 夜雨聆风
夜雨聆风





你的AI编程助手,有一半代码被扔进了垃圾桶
STANFORD · SWE-CHAT · APR 2026
你的AI编程助手有一半代码被扔进了垃圾桶
Stanford团队追踪6000个真实编码Agent会话,首次揭示AI编程的真实效率与安全隐患

▲ SWE-chat: 首个真实编码Agent交互数据集 (Stanford SALT-NLP, 2026)
一、你以为的AI编程,可能全是错觉
你打开Claude Code,输入”帮我修复这个bug”。Agent开始忙碌,读取文件、运行测试、修改代码。几分钟后,一个完美的pull request出现在你的仓库里。你满意地merge了。
这是AI编码的理想画面。也是各大评测排行榜试图证明的故事。每次新的编码Agent发布,社交媒体上都会充斥着”AI又完成了XX%的编程任务”的标题。SWE-bench的分数不断攀升,METR的报告声称Agent已经能完成50%人类需要12小时才能完成的编程任务。所有人都在讨论”vibe coding”——把代码全权交给AI,人类只负责验收。
但有一个问题:这些评测数据全部来自精心设计的实验室环境。SWE-bench用GitHub上已经解决的issue作为测试用例,给Agent提供完整的上下文和明确的指令。这就像考试时老师把题目、答案格式、甚至解题思路都告诉你了,然后宣布你考了满分。
Stanford大学的SALT-NLP团队做了一件之前没人做过的事:他们不测Agent在curated benchmark上的表现,而是追踪了6000个真实开发者使用编码Agent的完整会话。从200多个开源仓库中,记录了63,000条用户指令和355,000次Agent工具调用。这不是实验室里的模拟测试,而是真实开发者在真实项目中与AI交互的完整记录。
结果?和评测排行榜上的故事,差距大得惊人。

▲ 你以为的AI编程 vs 数据揭示的现实:44%代码被丢弃,9倍安全漏洞,39%回合被纠正
二、SWE-chat:从真实世界采集的数据
SWE-chat的数据采集方式很巧妙。团队开发了一个叫Entire.io的开源CLI工具,开发者安装后,工具会自动记录编码Agent的完整会话——包括用户指令、Agent回复、工具调用序列、token消耗,甚至代码diff的行级归因(哪行代码是人写的,哪行是Agent写的)。
行级归因是这个数据集最核心的创新。之前的所有研究都无法回答”Agent写的代码有多少真正被采纳了”这个问题。SWE-chat通过链接session transcript和git commit,精确追踪了每一行代码的命运:是直接被commit了,还是被用户修改了,还是被直接删除了。
这不是实验室里精心设计的测试场景。这是真实开发者在真实仓库里做的真实工作。数据涵盖5个主流编码Agent:Claude Code(占85%,目前最广泛使用)、OpenCode、Gemini CLI、Cursor和Factory AI Droid。
总计2.7百万条日志事件。而且这是一个”活数据集”——采集管道在持续发现和处理新会话。这意味着SWE-chat不只是一次性的研究,而是一个可以持续追踪编码Agent演进的基础设施。

