Hermes Agent:它不是又一个 AI 编程助手,它想当你的"Agent 操作系统"
大多数 AI Agent 产品还停留在”会聊天 + 会调几个工具”。任务一复杂记忆就断,流程一拉长能力就散,换个入口又像失忆重开。Hermes Agent 想解决的,不是”回答得更像人”,而是——能不能像一个长期在线、持续变强的代理人一样工作。
一、先搞清楚:Hermes 到底是个什么东西?
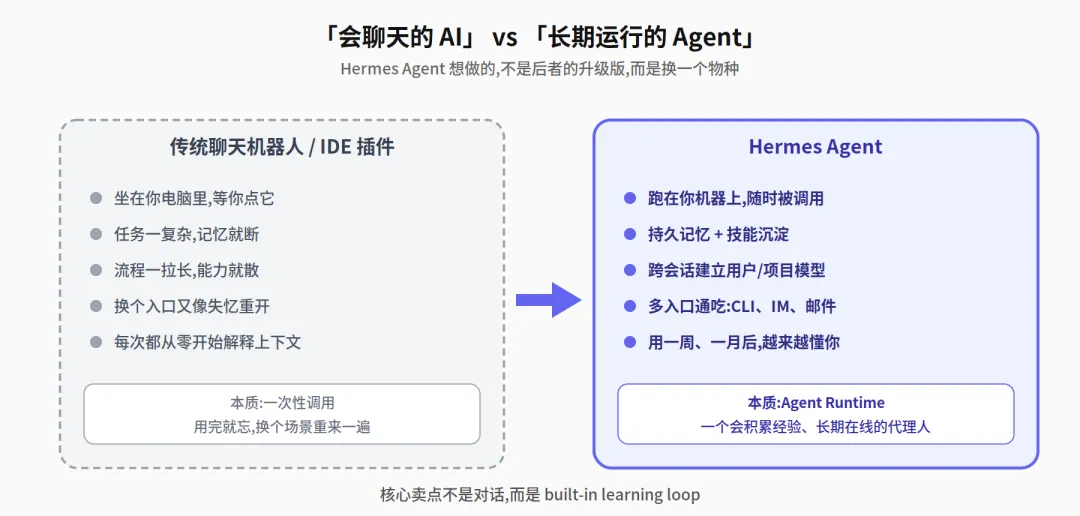
Hermes Agent 不是 IDE 里的一颗 AI 按钮,也不是又一个套壳聊天机器人。它更像一个长期运行的 Agent Runtime。
它既可以在 CLI 里工作,也可以通过单独的 gateway 进 Telegram、Discord、Slack、WhatsApp、Signal、邮箱、飞书、企微、钉钉、微信甚至 QQ 等入口持续提供服务。换句话说,它天然不是”坐在你电脑里等你点它”,而是”跑在你的机器或服务器上,随时被调用“。
按照 Nous Research 的官方定位,它的核心卖点不是对话,而是built-in learning loop——在使用中沉淀技能、推动记忆持久化、搜索过往会话,并跨会话建立越来越完整的用户与项目模型。
二、它凭什么不靠一段神 prompt 就能干活?
