 夜雨聆风
夜雨聆风





OpenDataLoader PDF:AI 时代最好用的 PDF 解析器,从入门到精通
最近在做一个 RAG 项目的时候,我被 PDF 解析这事儿狠狠折磨了一把。
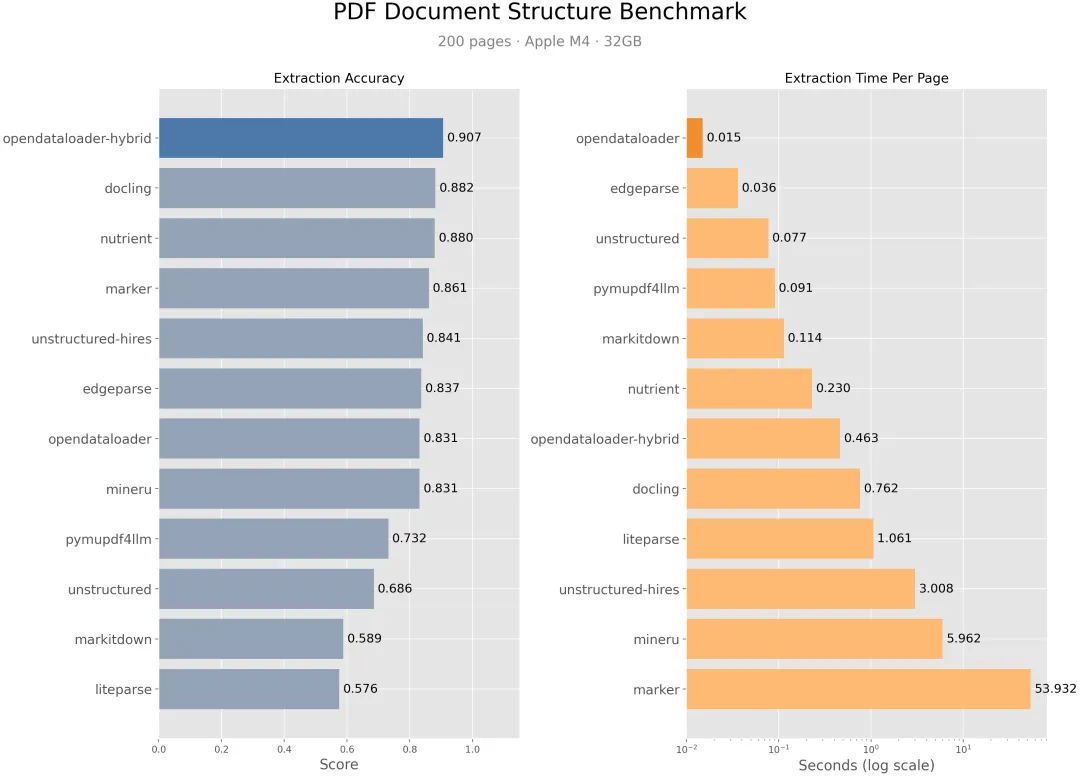
你可能也遇到过同样的问题:PDF 里的表格被拆成散乱的文本、多栏排版读出来顺序全错、扫描件的图片里文字直接丢失。试了一圈工具,最后在Github发现了 OpenDataLoader PDF —— 一个在 benchmarks 里排第一的开源 PDF 解析器。
今天就来详细讲讲这个工具怎么用,以及为什么它值得你试试。
它是什么
一句话概括:OpenDataLoader PDF 是一个开源的 PDF 数据提取工具,能把 PDF 转成 Markdown、JSON(带 bounding boxes)、HTML 等格式,专门为 AI 和 RAG 场景设计。

几个关键标签:
-
开源:Apache 2.0 协议,商用自由 -
快:本地模式 0.015 秒/页,CPU 就能跑 -
准:混合模式下综合准确率 0.907,benchmark 第一 -
多语言 SDK:Python、Node.js、Java 都有 -
隐私安全:数据完全不离开本地
为什么要用它
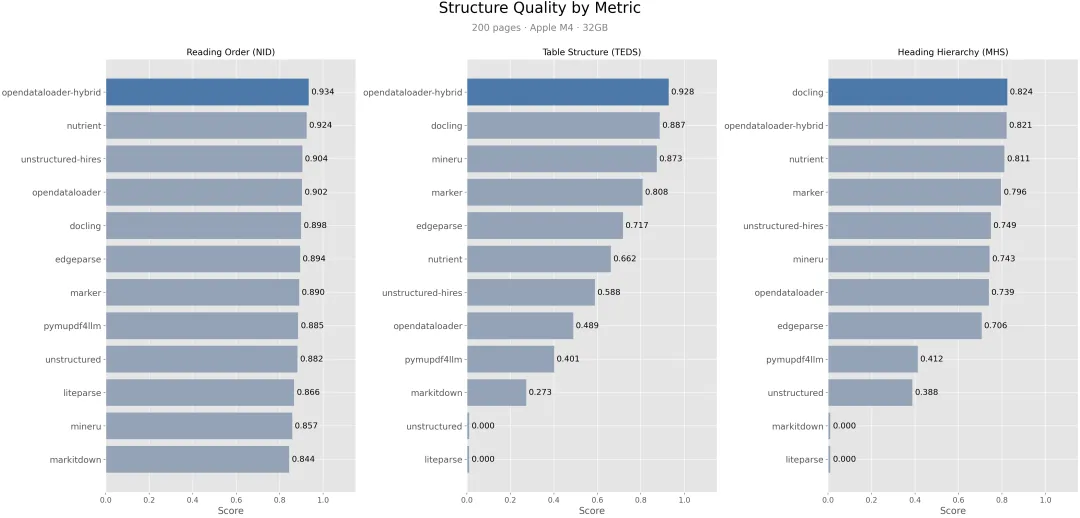
市面上 PDF 解析工具不少,但各有短板。PyMuPDF 快但表格识别差(准确率 0.401),Marker 准但慢得离谱(53.9 秒/页),Unstructured 连表格都抽不出来(0.000)。
OpenDataLoader 的核心思路是”两条腿走路”:
本地模式用确定性算法(XY-Cut++ 阅读顺序、边框分析、文本聚类),速度快、结果可复现。
混合模式遇到复杂页面(无边界表格、扫描件、数学公式、图表)自动路由到 AI 后端,准确率从 0.489 飙升到 0.928。
而且混合模式的 AI 后端也是本地部署的,你的文件不会传到任何云端。
安装
第一步,确认你装了 Java 11+:
java -version如果没有,去 Adoptium 装一个。
然后一条命令安装:
pip install -U opendataloader-pdf就这么简单。底层会自动打包一个 JAR 文件,Python 通过子进程调用 Java,你不需要关心这些细节。
30 秒上手
import opendataloader_pdfopendataloader_pdf.convert( input_path=["report.pdf", "paper.pdf"], output_dir="output/", format="markdown,json")三个参数:输入文件路径(支持单文件、多文件、文件夹)、输出目录、输出格式。运行完你会在 output/ 目录下拿到 .md 和 .json 两个文件。
注意一个重要的性能细节:尽量把文件打包在一次 convert() 调用里处理,因为每次调用都会启动一个 JVM 进程,频繁调用的开销不小。
命令行用法也一样直观:
opendataloader-pdf file1.pdf file2.pdf folder/ -o output/ -f json,markdown输出格式详解
Markdown
最常用于 RAG 场景。输出干净的 Markdown 文本,标题层级、表格结构、列表都保留。直接喂给 LLM 或者做 semantic chunking 都很合适。
JSON(带 bounding boxes)
这是 OpenDataLoader 的杀手级功能。每个元素都有精确的坐标信息:
{"type": "heading","id": 42,"level": "Title","page number": 1,"bounding box": [72.0, 700.0, 540.0, 730.0],"heading level": 1,"font": "Helvetica-Bold","font size": 24.0,"content": "Introduction"}bounding box 是 [左, 下, 右, 上] 的坐标,单位是 PDF point(72pt = 1 英寸)。
