夜雨聆风
夜雨聆风





【统计分析软件SPSS】51、数据转置
链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:
https://www.mizhushare.com/docs/
在日常数据分析中,我们常常会遇到数据格式不匹配的情况。比如,原始数据是“横向”记录的(每个变量占一列),但某些统计方法或者软件要求数据是“纵向”的(每个变量占一行)。这时,【数据转置(Transpose)】功能就派上了大用场。
-
数据转置:
数据转置,简单来说,就是将数据表格的行和列进行互换。在SPSS中,这通常意味着将个案(Case,即行) 和变量(Variable,即列) 进行对调。
这在进行某些特定的统计分析或调整数据格式以适应不同软件要求时,非常有用。

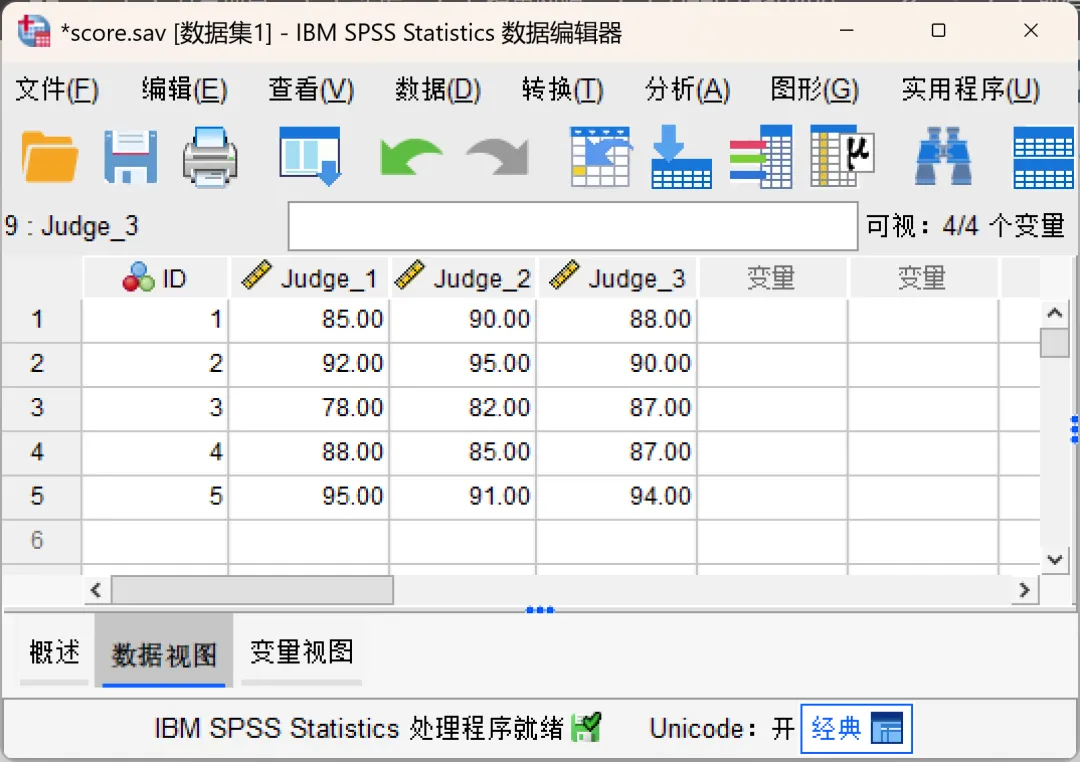
点击顶部菜单栏的【数据→转置】,在打开的对话框中进行相应设置。
-
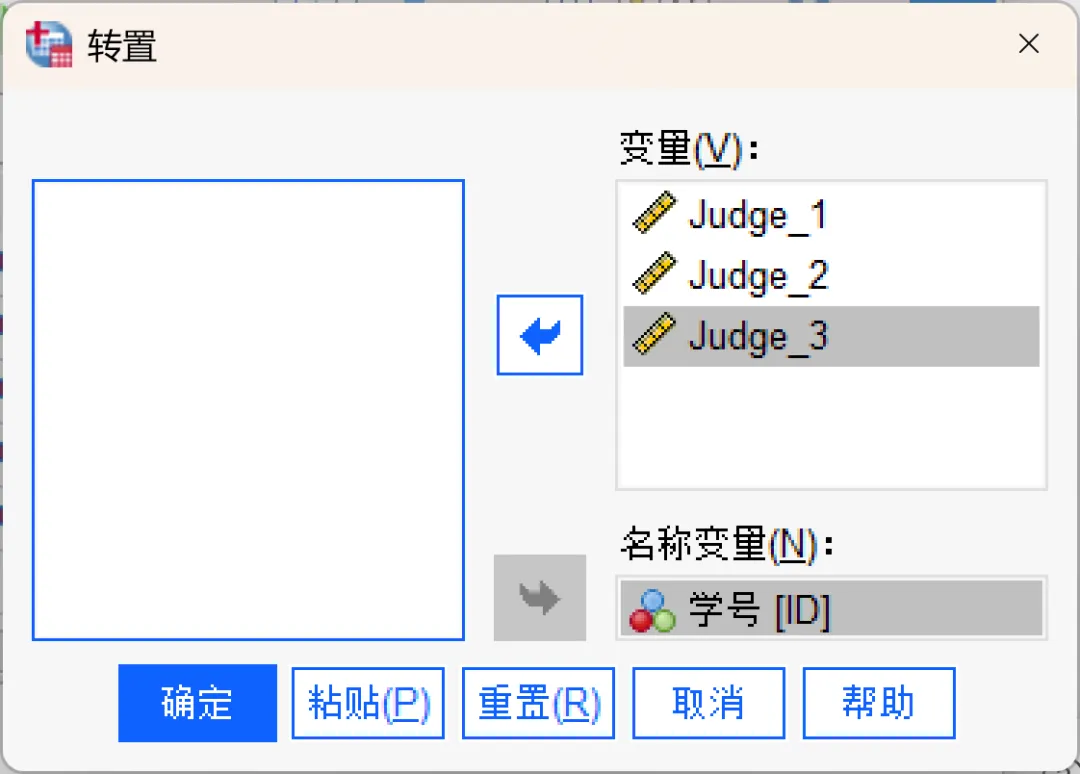