Hermes 真正有意思的地方,在于它不是把能力堆在一起,而是把能力分层了。
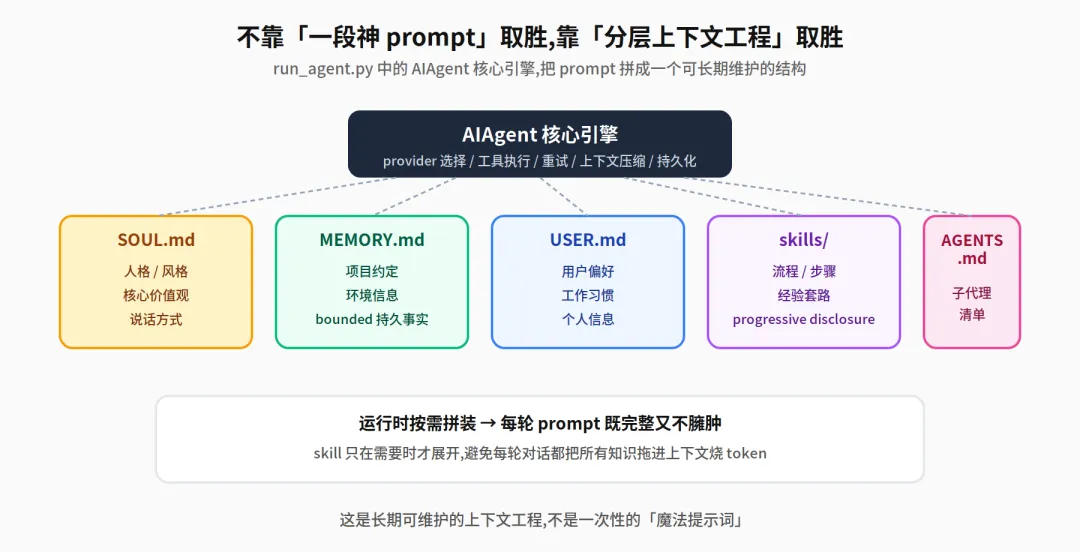
官方架构里,核心引擎是 run_agent.py 中的 AIAgent,负责 provider 选择、prompt 构建、工具执行、重试、fallback、上下文压缩和持久化。它的 prompt 也不是一段大杂烩的系统提示词,而是由 SOUL.md、MEMORY.md、USER.md、skills、AGENTS.md 这类上下文文件,以及工具使用指导等分层拼装起来。
Hermes 不是靠”单次神 prompt”取胜,而是靠”长期可维护的上下文工程”取胜。
你今天调好一句 prompt 的那种”爽感”,在 Hermes 里会被换成另一种更慢、但更稳的东西——一个可以被团队持续打磨、持续复用的上下文结构。
三、Memory 和 Skills 到底有什么区别?
很多人第一次看 Hermes,会被 memory 和 skills 这两个概念绕住。其实它们分工非常清楚:
Memory 存的是事实
——用户偏好、项目约定、环境信息。内置的持久记忆由 MEMORY.md 和 USER.md 两部分组成,而且有边界,不是无限膨胀的大仓库。
Skills 存的是做事方法
官方文档给了一个非常形象的区分方式:适合写在参考文档里的,是 skill;适合写在便利贴上的,是 memory。更重要的是,skills 采用 progressive disclosure,只在需要时才展开加载,避免每轮对话都把所有知识拖进上下文窗口里烧 token。
这也是 Hermes 和很多”有记忆的助手”不太一样的地方。它不只是把你说过的话记下来,而是把”会做某件事的方法”抽出来,变成可以复用的技能。
官方文档里明确写到,agent 在完成复杂任务、踩过坑找到正确路径、被用户纠正后发现更优做法时,会通过 skill_manage 工具创建、更新或删除技能。也就是说:
Hermes 不只会”记住你”,它还会”记住怎么做”。
当然,Hermes 也没有把”长期记忆”全都塞进 prompt 里。它还会把所有会话保存成 session,存进 ~/.hermes/state.db 的 SQLite 中,配合 FTS5 做全文检索;网关侧还会保留 JSONL 转录。需要时再通过 session_search 找回来。
这个设计很像一个靠谱的工作系统:不是把所有纸都铺满桌面,而是把档案归进柜子,真正要用时再调出来。
四、为什么说它是一个”Agent 中枢”,不是一个产品?