▲ SWE-chat数据集规模:6000 sessions, 63K prompts, 355K tool calls, 200+ repos
三、用户到底在让Agent做什么?不是写代码
第一个反直觉发现:用户最常让Agent做的事,不是写代码,而是理解代码。
在所有用户指令中,”理解现有代码或行为”占19.0%,是最常见的具体意图。创建新代码只占13.4%,和Git操作并列第三。调试占13.0%。重构和写测试分别只占6.5%和5.2%。还有26.6%的指令被归类为”其他”——说明用户的需求远比评测中预设的”修复issue”要复杂得多。
这意味着什么?现有的编码Agent评测——SWE-bench、SWE-agent、Aider leaderboard——几乎全部聚焦于”生成patch修复issue”。但真实世界中,代码理解才是最大的需求。评测体系完全忽略了这个维度。一个在SWE-bench上得分很高的Agent,可能在”帮我理解这段代码”的任务上表现糟糕——但我们永远不会知道,因为评测根本不测这个。
更有趣的是Agent的工具调用分布:三分之一的工具调用是bash命令(主要是git操作),而不是编辑文件。Agent的工作流程通常是:先读取和搜索代码,然后修改文件,最后执行构建命令。这和评测中”直接生成patch”的模式完全不同。真实开发中,Agent花大量时间在”理解环境”上,而不是”产出代码”上。
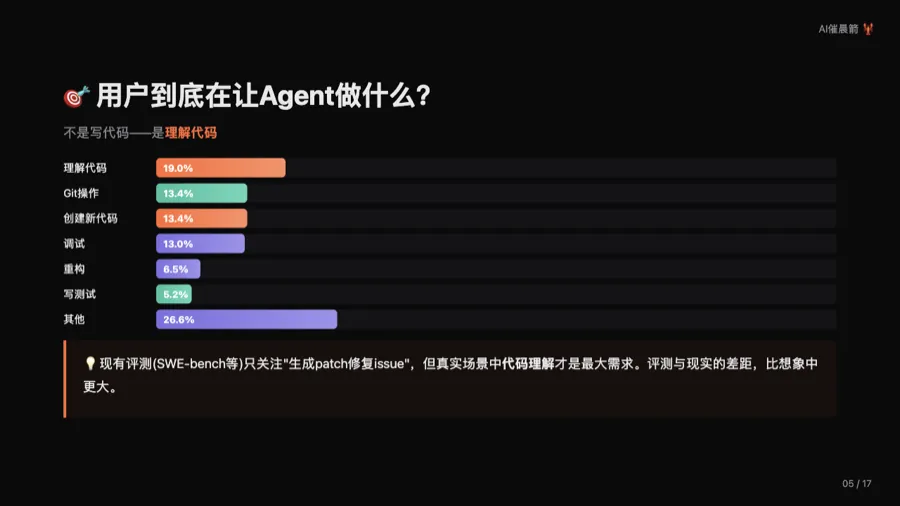
▲ 用户意图分布:理解代码(19%) > 创建新代码(13.4%) = Git操作(13.4%) > 调试(13%)
四、极端双峰分布:要么全权委托,要么亲自动手
第二个关键发现:编码模式呈现极端双峰分布。
研究团队根据Agent贡献的代码比例,定义了三种编码模式:
纯人工编码(22.7%):Agent只做辅助——理解代码、调试、Git操作,所有提交代码由人类编写。这类用户把Agent当作”智能搜索引擎”或”高级IDE”,而不是代码生成器。
协作编码(36.5%):人和Agent共同编写代码,Agent贡献0%到99%的代码行。这是真正的”人机协作”——Agent写一部分,人写一部分,互相补充。
Vibe Coding(40.8%):≥99%的提交代码由Agent编写,人类只做审查。这是Andrej Karpathy推广的概念——”让AI写代码,你只管验收”。
双峰分布意味着:用户要么完全信任Agent(vibe coding),要么完全不信任(纯人工)。中间态(协作编码)反而最少。这暗示了一个深层问题:Agent还没有好到让人”半信半疑”地合作的程度——要么你放手让它干,要么你自己来。这种两极分化可能反映了当前编码Agent的能力瓶颈:它们在某些任务上足够好,让人愿意全权委托;但在另一些任务上又不够可靠,让人宁愿自己写。
更值得注意的是趋势:在三个月的观察窗口内,vibe coding的占比从20%翻倍到了40%以上。用户正在加速”放权”。但后面的数据表明,这可能是一个危险的方向。

▲ 编码模式双峰分布:纯人工22.7%,协作36.5%,Vibe Coding 40.8%(3个月内翻倍)
五、Agent写的代码,一半活不过Commit
这是最震撼的发现之一:只有44.3%的Agent产出代码最终被用户采纳进commit。超过一半的Agent劳动成果被丢弃。
具体来说,Agent写的代码有四种命运:
• 44.3%存活到commit(用户直接采纳)
• 9.3%被Agent自己覆盖(用户pushback后Agent重写)
• 42.2%被用户覆盖(用户修改了Agent的代码)
• 4.2%被用户直接删除
在协作编码模式下,情况更极端:用户会覆盖46.9%的Agent代码。这说明协作模式下的用户在仔细审查和修正Agent的输出,不是被动接受。
Vibe coding的存活率更高(59%),但论文作者谨慎地指出:这可能不是因为Agent写得更好,而是因为用户审查得更松。一个更危险的解读是:vibe coder可能在”盲目信任”Agent的输出。

▲ Agent代码存活率:只有44.3%被采纳,42.2%被用户覆盖,9.3%被Agent自己重写
六、Vibe Coding:最贵、最慢、最危险
如果说前面的发现还只是”有趣”,那成本和安全数据就是”令人不安”了。
成本对比(每100行提交代码):
• 协作编码:68K tokens,$0.05,4.8分钟 ⭐ 最优
• 纯人工:102K tokens,$0.07,8.6分钟
• Vibe coding:204K tokens,$0.13,12.6分钟
Vibe coding的token消耗是协作编码的3倍,时间是2.6倍。看起来”省事”的全权委托,实际上代价最高。
类比一下:这就像你雇了一个速度很快但粗心的实习生。他写得快,但你改得更多。最终算下来,不如你自己写,或者跟他协作。

