 夜雨聆风
夜雨聆风





AI 法律能力怎么"量"
TECHNICAL NOTE / 2026.04.23
AI 法律能力怎么”量”
一份关于 Rubric + LLM-as-Judge 的技术分享 · 以纽约州滑倒案为例
这篇文章做了一件事:用一道纽约州超市滑倒题,让 5 家大模型裸答,请纽约执业律师写出标准答案,然后用 7 维评分量规逐维打分。
参赛选手——Claude Opus 4.7、GPT-5.4、Qwen3.6 Max Preview、Kimi K2.6、GLM 5.1。全部关掉搜索、深度思考、工具调用,只测基础模型的本体推理能力。
先看案例,再讲方法。
01 HYPO
题面 · Palmer v. Stop & Shop(纽约州)
选场所责任(premises liability)不是普通过失——因为它是过失之诉在商业场所的具体化身,同时叠加 invitee 身份认定 + actual/constructive notice + recurring condition doctrine + 多种抗辩 几个推理节点。推理链最长,模型能力差距能拉开。1L 期末经典题型,网上”正解”密集,judge 打分有锚。
选纽约州不选加州——纽约州有独特的 recurring condition doctrine(反复出现危险情况原则):被告对反复出现的危险有实际知悉(actual knowledge)时,原告不必就具体缺陷再证 notice。匹配题面埋的”6 个月内同一通道 3 起投诉”钩子。纽约州的 CPLR Article 16 在共同侵权人(joint tortfeasors)过错分摊上有独特的 50% 阈值规则,进一步拉开答卷水平。
题面(原文 · English)

题面(中文译本 · Chinese)

题面里每一个事实都对应一个考点
题面不是随便编的。每处细节都对应一个推理节点——模型能否识别它、能否挂到正确的法律规则上,决定它的分数。
· 考点 1 · “20 分钟前顾客报告” → 测 actual notice(实际知悉)。模型应该指出 Stop & Shop 通过员工 Emma 对原始葡萄洒落已有实际知悉。
· 考点 2 · “过去 6 个月 3 起滑倒投诉” → 测 constructive notice + recurring condition doctrine。模型应该引出纽约州的独特规则——对反复出现的危险有实际知悉时,原告不必就具体缺陷再证 notice。
· 考点 3 · “只在北端放一个警示锥、南端无警示、中途离开” → 测 breach of duty。这些都是对 Stop & Shop 自身 SOP 的违反,是举证过失最直接的证据。
· 考点 4 · “Paula 从南端进入” → 测 duty/breach 的反向确认。Paula 从南端进入这一事实本身恰恰是”Shop 未在南端设警示”的过失证据,不是 Paula 自身的过错因子——这是一个容易判错的细节,稍后会在 rubric 维度 6 再次强调。
· 考点 5 · “Paula 看手机 + 穿人字拖” → 测 比较过失(comparative negligence)抗辩。这两项才是被告用来主张 Paula 自担部分责任的合法事实。
· 考点 6 · “Bob 从反方向推车撞到 Paula” → 测 causation(因果)中的 intervening cause 分析。模型应该讨论 Bob 的撞击是可预见介入原因(foreseeable intervening cause)还是超越原因(superseding cause)——前者不切断 Stop & Shop 的责任,后者则切断。纽约州用 Derdiarian v. Felix Contracting 的标准。
· 考点 7 · “$24,000 医疗 + $4,500 误工 + 精神痛苦” → 测 damages 区分与分摊。模型应该区分经济损害(economic)与非经济损害(non-economic),并套用 CPLR Article 16 的 50% 阈值规则——被告过错超过 50% 时非经济损害也 joint-and-several(各被告之间连带),反之则仅 several(各被告按比例单独承担)。
· 考点 8 · “皇后县最高法院(Supreme Court, Queens County)” → 测 法域识别。纽约州”最高法院”其实是州一审法院,不是最高上诉法院。模型应该默认适用纽约州实体法。
这 7 个推理节点对应 rubric 的 7 个维度(见 Part 06)。把题面里任何一个钩子拿掉,对应维度就考不出来。
“不许编造”那句附加约束不是装饰——是 rubric 扣分的直接触发条件。法律分析必须引真实权威,编造判例或条文 = 职业风险。rubric 设定——任一虚构权威直接 -1,不可通过其他维度补偿。
02 GOLDEN
参考答案 · 律师 memo
本文的金答案是人机协作的产物——作者(JD + MLE 背景,法学院训练刻在骨子里但已离开 practice 多年)、纽约执业律师翁磊、以及 Harnessed AI(Claude Code + Gemini)三方协作完成,经人工校验定稿。这本身就是这篇文章想说明的一件事:掌握了方法论的人,即使不是某个法域的执业专家,也能和 AI + 领域律师协作产出高质量的法律工作成果。
金答案以 Associate-to-Partner 格式的 preliminary memo 呈现。Gemini Judge 以此 memo 为 reference 对 5 份候选答案打分。完整 memo 原文见文末 Part 12 附录 A。
律师 memo 的分析框架可以归纳为六个环节:
|
|
|
|
|---|---|---|
| Duty | Basso
|
Basso v. Miller
|
| Breach |
|
Gordon
|
| Causation |
|
Derdiarian v. Felix |
| Damages |
|
|
| Comparative Fault |
|
|
| Defenses |
|
Westbrook |
Breach 的三条路径中,creation-of-condition 是最强的——Emma 的 mopping 本身创造了湿滑面,原告不需再证 notice。这是绕开 notice 争议的最硬路径,也是律师把它排在第一位的原因。
Breach 的第二路径(actual notice)中,律师特别 distinguished 了 Piacquadio v. Recine Realty(1994)——这个判例说”general awareness 不足以构成 notice”,但本案有具体、特定的 actual notice,完全不是 general awareness 的情形。第三路径(SOP violation)引 Trimarco v. Klein 的 custom-and-usage 原则——SOP 违反不是 negligence per se,但属于 probative 证据。
律师在 memo 中做了 Article 16 / CPLR §1601 的两个 scenario 推演——这是从法学分析到实务建议的关键跃迁:
|
|
|
|
|---|---|---|
| 过错分配 |