它可以通过MCP连接外部工具服务器,把 GitHub、数据库、文件系统、浏览器栈和内部 API 接进来,支持本地 stdio 和远程 HTTP 两种模式,还能按 server 过滤暴露哪些工具给 agent。
它还能通过API Server暴露为 OpenAI-compatible endpoint,让 Open WebUI、LobeChat、LibreChat、NextChat 这类前端把它当后端来调用。
你会发现,Hermes 的思路不是把自己做成一个封闭产品,而是把自己做成一个 agent 中枢。
再加上cron和delegation这两张牌,它就更像”会工作的 agent”而不是”会说话的模型”了:
Cron
支持一次性或周期性任务、技能绑定、结果投递到聊天入口或本地文件;
Delegation
允许它拉起隔离的子 agent 并行处理任务,每个子 agent 有独立会话、终端和工具集,只把最终摘要回传给主上下文,避免上下文被中间过程挤爆。
官方甚至给了并行执行的边界:子代理并发上限、不可递归继续 delegation、不适合碰同一个文件。这些细节,都能看出这是一个认真在考虑”生产环境怎么跑”的项目,不是一个 demo 玩具。
看到这里,你大概能理解,为什么我不建议把 Hermes Agent 简单归类到”AI Coding 工具”。
它当然可以做 coding,但它的野心明显更大——它既能做开发协作,又能做群聊机器人、定时报告、跨平台通知、企业内部流程代理,甚至可以当一个自带工具、记忆、技能和消息入口的统一工作底座。
五、那么,Hermes Agent 到底该怎么落地?
我的建议是:按三步走,不要一上来就想做一个”全能智能体”。
最简单的落地方式不是接企业系统,而是先用 CLI 跑起来,把你的 AGENTS.md、SOUL.md、memory 和几个高频 skill 建起来。
这样做的意义是先跑通“长期上下文 + 技能沉淀”的闭环。因为 Hermes 的强项,从来不是第一轮回答有多惊艳,而是你连续用一周、两周、一个月之后,它是不是越来越懂你的项目和套路。
官方也明确支持本地模型或任何 OpenAI-compatible endpoint,意味着你可以用 Ollama、vLLM、llama.cpp 这类本地或私有推理服务,去降低成本、提高数据可控性。
Hermes 最适合出成绩的场景不是单机自嗨,而是接到 Telegram、Slack、飞书、企微、钉钉这类团队沟通入口里,让它变成统一的任务代理。
研发群里发一句”每天上午 9 点汇总 GitHub 最近 24 小时的 PR、Issue 和主干 CI 状态”,Hermes 直接建 cron;
运维群里让它每 6 小时检查磁盘、内存和容器状态,异常时推送告警摘要。
等你已经有了稳定入口,再考虑通过 MCP 接 GitHub、数据库、知识库、内部工单系统、发布系统、监控系统;或者通过 API Server 让前端面板、内部门户、知识助手统一走 Hermes 后端。
这一步 Hermes 的价值才真正出来。因为它不是一个单点工具,而是——
“一个可长期运行、能调度工具、能跨入口交互、能带记忆和技能”的 agent 内核。
对企业来说,这比一个只能在 IDE 里帮你改代码的 AI 助手,更接近真实生产力。
六、真正落地时,最容易踩的 6 个坑
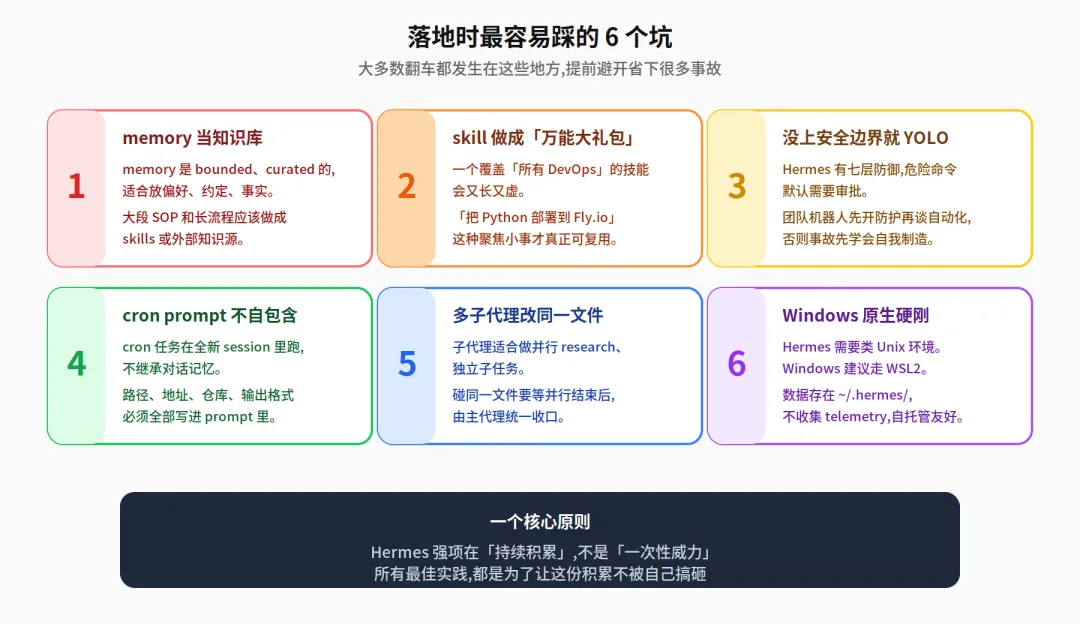
