 夜雨聆风
夜雨聆风





AI项目面试技巧:如何把AI项目讲得让面试官印象深刻
AI项目面试技巧:如何把AI项目讲得让面试官印象深刻
适读人群:正在求职或准备跳槽的Java工程师,简历上有AI项目经历
阅读时长:约15分钟
文章价值:掌握AI项目面试的叙述框架,从”我用了Spring AI”升级到”我解决了XXX挑战”
那个答到面试官睡着的候选人
我在星球里做简历诊断,看过快两百份AI工程师简历,陪聊过不少面试复盘。
有个叫阿明的同学,做了一年多的RAG系统,技术栈很不错:Spring AI、Milvus、GPT-4、Langchain4j都用过。面试前我帮他模拟了一轮,他是这么介绍项目的:
“我们做了一个RAG系统,用Spring AI框架,调了OpenAI的接口,做了文档向量化,存到Milvus里,用户问问题的时候检索相关文档,然后塞到prompt里让GPT-4回答……”
我说停停停,你讲了一分钟,讲的全是”做了什么”,没有一句是”遇到什么难题、怎么解决的”。
面试官听这种介绍,跟听你背技术文档一样,哈欠连天。
好的面试表达,是讲故事,不是念PPT。
面试官真正想听什么
先搞清楚面试官的心理模型。他们问AI项目,核心想评估三件事:
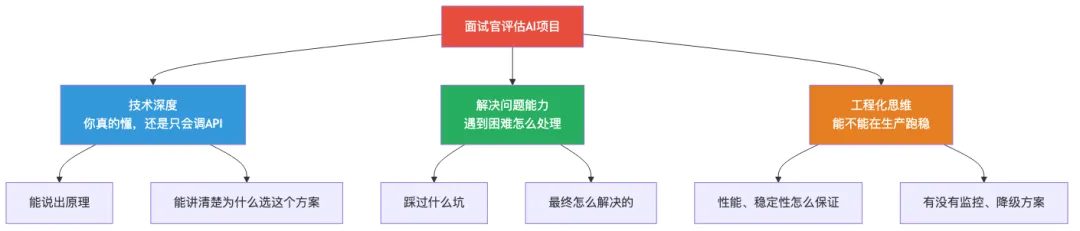
看清楚了,面试官不是要你背框架文档,他们要的是你的思考和判断。
STAR-T框架:AI项目专用叙述结构
通用的STAR框架(情境-任务-行动-结果)用在AI项目上不够用,我加了一个T——Trouble(技术挑战)。

重点在TR(技术挑战)和A(解决方案),这是区分”用过”和”懂”的分水岭。
五类高频问题的回答模板
问题1:「介绍一下你的AI项目」
差的回答:把技术栈念一遍。
好的回答模板:
“我们做的是[公司类型]的[业务场景]AI系统。核心解决的问题是[痛点描述]。
我在项目中负责[具体模块]。最有挑战的部分是[技术难点]——当时遇到的问题是[具体描述],最初的方案有[局限性]。
我们最终通过[解决方案]解决了这个问题,上线后[量化指标:响应时间/准确率/成本]改善了[具体数值]。”
阿明改版后的表达:
“我们做的是一个知识库问答系统,给内部运营用,以前他们查政策要翻几百页Word文档,现在直接问AI。
我负责整个RAG流程的技术选型和实现。最难的部分不是RAG本身,是召回质量——早期用余弦相似度检索,对于口语化问题命中率只有60%多,经常召回一堆不相关的文档片段,导致AI回答驴唇不对马嘴。
我们做了三个改进:一是加了BM25做关键词混合检索;二是在嵌入模型上做了行业语料的fine-tuning;三是加了一个reranker模型做二次排序。最终召回准确率从62%提升到了89%,用户满意度评分从3.2提到4.6。”
这个版本里,有具体数字、有技术细节、有迭代过程——面试官一听就知道这不是背出来的。
问题2:「你们RAG系统的召回效果怎么保证?」
这是深度问题,要展示你的体系化思考:
// 你可以结合代码讲解你的混合检索方案@Service@Slf4jpublicclassHybridSearchService {privatefinalVectorStore vectorStore;privatefinalElasticsearchClient esClient;privatefinalRerankService rerankService; /** * 混合检索:向量相似度 + BM25关键词 */publicList<Document> hybridSearch(String query, int topK) {// 1. 向量检索(语义相似)List<Document> vectorResults = vectorStore.similaritySearch(SearchRequest.query(query).withTopK(topK * 2) );// 2. BM25关键词检索(精确匹配)List<Document> bm25Results = bm25Search(query, topK * 2);// 3. RRF融合排序(Reciprocal Rank Fusion)List<Document> merged = reciprocalRankFusion(vectorResults, bm25Results);// 4. Reranker二次精排return rerankService.rerank(query, merged, topK); } /** * RRF融合算法:综合两路检索结果的排名 */privateList<Document> reciprocalRankFusion(List<Document> list1, List<Document> list2) {Map<String, Double> scoreMap = newHashMap<>();int k = 60; // RRF常用参数for (int i = 0; i < list1.size(); i++) {String id = list1.get(i).getId(); scoreMap.merge(id, 1.0 / (k + i + 1), Double::sum); }for (int i = 0; i < list2.size(); i++) {String id = list2.get(i).getId(); scoreMap.merge(id, 1.0 / (k + i + 1), Double::sum); }// 按融合分数排序Map<String, Document> docMap = buildDocMap(list1, list2);return scoreMap.entrySet().stream() .sorted(Map.Entry.<String, Double>comparingByValue().reversed()) .map(e -> docMap.get(e.getKey())) .filter(Objects::nonNull) .collect(Collectors.toList()); }}这段代码配合你的解释,面试官立刻能判断你对RAG的理解深度。
