 夜雨聆风
夜雨聆风





2026年多模态AI创作工具链保姆级教程
你有没有过这种崩溃时刻:
Midjourney出图风格不对,重来;Runway生成的视频人物总变脸,重来;文案写完,配图又得切到另一个工具……切换5个软件,调了20版参数,AI反而让我的工作量翻倍了。
以前我也这样。直到我真正搞懂了“多模态AI工具链”——不是单个工具有多强,而是怎么让它们像流水线一样运转起来。
今天这篇,就是帮你彻底告别“工具间反复横跳”的保姆级用户手册。从概念到原理,从入门到高阶,一篇文章讲透2026年最前沿的多模态AI创作玩法。
图例1:多模态AI创作工作流全景图
一、别搞错了:多模态AI不是“多个AI”
先破除一个最大的误解。
很多人以为多模态AI就是“图像AI+语音AI+文字AI”的缝合怪——打开一个软件画图,再打开另一个软件写文案,这叫多工具,不叫多模态。
真正的多模态AI,是把文本、图像、音频、视频放在同一个技术体系下协同处理。它能看懂图里的文字情绪,能听着视频配乐写脚本,能根据一句话同步产出图文视频三件套。
2026年,这个能力已经成熟了。市场规模达到28.3亿美元,从阿里Qwen3.5-Omni到谷歌Gemini 2.5,一个模型搞定“听、看、说、做”正在成为标配。
📌 记住一句话: 多模态AI不是在给你更多工具,而是在给你一个更聪明的大脑。
二、1分钟搞懂原理:它为什么这么聪明?
你不用成为算法工程师,但理解原理能让你少踩90%的坑。
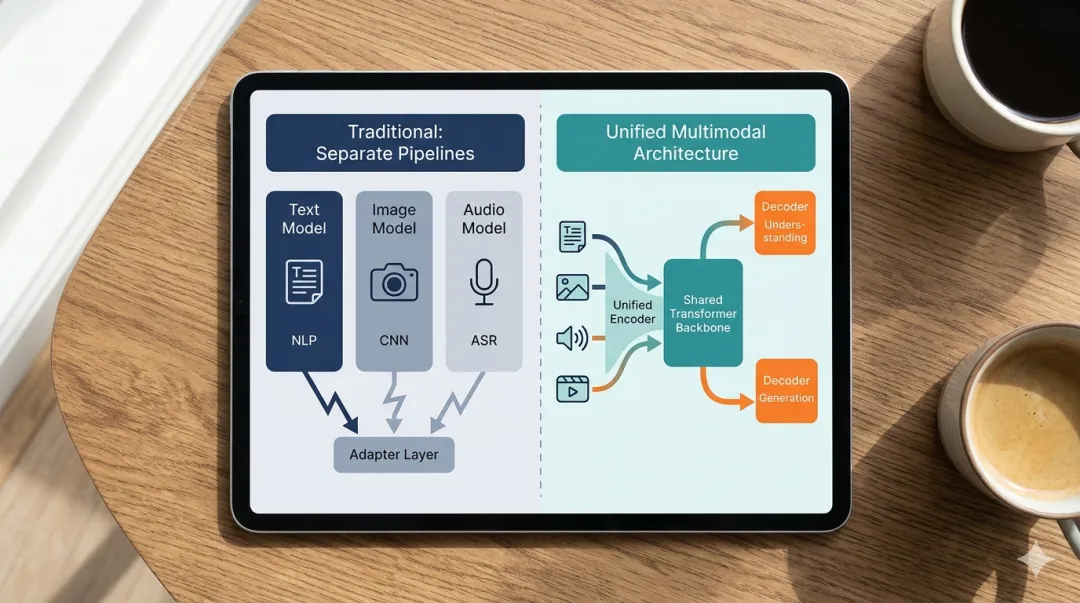
传统做法是“分模块拼接”:图片归图片模型管,文字归文字模型管,中间加个传话的“翻译层”。问题出在传话过程——信息损耗严重,AI根本搞不懂“这张悲伤的图”和“那段开心的文案”之间有什么关联。
新一代方案叫统一表示空间架构。简单说,就是把所有类型的数据——文字、图片、声音、视频——全部压缩成同一种数学语言,放进同一个大脑里思考。

图例2:多模态统一架构示意图
这样做的好处立竿见影:
-
跨模态理解:上传一张产品图,AI能自动分析视觉风格、识别品牌元素,甚至帮你写营销文案。 -
跨模态生成:输入“夏日海边落日”,AI同时给你图片、配乐和15秒短视频分镜。 -
跨模态检索:用一张随手拍的照片,搜到风格相似的插画师作品。
📋 一分钟行动卡
-
打开你常用的AI工具(ChatGPT/Claude/DeepSeek任意一个) -
上传一张工作相关的图片 -
输入提示词:“请分析这张图的视觉元素,并写一句社交媒体配文” -
感受一下什么叫“AI看懂图了”
三、2026工具链地图:别乱花钱,按需取用
市面上的多模态工具上百个,你不需要全学。按这四个层级选,够用且不冤。
第一层:图像生成
