 夜雨聆风
夜雨聆风





AI 代理、AI 工厂与下一场工业革命,黄仁勋这次把底层逻辑讲透了
如果只把 NVIDIA 理解成一家卖 GPU 的公司,那已经明显落后于黄仁勋想推动的叙事。
在这场 GTC 期间的深度专访里,他真正想解释的是一件更大的事:AI 不只是一个模型能力的升级,而是一整套新的生产系统正在成形。 这套系统里,数据中心不再只是“放服务器的地方”,而更像一座持续生产 Token、智能体和自动化能力的“AI 工厂”;软件也不再停留在单次问答,而是开始进入“代理化处理”的阶段;机器人、自动驾驶、工业数字孪生,则是这套系统向物理世界的延伸。
更值得注意的是,这并不是一套单点技术愿景。它把算力、推理、内存、网络、调度、仿真、边缘执行和产业供应链全部连在了一起。
下面我按照访谈的几个章节,结合公开资料,把这套逻辑拆开讲清楚。
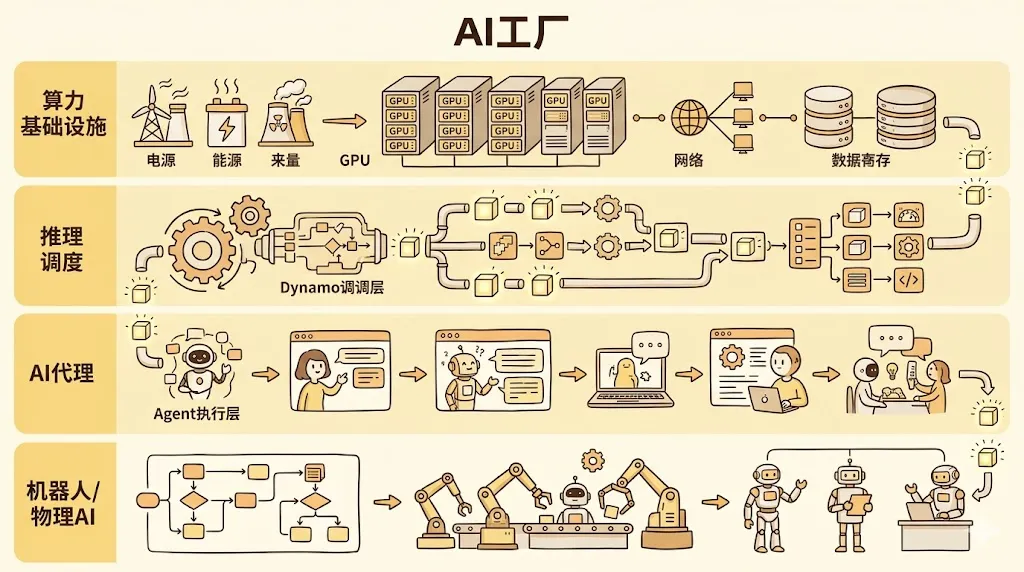
一、NVIDIA 已经不想只做 GPU 公司了,而是想做“AI 工厂公司”
黄仁勋在访谈里反复强调,NVIDIA 正在从一家 GPU 公司,转向一家“AI 工厂”公司。
这个提法很重要,因为它意味着价值衡量标准变了。过去,数据中心的核心指标是服务器数量、虚拟机负载和存储容量;而在 AI 工厂逻辑里,更关键的指标变成了:
-
• 单位时间能生产多少高价值 Token -
• 每个 Token 的综合成本是多少 -
• 整个系统能否持续、高吞吐、低延迟地完成训练、推理和代理协作
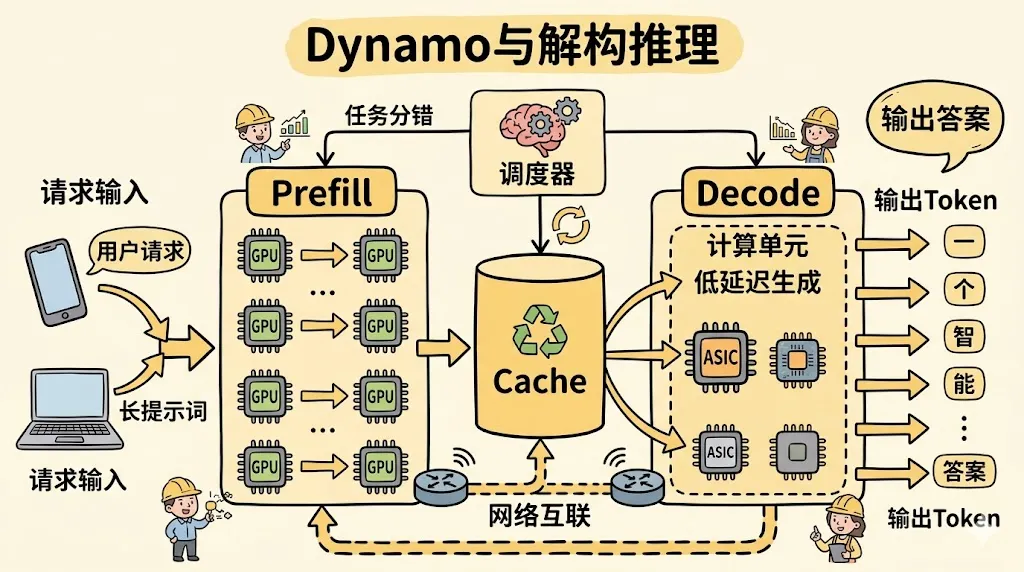
公开资料里,NVIDIA 把 Dynamo 定义为 AI Factory 的推理操作系统。它是 Triton Inference Server 的延伸,但目标更激进,不只是“把模型跑起来”,而是把推理过程拆解、调度、路由和缓存优化到极致。官方披露的重点能力包括:
-
• 将 prefill 与 decode 解耦,分别调度到不同资源池 -
• 通过分布式 KV cache 降低重复计算 -
• 对 GPU、内存和网络进行统一编排 -
• 为大规模推理和 agentic workload 提供更高吞吐和更低单位成本
这也是为什么黄仁勋会用“工厂”这个比喻。传统工厂把能源、原料和机械组织起来,持续生产标准化产品。AI 工厂则把电力、芯片、网络、存储和软件调度组织起来,持续生产 Token、预测、决策和自动化能力。
换句话说,GPU 已经从商品本身,变成了流水线上的关键机器;真正的产品,是智能。
这一章背后的公开资料补充
结合 NVIDIA GTC 相关公开资料,可以看到这套叙事不是修辞,而是产品路线图:
-
• NVIDIA 将 Dynamo 公开定义为面向 AI 工厂的开源推理软件层 -
• Dynamo 强调 disaggregated serving,也就是将不同推理阶段拆开优化 -
• 公开材料多次提到 agentic AI、reasoning model 和 AI factory 是同一代基础设施问题的不同侧面
这意味着 NVIDIA 的野心早就不止是卖卡,而是定义“AI 时代的数据中心操作方式”。
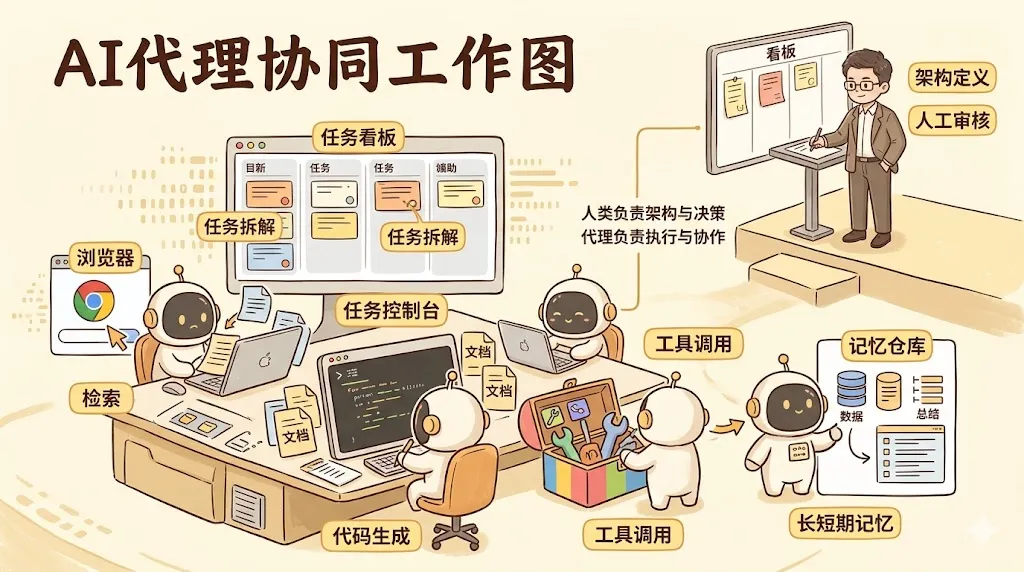
二、从 LLM 到 AI Agent,计算范式真的变了
黄仁勋在这次访谈里最值得重视的判断之一,是行业正从“大语言模型”走向“代理化处理”。
这是一个经常被说滥,但很少被讲透的词。
所谓 Agent,不只是把聊天框换个名字。它至少意味着四个变化:
-
1. 它不只回答问题,还要执行任务 -
2. 它不只读当前上下文,还要连接长短期记忆 -
3. 它不只调用一个模型,还要调度多个工具和子代理 -
4. 它不只输出文本,还要对外部系统产生真实动作