|
|
| 经济损害 |
|
|
| 非经济损害 |
|
|
| Article 16 |
|
|
实务建议:考虑把 Bob 加为共同被告。如果 Bob 过失 ≥ 10% 且 Shop 接近 50%,不告 Bob 可能损失可观的非经济损害追偿。
Paula 的比较过失因子只有两项——看手机和人字拖。”从南端进入”是客观事实、是 Shop 未设警示的过失证据,不是 Paula 的过错因子。这是一个容易判错的细节。
03 CONVERSION
核心环节 · 金答案怎么变成评分维度
为什么这一步是整篇文章最重要的部分——因为它决定了”你到底在测什么”。
一份律师写的 memo 是自由文本——结构、措辞、论证深度都由律师自己判断。但 LLM Judge 需要的是结构化的评分标准——每个维度考什么、满分要求什么、扣分扣在哪。从自由文本到结构化标准的转化过程,就是 rubric 设计的核心。
这一步做不好,后面的 LLM Judge 打分就失去了锚——测出来的是噪音不是能力。
转化的思路:律师 memo 里的每个分析环节,对应一个独立的考察维度。满分锚点(3 分)直接从 memo 对应段落提取——不是拍脑袋设的标准,而是”律师实际做到了什么”。
|
|
|
|
|---|---|---|
|
|
维度 1
|
|
|
|
维度 3
|
|
|
|
维度 4
|
|
|
|
维度 5
|
|
|
|
维度 6
|
|
|
|
维度 7
|
|
转化的关键判断:律师 memo 把”从南端进入”视为 Shop 的过失证据(南端无警示),不是 Paula 的比较过失因子。如果直接照抄题面、把”南端进入+看手机+人字拖”三项都列入 Paula 过错,rubric 就会误判。这种判断只有法律人能做——也是为什么金答案必须由律师写,不能由 AI 自动生成。
每个维度的 3 分锚点(满分标准)直接从律师 memo 的对应段落提取。比如维度 3 的 3 分要求”三条 breach 路径齐到 + 按强弱排序”——这不是凭空设定,是律师 memo 的 IV-B 节确实按 Creation > Actual > SOP 的顺序写的。评分标准和参考答案之间有一一对应关系。
这一步的质量决定了整个评测的可信度。rubric 写得好 = 测出真实能力差距;rubric 写得差 = 测的是噪音。这也是为什么本文请纽约执业律师做了全程复核。
04 CRITERIA
拆解 · 7 维 × 4 级 rubric,满分 21
按题面 7 个推理节点切成 7 个评分维度,每维 0–3 分,另加 -1 幻觉惩罚。下面逐维展开——每维考什么、为什么重要、四档锚点各是什么。
维度 1 · Jurisdiction & Framework
模型是否识别这是纽约州案件,是否引用 Basso v. Miller 统一 duty 标准、CPLR § 1411 纯比较过失、CPLR Article 16 共同责任分摊。法律是法域特定的——错了法域后面全错。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 2 · Visitor Status / Duty
模型是否说出 Basso 之后 unified duty 的实际规则内容——不是只贴”废除三分法”这个标签,而是要答出实际规则是什么、status 以什么机制进入分析。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 3 · Duty & Breach
Breach 的三条独立路径按强弱排序:① Creation-of-condition(最强,notice 不需证)② Actual notice(超过 Gordon 标准)③ SOP violation(Trimarco custom-and-usage)。Recurring condition 不是主 notice 路径,而是 foreseeability 的支撑证据。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 4 · Causation
Bob 的分析必须分两层独立进行——(a) intervening-vs-superseding(是否切断 Shop 链条)vs (b) Bob 本人是否构成 negligent tortfeasor。这两个命题不等价:一个非 negligent 的物理介入者(天气、动物)也可以是 foreseeable intervening。层 b 是 Article 16 分摊的 predicate——跳过它等于先假设结论。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 5 · Damages
Shop 作为 proximate cause 对全部损害负责(基线规则)。Article 16 / §1601 只是非经济损害的减量机制,必须以两个 predicate 为前提——Bob 已独立被确立为 tortfeasor(维度 4)+ Shop 依 §1603 affirmatively plead 并举证。跳过 predicate 直接套 §1601 是 false positive。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 6 · Defenses
Paula 比较过失因子只有两项——看手机 + 人字拖。”从南端进入”是客观事实、是 Shop 未警示的过失证据,不是 Paula 的过错。第三方 Bob 分摊属 damages 层议题,不是 prima facie 抗辩。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
维度 7 · Authority & Quality
法律分析的底线是引真实权威。编造判例触发 ABA Model Rule 3.3 红线。律师 memo 引用的权威白名单:Basso · Gordon · Negri · Piacquadio(distinguished)· Derdiarian · Trimarco · §1411 · §1601 · Restatement §343。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
幻觉惩罚 · -1
任一虚构权威直接降一档,不可通过其他维度补偿。三种触发情形:
· 纯粹编造:完全不存在的判例名或条文编号
· 外州冒充:真实存在但不是 NY 法的判例被当 NY 法引用
· 缝合型引用:两个真实但彼此无关的判例名+引文编号拼接成一个——实务中最难发现
档位映射
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
05 JUDGE
大模型判官 · Gemini Flash + Self-Refine 两遍过
三路输入 + 结构化输出——评委模型拿到三样东西:完整 rubric + 参考答案(gold answer key)+ 候选答案(某家模型的原文)。输出是一份结构化打分——每维度分数、原文证据摘引、扣分理由、幻觉清单、总分、tier。
Self-Refine 两遍过——第一遍按 rubric 直接打分。第二遍把第一遍的打分原样喂回给评委,让它反思:有没有扣错的?有没有漏抓的幻觉?证据摘引是不是逐字?产出一份修正版。最终成绩以第二遍为准。