|
|
|
|
|---|---|---|
| Midjourney V8.1 |
|
|
| Stable Diffusion |
|
|
| Adobe Firefly |
|
|
🔥 新功能速递:Midjourney V8.1的“Run as HD”按钮,标准图一键转2K高清,渲染速度快了3倍,成本降了3倍。
第二层:视频生成
行业地震了——OpenAI在2026年3月关停了Sora。填补空缺的是这两家:
-
Runway Multi-Shot App:输入一段文字,AI自动拆镜头、配乐、剪辑成完整短片。 -
Mootion Wan 2.7:角色一致性极强,电影级镜头控制,专业创作者首选。
第三层:全模态大模型
|
|
|
|---|---|
| Qwen3.5-Omni |
|
| Gemini 2.5/3 |
|
| Claude 3.7 Sonnet |
|
| DeepSeek |
|
第四层:工作流串联器
单点工具玩得再溜,效率也是加法。工具链串联才是乘法。
-
Adobe Firefly AI Assistant(2026公测):跨PS、PR、AI编排工作流,一句“把这张海报做成15秒宣传片”自动跑完全流程。 -
SeaVerse:集成了大模型、绘画、视频和AI智能体,一句话打包创意为完整产品。
📋 一分钟行动卡
-
根据你的工作场景,从上面四个层级各挑一个工具 -
本周只研究这4个,其他的先不看 -
目标:能用这4个工具跑通一个完整创作流程
四、从入门到精通的三级跳
Level 1:基础用法——写好提示词
提示词是AI时代的“咒语”。记住这个万能公式:
主体描述 + 风格/材质 + 构图/视角 + 光线/氛围 + 技术参数
实战示例(Midjourney) :
A cozy coffee shop interior, warm lighting, wooden furniture, plants by the window, cinematic composition, soft morning light, 4K, --ar 16:9 --v 8.1
💡 进阶心法:先出量再求精。用标准模式快速跑出20张图找方向,确认后点击“Run as HD”高清出图。迭代速度比一次完美重要十倍。
Level 2:进阶用法——跨模态工作流
这是效率跃迁的核心。以品牌营销物料制作为例:
-
文案生成:用Claude/DeepSeek写品牌故事(文本) -
视觉产出:把文案中的关键词输入Midjourney出图(文生图) -
风格锁定:用Midjourney的图像提示功能,以品牌现有素材为参考保持风格统一(图生图) -
视频输出:将图文素材导入Runway,生成15秒短视频 -