变量:需要参与转置的变量,即原数据中需要变成行的变量。本次示例将「Judge_1、Judge_2、Judge_3」这三个变量移入「变量」框,这意味着转置后,这三位评委将变成新的个案(行)。
-
名称变量:用于定义转置后新变量的名称。如果名称变量是数值,系统会自动加「K_」前缀(比如K_1、K_2),因为SPSS不允许纯数字作为变量名。如果不指定名称变量,SPSS会自动生成「var001、var002」等默认名称。本次示例将「ID」变量移入「名称变量」框。
需要注意的是,没有被选入右侧「变量」或「名称变量」框中的变量将不会出现在新数据集中。
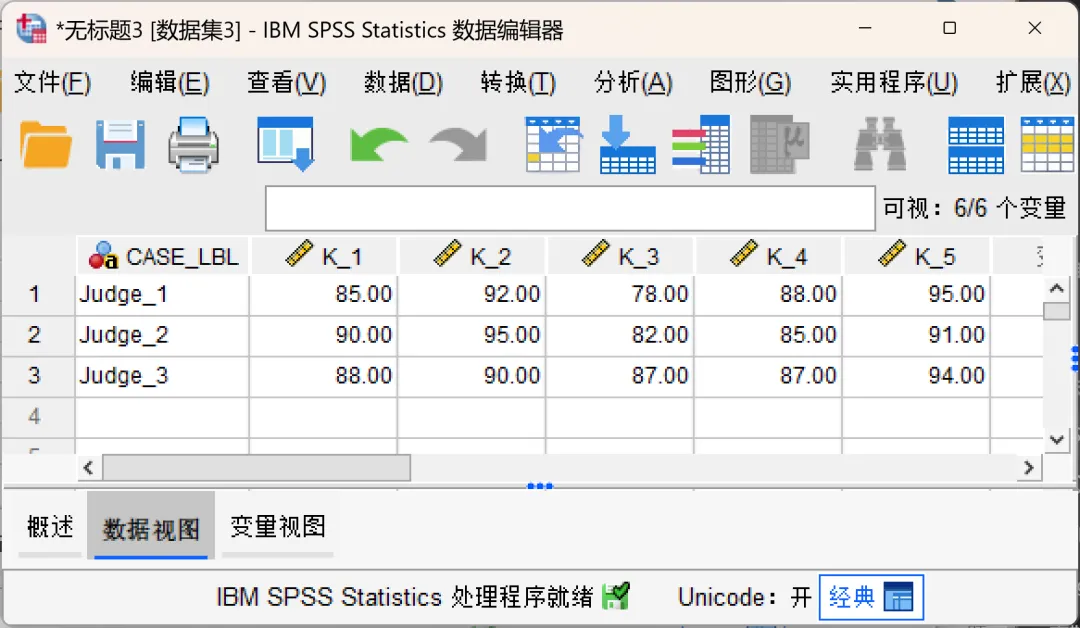
设置完成,点击确定。SPSS会生成一个新的数据文件,将原始数据文件中的行和列进行互换。其中:
-
CASE_LBL:系统自动生成的一个字符串变量,它保存了转置前被选入「变量」框的那些变量的原始名称,即「Judge_1、Judge_2、Judge_3」。
-
K1 到 K5:这是转置后的新变量。因为我们指定了「ID」变量作为名称变量,因其为数值类型,系统会自动生成了以「K_」开头的变量名,分别对应原来的5位运动员。