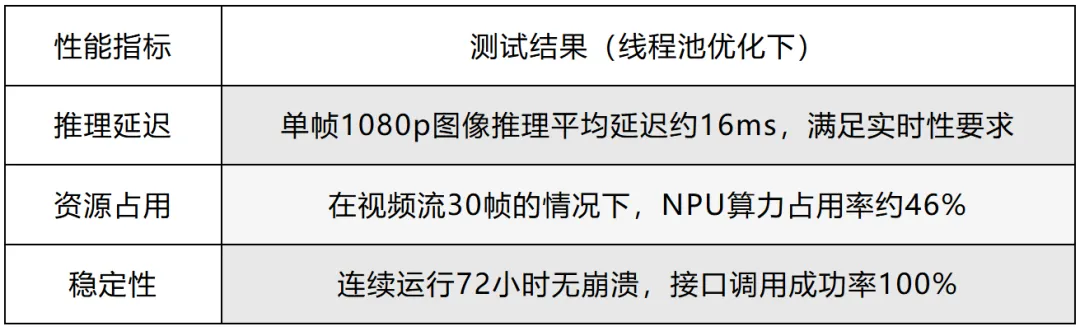
测试结果表明,封装后的接口可充分发挥瑞芯微RKNPU的硬件性能,同时具备低延迟、高稳定的特点,可直接应用于实际项目开发。
总结
基于瑞芯微 RK3588 NPU 架构的推理开发框架,通过RAII资源管理与分层封装设计,深度屏蔽了底层 rknn_context 维护及张量内存对齐等硬件交互细节。该框架凭借标准化的推理流水线与零拷贝(Zero-Copy)技术配合RGA硬件加速预处理(可选 OpenCV 兼容模式),大幅降低了边缘AI应用的开发与部署门槛。
本文以YOLOv5目标检测模型为例,验证了该框架在1080p图像检测处理场景下,能够实现显著的低延迟推理,并支持72小时以上的工业级稳定运行。该封装方案为边缘侧智能计算任务的快速落地提供了高效、可靠且易于维护的技术支撑。
欢迎联系spark-lab获取本开发包。
参考文献
[1]瑞芯微电子股份有限公司. Rockchip_RKNPU_User_Guide_RKNN_SDK_V2.3.2_CN [EB/OL]. https://github.com/airockchip/rknn-toolkit2/blob/master/doc/04_Rockchip_RKNPU_API_Reference_RKNNRT_V2.3.2_CN.pdf, 访问日期 [2026.2.20]
声明:版权归原作者所有。如需转载请联系我们。
ABOUT
东南大学Spark Lab课题组聚焦边缘人工智能,做“可落地”科研,使能百模千态,助力千行万业。
交流&合作:sparklab@qq.com