配音字幕:用Qwen3.5-Omni生成配音,AI自动加字幕
一个人,1小时,一套完整物料。去年需要设计师+文案+剪辑师协作半天。
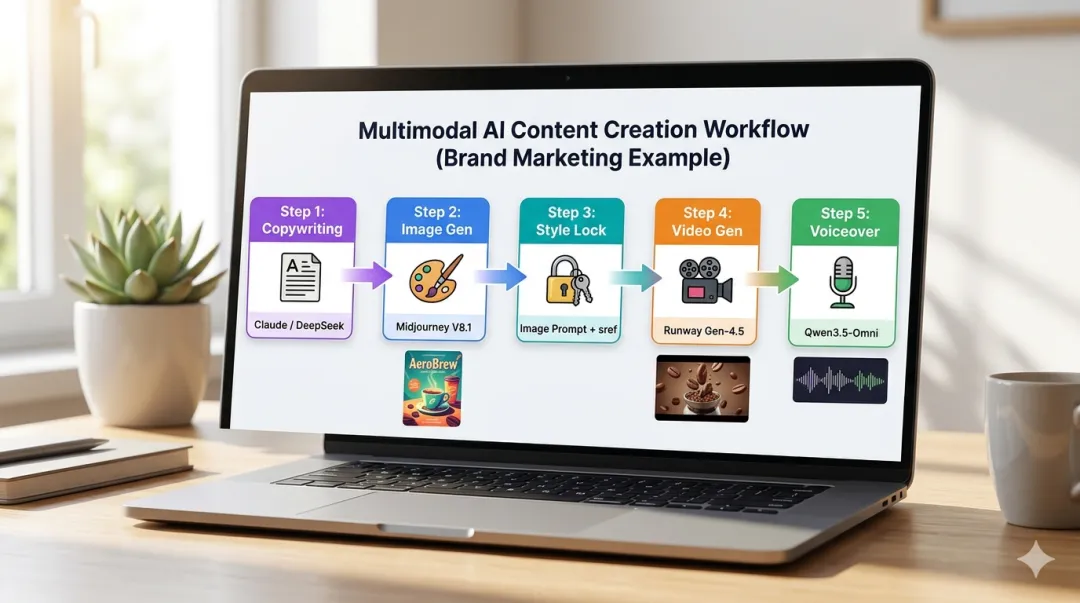
图例3:工具链串联工作流示意图
Level 3:高阶用法——情绪板与AI智能体
情绪板(Moodboard)锁定风格:Midjourney V8.1允许你保存“复古电影感”“某艺术家笔触”等风格模板,随时调用,品牌视觉从此高度统一。
AI智能体自主创作:这是终极形态。在Adobe Firefly AI Assistant里说一句“帮我做一组新品宣传物料,风格参考上次的春季系列”,AI会自动选工具、拆步骤、出方案、迭代优化。你只需要说“要这个”或“换那个”。
五、落地价值:真的能省钱省时间吗?
用数据说话。
时间维度:创意工作者反馈,多模态工具链让迭代周期缩短60%。以前“一天出3稿”,现在“一小时出30稿”。
成本维度:Midjourney V8.1高清渲染成本降至原来的1/3;国产大模型Token价格战让文字生成几乎零成本。
人力维度:一个人+一套工具链=一个小型内容团队的基础产能。
真实场景举例:
-
市场营销:A/B测试素材同时出20版,数据反馈后AI自动优化下一版。 -
产品设计:从“几天画一稿”到“一天出几十个概念方案”。 -
个人创作:写小说配插画、做播客配封面,创作门槛归零。
六、避坑指南:这五个坑我替你踩过了
坑一:以为AI能一键出成品。真相是AI给的是“毛坯”,需要人工精选和微调。
坑二:工具收藏癖。集齐100个工具不如精通1条工作流。
坑三:忽视版权。商用前一定确认AI工具的授权条款,Adobe Firefly是目前版权最清晰的选项。
坑四:提示词写得太抽象。“画一个好看的女孩”——AI不知道什么叫“好看”。改为“画一个25岁亚洲女性,自然光,温柔笑容,森系穿搭”。
坑五:不用“图生图”功能。从零出图效率低,先给AI一张参考图,再调整参数,精准度提升50%。
七、写在最后:AI永远不会替代的东西
2026年,多模态AI还在加速进化。三个信号值得你盯紧:
-
AI智能体将成为主流——从“你操作AI”到“AI帮你操作工具” -
实时多模态交互成为标配——AI像真人一样和你对话、看图、听声 -
版权体系加速完善——商业应用的最后一公里正在打通
但有一件事不会变:AI放大的是效率,不是灵魂。
它能帮你1小时出100版海报,但选哪一版、传递什么情绪、讲什么故事——这些决定来自你的审美、你的洞察、你对世界的理解。
把重复劳动交给AI,把创造力留给自己。这才是多模态工具链的终极用法。
📌 记住这句话:
多模态AI把画笔给了每一个人,但画出什么的,永远是你自己。