Hermes 的 built-in memory 是 bounded、curated 的,适合放偏好、约定、环境事实,不适合拿大段 SOP、长流程、系统说明文档往里塞。大块知识要做成 skills,或者放上下文文件、外部知识源,再通过 MCP 或检索方式取。否则 memory 会像口袋里塞砖头,越走越沉。
官方 best practice 说得很清楚,skill 要聚焦。一个覆盖”所有 DevOps”的技能会又长又虚,一个只解决”把 Python 应用部署到 Fly.io”的技能才真正可复用。很多团队一上来就喜欢做”大而全知识包”,结果 agent 每次都像背着旅行箱跑百米。
Hermes 有七层防御模型,包括用户授权、危险命令审批、容器隔离、MCP 凭据过滤、上下文文件扫描等。默认模式下,危险命令需要人工批准;如果用 Docker 终端后端,还会有额外的容器隔离和硬化设置。
团队机器人别一上来就 YOLO——不然 agent 还没变聪明,事故先学会自己制造了。
这是很多人会忽略的点。官方教程明确提醒,cron 任务是在全新 session里跑的,不会继承你当前对话里的上下文记忆。所以路径、地址、仓库、目标格式都要写在 prompt 里。
别把它想成”稍后继续聊”,它更像”按时派出一个全新工人去干活”。
第五,并行 delegation 很强,但别让多个子代理改同一个文件。
Hermes 的子代理适合做并行 research、代码审查、独立子任务处理,因为它们有独立会话和终端,只回传摘要,能显著节省主上下文。
但官方也提醒了,如果多个子代理可能碰同一文件,最好等并行阶段结束后由你或主代理统一收口。否则就是几把刷子一起蘸一桶油漆,墙没刷好,地板先遭殃。
官方 FAQ 已经写明,Hermes 需要类 Unix 环境,Windows 建议走 WSL2。数据本地存储在 ~/.hermes/,Hermes 自身不收集 telemetry,API 请求只发到你配置的 provider。
这个特性对隐私和自托管都很友好,但前提是——部署环境别一开始就选错。
七、我的判断:Hermes 值得研究,但它真正适合的是”想做系统”的人
如果你只是想要一个”会写代码的 AI 助手”,Hermes 可能不是最快上手的那个。它有自己的目录结构、上下文体系、技能体系、网关体系、安全边界和运行方式,学习门槛并不低。
把 AI 从一次性聊天,升级成持续运行的研发代理、运维代理、测试代理、团队协作代理——那么 Hermes 的价值就会非常大。因为它已经把长期运行、跨入口交互、记忆、技能、MCP、API Server、cron、delegation 这些拼图基本拼齐了。
你真正要做的,不是再发明一遍 Agent,而是结合自己的业务场景,把入口、上下文、工具和安全边界编排好。
Nous 还单独做了一个 hermes-agent-self-evolution 项目,用 DSPy + GEPA 去优化 skills、工具描述、system prompts 甚至代码,而且不需要 GPU 训练。这很有想象力,但我不建议一开始就碰。
对大多数团队来说,先把”稳定可用的 Agent 工作流”跑起来,比”自动进化的 Agent”更重要。
一句话总结:Hermes Agent 不是让你”用 AI 更快地做一次事”,而是让你的 AI 能”一直在线、持续变强、越用越懂你”。它卖的不是对话能力,是时间复利。
 夜雨聆风
夜雨聆风