 夜雨聆风
夜雨聆风





0.9B小模型,文档解析干翻GPT-4o?这事还真不是吹的
关注”东哥说AI“,持续分享大模型应用实战经验。
你有没有碰到过这种头疼的场景——
手头一堆PDF,里面是财务表格、合同条款、手写笔记,想让AI帮你分析,结果丢进去一看,识别出来的东西乱七八糟,根本对不上号。
我自己就遇到过。明明是一份整整齐齐的合同,OCR识别完以后,表格变成了乱码,金额全错了。这个时候让大模型去”审查合同”,审出来的结果能用才怪。
问题不在大模型,在于它”看文件”的眼睛有问题。
大模型有个先天短板,很少有人讲透
我们说大模型能写代码、能做分析、能回答各种问题,但很少有人追问一句:这些内容是从哪来的?
现实业务里,大量的知识和信息是”锁”在文档里的。财务报表、内部报告、扫描件、手写记录……这些东西不是干净的文字,是图片、是版式复杂的PDF。
大模型要消化这些东西,先得有个东西把它们”翻译”成可读的文字。这个环节,就是文档解析。
这一步搞不好,后面全白费。你给大模型喂了一堆乱码,它不会告诉你”这个我读不懂”,它会非常自信地给你分析一堆没有意义的东西。
OCR(光学字符识别)做的就是这件事,但市面上大多数OCR工具对付简单文字还行,一碰到复杂表格、混排版式、公式图表,就歇了。
所以,文档解析的质量,直接决定了AI应用的上限。这也是为什么,这个领域最近热得很快。
百度飞桨发了个有点意思的东西
今年1月底,百度飞桨团队开源了 PaddleOCR-VL-1.5,这是他们专门为文档解析设计的一个视觉语言模型。
参数量 0.9B,不到10亿。
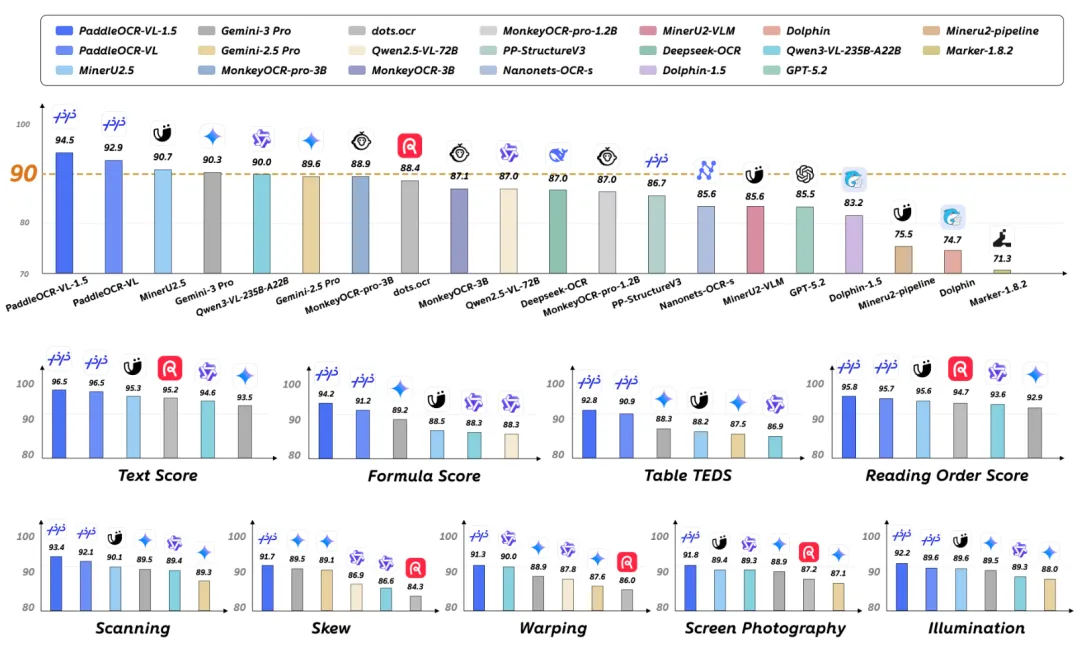
这个数字初听有点出戏——现在随便一个”大”模型都是几十亿、几百亿参数起步,0.9B好像轻得离谱。但它在 OmniDocBench 这个全球文档解析评测集上打到了第一,综合得分超过了 GPT-4o 和 Gemini 2.0。
我第一次看到这个结果的时候,想着应该是哪里有水分,仔细查了一下,这个评测覆盖的是表格识别、公式理解、多语言文本、阅读顺序还原等维度,不是只会认字的那种测试。
所以这件事是值得认真看的——而且是开源免费的。
它怎么做到的?