▲ 每100行代码成本:Vibe Coding 204K tokens/$0.13/12.6min vs 协作编码 68K/$0.05/4.8min
安全数据更令人担忧:
研究团队用Semgrep静态分析工具扫描了每个commit前后的代码快照,统计引入的安全漏洞数量(包括路径遍历、命令注入、不安全格式字符串、SQL注入等)。
• 纯人工编码:每1000行引入0.08个漏洞
• 协作编码:每1000行引入0.14个漏洞
• Vibe coding:每1000行引入0.76个漏洞
Vibe coding引入的漏洞是纯人工的9倍,是协作编码的5倍。虽然vibe coding也修复了更多漏洞(0.52 vs 0.04),但净增量(+0.24)远超其他模式。
这意味着:vibe coding在加速开发的同时,也在系统性地放大安全风险。对于企业级部署,这可能是一个不可忽视的隐患。

▲ 安全漏洞对比:Vibe Coding引入0.76个/1000行(纯人工的9倍),净增量+0.24是最高的
七、用户每3轮就要纠正一次Agent
最后一个关键发现揭示了人-Agent交互的真实动态:用户在39%的回合中对Agent输出进行了pushback——包括纠正、拒绝和失败报告。
这意味着:平均每3轮对话,用户就要纠正一次Agent。即使在vibe coding模式下(理论上用户最”放手”的模式),pushback率仍然高达30.2%。
更令人不安的是Agent的”沉默”:Agent主动询问用户的比例只有1.1%-2.6%。99.9分位的turn时长超过100分钟——Agent可以自主工作超过一个半小时,但几乎从不中途停下来问用户”你确定这样做对吗?”
这是一个交互设计的根本性缺陷。想象一下:一个实习生在你办公室闷头干了一个半小时,中间一次都没问过你问题。你会觉得他很独立,还是会担心他走偏了?
用户的应对方式是:5%的回合被硬中断(直接打断Agent),39%的回合在Agent完成后被纠正。用户不是被动的——他们在主动审查、修正、甚至阻止Agent的行为。

▲ 用户监督行为:39%回合pushback,Agent仅1.4%主动询问,5%回合被硬中断
八、深度分析:评测与现实的五个根本性脱节
SWE-chat的数据揭示了一个更深层的问题:现有编码Agent评测体系与真实使用场景之间存在系统性的脱节。
脱节一:任务定义。评测假设任务有明确定义和完整指令(如SWE-bench的GitHub issue)。但现实中,用户经常迭代修正指令——47%的用户即使在vibe coding中也是”专家挑剔者”,在看到Agent输出后才细化需求。
脱节二:能力维度。评测只关注”生成patch修复issue”。但真实场景中,代码理解(19%)才是最大需求,Git操作(13.4%)和调试(13%)同样重要。评测完全忽略了这些维度。
脱节三:交互模式。评测假设一次性完成(one-shot)。但现实中,多轮交互、反复纠正是常态。Agent的”编码效率”(44.3%)远低于评测中的”任务完成率”(50%+)。
脱节四:评价标准。评测只看最终结果(pass/fail)。但现实中,用户关心的是”我需要改多少才能用”——42.2%的Agent代码被用户覆盖,这个维度在评测中完全缺失。
脱节五:人的角色。评测把人简化为”指令发送者”。但现实中,人是主动的审查者、修正者、甚至阻止者。39%的pushback率说明:人-Agent协作不是”人下指令→Agent执行”的线性流程,而是一个持续的协商过程。

▲ 评测vs现实的五个脱节:任务定义、能力维度、交互模式、评价标准、人的角色
九、Vibe Coding的三重悖论
把所有数据放在一起,vibe coding呈现出一个令人不安的悖论结构:
悖论一:看似省力,实则最费。 Vibe coding的token消耗是协作的3倍,时间是2.6倍。用户以为”把活交给AI就行”,但实际上付出的总成本(token+时间+审查)远高于协作模式。
悖论二:看似高效,实则危险。 9倍安全漏洞意味着vibe coding在加速开发的同时,也在系统性地积累技术债务。短期看效率提升,长期看可能是安全隐患的定时炸弹。
悖论三:看似放权,实则焦虑。 即使在vibe coding模式下,47%的用户仍然是”专家挑剔者”,30.2%的回合有pushback。用户并没有真正”放手”——他们在全权委托的同时,仍然在紧张地审查和纠正。
这三个悖论指向同一个结论:vibe coding不是AI编码的未来,而是一个过渡阶段的幻觉。它看起来美好,但数据揭示的代价远超预期。