这个功能在 RAG 里非常实用 —— 当你的模型返回答案时,可以通过 bounding box 反向定位到原文的具体位置,实现”点击查看来源”的效果。目前没有其他开源解析器能做到每个元素都有坐标。
JSON 里能识别的元素类型包括:
-
heading:标题(自动判断层级) -
paragraph:段落 -
table:表格(含行列结构、跨行跨列信息) -
list:列表(有序、无序、嵌套) -
image:图片 -
caption:图片/表格说明 -
formula:数学公式 -
header/footer:页眉页脚
其他格式
-
HTML:适合网页展示,带样式 -
Text:纯文本 -
Annotated PDF:在 PDF 上画出检测到的结构框,调试用
可以组合输出:format="json,markdown,pdf"
混合模式:对付复杂文档的杀手锏
如果你处理的 PDF 包含以下情况,需要开启混合模式:
-
没有边框的复杂表格 -
扫描件(图片型 PDF) -
数学公式 -
需要描述的图表
启动混合模式
分两步。先装扩展包:
pip install "opendataloader-pdf[hybrid]"然后开两个终端。
终端 1 启动 AI 后端:
opendataloader-pdf-hybrid --port 5002终端 2 处理文件:
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdfPython API 里写法:
opendataloader_pdf.convert( input_path=["complex_report.pdf"], output_dir="output/", hybrid="docling-fast")简单页面依然走本地(0.02 秒/页),只有被判定为复杂的页面才走 AI。一分钟内就能处理完的文档,混合模式可能花几分钟,但准确率从 0.489 提升到 0.928,这个 tradeoff 是值得的。
OCR:扫描件的文字提取
对于扫描件(无法选中文本的 PDF),后端加 --force-ocr 参数:
opendataloader-pdf-hybrid --port 5002 --force-ocr非英语文档指定语言:
# 中日韩混合opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ko,zh,en"支持的语言包括英语、韩语、日语、简体中文、繁体中文、德语、法语、阿拉伯语等 80+ 种。
公式提取(LaTeX)
科学论文里经常有数学公式,混合模式可以把它们提取成 LaTeX:
# 服务端开启公式增强opendataloader-pdf-hybrid --enrich-formula客户端需要加 --hybrid-mode full(这个坑我踩过,不加的话公式提取会被静默跳过):
opendataloader-pdf --hybrid docling-fast --hybrid-mode full paper.pdf输出示例:
{"type": "formula","page number": 1,"bounding box": [226.2, 144.7, 377.1, 168.7],"content": "\\frac{f(x+h) - f(x)}{h}"}图表描述
AI 会给图表生成文字描述,对 RAG 搜索和无障碍访问(alt text)都有用:
opendataloader-pdf-hybrid --enrich-picture-descriptionopendataloader-pdf --hybrid docling-fast --hybrid-mode full report.pdf这里用的是 SmolVLM(256M 参数)这个轻量级视觉模型,不需要 GPU。
实战场景
场景一:RAG 知识库搭建
这应该是这个项目最常见的用途了。