这和传统 LLM 最大的不同,是“系统边界”被打破了。模型不再只是一个语言接口,而是被放进一个带有记忆、工具、调度、权限与资源管理的运行时里。
也正因为如此,黄仁勋才会在访谈里把 OpenClaw 提到一个近乎“新型操作系统”的高度。这个判断的关键不在于某个具体开源项目本身,而在于他点出了 agentic computing 的核心不是模型,而是运行时:
-
• 有没有内存系统 -
• 能不能做资源管理 -
• 能不能调度多代理协作 -
• 有没有清晰的接口和权限边界 -
• 能不能把 reasoning、tool use、memory、execution 串起来
这其实是在重新定义未来软件栈。
未来的软件,不一定是一个单体 App,而更像是一个“任务执行系统”:用户提出意图,代理理解目标,拆分任务,调用工具,访问记忆,协同执行,再回到人类审批或接管。
为什么这会改变软件工程师的工作方式
黄仁勋提到,未来软件工程师可能会拥有成百上千个 AI 代理。这个说法看起来夸张,但方向并不夸张。
当生成代码、跑测试、写文档、搜资料、做 review、部署和监控都可以被代理分解承担时,人类工程师最稀缺的能力就会从“写每一行代码”,转向:
-
• 定义架构 -
• 拆解规格 -
• 设置约束 -
• 评估风险 -
• 审核代理结果 -
• 做最终决策
也就是说,工程师的价值更像“系统设计师”和“责任承担者”,而不是单纯的键盘执行者。
这不是程序员消失,而是软件生产线被重构。
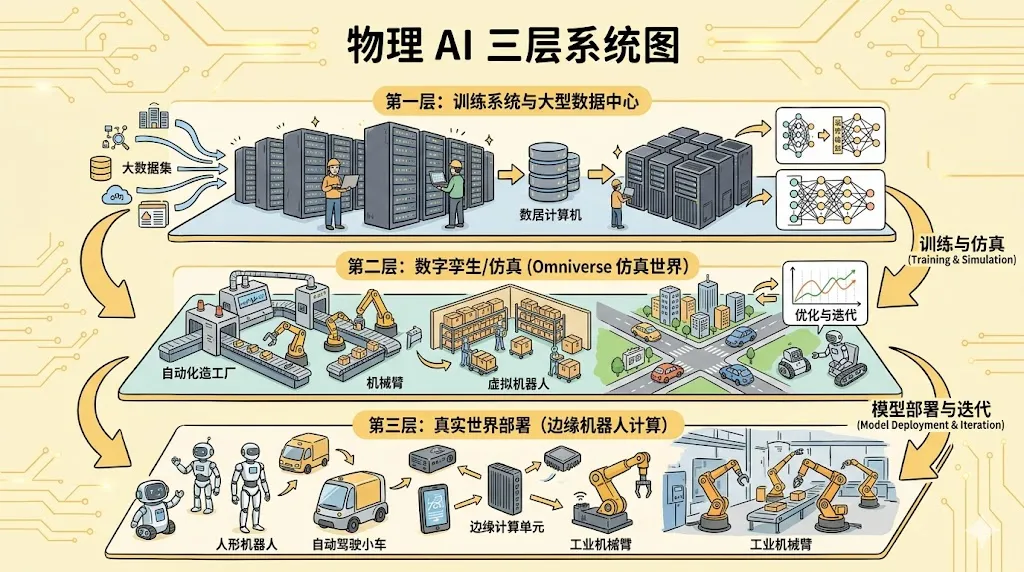
三、物理 AI 才是这套叙事真正落地到现实世界的部分
很多人提到 AI,脑子里想到的还是聊天机器人、搜索和生成内容。但黄仁勋讲得更远,他关心的是 Physical AI,也就是 AI 进入物理世界之后,如何理解环境、做规划并驱动机器行动。
在这套叙事里,自动化不是一个单点模型问题,而是三个计算系统的协同:
-
• 用于训练智能模型的训练系统 -
• 用于模拟物理世界的 Omniverse / 数字孪生系统 -
• 运行在边缘设备上的机器人计算系统
这三者缺一不可。
如果没有训练系统,机器人没有“大脑”;如果没有仿真系统,机器人无法在低成本环境里学习复杂物理互动;如果没有边缘计算系统,机器人就无法在真实世界低延迟执行。
公开资料显示,NVIDIA 正在把 Omniverse、Isaac、Cosmos、GR00T 这类能力接到同一条链路上,本质上就是想做一条从“世界建模”到“仿真训练”再到“实体部署”的工业级流水线。
这也是黄仁勋为什么会预测,未来 3 到 5 年机器人会“无处不在”。
如果说过去机器人受限于机械成本和规则编程,那么现在真正被突破的是“通用感知 + 世界模型 + 仿真训练 + 边缘算力”的组合门槛。一旦这一组合成熟,机器人扩散速度就不会是线性的,而会像工业自动化软件那样呈平台化扩散。
为什么他特别提到中国供应链
这部分尤其现实。
黄仁勋提到,中国在微电子、电机、稀土、磁材等机器人关键环节上的能力,对全球机器人产业至关重要。这不是礼貌性表态,而是产业事实。
机器人的“大脑”可以由 AI 模型、边缘芯片和仿真系统驱动,但它的“身体”仍然高度依赖成熟的制造供应链,包括:
-
• 伺服电机 -
• 减速器 -
• 传感器 -
• 功率电子 -
• 稀土永磁材料 -
• 精密加工与规模制造体系
这意味着未来机器人竞争并不是纯软件战争,而是“算力平台 + 软件栈 + 制造供应链”的综合竞争。
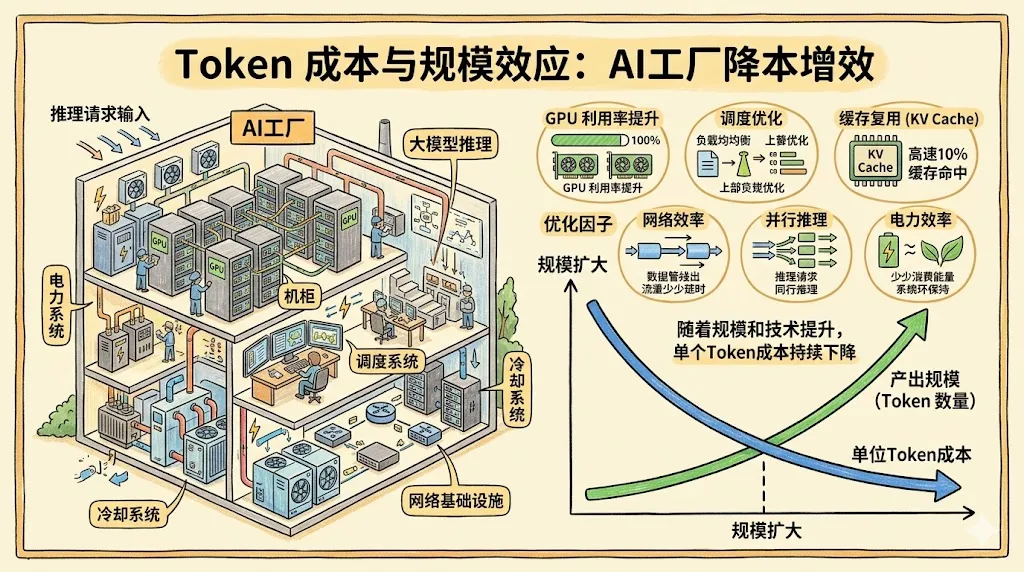
四、为什么黄仁勋坚持说,昂贵的 AI 工厂反而能打出最低 Token 成本
很多人一听到“500 亿美元级工厂”,第一反应就是太贵了,不可持续。
但黄仁勋的逻辑正好相反:越是高强度、规模化、系统化设计的 AI 工厂,越可能把单位 Token 成本压到最低。
