 夜雨聆风
夜雨聆风





快手AI Agent应用开发面经(附答案)
Q1:测试时扩展(test-time scaling)是什么?怎么实现?
测试时扩展(Test-Time Scaling,简称TTS)是提升大型语言模型(LLM)推理性能的一种方法,其核心思想是在模型推理阶段动态分配更多计算资源,以获取更优的答案。
✨常见的实现方法包括:
1.多次采样(外部扩展):对同一输入进行多次推理,取平均或投票结果。
2.自我验证(内部扩展):推理过程中,模型自身进行验证,并选择最佳推理结果。
3.CoT(内部扩展):模型在推理过程中,通过生成推理步骤,并使用这些步骤来生成推理结果。
4.延长思考步骤(内部扩展):在 CoT 中加入特殊指令(如”Wait”)强制模型延长思考时间,纠正错误思路。
例如:模型尝试提前输出答案时,追加”Wait”标记使其继续推理,直至达到计算预算上限。
Q2:基于 Transformer 架构的大模型在推理时显存主要消耗在哪些方面?
推理时显存主要消耗在如下三个方面。
1.模型参数:占用 2x 模型参数量 GB 的显存。
2.激活值:Transformer 模型在推理时存储每一层的激活值,通常占用 2 x 批大小 x 序列长度 x 层数 x 隐层维度 GB 的显存。
3.KV-Cache:{k;}t-1,{ui}1=1,因为基于Transformer 架构的模型在串行推理时每个时间步的输出O =9t*∑-1k2*0,在计算o 时需要用到{k:1w1-1因此可以在每一步把k;和v;缓存起来,方便下一步使用。
Q3:Deepseek-R1 训练的四个阶段?
DeepSeek-R1 的训练流程分为四个核心阶段,通过两轮有监督微调(SFT)和两轮强化学习(RL)的交替优化,逐步提升模型的推理能力、通用性及安全性。
第一阶段:冷启动监督微调(Cold Start SFT)
-
推理数据:采用拒绝采样方法,从 RL 模型中生成响应,筛选高质量答案(约 60 万条推理数据)。 -
通用数据:复用 DeepSeek-V3 的 SFT 数据集(约 20 万条),覆盖写作、问答、角色扮演等任务。 -
两轮监督微调:第一轮仅使用 60 万条拒绝采样数据微调模型,第二轮用全部的 80 万条数据微调模型,平衡推理与非推理能力。
-
推理任务:沿用规则奖励(如数学答案验证)。 -
通用任务(如对话、写作):使用神经奖励模型评估”无害性”和”实用性”。
Q4:你认为好的大模型提示词应该是什么样的?
好提示词的黄金公式 = 清晰角色 + 结构化任务 + 强约束 + 可验证。
🔘角色:明确模型身份(如”编程助手”)
🔘结构:使用 TAG(Task + Action + Goal) / COS(Context + Objective + Steps) 框架分步拆解
🔘约束:指定格式、长度、安全红线
🔘验证:通过人工评审及指标量化效果
Q5:大模型的灾难性遗忘问题是什么?怎么解決?
大模型的灾难性遗忘(Catastrophic Forgetting)是指模型在适应新任务或新数据时,对先前学到的知识大面积遗忘。
解决方案:
🔘 重放( Replay ):在微调数据中混入一部分预训练数据,让模型在学习新知识的同时”复习”旧知识。
🔘参数高效微调( PEFT ):如 LORA 、 QLORA 。只微调模型的一小部分参数(适配器),冻结大部分原始参数,从而最大程度保留预训练知识。
🔘正则化方法:如 EWC (弹性权重巩固),对预训练阶段重要的参数增加一个正则项,限制其在微调时发生剧烈变化。
Q6:对比 Deepspeed 和 Megatron 的区别?
Deepspeed 和 Megatron 的差异主要体现在并行策略优化、硬件适配性和功能定位等方面。
1.并行策略优化:
-
Deepspeed:更擅长数据并行,通过ZeRO技术在不同设备间分片数据,减少显存冗余,适合大规模数据并行场景。 -
Megatron:更擅长模型并行,尤其在处理超大模型(如百亿参数以上)时,通过张量并行和流水线并行有效解决单卡显存不足问题。
2.硬件适配性:
-
Deepspeed:支持多种硬件平台(如 CPU 和 GPU),并且可以将优化器状态卸载到 CPU 上,适合资源受限的环境。 -
Megatron:深度优化 NVIDIA GPU,特别是 Tensor Core 加速,依赖 NCCL 通信库,主要在高性能计算集群(如 DGX/A100)上表现优异。
3.适用场景:
-
Deepspeed:适合需要大规模数据并行训练、显存优化需求高的场景,如训练中等规模模型或需要快速迭代的实验。 -
Megatron:适合训练超大规模模型(如千亿参数以上),尤其在NVIDIA硬件集群上,能充分发挥硬件性能优势。
Q7:Decoder-only 架构的注意力矩阵为什么是满秩的?满秩注意力矩阵有什么优势?
