 夜雨聆风
夜雨聆风





当你的 AI 编程助手开始“脑抽”:四大框架深度拆解与生存指南
做过大项目的兄弟们都知道,跟 AI 助手玩“计划并执行”那一套,初期爽歪歪,后期火葬场。核心问题在于:当计划在第三步崩盘时,你的框架是带你飞,还是带你入坑?
如果你在过去半年里深度用过 Claude Code、Cursor 或 Codex 搞过正经项目,你一定遇见过这个名场面:AI 脑子挺好使,但一旦上下文撑到 80K token 左右,它就开始“间歇性失忆”。它会忘掉之前的决策、悄悄缩减需求范围,甚至把你一小时前刚写的函数重新发明一遍。
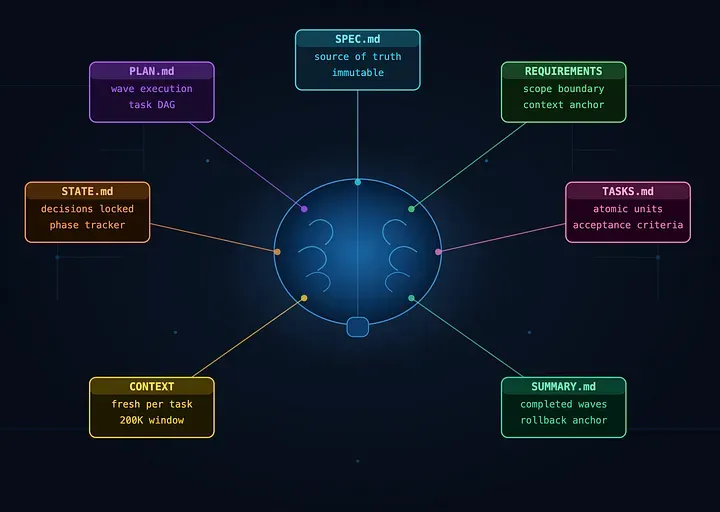
这病在圈子里叫 “上下文腐烂”(Context Rot)。为了治这个病,2025 年涌现了六大派系:BMAD、Spec Kit、SPARC、Prompt-Driven Dev、Context Engineering 和 GSD (Get Shit Done)。
虽然它们都贴着“规格驱动开发”(Spec-driven dev)的标签,但我们要看透本质:当计划赶不上变化时,这个框架到底在干嘛?
本文将硬核对比四个主流框架:BMAD、Spec Kit、GSD 和 Superpowers。它们不挑食,不管是 Claude、GPT 还是 Gemini,不管是 Cursor 还是命令行 CLI,都能跑。我们将聊聊在“边跑边改”的 MVP 项目中,谁是真大腿,谁是绣花枕头。
一、 核心病灶:上下文腐烂的“尸检报告”
在拆解框架前,我们要明白为什么即便有 200K 的大窗户,LLM 还是会“侧漏”:
-
**注意力稀释 (Attention Dilution)**:Transformer 架构虽然号称雨露均沾,但注意力是稀缺资源。上下文越长,每个决策分到的注意力就越薄。最后,关键决策变成了噪音。 -
**决策漂移 (Decision Drift)**:开头说好“咱们用 React”,那是圣旨。120K token 之后,这个决定就成了淹没在几百行废话里的碎纸屑。AI 写新文件时,可能转头就给你撸了一段原生 JS。 -
**需求侵蚀 (Scope Erosion)**:初期 10 个需求,AI 跑着跑着就觉得其中 3 个已经写完了,2 个不重要。当它告诉你“搞定”时,其实只完成了 70%——而你可能两天后才发现。
二、 四大框架排排坐:谁才是你的菜?