背后至少有三层原因。
1. 推理时代的核心不再是“买到卡”,而是“把整套系统吃满”
AI 成本并不只取决于单张 GPU 的价格,还取决于:
-
• GPU 利用率 -
• 网络延迟 -
• 内存调度效率 -
• KV cache 命中率 -
• prefill / decode 分工是否合理 -
• 电力和散热效率 -
• 任务排队与负载均衡能力
这就是为什么 NVIDIA 不断强调系统设计,而不是只强调芯片参数。单点性能再强,如果整个系统调度糟糕,最终每个 Token 的成本仍然会很高。
2. Agentic workload 会把推理需求放大到传统聊天场景无法比拟的程度
一个简单问答只需要生成一段文本;而一个代理系统可能要:
-
• 先检索外部资料 -
• 再做多轮 reasoning -
• 同时调用多个工具 -
• 写代码并执行 -
• 回读结果再继续决策
它消耗的 Token、上下文、缓存和并发资源都远超单次聊天。
所以未来的竞争,不是谁“能跑模型”,而是谁能以更低成本、更高吞吐、更稳定的方式跑复杂代理系统。
3. 当智能变成工业品,规模效应一定会出现
黄仁勋把 AI 工厂和发电厂、制造工厂类比,本质上是在强调一件事:一旦 Token 成为真正可计量、可优化、可规模化生产的产物,边际成本就会像工业时代的电力和算力一样不断下降。
这套逻辑是否百分之百成立,还要看未来需求增长是否足以覆盖资本开支,但有一点已经很明确:NVIDIA 希望把 AI 基础设施从“IT 支出”叙事,改写成“生产性资本开支”叙事。
五、AI 对就业的影响,不是简单替代,而是把“任务”从“目的”里剥离出来
黄仁勋在很多场合都喜欢用放射科医生举例,这次访谈也延续了这个思路。
这个例子的关键不是“AI 会不会读片”,而是一个更深的问题:一个职业到底是由若干任务构成,还是由一个更高层的目的定义?