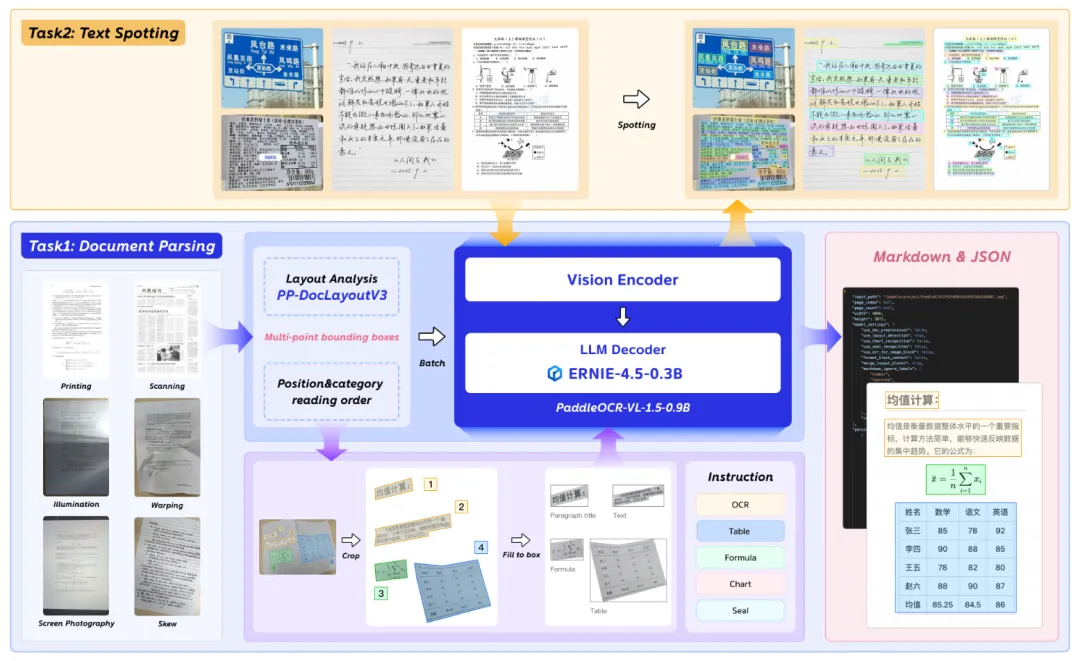
跟普通OCR不同,PaddleOCR-VL 走的是两段式的路子。
第一段,先做布局分析。就是先把文档”扫一眼”,判断哪里是标题、正文、表格、图片、公式,相当于先建一个地图。这一步用的是专门的版面检测模型 PP-DocLayoutV2。
第二段,再对每个区域做精准识别。针对不同类型的内容用不同的策略,文字认文字,表格理解表格结构,公式输出 LaTeX 格式。这部分是视觉语言模型做的,能”看懂”内容而不只是”抄写”。
最后输出的是结构化的 Markdown 或 JSON,格式干净,直接就能往后续的 AI 流程里送。

这种分工方式,解释了为什么它用 0.9B 就能做得很好:它没有试图用一个大模型搞定所有事,而是把不同任务分配给专门的模块,每个模块专注做好自己的那一块。
本地部署这件事,对企业来说挺重要
很多企业不敢用云端API处理内部文件,理由说出来都一样:数据不能出去。
合同、报表、内部方案,这些东西哪能随便上传给第三方?
PaddleOCR-VL 支持完整的本地化部署,配合 vLLM 这个推理框架跑,效率也不差。整个方案里,vLLM 负责加载和运行模型,PaddleOCR 的服务层负责接请求、分析版面、把任务转发给 vLLM,最后统一返回结果。
GPU 显存的门槛是 6GB,推荐 8GB 以上。这个配置对很多小团队也够用了,不需要动辄买 A100。
部署完成后,前端可以直接上传 PDF 文件,选择解析模型,然后就能看到结构化的解析结果。表格、图片、文字全部分类清楚,这个体验比传统方案好很多。
结合 AI Agent 做文档处理,这个方向值得试
学这套部署方案本身不是目的,后面能做什么才更有意思。
如果你在做 RAG 知识库,解析质量直接决定检索准确率。之前很多项目卡在这里,换了更好的解析工具之后效果立竿见影。
如果你想搭文档审核的 Agent,比如合同合规审查、发票识别核对、政策文件提取关键信息,这类项目的核心之一就是底层文档解析的准确性。审核 Agent 读到的如果是乱码,它审出来的结论参考价值就很有限。
当然,如果你就是想把公司积压多年的纸质档案、扫描件数字化,PaddleOCR-VL 处理复杂场景(倾斜、阴影、模糊)的能力也比传统方案好不少。
只要你的 AI 应用需要”读文件”,这个工具都值得试试。
0.9B 打过 70B,这意味着什么
我觉得 PaddleOCR-VL 这件事,背后有一个值得单独说说的信号。
一个 0.9B 的专用小模型,文档解析能力超过了几十倍参数量的通用大模型。这不是偶然。
“参数越多越厉害”这个逻辑,在通用场景里勉强成立,但到了具体的垂直任务,就未必了。文档解析需要的是对版式的理解、对特定内容的训练数据,而不是什么都能做的万金油。专注做一件事,把这件事训练到极致,有时候比堆参数更有效。
这个思路在其他 AI 落地场景里同样适用。与其花钱调用昂贵的大模型做所有事,不如找几个在各自领域里真正好用的专用工具,组合起来用。
PaddleOCR-VL 现在是开源免费的,代码在 GitHub 上,模型权重在魔搭社区能下载到。如果你在做 AI 应用,文档解析这个环节迟早要面对,不妨现在就看看这个方案。
就这些,东哥说AI,我们下期见。