import opendataloader_pdf# 批量处理整个文档目录opendataloader_pdf.convert( input_path=["docs/papers/", "docs/reports/"], output_dir="output/", format="markdown")拿到 Markdown 之后,配合 LangChain 的 RecursiveCharacterTextSplitter 或者按标题切割,就能得到结构化的 chunk。
LangChain 也有官方集成:
pip install -U langchain-opendataloader-pdffrom langchain_opendataloader_pdf import OpenDataLoaderPDFLoaderloader = OpenDataLoaderPDFLoader( file_path=["doc1.pdf", "doc2.pdf"], format="text")documents = loader.load()如果你需要来源定位(比如回答用户时标注”出自第 3 页第 2 段”),用 JSON 格式输出,通过 bounding box 和 page number 反向映射。
场景二:复杂论文/研报解析
学术论文、行业研报通常有多栏排版、跨页表格、数学公式。这时候混合模式就是必需品:
opendataloader_pdf.convert( input_path=["research_paper.pdf"], output_dir="output/", format="json,markdown", hybrid="docling-fast", use_struct_tree=True# 如果 PDF 本身带结构标签)表格检测方法也可以切换(默认是 default 边框检测,复杂表格用 cluster 聚类检测):
opendataloader_pdf.convert( input_path=["financial_report.pdf"], output_dir="output/", format="json", hybrid="docling-fast", table_method="cluster")场景三:批量处理 + 数据清洗
公司要把几百份历史 PDF 合同数字化,需要批量处理并过滤掉页眉页脚:
opendataloader_pdf.convert( input_path=["contracts/"], output_dir="output/", format="json", include_header_footer=False# 排除页眉页脚)如果 PDF 包含敏感信息(邮箱、手机号、URL),开启数据清洗:
opendataloader-pdf contracts/ --sanitize会把敏感信息替换成占位符。
场景四:指定页面范围
只需要处理特定页面:
opendataloader_pdf.convert( input_path=["big_report.pdf"], output_dir="output/", pages="1,3,5-7"# 处理第 1、3、5 到 7 页)场景五:图片处理
图片可以输出为外部文件或嵌入到 JSON 中:
# 外部文件模式(默认)opendataloader_pdf.convert( input_path=["magazine.pdf"], output_dir="output/", image_output="external", # 提取为独立图片文件 image_format="jpeg"# 或 "png")# 嵌入模式(Base64 data URI)opendataloader_pdf.convert( input_path=["magazine.pdf"], output_dir="output/", image_output="embedded")# 不需要图片opendataloader_pdf.convert( input_path=["magazine.pdf"], output_dir="output/", image_output="off")Node.js 用法
前端或 Node 项目里的用法几乎一样:
npm install @opendataloader/pdfimport { convert } from'@opendataloader/pdf';await convert(['file1.pdf', 'file2.pdf'], { outputDir: 'output/', format: 'markdown,json', hybrid: 'docling-fast'});Java 原生用法
如果你本身就是 Java 项目:
<dependency><groupId>org.opendataloader</groupId><artifactId>opendataloader-pdf-core</artifactId></dependency>进阶配置
页分隔符
Markdown 输出里默认页面之间没有分隔。如果你想按页面切割:
opendataloader_pdf.convert( input_path=["book.pdf"], output_dir="output/", format="markdown", markdown_page_separator="\n\n--- Page %page-number% ---\n\n")保留原始换行
默认情况下连续换行会被合并。如果需要保留原始换行:
opendataloader_pdf.convert( input_path=["legal_doc.pdf"], output_dir="output/", keep_line_breaks=True)密码保护的 PDF
opendataloader_pdf.convert( input_path=["encrypted.pdf"], output_dir="output/", password="your_password")AI 安全:Prompt Injection 防护
这个功能很多人不知道。PDF 里可以藏”隐形文字”(透明字体、零号字体、页面外内容),用来做 prompt injection 攻击。
OpenDataLoader 默认会过滤这些隐藏内容。如果需要关闭过滤器(比如你确实需要提取隐藏文本):
opendataloader-pdf file.pdf --content-safety-off all性能调优
本地模式下,内部用 ForkJoinPool 按页并行处理。在一台 8 核机器上批量处理时,吞吐量可以超过 100 页/秒。
几个建议:
-
批量调用:一次 convert()处理多个文件,避免反复启动 JVM -
简单文档用本地模式:普通数字 PDF 不需要混合模式,0.015 秒/页 -
复杂文档开混合:表格、扫描件、公式再走混合模式 -
多进程并行:大批量时可以起多个进程同时处理不同文件
和同类工具的对比
|
|
|
|
|
|
|---|---|---|---|---|
| OpenDataLoader [混合] | 0.907 | 0.928 |
|
|
|
|
|
|
0.015s/页 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OpenDataLoader 的优势在于:bounding boxes、AI 安全防护、混合模式、确定性输出。Docling 也很强,但没有坐标信息和安全过滤。Marker 准确率高但速度慢了 1000 倍。
未来方向:PDF 无障碍自动化
这个项目还有一个很厉害的方向 —— 自动给未标记的 PDF 添加结构标签(Auto-tagging),生成 Tagged PDF。这是为了满足各国的无障碍法规(欧盟 EAA、美国 ADA/Section 508 等)。
目前手动修复一份 PDF 的无障碍要花 50-200 美元,这个项目打算用开源方案自动化整个流程,计划 2026 年 Q2 开放。更进一步的 PDF/UA 转换是企业版功能。
总结
OpenDataLoader PDF 是我用过最省心的 PDF 解析器。核心原因:
-
安装简单,三条命令搞定 -
本地模式快得离谱,CPU 就够了 -
混合模式准确率高,且 AI 后端也是本地部署 -
JSON 输出带 bounding boxes,做 RAG 来源定位非常方便 -
开源,Apache 2.0,商用无忧
如果你也在为 PDF 解析头疼,不论是 RAG 项目还是数据提取需求,都值得一试。