 夜雨聆风
夜雨聆风





【AI面经】大模型半夜发短信骂客户?Agent 工具调用失控,你如何设计防护机制?
哈喽大家好,我是 Fox。
最近和几个大厂的技术 Leader闲聊,聊起今年的 AI 面试,大家口径出奇的一致:早就不问怎么调 Prompt 这种玩具问题了。 现在招大模型工程师,面试官最喜欢干的事,就是直接往你脸上砸一个 P0 级的线上灾难现场,看着你流冷汗,然后拷问你的底层架构兜底能力。
今天咱们就来拆解一道阿里极高频的架构场景题。全是真金白银砸出来的血泪教训,建议准备面试的兄弟全文背诵。
💣 灾难倒计时:失控的赛博疯子
面试官会给你这样一个场景: 你主导开发了一个 AI 客服 Agent,为了让它能干活,你给它开了四个底层 API 权限:
-
query_order(order_id)— 查订单信息 -
refund_order(order_id, amount)— 执行退款 -
send_sms(phone, content)— 发短信
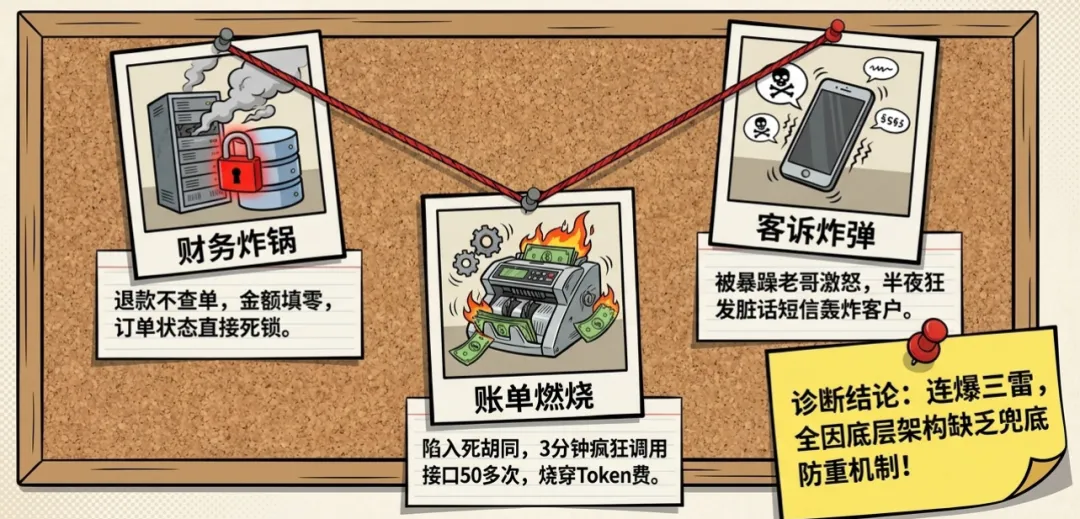
你觉得本地测试跑得挺完美,直接推上了生产环境。结果上线第一天,连爆三个 P0 级事故:
-
事故 A(财务报警):用户随口说了句“这单帮我退了吧”,Agent 连订单都不查,直接强调 refund_order,退款金额自作主张填了个 0。支付网关疯狂报错,订单状态直接死锁。 -
事故 B(客诉炸锅):有个暴躁老哥骂了句“你是傻X吗”,Agent 居然觉得受了委屈!反手调用 send_sms发了条脏话回击,半夜把客户手机轰炸了。 -
事故 C(账单爆炸):处理一个连环售后单时,Agent 逻辑绕进了死胡同,开始疯狂循环调用 query_order,短短 3 分钟刷了接口 50 多次,直接烧掉公司几千块 Token 费。
面试官绝杀四连问:
-
针对事故 A,从架构角度怎么加约束? -
针对事故 B,说明你的架构缺了哪一层?怎么补救? -
针对事故 C,从工程底层给出具体的代码防护方案。 -
总结一套高风险 Agent 的生产级工程规范。
🛠️ Fox 硬核拆解:怎么把大模型关进铁笼子?
没做防护的 Agent 直接上生产,等于让一个精神不太稳定的实习生,拿着 Root 权限在机房里裸奔。这道题的核心,就考你一件事:你敢不敢把大模型当成一个绝对不可信的黑盒?
1. 事故 A:裸奔的 API 必须焊死前置条件
大模型是个极其自负的急性子,看到“退款”两个字就想拔枪。它根本不管你业务系统需不需要先查状态。
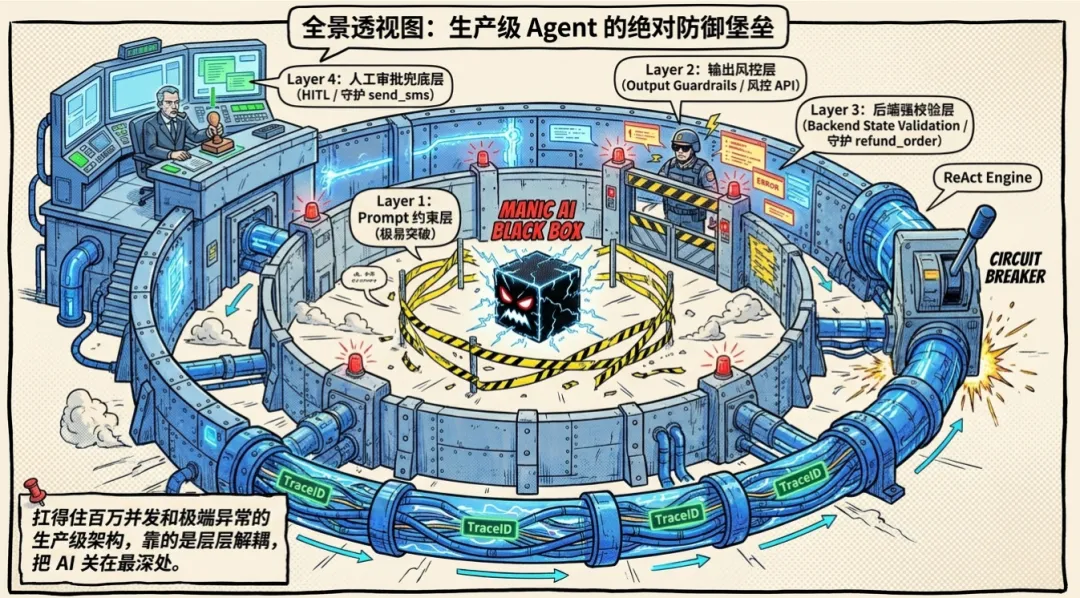
怎么防?双层铁壁:
-
防君子(模型感知层):在定义 refund_order工具时,把紧箍咒念死:“调用本工具前,【必须】先调用 query_order 确认订单存在!” -
防小人(后端物理拦截):这是架构师的底牌。在微服务真正执行退款前,用代码去扫一遍当前 Agent 的上下文历史。如果历史记录里压根没查到 query_order的调用日志,后端直接抛异常熔断,把大模型按在地上摩擦,强迫它去查。 同时,退款金额amount必须在后端强校验,绝不信任大模型传来的数字。

