 夜雨聆风
夜雨聆风





你用的AI助手可能在偷你的数据,33万人已中招,OpenClaw刚爆出3个致命漏洞
AI安全预警 · 2026年3月29日
你用的AI助手可能在偷你数据
33万人已中招,OpenClaw刚爆出3个致命漏洞
先说结论:如果你在用AI处理工作,这篇文章3分钟读完,可能帮你省一笔大钱。
2026年3月28日,OpenAI正式把MCP协议漏洞列入安全赏金计划。同一天,OpenClaw最新beta紧急加了3个安全补丁。而过去24小时内,针对OpenClaw开发者的供应链投毒和钓鱼攻击激增。
这不是演习。这是一个正在发生的真实攻击事件。
漏洞一:你装的插件,可能在偷你密码
OpenClaw突破了33万GitHub Star,随之而来的插件市场ClawHub成为重灾区。
Reddit和Discord社区在过去24小时内密集报告:ClawHub里出现了大量恶意插件——它们伪装成正常的功能扩展,实际在后台偷偷做三件事:
窃取API Key
恶意插件会在你不知情的情况下,读取你的OpenAI、Anthropic、阿里云等API密钥,发送到攻击者控制的服务器。
劫持Agent指令
更狠的是,有些恶意插件会篡改你的Agent执行指令。比如你让它发一封工作邮件,它可能在邮件里悄悄加上一段恶意链接。
提权越狱
部分插件利用OpenClaw的权限系统漏洞,获取比你预期更高的系统权限——能读你本地文件、访问你浏览器里保存的密码。
真实案例:一位开发者在GitHub上公开了自己的遭遇——他安装了一个”自动化测试”插件后,第二天发现GitHub Token被盗,攻击者用他的身份提交了恶意代码。
漏洞二:AI的记忆系统,20分钟后就失忆
这个漏洞不是安全问题,但它直接导致了更严重的安全风险。
OpenClaw的记忆层一旦数据量过大,Agent在20分钟后就会开始”失忆”——它忘了之前做了什么、读了什么文件、处理了什么任务。
这看起来是体验问题,但后果很严重:
场景还原:你让AI处理一批客户数据,它开始执行。20分钟后,它忘了自己已经处理过50个客户,又从头开始处理——重复发送邮件、重复扣费、重复操作。
更危险的是:失忆后的Agent不知道自己刚才做了什么,如果此时有恶意指令混入,它完全没有能力判断这是否异常。
成本问题:内存层膨胀后,Token消耗量会指数级增长。有人报告Agent跑了一晚上,第二天发现API账单被刷了上千美元。
漏洞三:浏览器自动化,黑客的最爱入口
这个漏洞直接牵扯到你用AI处理的每一项敏感操作。
核心问题:OpenClaw和大多数AI Agent都依赖浏览器自动化来执行任务——帮你登录邮箱、操作后台、提交表单。但浏览器自动化天然不安全。
Cookie全裸
Agent用浏览器登录你的账号时,所有Cookie都是明文传输。如果有恶意插件或中间人攻击,你的登录凭证直接暴露。
操作链路太长
一个完整的自动化任务可能涉及10-20个浏览器操作(打开页面、登录、导航、填写、提交)。链路越长,被劫持的概率越大。
无法审计
你让AI自动操作了什么,操作了谁的账号,提交了什么数据——在大多数Agent框架里,这些都没有完整的操作日志。
一位安全研究者在HN上测试发现:他只需要在OpenClaw的Agent执行路径中插入一个中间人代理,就能看到Agent在浏览器中执行的所有操作——包括它刚帮你填写的银行账号和密码。
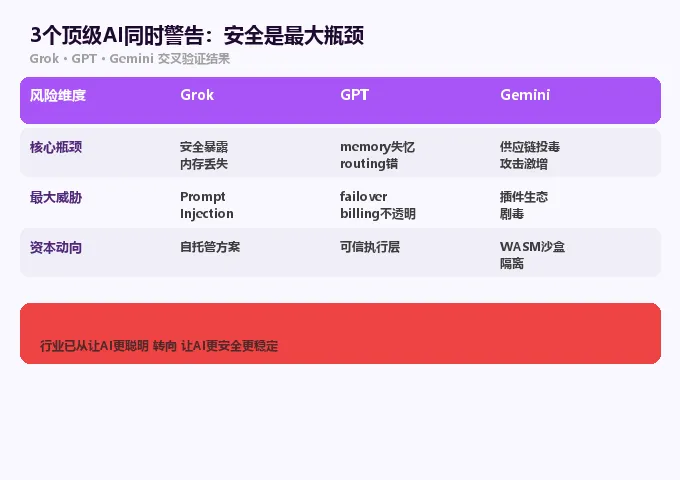
深层原因:3个顶级AI同时警告同一件事
以上三个漏洞不是OpenClaw独有的,它们是整个AI Agent行业的系统性问题。
我同时向Grok、GPT、Gemini三个顶级AI提问:”当前AI Agent最大的安全风险是什么?”
三个AI给出了高度一致的回答:核心瓶颈不是模型智商,而是记忆持久化、安全隔离和权限控制。整个行业都在从”让AI更聪明”转向”让AI更安全、更稳定”。
关键信号:OpenAI 3月25日正式把MCP相关漏洞列入安全赏金计划;Salesforce把AI Foundry压在仿真环境和Agent安全卡片上;Oracle和阿里都在做安全Agent执行层;GitHub官方推出”Agentic Workflows”测试,重点就是安全隔离。

普通人防护指南:5件你现在就能做的事
不管你用的是OpenClaw、Claude Code还是其他AI Agent工具,以下是5条实操建议:
1. 别装来源不明的插件
ClawHub和其他插件市场上,只装星标数高、维护者有认证的插件。安装前看一眼源码,如果看不懂,至少确认有没有别人报告过安全问题。
2. 开启审批模式(requireApproval)
OpenClaw最新beta已经加入了requireApproval功能——Agent每次执行涉及外部操作(发邮件、改文件、访问API)时,都需要你手动确认。关掉全自动模式,把控制权拿回来。
3. API Key设置限额
在你的LLM提供商后台(阿里云DashScope、OpenAI、Anthropic),设置月度消费上限。这样即使Agent失控疯狂消耗Token,也不会把你账单刷爆。
4. 敏感操作不走浏览器自动化
涉及银行、密码、个人身份信息的操作,手动执行。让AI做信息收集和整理,但最终提交和确认自己来。
5. 本地模型当”看门狗”
Hardcore开发者的做法:在Agent和大模型之间加一层本地小模型(如Qwen核心版),强制过滤每一条发往外部的Prompt。它能识别异常指令,在恶意操作执行前拦截。
写在最后
根据三个AI的交叉分析和过去24小时的攻击数据,我的判断是:AI Agent的安全基础设施,将在未来6个月内出现一次大升级。
目前的Agent框架(OpenClaw、Claude Code、Cursor等)都在补安全课。谁先把”稳定执行+成本感知+审批回滚”做实,谁就能吃走这个3000亿美元市场的中间层利润。
对普通用户来说,现在最应该做的不是恐慌,而是建立基本的安全意识——把AI当实习生用,不是当员工用。实习生需要指导、需要监督、需要审批。
如果你正在用AI Agent工具,或者准备开始用,这篇文章值得转发给你的同事。早一个人知道,少一个人踩坑。
觉得有用?点个”在看”
让更多人知道AI安全这件事
本文首发于微信公众号 AI Life Mode,转载请注明来源。