 夜雨聆风
夜雨聆风





花了2天,我做了一个AI测试用例去重工具,从此告别半天的手工整理
敏捷迭代中,用例库越来越臃肿?相似用例重复执行? 一个基于语义分析的小工具,帮你自动识别重复用例。
一个真实的痛点
在敏捷迭代中,每个版本都会新增大量测试用例。 时间一长,用例库就变成了这样:
-
同一个功能,有多条描述不同但测点完全相同的用例 -
回归测试时,花大量时间执行重复的用例 -
定期整理用例库,每次要花半天甚至一天人工去重
我以前的做法是:每两个月手动整理一次,一条条看,一条条比对。 眼睛看花,效率极低,还容易漏。
能不能让AI自动帮我找出重复的用例?
解决方案:一个AI去重小工具
我花了两天时间,基于 Embedding + sentence-transformers 做了一个Web工具。 界面长这样: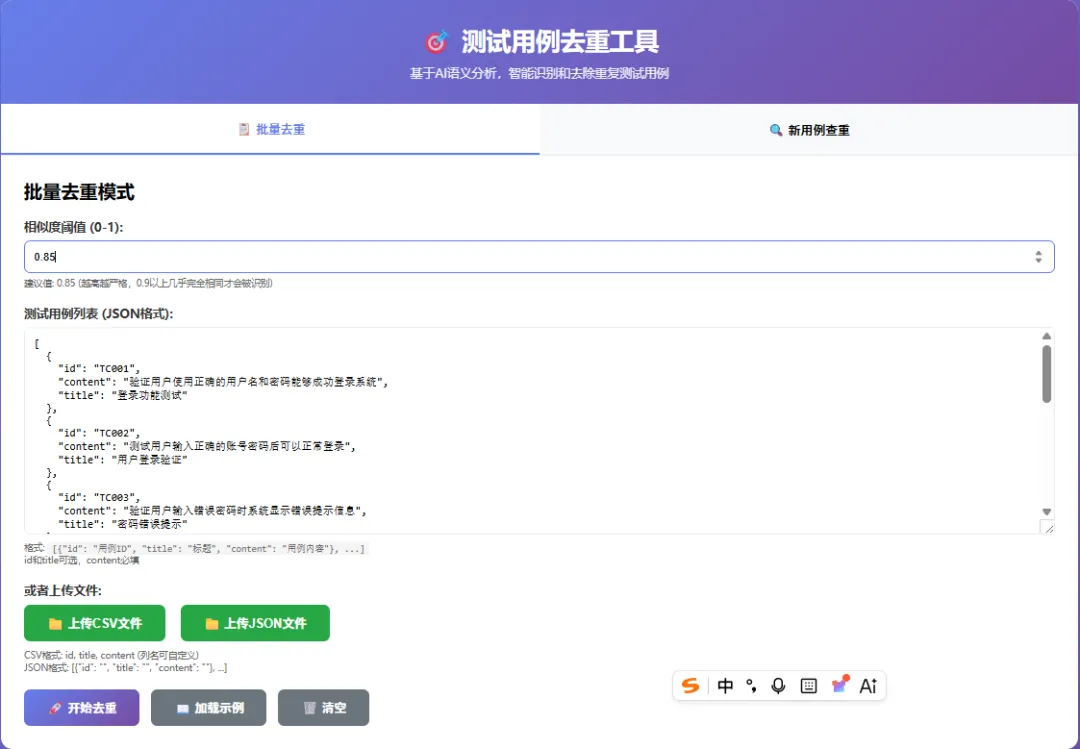
批量去重模式 + 相似度阈值调节
核心能力:
-
自动计算两条用例的语义相似度(不是字面匹配) -
支持批量去重:一次处理整个用例库 -
支持新用例查重:写新用例前先查一下,避免重复添加
核心功能详解
批量去重模式
场景: 定期优化用例库,清理历史积累的重复用例。
操作:
-
设置相似度阈值(推荐0.85) -
上传用例库(JSON或CSV格式) -
一键去重
输出:
-
原始用例数量 -
保留的用例(去重后) -
移除的重复用例列表,附带相似度分数
示例:
输入两条用例:
{"id": "TC001","content": "验证用户使用正确的用户名和密码能够成功登录系统"},{"id": "TC002","content": "测试用户输入正确的账号密码后可以正常登录"}工具计算出的相似度:92.5% → 判定为重复,建议保留其中一条。
新用例查重模式
场景:编写新用例时,检查是否与现有用例库重复。
操作:
-
输入新用例(JSON格式) -
输入现有用例库 -
点击查重
输出:
-
是否发现重复 -
最高相似度百分比 -
所有相似用例的详情
这样,新同学在写用例时就能实时避免重复,从源头控制用例库质量。
技术原理(通俗版)
这个工具的核心是 Embedding(嵌入向量)。
简单说:把每一条测试用例的文字,转换成一串数字(向量)。 语义越相似的用例,它们的向量在空间里离得越近。
然后,工具计算两条用例向量的余弦相似度,得到一个0-1之间的分数。 分数越高,表示越相似。
你可以在界面上调节相似度阈值:
· 0.85:推荐值,能识别出大部分语义重复的用例 · 0.90以上:非常严格,几乎完全相同才会被标记 · 0.80以下:较宽松,会找出更多“可能相关”的用例
底层使用的是开源模型 paraphrase-multilingual-MiniLM-L12-v2,完美支持中英文,而且可以本地运行,不用联网。
如何使用这个工具?
环境要求
-
Python 3.8+ -
首次运行会自动下载模型(约500MB)
快速启动(Windows)
# 1. 下载代码(已上传GitHub,链接见文末)# 2. 双击 start.bat# 3. 浏览器打开 http://localhost:8000手动启动
pip install -r requirements.txtpython main.py用例格式(JSON示例)
[ {"id": "TC001","title": "登录功能测试","content": "验证用户使用正确的用户名和密码能够成功登录系统" }, {"id": "TC002","title": "用户登录验证","content": "测试用户输入正确的账号密码后可以正常登录" }]content字段必填,id和title可选。content实际上就是我们用例的测试步骤,这里我当时忘记改了
实际效果
我用自己以前项目的500条用例做了测试:
-
原本人工整理需要3小时 -
工具处理耗时不到1分钟 -
识别出37组重复/高度相似用例,其中12组是我之前人工漏掉的
效率提升肉眼可见。
未来我还想加的功能
-
支持Excel/CSV文件直接导入导出 -
接入数据库,实现用例库的增量去重 -
支持更多相似度算法(如BM25 + 向量混合检索) -
一键生成去重报告(PDF/Word)
写在最后
这个工具我已经开源在GitHub上
如果你也是测试同行,正被用例库膨胀困扰,欢迎下载使用。 如果你觉得有用,也欢迎点个⭐Star,或者转发给需要的朋友。 关注我,一起用AI重新武装测试人的技能树。当然也欢迎大家加我,一起交流学习。