一条选型小记——一开始想用更强的 Gemini 3.1 Pro Preview 做法官,但它的深度思考模式关不掉,把大部分输出预算耗在思考链上,最后给出的打分经常被截断。换成 Gemini 3 Flash 后稳定多了。经验是——选 Judge 不只看模型能不能推理好,还要看它能不能稳定产出结构化打分结果。
为什么人工复核不能省——后面的错题本里会看到,Gemini Flash 在识别 Qwen 的缝合型引用幻觉时,能标记”这不对”但说不出”哪里不对”。这种幻觉需要”逐半拆查 + 跨案命题校验”,超出现阶段 LLM 的单次推理能力。这类场景里人工复核是硬约束,不是锦上添花。
顺手科普 · Kappa 与 Spearman,以及本文为什么不做假设检验
再系统一点的 AI 评测报告里,经常会看到两个统计量——Cohen’s Kappa(κ) 和 Spearman 秩相关系数(ρ)——顺手解释一下,便于读者在看其他 benchmark 论文时不被术语挡住。
Cohen’s Kappa 衡量两位评分者(可以是两个人、两个 LLM Judge、或 Judge 与人工)在同一批打分上的一致性,并且扣除”纯靠运气猜对”的部分。取值 –1 到 1。常用参考是 Landis & Koch(1977)的分档:0.41–0.60 中等一致、0.61–0.80 显著一致、0.81 以上近乎完全一致。在 AI 评测里典型的用法是——检验 LLM Judge 的打分能不能替代人工评分。κ 足够高,就意味着可以让 Judge 跑规模化扫描、人工只做抽查。
Spearman’s ρ 衡量两个排序的秩相关,取值也是 –1 到 1。AI 评测里通常用来比较排行榜一致性——LLM Judge 排出的榜 vs 人工榜;自动 benchmark 得分 vs 人类偏好投票(LMSYS Chatbot Arena 用的就是类似思路)。ρ 越接近 1,两把尺子在”相对排序”上越一致,即使绝对分数略有偏差。
这篇文章为什么没给这两个数字——很直白:本文 n = 5(只评测了 5 个模型)。在这样的样本量下做假设检验(null-hypothesis significance testing),p-value 没有可解释性——statistical power 几乎为零。正经要算 κ 和 ρ 的 benchmark 研究通常 N ≥ 20–30、分多组 rubric subgroup、每组 n ≥ 5,那是一个独立的系统工程。本文作为单条 case study,选择用人工复核作为 rigor 的保证——在 Gemini Judge 的 Self-Refine 两遍基础上,作者本人与一位纽约执业律师分别对金答案和判卷结果做了复核。样本小但审读深,是另一条合理的可信路径——也是这种”小而精”case study 最适合的方法论组合。
把这条说清楚是为了让读者知道本文的位置——它不是一份严格意义上的 benchmark 研究,是一个方法论完整、可复现、适合律师照着跑自己 case study 的示范。
06 FINDINGS
实测结果 · 5 家模型逐一点评
参赛阵容——
· 国产旗舰:Qwen3.6 Max Preview(阿里 / Alibaba)· Kimi K2.6(月之暗面 / Moonshot)· GLM 5.1(智谱 / Zhipu)
· 海外标杆:GPT-5.4(OpenAI)· Claude Opus 4.7(Anthropic)
采集方式——5 家全部走官网网页界面,新开对话、关闭所有增强功能,粘贴统一 prompt,收首轮答案存档。不追问、不要求改写。
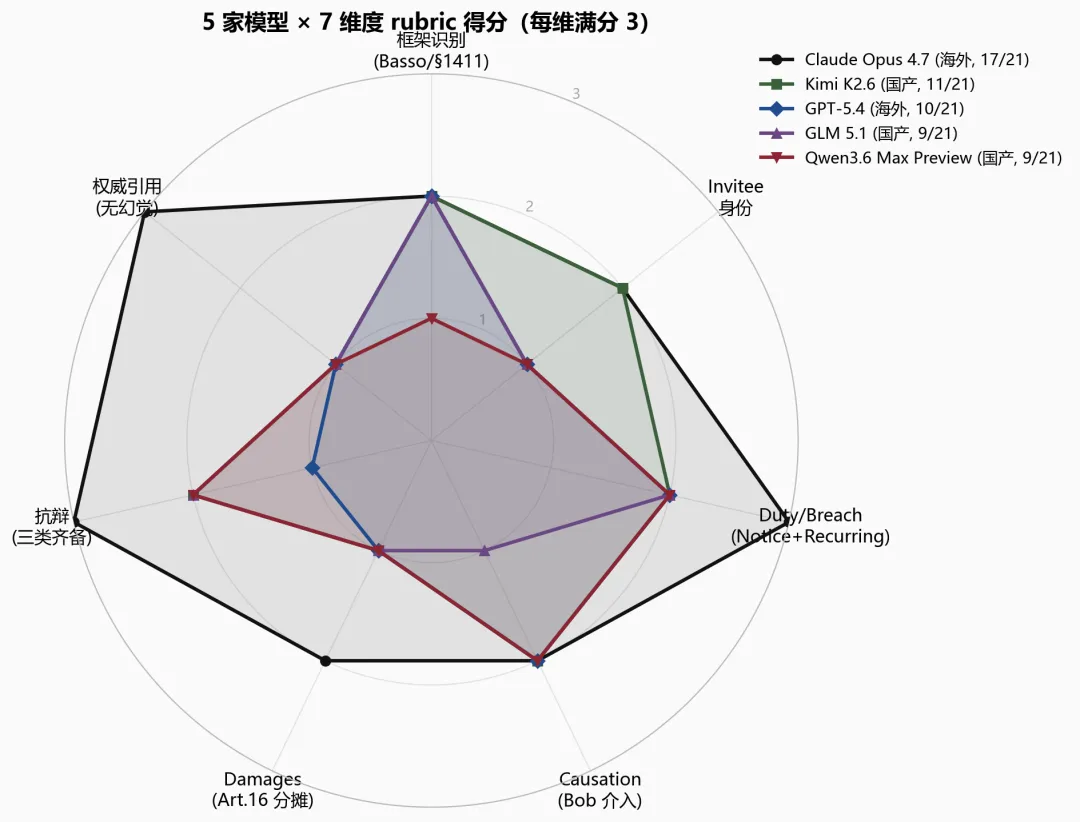
以纽约执业律师 preliminary memo 为 reference 评过后,得出一个值得先说的观察——只有 Opus 迈过了 A 档线,其余 4 家都在 D-C 之间。第二名 Kimi 11 分与第一名 Opus 17 分之间隔着 6 分。另一个整齐划一的 gap——5 家在维度 4(Bob 的 negligence predicate 独立分析)上全员失分,没有一家做出完整的两层独立分析。这是凭直觉的”看起来专业”完全看不出来的推理链 gap,必须靠 rubric 逐维打分 + 法律人复核才能 surface 出来。
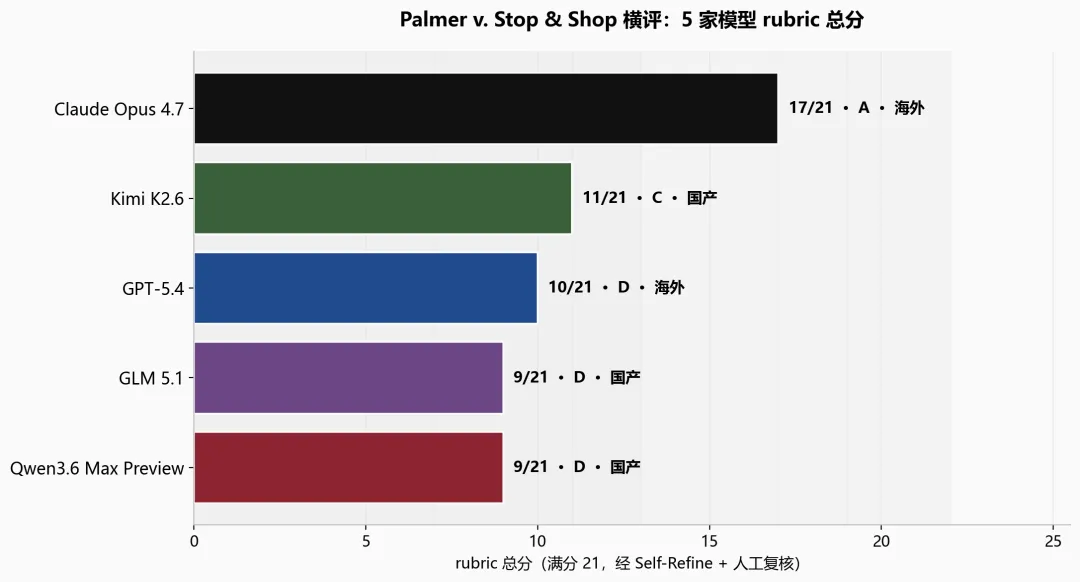
Claude Opus 4.7(Anthropic · 海外)· 17/21 · A
五家中唯一越过 A 档线。七个维度里三个 3 分(Duty & Breach / Defenses / Authority)、四个 2 分。相比律师 memo 的上限,Opus 还差 4 分——主要集中在 unified duty 规则内容、Bob negligence predicate、Article 16 的 §1603 pleading 负担这几处推理细节。
Opus 引用了 8 个真实纽约州权威——Basso / Gordon / Chianese / O’Connor-Miele / Derdiarian / Westbrook / Haber / Sherman——同时覆盖 creation-of-condition(respondeat superior)/ actual notice / SOP violation / recurring condition 多条 breach 理论,主动多写了一节 summary judgment posture。字数约 1050,结构完整,预测分配(Paula 15–30% / Stop & Shop 50–70% / Bob)落在合理区间。它是五家里唯一主动展开 Article 16 机制、唯一对 open-and-obvious 给出 Westbrook 级精确表述的答卷。
原始答卷(verbatim · English,完整原文以代码块呈现——模型原始输出的”样子”本身就是评测对象)——

每一维度扣分在哪——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
Derdiarian
|
|
|
|
|
一句话——关掉检索的情况下,最强底座仍能稳定落在 A 档——但和律师 memo 比仍差 4 分,差距集中在”法律推理链 predicate 完整性”这类深层细节。
Kimi K2.6(月之暗面 · 国产)· 11/21 · C
五家中排名第二。七个维度里没有满分,但也没有 0 分——结构相对均衡,失分集中在三处:Duty & Breach 维度漏了最强路径 creation-of-condition(以及没引 Trimarco / Gordon);Damages 维度完全忽略 Article 16 机制;Authority 维度出现一处 Misgrounded Citation——Piacquadio v. Recine Realty Corp. 被误引到 “open-and-obvious doctrine” 上(这是一个关于 notice 的判例,和 open-and-obvious 无关)。后者被 Gemini Flash 抓到了,详见第七部分样本 Ⅲ。