|
|
|
|
|
|---|---|---|---|
| BMAD |
|
|
|
| Spec Kit |
|
|
|
| GSD |
|
|
|
| Superpowers |
|
|
|
1. BMAD Method:角色扮演深度玩家
BMAD 走的是“人多好办事”路线。它的逻辑很简单:既然项目是由不同角色推进的,那我就给 AI 安排不同的马甲。
-
全家桶角色:分析师、PM、架构师、敏捷教练、开发、QA、UX。 -
优点:专业。每个角色都有标准模板(PRD、架构文档),一股浓浓的 500 强企业味儿。 -
槽点:太重了! 我就想写个 side-project,你让我先跟 7 个特种兵开会?而且一旦底层架构要改,你得从分析师开始重新走一遍流程,极其死板。
2. Spec Kit:文档即真理
GitHub 官方出品,态度极度强硬:代码是暂时的,文档(Spec)才是永恒的。
-
工作流: /specify(干啥)→/plan(咋干)→/tasks(分工)→/implement(搬砖)。 -
优点:极其严谨。它有个“宪法”文档(memory/constitution.md),不符合宪法的代码一律不准过。 -
槽点:线性思维。一旦你要改需求,得像推倒多米诺骨牌一样重来。且容易出现上下文腐烂。
3. GSD:上下文工程的暴力美学
GSD 不跟你聊角色,它只关心一件事:如何让 AI 在写每一行代码时,脑子都是清醒的?
-
黑科技:波次执行(Wave Execution)。它把任务拆成一个有向无环图(DAG),没依赖的任务直接开几个“干净”的新窗口并行跑。 -
优点:上下文隔离极好。 每个小任务都只带着最相关的几个文件启动,彻底根治“脑抽”。而且它的 XML 任务格式非常适合机器读取,容错率极高。 -
槽点:学习曲线略陡,那一堆 .planning/文件夹里的状态文件偶尔需要人工对齐。
4. Superpowers:代码洁癖者的福音
它不关注项目怎么规划,它只关注:你怎么敢不写测试就写代码?
-
绝活:强行 TDD。 测试不红,不许写逻辑。它还会自动开 Git Worktree,每个任务都在独立的树枝上跑,互不干扰。 -
优点:工程纪律拉满。自带“苏格拉底式提问”,在你动手前先问得你怀疑人生,防止无脑开搞。 -
槽点:不管宏观。它没有 Roadmap,没有里程碑。如果你没个大计划,它就是个“局部战神”。
三、 终极大考:计划崩盘了怎么办?
假设你做到第三步发现:完了,数据库设计错了,得支持多租户。
-
BMAD:分析师重新调研,架构师重改文档,全员重新开会。耗时:3 小时。 -
Spec Kit:改 spec.md,重跑 plan,重跑 tasks。耗时:1 小时 + 复杂的 Git 合并。 -
GSD:更新 STATE.md,只针对受影响的模块重跑“讨论”和“计划”。新旧代码通过波次隔离。耗时:20 分钟 + 丝滑回滚。 -
Superpowers:它不管你全局崩不崩,它只负责给你的新需求开个新 Worktree,继续敲测试。耗时:5 分钟(但全局影响得你自己看)。
四、 暴论:GSD + Superpowers 才是完全体
我个人的实践结论是:大人才做选择,高手直接混搭。
GSD 负责“宏观调控”(管计划、管波次、管上下文隔离),而 Superpowers 负责“微观操作”(管测试、管 Git 规范、管 Code Review)。
顶级组合拳流程:
-
用 GSD 初始化项目,画好 DAG 任务图。 -
进入执行阶段,GSD 派发一个任务。 -
Superpowers 接管这个任务:开独立 Worktree → 写测试 → 写代码 → AI 互评。 -
任务完成后,GSD 进行全量验证。
总结:
-
小脚本:直接用 Superpowers,快准狠。 -
中型 MVP:用 GSD,抗住需求变更。 -
硬核大活:GSD 坐镇指挥部,Superpowers 深入前线搬砖。
在这个 AI 编程的战国时代,选对框架不只是为了提效,更是为了在项目上下文爆炸的那一刻,你还能优雅地喝杯咖啡,而不是对着屏幕骂 AI 是智障。