问题3:「遇到过LLM幻觉问题吗?怎么处理的?」
不能说:”没有啊,没遇到过”(面试官认为你根本没在用)
要这样说:
“遇到过,而且是个持续治理的问题,不是一次性解决的。
我们在贷款审核场景里,有次AI把客户甲的部分信息混入了客户乙的回答里,这是典型的幻觉问题。
我们做了几层防护:首先在prompt层,明确要求AI只能基于提供的文档回答,不允许推断;然后在后处理层,加了一个验证步骤,让AI在回答里标注每句话的来源文档;最后在监控层,用一个小模型做答案一致性检测,对低置信度的回答触发人工复核。
这套方案下来,幻觉导致的投诉从每百次对话3.2次降到了0.4次。”
这个回答展示了你的工程化思维:不是靠prompt魔法一劳永逸,而是多层防护+持续监控。
问题4:「你们的LLM调用成本怎么控制?」
这个问题暴露你有没有做过真正的生产系统:
// 聊聊你的缓存+成本控制方案@Service@Slf4jpublicclassCostAwareChatService {privatefinalChatClient chatClient;privatefinalSemanticCacheService semanticCache; /** * 带语义缓存的AI调用 * 相似问题命中缓存,省掉90%的重复token消耗 */publicString chatWithCache(String userId, String question) {// 1. 先查语义缓存Optional<String> cached = semanticCache.get(question);if (cached.isPresent()) { log.info("命中语义缓存: question={}", question);return cached.get(); }// 2. 缓存未命中,调用LLMString response = chatClient.prompt() .user(question) .call() .content();// 3. 写入缓存(TTL 1小时) semanticCache.put(question, response, Duration.ofHours(1));return response; } /** * 根据问题复杂度选择不同模型 * 简单问题用便宜模型,复杂问题用贵的 */publicString chatWithModelSelection(String question) {ModelTier tier = classifyQuestion(question);returnswitch (tier) {caseSIMPLE -> callModel("gpt-3.5-turbo", question); // 低成本caseCOMPLEX -> callModel("gpt-4o", question); // 高质量caseULTRA -> callModel("gpt-4o", question); // 最高质量 }; }}“我们做了两件事控制成本:一是语义缓存,同类问题重复率很高,缓存命中率稳定在35%,省掉了1/3的费用;二是模型分级路由,把问题分成简单/复杂两档,简单问题用GPT-3.5,复杂问题才用GPT-4。这两项组合,整体token成本降了约55%。”
问题5:「如果LLM接口挂了,你们系统怎么办?」
这是考验你有没有生产运维经验的问题:
好的回答要提到:
-
超时设置(别让一个请求吊死) -
重试策略(指数退避,别打死LLM) -
熔断降级(挂了就返回降级回答) -
多模型切换(主用OpenAI,备用国内大模型)
@ConfigurationpublicclassResilientChatConfig {@BeanpublicChatClient chatClient(ChatClient.Builder builder) {return builder .defaultAdvisors(newRetryAdvisor(RetryConfig.builder() .maxAttempts(3) .waitDuration(Duration.ofSeconds(1)) .exponentialBackoff(2.0) .build()),newFallbackAdvisor("很抱歉,AI服务暂时不可用,请稍后重试或联系客服。") ) .build(); }}简历上怎么写AI项目
好的简历描述要有三层:做了什么、遇到什么挑战、取得什么结果。
差的写法:
使用Spring AI框架开发智能问答系统,集成OpenAI GPT-4,实现RAG检索增强生成功能
好的写法:
主导研发基于RAG架构的内部知识库问答系统(Spring AI + Milvus + GPT-4)
– 针对召回精度不足问题,设计混合检索方案(向量+BM25+Reranker),将召回准确率从62%提升至89%
– 通过语义缓存+模型分级路由,将单次对话token成本降低55%
– 搭建完整的AI调用监控体系,P99延迟控制在2.3秒以内
对比看,第二个版本里有具体问题、具体方案、具体数字,这才是面试官想看的。
最后一条:不要背答案
所有这些模板,只是给你一个结构,不是让你背台词。
面试官都是有经验的,一听就知道你是真的踩过坑还是临时包装的。
我给阿明的建议是:把你真实遇到的每一个坑都整理成STAR-T格式,每个坑写一页A4纸,写10个,然后开始面试。
技术有深度,故事讲得好,offer自然来。
觉得有收获,点个在看让更多人看到。
还没关注的,欢迎关注「老张聊AI转型」,设为星标不错过每一篇更新。
遇到类似问题或有不同思路,欢迎在评论区留言,我认真回每一条。
本文由「老张聊AI转型」原创发布,转载请注明出处