如果把放射科医生理解成“看影像的人”,那 AI 的确在替代其中大量任务;但如果把放射科医生理解成“帮助患者诊断疾病的人”,那么影像识别只是其中一部分工作。
当 AI 提高读片效率时,会带来几个连锁反应:
-
• 医生可以处理更多病例 -
• 诊断速度更快,更多患者愿意进入流程 -
• 医院整体服务能力提高 -
• 新的临床分工和协作需求反而增加
因此,被改变的往往是任务结构,而不是职业目标本身。
这也是黄仁勋反复强调“AI 是让人获得超能力”的原因。AI 真正释放的,不是人类的存在价值,而是人类在重复性任务上的时间。
当繁琐任务被外包给机器,人类更应该回到创造、判断、协作、同理心和责任承担。
当然,这并不意味着转型没有痛感。短期内,一部分岗位会先经历流程再造、技能迁移和组织重组。真正值得警惕的,不是 AI 一夜之间消灭所有工作,而是组织和个体是否足够快地完成再学习。
六、全球竞争的关键,已经从“有没有模型”转向“谁定义整套技术栈”
这场访谈另一个很清楚的信号,是黄仁勋对全球技术竞争的理解并不局限于芯片出口管制,而是更大的平台问题。
他的核心观点可以概括为两句:
-
• 国家安全不只来自控制,也来自技术栈的全球领导地位 -
• 行业不只需要顶级私有模型,也需要开源模型去承载不同领域的知识和定制能力
这两点合起来,实际上是在说:未来真正有统治力的,不是一个孤立模型,而是一整套被全球开发者、企业和产业链采用的基础设施组合,包括:
-
• 芯片 -
• 服务器与网络 -
• 推理运行时 -
• 开发框架 -
• 开源生态 -
• 企业级安全与治理工具
为什么开源重要?
因为行业知识是分散的。医疗、制造、金融、教育、零售、科研,每个领域都有自己的流程、术语、合规要求和经验数据。不是所有行业都会把核心知识完全交给单一闭源模型厂商。
所以未来很可能是这样的格局:
-
• 通用能力由世界级私有模型持续拉高天花板 -
• 领域适配由开源模型和开源代理框架加速落地 -
• 企业级产品再把安全、权限、治理和责任闭环补上
这其实不是“开源 versus 闭源”,而是“开源 + 闭源”共同构成产业分层。
七、把这些线索放在一起,黄仁勋真正讲的是一场新的工业组织方式
如果把整场访谈压缩成一句话,我会这样总结:
AI 革命的主战场,正在从“模型能力竞赛”转向“智能生产系统竞赛”。
这个系统包含几层递进关系:
-
1. 底层是电力、芯片、网络、存储和散热 -
2. 中间层是训练、推理、调度、内存和运行时 -
3. 上层是代理系统、企业工作流与行业软件 -
4. 再往外,是机器人、自动驾驶和物理世界自动化
在这套框架里,单个模型只是发动机的一部分,不是全部。
真正决定谁能赢得下一轮产业红利的,是谁能把这几层真正接起来,并且跑出规模化、低成本、可治理、可部署的闭环。
从这个角度看,黄仁勋谈 AI agent、AI factory、Omniverse、机器人、开源生态、全球供应链,根本不是几个分散话题,而是在讲同一张图。
而这张图对企业最现实的启发是:
-
• 不要再只盯着“我该不该接入某个模型” -
• 要开始思考“我的业务会不会变成一个代理系统” -
• 要开始思考“我的数据、流程、知识库、权限体系能否被 AI 工厂化” -
• 也要开始思考“当物理 AI 成熟时,我所在行业会不会被重新定义”
这才是这场访谈真正让人警醒的地方。
它谈的不是一个新功能,而是一种新的工业操作系统。
结语
黄仁勋最厉害的地方,从来不只是预测技术趋势,而是他总能把一堆看似零散的技术,讲成一个统一的生产逻辑。
在这套逻辑里,AI 代理不是聊天机器人的升级版,AI 工厂也不是 GPU 机房的营销新名字,机器人更不是离现实很远的科幻玩具。
它们正在拼成一条完整链路:从 Token 到智能体,从智能体到工作流,从工作流到机器人,从机器人再回到新的工业能力。
如果这条链路成立,那么未来几年最重要的问题就不再是“AI 能做什么演示”,而是:
谁能最先把 AI 变成持续、低成本、可治理、可复制的生产系统。
这或许就是下一场工业革命真正的起点。
参考资料
-
1. NVIDIA 关于 Dynamo 与 AI Factory 的公开资料与 GTC 相关发布 -
2. NVIDIA 关于 Omniverse、Isaac、GR00T、Physical AI 的公开材料 -
3. 行业报道中关于黄仁勋对 radiology、agentic AI、机器人和全球技术栈的多次公开表述 -
4. 本文对访谈原始摘要进行了结构化整理与扩展解读