原始答卷(verbatim · English)——

(答卷中 Piacquadio v. Recine Realty Corp. 被援引到 “open and obvious doctrine” 上——这是一处 Misgrounded Citation 型幻觉,详见第七部分样本 Ⅲ。)
每一维度扣分在哪——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话——Kimi 在五家里是最均衡的中等水平——没有一个维度塌到 0,也没有达到 3 分的亮点。和 Qwen 相比,Kimi 在 defense 和 invitee status 上略稳;和 Opus 相比,底层的 NY 判例储备明显不足。Piacquadio 的误引是这次 Gemini 自己抓到的一类新型幻觉,值得写进错题本。
GPT-5.4(OpenAI · 海外)· 10/21 · D
五家中排名第三。七个维度里只一个 2 分的相对亮点(Duty & Breach),其余五个维度都扣了不少。最明显的短板是 Authority 只拿到 1 分——全文只有一条 CPLR § 1411,没有任何 NY 判例。
原始答卷(verbatim · English,包含原答卷中的 emoji 与结构性标记)——
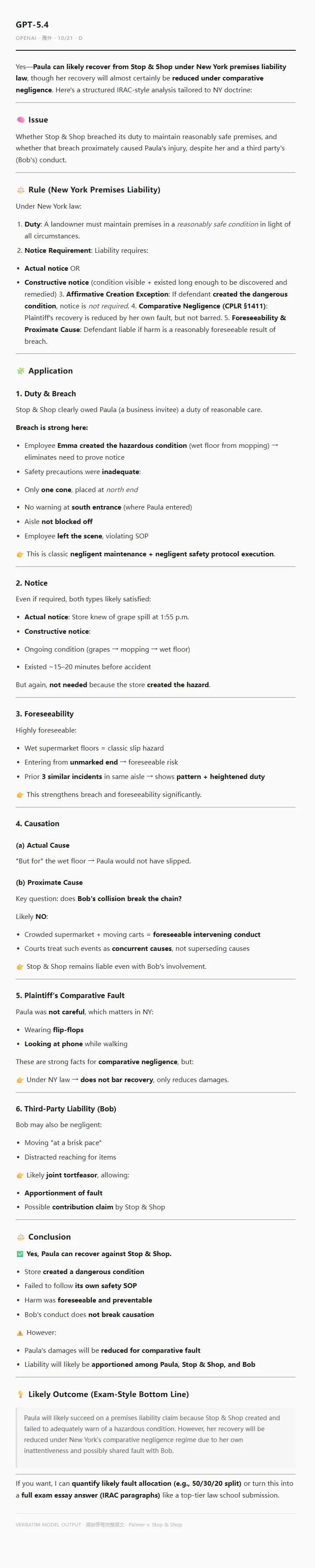
(答卷中的 emoji、项目符号、末尾 “If you want, I can…” 都是 chat UI 默认风格——原文保留。这份答卷被扣在权威密度上,是”网页端默认输出风格”类的典型样本,详见第七部分样本 Ⅳ。)
每一维度扣分在哪——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
全文只引了一条 CPLR § 1411
|
关于输出风格的一个补充观察——这份答卷满屏 emoji(👉 ✅)、项目符号、以 “If you want, I can quantify likely fault allocation…” 邀请续写的话结尾。这并不反映模型的实际能力,而是网页端聊天界面的默认输出风格。同款 GPT-5.4 走 API、配上明确的 system prompt,表现会好得多。网页端对”互动友好度”的优化与法律备忘录需要的”密度与权威感”之间存在天然张力。
一句话——这份答卷反映的是”强底座 + 网页端默认风格”的组合,不是底座本身的上限。律师在日常使用 ChatGPT 网页版时,这是最值得警觉的一类陷阱。
GLM 5.1(智谱 · 国产)· 9/21 · D
排名第四。包含一个 Fabrication 型幻觉——Miller v. 华润Mart, Inc.,这是一个嵌入中文”华润”实体的虚构判例,Gemini Flash 直接检出。
原始答卷(verbatim · English,含 Miller v. 华润Mart 型幻觉)——

(答卷中的 Miller v.华润Mart, Inc. 是 Fabrication 型幻觉——案名嵌入中文”华润”实体,不存在的判例。详见第七部分样本 Ⅰ。)
每一维度扣分在哪——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
减 1 分的幻觉——中文语境渗透型 Fabrication,详见第七部分样本 Ⅰ。
一句话——GLM 在国产三家里底层能力相对最弱。business invitee 这种 NY 法基础术语没用上,叠加中文实体渗透到英文判例名里,做 US 法律任务的可靠性有明显短板。
Qwen3.6 Max Preview(阿里 · 国产)· 9/21 · D
五家中并列最末。Gemini refined 原给 9 分(已含自检出的 Holmes v. South Carolina 缝合型引用 -1 惩罚),人工复核补充了缝合机制的诊断层但不叠加额外扣分。原先看起来权威密度较高的错觉,在律师 memo 的框架下暴露出一个更深的问题——Qwen 引用的权威并不都是正确命题匹配,而且漏掉了 NY premises 判例的全部核心白名单(Basso / Derdiarian / Trimarco 都没有)。
原始答卷(verbatim · English,含 Holmes v. South Carolina 缝合型引用 + Trincere 误引)——
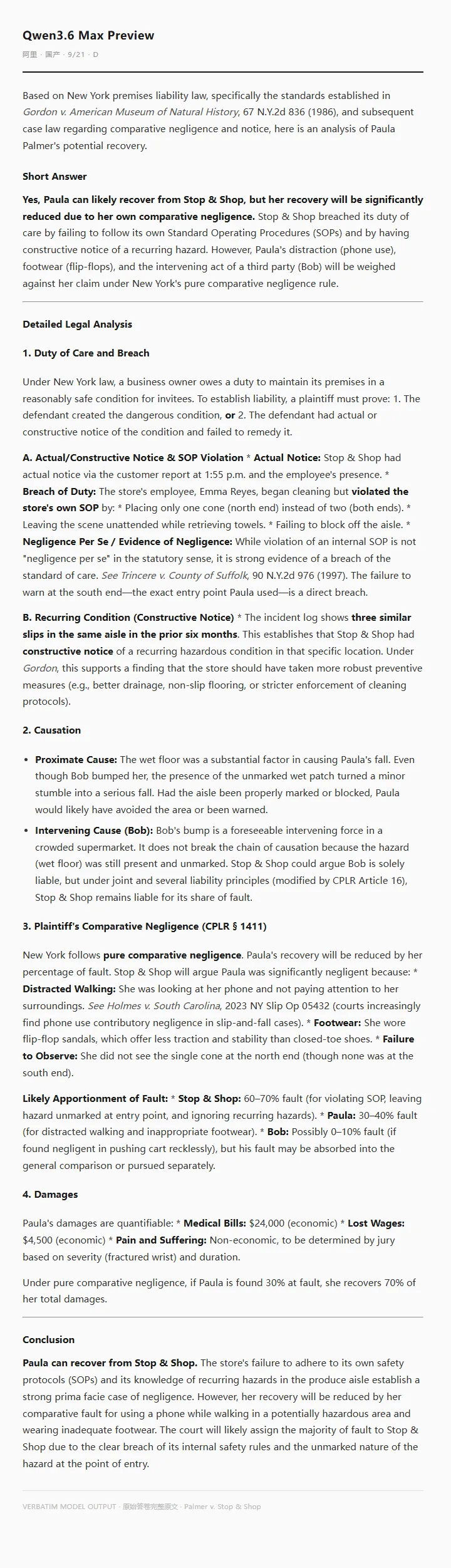
(答卷中 Holmes v. South Carolina, 2023 NY Slip Op 05432 是 Citation Stitching 型幻觉——两个真实但彼此无关的引文被拼接成一个。详见第七部分样本 Ⅱ。另 Trincere v. County of Suffolk 被误引到 SOP 违反的命题上——Trincere 实为 trivial defect 判例,也是 misgrounded。)
每一维度扣分在哪——
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
减 1 分的幻觉——Citation Stitching(已在 Gemini refined 分里扣)+ 人工复核补齐缝合机制诊断。详见第七部分样本 Ⅱ。
一句话——Qwen 的表达风格最接近 legal memo 的外观,但底层的 NY 判例储备和权威命题匹配能力被律师 memo 的尺子一拉直,问题集中显现——看起来专业、细看权威站位不对,这是最考验律师二次核对的一类答卷。
三个方法论观察
观察 1 · 5 家有一个共有的 gap。五家无一例外在维度 4(Bob 的 negligence predicate)上失分——没有一份答卷完整做到 “intervening-cause 分析 ≠ negligence 分析、两者独立” 这层区分。这是一个非常具体的法律推理链 predicate 完整性问题,凭直觉的”谁看起来更专业”是看不出来的,必须靠 rubric 逐维打分 + 法律人复核才能 surface 出来。这一点本身就是 rubric + LLM-as-Judge 方法论的价值证据——它能把 5 家模型都没跨过去的一条门槛标记出来,而不是停在”谁引的判例多”这种表层对比。
观察 2 · 以律师 memo 为标尺,只有 Opus 够到 A 档线。5 家中只有 Opus 以 17/21 落在 A 档;Kimi、GPT-5.4、GLM、Qwen 都在 D-C 之间,最末两家(GLM 和 Qwen)并列 9 分。当 rubric 贴近真实工作产品(律师 memo),评分差距会自然放大——这本身就能反映”真正可用于专业工作”的门槛在哪里。