Decoder-only架构采用因果注意力机制,通过因果掩码确保每个位置只能关注当前及之前的 token,其注意力矩阵是严格的下三角矩阵,因为三角矩阵的行列式 = 对角线元素之积,又 Softmax 保证了注意力矩阵中所有元素均为正,因此对角线元素也均为正 -> 行列式恒为正 -> 矩阵满秩。
满秩注意力矩阵的优势包括:
-
更强的表达能力:满秩矩阵意味着矩阵的列(或行)向量线性无关,能够更充分地捕捉输入序列中的信息关系和模式,避免因矩阵秩不足导致的信息丢失或表达能力受限。
-
更大的模型容量:注意力矩阵中没有冗余参数(因为行/列向量线性无关,彼此无法线性表示),能够更好地利用参数空间,提升模型的表达能力。 -
工程实践优势:相比与 Encoder-Decoder 模型,Decoder-only 的泛化能力更强(GPT 的 Zero-shot 能力强于 T5),微调时收敛更快。
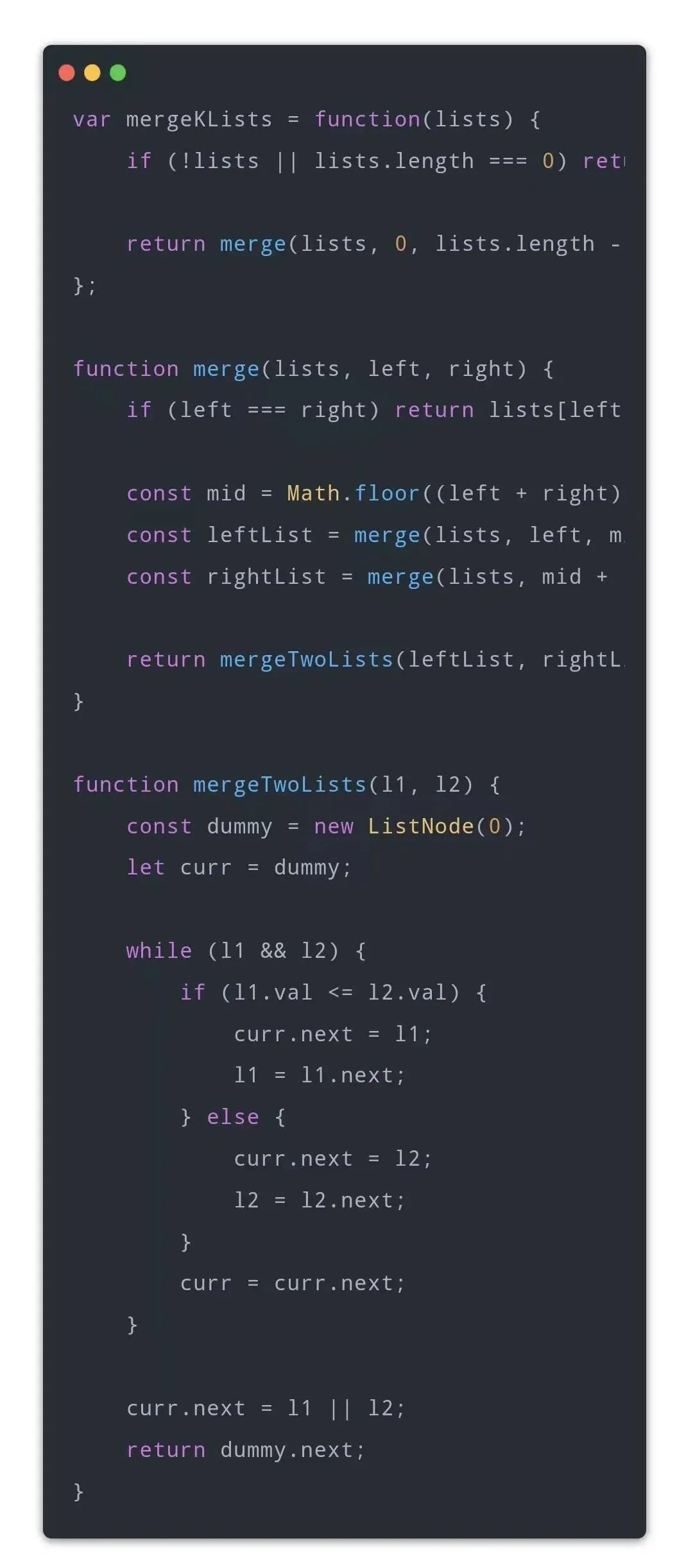
Q8:代码:23.合并 K 个升序链表
📚如果需要项目提升或面试辅导
📳欢迎添加微信: Mr_Lin-07-21
后续会进行更多算法面经和技术干货分享