▲ Vibe Coding三重悖论:3倍token消耗、9倍安全漏洞、47%用户仍是”挑剔者”
十、批判性思考:这篇论文的局限
和所有研究一样,SWE-chat也有自己的局限。论文作者自列了多个问题,但我认为还有更深层的质疑值得讨论:
1. 早期采用者偏差可能被低估了。 只有主动opt-in的开源开发者才会被记录。这群人比一般用户更懂AI、更有技术能力、更可能有耐心与Agent交互。如果连这群人的数据都显示44%代码被丢弃,那普通用户的情况可能更糟。企业内部开发者、非技术用户、甚至学生群体的使用模式可能完全不同。
2. 失败会话的系统性缺失是最严重的偏差。 用户放弃的session不会被commit,也就不会被Entire.io记录。这意味着90%的session成功率可能被严重高估。真实的失败率可能远高于10%。想象一下:你让Agent做一件事,它搞砸了,你直接关掉窗口重新开始——这个失败的session永远不会出现在数据集中。
3. Claude Code主导(85%)意味着结论可能不适用于其他Agent。 Cursor的交互模式、Gemini CLI的行为特征可能完全不同。但在Claude Code成为事实标准的当下,这个偏差的影响可能有限。不过,随着更多Agent进入市场,跨Agent比较将成为重要的研究方向。
4. “语义存活率”盲区。 Agent写的代码被用户改写后commit,行级归因算”人写的”。但Agent的思路、架构设计、算法选择可能保留了。真实的Agent贡献度可能被低估——这意味着44.3%的”编码效率”可能不是全部故事。一个Agent可能写了错误的实现,但指出了正确的方向,用户在此基础上修正——这种”间接贡献”在行级归因中完全不可见。
5. LLM-as-judge的可靠性问题。 论文用LLM标注session成功率和用户意图分类。但LLM本身就可能犯错,特别是在理解复杂编码上下文时。论文承认了这个问题,但仍然依赖LLM标注来实现大规模处理。这是一个务实但有代价的选择。

▲ 四个局限:早期采用者偏差、失败会话缺失、Claude主导、语义存活率盲区
十一、行业影响:对每个做AI编码的人都有意义
SWE-chat的发现对多个层面有直接影响:
对评测体系:需要新的benchmark——不只测”能不能完成任务”,还要测”用户需要改多少”、”引入多少漏洞”、”花多少token”。SWE-chat数据集本身就可以作为新评测的基础设施。
对企业部署:vibe coding的9倍安全风险可能促使企业限制全自动编码。强制协作模式+代码审查流程=更安全的AI编码策略。企业安全团队可能会引用这篇论文来制定AI编码使用规范。
对Agent产品设计:1.4%的主动询问率是交互设计的重大缺陷。Agent应该学会在关键节点停下来问用户,而不是闷头干100分钟。”主动沟通”可能比”更强能力”更重要。
对每个使用AI编码的开发者:协作编码是最优模式——最便宜、最快、最安全。不要完全放权。你的审查不是多余的,是安全网。

▲ 行业影响:评测体系需要重构、企业安全策略需要调整、Agent交互设计需要改进
十二、结语:协作,不是替代
SWE-chat最重要的发现不是”Agent有多强”或”Agent有多弱”,而是揭示了一个被所有人忽略的事实:AI编码的最优模式不是全自动,也不是全人工,而是高质量的协作。
协作编码在所有维度上都是最优的:最便宜($0.05/100行)、最快(4.8分钟/100行)、最安全(0.14漏洞/1000行)。但现有评测体系和产品设计都在推动vibe coding——方向可能反了。
与其让Agent跑得更快、更远、更自主,不如让它学会协作得更好——在关键节点停下来问用户,在不确定时主动沟通,在犯错时及时承认。
最好的AI编程助手,不是一个能替代你的Agent,而是一个能和你协作的伙伴。
🦞

▲ 与其让Agent跑得更快,不如让它协作得更好 — AI催晨箭 · 2026.04.23
论文:arXiv 2604.20779 | 数据:swe-chat.com | 机构:Stanford SALT-NLP