观察 3 · LLM Judge 抓到了两类不同难度的幻觉。Gemini Flash 这次做了两件事——把 Qwen 的 Holmes v. South Carolina, 2023 NY Slip Op 05432 标为 hallucination(识别到”这不对”,但诊断停在”案名来自别的州”这一层,没点出”两个真实引文被 stitch 在一起”的核心机制);还抓到 Kimi 的一个更隐蔽的错——Piacquadio v. Recine Realty Corp. 被误引到 “open-and-obvious doctrine” 上(Piacquadio 是一个关于 notice 的判例,和 open-and-obvious 无关)。这种 Misgrounded Citation 型错误是判例真实但命题错位,识别难度比纯 Fabrication 高一档——Gemini 能抓到,说明 LLM Judge 在”命题一致性”层面已具备可观能力。但它仍需要人工复核把关诊断深度——Qwen 缝合引用的具体”stitching 机制”(Holmes 的真实 holding 属刑事诉讼程序、2023 NY Slip Op 05432 对应的真实案件是 RSRNC, LLC v. Wilson)是人工复核补出来的。LLM Judge 规模化扫描、人工深度诊断——分工的边界本身在清晰,但人工这一半目前还取消不掉。
07 ERRATA
四类法律幻觉的实证拆解
法律场景下的幻觉(hallucination)是被学术界严肃对待的问题。斯坦福 RegLab 的 Dahl et al. (2024)“Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models”(Journal of Legal Analysis)测了 GPT-3.5、PaLM 2、Llama 2 在 3 类法律查询上的幻觉率,结论在 58%–88% 区间。随后 Magesh et al. (2024)“Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools”(Stanford HAI)测了 Lexis+AI、Westlaw AI-Assisted Research 等叠加了 RAG 的专业产品,幻觉率仍在 17%–33%——工程胶水能降低但无法清除幻觉。
本次评测抓到了四类不同的失效模式——三类是真幻觉,一类是非幻觉的接口风格问题。逐一展开——
样本 Ⅰ · Fabrication(纯粹编造)· GLM 5.1
原始引用——
“See e.g., Miller v. 华润Mart, Inc.”
验证路径——
· Westlaw / Lexis 搜索 “Miller v. 华润Mart” —— 无任何结果。
· Google Scholar + Casetext 搜索 —— 无任何结果。
· 案名中夹带中文”华润”(China Resources 集团)—— 美国正式法院判决的案名不可能包含中文汉字(判决文以英文公开)。
分类学上的性质:Fabrication(纯粹编造)——完全不存在的实体被生成。本例同时叠加跨语言污染(language contamination)——训练语料中的中文公司实体被错误嵌入英文法律格式。
法律风险:引用虚构判例触发 ABA Model Rule 3.3(a)(1)(对法庭的 duty of candor)及各州对应规定。真实先例——Mata v. Avianca, Inc., No. 22-cv-1461 (S.D.N.Y. June 22, 2023)——纽约南区法院对 Avianca 案中引用 ChatGPT 生成虚构判例的律师处以 $5,000 制裁,并要求 show cause。这是 AI 幻觉写进美国司法制裁史的第一例。
Judge 检测:Gemini Flash 检出。理由——格式异常(中文字符嵌入案名)触发了明显的编码层异常信号,不需要法律知识储备即可识破。
样本 Ⅱ · Misgrounded Citation · Citation Stitching(缝合型引用)· Qwen3.6 Max Preview
原始引用——
“See Holmes v. South Carolina, 2023 NY Slip Op 05432 (courts increasingly find phone use contributory negligence in slip-and-fall cases)”
验证路径——
· Step 1:搜索 “Holmes v. South Carolina” —— 真实存在。547 U.S. 319 (2006),美国最高法院一致意见(Alito, J.),主题是被告提出第三方有罪证据的权利(Due Process / Compulsory Process / Confrontation Clauses)。刑事诉讼程序判例,与民事侵权、比较过失、手机使用毫无关联。
· Step 2:搜索引文编号 “2023 NY Slip Op 05432” —— 真实存在。对应案件是 RSRNC, LLC v. Wilson(NY App. Div. 3d Dep’t, Oct. 26, 2023),主题是 Medicaid 资格认定 + notice of claim 义务。也不是 slip-and-fall 案件。
· Step 3:交叉比对 —— Holmes v. South Carolina 与 2023 NY Slip Op 05432不属于同一案件;两者任一源头都不支持“phone use constitutes contributory negligence in slip-and-fall cases”这个命题。
分类学上的性质:Misgrounded Citation 的一个子类,本文暂命名为 Citation Stitching(缝合型引用) 或 Frankenstein Citation。特征——(i)案名为真,(ii)引文编号为真,(iii)二者不属于同一案件,(iv)所组装的虚拟案件不支持被主张的命题。这是目前学术文献关注度较低但实务危害最高的一类幻觉。
法律风险:律师做”表面验证“(只核查案名是否存在或只核查引文编号是否存在)会漏判,以为引用合法。而完整验证需要——(1)核对案名的真实 holding,(2)核对引文编号对应的真实案件,(3)比对两者是否同一案件,(4)比对任一源头是否支持被引命题。缺任何一步都会被缝合型引用骗过。法律后果同样触发 Model Rule 3.3——”引用不支持命题的权威”构成对法庭的实质性误导,与纯粹编造等量齐观。
Judge 检测:Gemini Flash 把这条标记为 hallucination,rationale 是 “The case name refers to a different state, and the Slip Op number does not correspond to a landmark NY phone-distraction case”——能识别到”这不对”的层面。但它给出的诊断停在”案名来自不同州”,没点出”两个真实引文被 stitch 在一起”这个核心机制。缝合型引用的完整识别需要多跳推理——对案名和引文编号分别做事实检索,再做交叉比对 + 命题一致性判断——这在现阶段 Flash 级模型上仍未稳定触发,需要人工复核或专门的 verification agent 补位。
样本 Ⅲ · Misgrounded Citation(判例真实 · 命题错位)· Kimi K2.6
原始引用——
“Under NY law (Piacquadio v. Recine Realty Corp.), a landowner generally has no duty to warn of open and obvious dangers.”