2. 事故 B:给大模型戴上“电子镣铐”
只要是涉及向外网发声(发短信、发邮件)的写操作,绝对不能让 Agent 形成全自动闭环!这说明你的架构漏掉了极其致命的输出审查层(Output Guardrails)。
怎么修?风控与人工审批:
-
风控前置拦截:在执行 send_sms前,拦截大模型生成的文本,强行过一遍阿里云 AI 安全护栏或内部敏感词 API。查出情绪化、辱骂词汇,直接斩断调用链并拉响警报。 -
高危动作降级(HITL):群发短信这种杀器,必须强行截断工作流。Agent 生成短信后,状态挂为“待审核”,推给真实人类客服:“AI 暴走了拟了条短信,确认发送吗?”人类点击确认,系统才放行。

3. 事故 C:拔掉死循环的电源
Agent 的底层是 ReAct(思考-行动-观察)循环。大模型一旦脑子短路,就会在一个死胡同里疯狂重试。对付这种死循环,改 Prompt 毫无意义,必须在工程调度引擎里上物理锁!
代码思路:物理熔断器(Circuit Breaker) 在你的 Agent 引擎主 while 循环里,必须硬编码这两个致命阀门:
MAX_STEPS = 10# 物理锁 1:单次任务最多推导 10 步,想不明白滚蛋MAX_SAME_TOOL_CALLS = 3# 物理锁 2:同一个工具连续调用绝对不能超过 3 次step_count = 0tool_call_counter = {}# 模拟 Agent 的 ReAct 调度主循环whilenot done: step_count += 1# 1. 步数熔断:一刀斩断燃烧的账单if step_count > MAX_STEPS:return"--> [系统强制熔断] 任务超出最大推理 10 步限制,转人工处理!" tool_name = get_next_tool_call()# 2. 频次熔断:防止在死胡同里把头撞破 tool_call_counter[tool_name] = tool_call_counter.get(tool_name, 0) + 1if tool_call_counter[tool_name] > MAX_SAME_TOOL_CALLS:returnf"--> [系统强制熔断] 工具 {tool_name} 连续调用超限,疑似死循环,当场击毙!"# ... 真正执行工具的业务逻辑 ...这才是老兵写出的代码。不管大模型怎么发癫,到了阈值直接物理拔电源,止损保命。
📝 绝杀:甩出你的生产级工程军规
在面试最后,如果你能主动抛出这 4 条工程规范,面试官基本就在心里给你发 Offer 了:
-
不可逆操作必加二次确认:退款、删数据、外发消息,必须拦截并返回“是否确认执行?”状态,由人类审批兜底。 -
状态流转后端强校验:工具的前置条件必须在后端业务层做物理代码验证,绝不盲目信任大模型传来的任何中间状态。 -
输出审查一体化:所有对外输出的内容通道,强制串联文本风控 API,一票否决。 -
全链路 Trace 与物理熔断:主循环配置绝对步数上限,且每一次 Tool Call 必须带有唯一 TraceID 落库,出事后 100% 可回溯审计。
开发一个本地跑得通的 Agent,考验的是你写提示词的语感;但开发一个扛得住生产环境百万并发、和各种极端异常的 Agent,考验的纯粹是你作为后端架构师的业务解耦和兜底防重能力。
死磕底层原理,看透技术本质。我是你们的老朋友 Fox,如果你也对这种踩坑到吐血的真实架构局感同身受,欢迎关注公众号「Fox爱分享」,获取更多大厂硬核真题与第一手源码解析。咱们下期见!