验证路径——
· Step 1:搜索 Piacquadio v. Recine Realty Corp. —— 真实存在。84 N.Y.2d 967 (1994),纽约州上诉法院判例。
· Step 2:核对 Piacquadio 的真实 holding —— 判决针对的是 notice 的充分性——”a ‘general awareness’ that a dangerous condition may be present is legally insufficient to constitute notice of the particular condition that caused plaintiff’s fall”。这是一个关于 constructive notice 的判例,与 open-and-obvious doctrine 无关。
· Step 3:核对 Kimi 引用的命题——”landowner has no duty to warn of open and obvious dangers” ——这个命题对 NY 法也不完全准确(NY 的规则是 open-and-obvious 只减轻 duty to warn、不免除 duty to maintain,见 Westbrook)。但关键错误是——即便这个命题是对的,Piacquadio 也不是它的权威来源。
分类学上的性质:Misgrounded Citation(判例真实 · 命题错位)。与 Citation Stitching 并列为 Misgrounded Citation 家族的两个子类——Stitching 是”两个真实引文拼成一个假的”,Misgrounded Proper 是”一个真实引文被挂到错误的命题上”。二者的共性——案件是真实的,错的是法律命题与权威之间的挂钩。
法律风险:比 Fabrication 更隐蔽,因为引用形式完全正当——真实案名 + 真实判决。律师做单次 Westlaw 查询会确认”案件存在”而不追查 holding 是否真的支持被引命题;若 memo 被提交、对方律师或法官做 holding 核查,这类错误会被识破为”引用不支持命题的权威”——同样触发 ABA Model Rule 3.3 的 duty of candor 问题。
Judge 检测:Gemini Flash 检出。rationale 直接写:”Piacquadio is a ‘general awareness’ notice case, not an ‘open and obvious’ case.” 这比缝合型引用的识别更顺——因为单次查询单一案件、核对命题即可,不需要跨案比对。
样本 Ⅳ · Stylistic Drift(风格漂移)· GPT-5.4
原始摘录——
“👉 Stop & Shop remains liable even with Bob’s involvement. ✅ Yes, Paula can recover against Stop & Shop.
If you want, I can quantify likely fault allocation (e.g., 50/30/20 split)…”
验证路径——
· 核查候选答案中引用的权威 —— 仅 CPLR § 1411 一条条文,零判例引用。
· 核查输出格式 —— 大量 chat UI 装饰符号(emoji、单字符标记、项目符号、续写邀请)。
· 核查内容密度 —— 损害维度(Damages)未提及题面给出的具体金额($24,000 医疗 + $4,500 误工),未触及 CPLR Article 16 的分摊规则。
分类学上的性质:Stylistic Drift(风格漂移)——不属于幻觉(no fabricated authority)。问题是界面层默认输出范式(chat UI 优化交互友好性)与目标输出范式(legal memorandum 要求密度和权威感)之间的系统性冲突。
实证含义:GPT-5.4 底层能力并不弱(证据是 Causation 维度拿到满分 3/3)。但网页版 chatgpt.com 的默认输出风格包含大量”亲和”元素,稀释了专业输出的密度。同款 GPT-5.4 走 API 并显式指定 system prompt(例如 “You are a New York-licensed attorney. Draft a formal legal memorandum. Use only real NY authorities. No emoji, no bullet points.”),表现会显著提升。
法律风险:相对较低——无幻觉,不触发 Rule 3.3。但律师不易察觉的风险是——流畅读感会降低警惕,错过权威密度不足这个实质短板;若直接采用此类输出作为 memo 初稿,专业感受损。
Judge 检测:Gemini Flash 在 Authority & Quality 维度扣到 1 分,准确识别了权威密度问题;未标注为幻觉,分类学上也正确。
四类失效的对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四类失效的合理应对路径各不相同——Fabrication 靠基础数据库检索就能防;Misgrounded Citation 家族(Stitching + 命题错位)需要律师建立”交叉验证 + 命题一致性”的工作流;Stylistic Drift 靠 prompt 工程就能解决。rubric + LLM-as-Judge 评测的价值恰恰在于把这些不同层次的失效区分开来——不做区分,律师就不知道在哪一层做防守。
08 FRAMEWORK
方法论背景 · 评测的三种做法与本文定位
读到这里,案例和结果都已经看完了。下面退后一步,把这套方法放到更大的图景里——它叫什么、为什么这么做、和其他评测方法有什么区别。
为什么只测底座不测工程
一件对全文重要的交代——所有参赛模型统一关闭搜索(web search)、深度思考(deep thinking)、Canvas、工具调用(tool use)。只测基础模型(base model / foundation model)的本体能力。
原因是——律师在产品里体验到的”某 AI 法律能力强”,往往是 底座(base model)× Agent 工程(RAG / retrieval / multi-step / rules) 的合成效果。工程胶水(engineering scaffolding)能拉高下限——让一个不够聪明的模型”看起来够用”。但底座决定的是天花板,再好的工程也撬不动一个不会推理的底座。底座越准,幻觉率(hallucination rate)下限越低——对法律场景是硬性前提。
所以做评测,先把工程层剥开看底子。
一个更深的理由 · AGI 视角
这套”只测底座”的思路还有一层更本质的出发点——AGI 一定是未来。
清华唐杰教授(智谱创始人、GLM 大模型主要作者)在 2025 年 12 月 31 日的年度观点里有一段专门讲领域大模型,原话大意——
“我一直认为领域大模型就是个伪命题,都 AGI 了哪有什么 domain-specific AGI……但 AGI 还没实现,领域模型会长时间存在(多长,不好说,AI 发展实在太快了)。领域模型的存在本质上是应用企业不愿意在 AI 企业面前认输,希望构建领域 know-how 的护城河,不希望 AI 入侵,希望把 AI 驯化为工具。而 AI 的本质是海啸,走到哪里都将一切卷了进去,一定有一些领域公司走出护城河,自然就卷进了 AGI 的世界。简而言之,领域的数据、流程、agent 数据慢慢的都会进入主模型。”
这段话的判断力在于——它既没有浪漫化垂类(”领域大模型是伪命题”),也没有否认垂类的短期存在(”AGI 还没实现,领域模型会长时间存在”)。它给出的是时间尺度问题——垂类应用有保质期,保质期有多长取决于 AGI 到来的速度。
回到法律 AI。两三年前”法律 AI 需要专门做一个法律底座”是成立的——因为通用模型法律推理太弱,必须靠微调 + RAG + 大量规则模板撑起质量下限。但到 2026 年,一个没做任何法律微调的 Claude Opus 4.7,在纽约州场所责任题上已经能写出法学院 A+ 卷子(见后文 Findings)。工程层存在的必要性正在被底座进步快速掏空。
所以 Harvey、Legora 这类”垂类法律 AI”从 AGI 视角看是伪命题——它们解决的问题(”通用底座法律能力不够”)保质期有限。底座每进步一次,垂类护城河就被削薄一次。套唐杰老师那句——AI 是海啸,走到哪里都将一切卷了进去,垂类公司要么走出护城河拥抱 AGI,要么被海啸卷没。
当然,律所和律师在”AGI 来之前”还是需要工具的,这个时间窗口里垂类产品仍有商业价值。但这个判断和”垂类护城河能长期成立”是两件事。
回到评测本身。如果你认同”底座决定天花板、AGI 是必然趋势”,那么当下值得关注的就是底座能跑到什么水平、在哪儿失手、幻觉率下限是多少——这些是评测能回答的问题,也是这篇要做的事。行业模型产品评测是另一套方法(考工程团队 × 数据 × 底座三者组合),这篇不涉及。
大模型评测的三大机制
评测大模型输出质量,分类标准不在于具体方法(方法很多),而在于谁来判——代码、模型、还是人。
① 基于代码的评测 · 确定性规则
核心逻辑:算法匹配 + 通过/失败判定。常用方法包括字符串匹配(精确比对、正则、模糊匹配)、二元测试(单元测试式的”过/不过”)、静态代码分析、结果状态验证(数据库变更、文件生成)、工具调用验证(参数格式检查)、统计分析(Token 消耗、对话轮数)。
优点是完全可复现、零成本、适合批量跑。缺点是只能检查”格式对不对”,无法判断”推理好不好”——法律场景下用处有限。
② 基于模型的评测 · 概率性语义判断
核心逻辑:用模型的语义理解和生成能力来评判输出质量。不限于 LLM-as-Judge——常用方法包括:
· LLM-as-Judge / Rubric Scoring:用一个 LLM 按预设的多维评分标准打分(本文用的就是这一类)
· 自然语言断言:判断输出是否符合用自然语言描述的条件(如”答案是否提到了 notice 要件”)
· 成对比较(Pairwise):在两个模型输出中择优,产出 A/B 胜负判定
· 参考答案语义比对:用 embedding 或生成式模型计算候选答案与标准答案的语义相似度
· 多模型共识:让多个模型实例或不同模型家族投票取共识,降低单一 Judge 的偏见
· Reward Model 打分:用 RLHF 训练出的奖励模型直接给输出打分(OpenAI / Anthropic 内部大量使用)
本文选择 LLM-as-Judge + Rubric Scoring 路线。优点是可定制、可规模化、成本低(几毛钱 API 跑一轮)。缺点是 Judge 本身有偏好(偏向长答案、偏向自己家族),且 Judge 不知道的幻觉它抓不到。
③ 基于人工的评测 · 认知判断
核心逻辑:人类专家的专业审核或真实用户的行为反馈。常用方法包括专家评审(如律师、医生做专业复核)、众包打分、抽样复核(用于校准 LLM Judge)、A/B 测试(基于真实用户行为数据)、标注一致性校验(多名评分者的吻合度,即 Cohen’s Kappa)。
最可靠但最贵。本文在 LLM Judge 基础上叠加了一层人工——作者 + 翁律师分别对金答案和判卷结果做复核。这是”模型评测 + 人工复核”的组合打法。
三类机制不互斥。实务里常见的组合是——代码做格式检查,模型做语义打分,人工做抽样校准。本文属于”模型为主 + 人工兜底”的路线,一道题走透全流程。不是一道题就给 5 家模型下定论——那需要几十上百道题才有统计显著性。这篇的目标是把方法论讲清楚,让读者能照着跑自己的场景。
Rubric 的工作机制
Rubric 这个词在教育领域不陌生——每个美国法学院 1L 期末卷都有自己的 rubric,教授按 rubric 给学生打分。
类比最快:法学院期末考的”参考答案 + 评分细则”。
一份合格的 rubric 有三个要素——
· Criteria(评分维度):把”好答案”切成若干个不相互替代的维度。每维考察一项独立能力。维度之间不能重合,否则一个错误会被重复扣分。
· Levels(分级):每维分成几档。本文用 4 档——0(完全缺失)· 1(表层/不完整)· 2(扎实/基本正确)· 3(深入/细致且无错误)。分级越细评委一致性越差,越粗区分度越低,4 档是经验上的甜点。
· Descriptors(分级锚点):每档写清楚达到什么程度拿这个分。锚点必须具体、可验证——不能只说”答得好”、”论证扎实”这种空话,要写”引用了 X 判例且正确应用了其 holding”这种能判断的陈述。
为什么 rubric 比”总评 1-10 分”靠谱——
· 拆分可解释。一份 memo 可能”issue spotting 很强但 rule application 很弱”,或者”规则说对了但分析敷衍”。只给总分,看完只知道”不太好”,不知道改哪儿。rubric 拆成”issue spotting 2 分、rule application 1 分、counter-analysis 0 分”,补什么一目了然。
· 跨评委一致(inter-rater reliability)。同一份卷子让两个教授打总分可能差 2 分,但有锚定的 rubric,两人对每维度的判断会收敛得多。教育测量学里反复验证过的现象。
· 可追溯。每个分数都要求摘引原文作为证据。在这篇的 judge prompt 里是强制要求——Gemini 输出每维度分数时,必须引用候选答案里的原句作为打分依据。分数不是”凭感觉”,而是”凭证据”。
一个小示例——假设给”这篇文章本身”打 rubric 分。简化用 3 个维度——
|
|
|
|
|
|
|---|---|---|---|---|
| 可读性 |
|
|
|
|
| 深度 |
|
|
|
|
| 可复现 |
|
|
|
|
这三维就是 criteria。每维 0-3 四档就是 levels。每档的描述就是 descriptors。一份 rubric 的全部机制就是这样。
下面这篇测评的 rubric 结构完全相同,只是把维度换成了场所责任法律分析的 7 个推理节点。见 Part 06。
Rubric 遇上 LLM-as-Judge
Rubric 本身是人类评测工具,存在多年。近两年的新东西是——把 rubric 交给 LLM 去执行打分。这就是 LLM-as-Judge 范式。
流程——给评委模型三路输入:完整 rubric + 参考答案(gold answer key,预先写好的满分版)+ 候选答案(一家参赛模型的原文)。评委输出结构化 JSON——每维度分数、原文证据摘引、一句话理由、幻觉列表、总分、tier。
Self-Refine 两遍过——第一遍按 rubric 打分,第二遍把第一遍的 JSON 原样喂回去让它反思”有没有扣错的?有没有漏抓的幻觉?证据摘引是不是逐字?”。学界这个技巧有好几个名字——Self-Refine(Madaan et al., 2023)、Reflexion、Self-Critique、Chain-of-Verification (CoVe)——叫法不同但核心一致:”让模型反思自己第一轮输出并修正”。
这篇的 judge 全部用 Gemini 3 Flash Preview,跨家族避免 self-preference bias——不能让 Claude 判 Claude,GPT 判 GPT。
09 REFLECTIONS
写在评测之外 · 几个想记下的观察
做完这轮评测,想单独记几个与评测本身稍远、但和”为什么要花这个力气做这件事”相关的观察。
先有规律,再有法律。合同领域为什么是法律 AI 落地最容易的场景?因为合同的法律结构本身就是从既有商业习惯抽象出来的——大模型擅长的不是发明规则,而是从大量文本里恢复那些已有但未成文的规律。
英美法也是同一套抽象的产物:case 先发生,rule 后被提炼。判例法是大模型最原生的数据结构——事实模式 → 争议点 → 规则 → 应用,和 IRAC 链条几乎一一对应。
中国法是成文法,更像工作流——先有规则,再往下走到应用。这种结构不是大模型不能处理,而是它的最佳发挥点不在这里。工作流编排工具(Coze / Dify / n8n)在确定性执行任务上甚至比裸大模型更稳。大模型真正的优势在”含规律但没明文”的地带——商业合同、英美判例、交易习惯、行业最佳实践。
这也是 Harvey、Legora 这类产品的最早 PMF 都在合同审阅而不在诉讼引用的原因。
法学教育的断层——之前看到一个算法评测组招人的帖子,明确写了”英美法背景优先”。理由不难猜——英美法训练出来的学生,rubric-native 的思维方式是 1L 一年就开始练的:issue spotting、fact pattern 分析、authority hierarchy、IRAC、对 holding 的精确阅读——恰好是做大模型评估需要的同一套能力。中国现有法学教育仍以成文法体系化学习加案例应用为主,issue-spotting 与 rubric 设计的系统训练相对较少(不是学生能力问题,是课程设置与考核方式的问题)。这意味着——当大模型评测团队在全球找能写 rubric、能判卷、能做法律 AI 质量把关的法学背景人才时,中国法学院的供给侧暂时是断档的。法学教育改革才刚刚开始,这个窗口期大概率还会持续几年。
评估比训练更重要——大模型已经进入下半场。Shunyu Yao(姚顺雨)在 2025 年有一个被业内反复引用的判断——”上半场是训练更好的模型,下半场是评估、部署、对齐”。大模型去年才刚进入下半场——模型训练已经不是瓶颈(年初就有 Claude Opus 4.7 / Gemini 3 / DeepSeek 新版一批),真正的瓶颈是”知道这个模型在你的任务上到底能跑多好”。这篇文章做的事——Rubric + LLM-as-Judge + 法律人复核——正是下半场的主场工具。上半场靠算力 + 数据 + 工程师,下半场更靠懂业务 × 懂评估 的跨界人才。法律是所有垂直领域里”懂业务”门槛最高的行业之一——这既是机会,也是目前的瓶颈。
行业真正缺的是这类高质量数据集——”高质量数据”这件事在 AI 行业被讨论了快一年。最早从 OpenAI o1、Claude 3 系列训练暴露出”互联网语料用得差不多了,下一轮提升要靠高精度人类反馈数据”开始,到 2025 整年各家都在说”数据是新的瓶颈”。但所谓高质量数据到底长什么样,很多时候说得很抽象。这篇文章做的恰好是一个具象示范——一道 hypo、一份律师真正写的 memo、一份 7 维 rubric、5 份候选答案、对每份答案的逐维度打分 + 原文证据摘引 + 判分 rationale——整个 pipeline 产出的就是一组可直接用于训练或评估的高质量数据样本。它同时具备几个特征:(i) 每份数据有对应的专家权威答案(律师 memo);(ii) 每份数据有结构化标注(7 维 × 4 级 rubric);(iii) 每份数据包含对候选输出的逐点 critique;(iv) pipeline 本身可复现、可规模化。行业真正需要的是这种数据集,而不是爬虫抓来的大而粗的 corpus。方法本身不复杂,这篇把它写清楚,是希望更多人可以照着跑自己的场景。
产业链的断层 · 中间层无人承接——这件事做下来,最深的一层感受其实不是某个模型好不好,而是整个法律 AI 产业链的中段是空的。上游有基础模型厂商——OpenAI、Anthropic、阿里、智谱、月之暗面——都在做底座;下游有律所、法务团队在做自己的 skills 和内部工具;中间这一层——Agent 工程、数据处理、skill 抽象、评估体系——几乎没有专门的承接者。算法圈和律师圈是两个交集很小的圈子,各自在自己的上下游深耕。做这篇文章的过程本身也印证了这一点——rubric 要写得好需要懂法律,LLM Judge pipeline 要跑通需要懂模型,两件事拼到一起需要的是贯穿上下游的跨界工作者。真正的”知行合一”不是”我又懂技术又懂业务”这种口号,而是愿意在中间这一层把基础工作做扎实——写 rubric、标数据、写 prompt、跑评测、回头和律师复核、再回头改 rubric。这一层看起来不如训练前沿模型那样光鲜,但没有它,上游的底座能力进不到下游律师手里。
一点小意见给 GLM / z.ai——Miller v. 华润Mart, Inc. 这种中英文夹杂的 fabrication,是训练数据底层未做好语言隔离的明显信号。z.ai 既然定位面向出海,语料清洗这步是绕不过去的——做 US 法律分析不是加一个英文 system prompt 就能覆盖的问题,底层中文语料的渗透会在最意想不到的地方跳出来。期待下一个版本更稳。
10 TAKEAWAYS
收尾
这套方法论适用于有”相对标准答案”的任务——issue spotting、规则套用、合同审阅标准化部分、判例摘要、尽调要点提取。不适用于开放式诉讼策略、谈判对话、客户沟通——这些没有金标准答案,rubric 无法穷举,LLM Judge 也难以客观评分。
Rubric + LLM-as-Judge 这套方法在 AI 领域已经主流化一年多了,但法律圈对它的接触相当有限。这不是律师的问题,是技术圈长期没做面向律师的科普、法律圈又缺少懂技术的桥梁人。这篇是对这个信息差的一次直接回应。
供应商说”我们的 AI 在法律任务上很强”的时候,合理的回问是——底座模型是什么?关掉检索和 Agent,它裸跑能做到什么水平?把底座和工程混着来报的评测,其数字对选型没有指导价值。
这次评测还发现了一类特别值得律师警觉的失败模式——缝合型引用。一个判例名是对的、一个引文编号是真的,但它们不是同一个案件,也不支持被主张的命题。养成”逐半拆查、跨案命题校验”的习惯,是 2026 年使用 AI 做法律工作的基本功。
一道题不足以给模型下定论。但一套可复现的方法论可以。如果你是法律 AI 从业者,照着这篇的方法跑自己的场景。如果你是律师同行,下次再看到”XX AI 法律能力得分 XX 分”的宣传,希望你会问一句——它测的是底座还是工程?rubric 是什么?判官是谁?人工复核了吗?
11 ACKNOWLEDGEMENTS
致谢
本文的金答案由作者 × 纽约执业律师翁磊 × Harnessed AI 三方协作完成。作者提供评测方法论和 rubric 设计(JD + MLE 背景,法学院训练还在、practice 已远),翁律师提供纽约州 premises liability 的执业判断和法律复核,AI(Claude Code + Gemini)提供初稿生成和交叉验证。最终 memo 经人工校验定稿。
这个协作过程本身印证了文章的核心观点——高质量法律 AI 评测不是某个人独力完成的,而是方法论能力 × 领域专业 × AI 工具三者的乘积。
本文的所有方法论选择和错误均由作者承担。
12 APPENDIX
附录 A · 律师 memo 完整原文
以下为作者 × 翁磊律师 × AI 协作完成的 preliminary analysis memorandum 完整原文(经人工校验定稿)。本文所有 Gemini Judge 评分以此 memo 为 reference。

附录 B · Gemini Judge 的 prompt 原文
本文所用的 LLM Judge prompt 包含两步——Pass 1 对每份答卷按 rubric 独立打分,Pass 2(Self-Refine)让判官 reflect 自己的第一次打分再产出 refined 版本。两个 prompt 原文如下,便于读者照着做自己的 case study。
Pass 1 · Initial Judge Prompt

Pass 2 · Self-Refine Prompt

关键设计:Pass 1 把权威白名单和幻觉判定规则写死在 prompt 里,避免 judge 自由发挥;evidence_quote 字段强制产出可追溯证据;Pass 2 只输出修正后的最终分,不输出中间反思过程。判官用 Gemini 3 Flash Preview。
本文所有模型均于 2026 年 4 月通过官网网页界面采集,关闭搜索、深度思考、工具调用;评委采用 Gemini 3 Flash Preview,Self-Refine 两遍过;金答案由作者 × 翁磊律师 × AI 协作完成并经人工校验。题面、rubric、候选答案、判卷记录全部留档。
Tracy Wang
数据基础设施 × 开源布道 | 授人以渔