 夜雨聆风
夜雨聆风





3 天搓一个 AI 小程序:从 0 到 1 的技术架构拆解
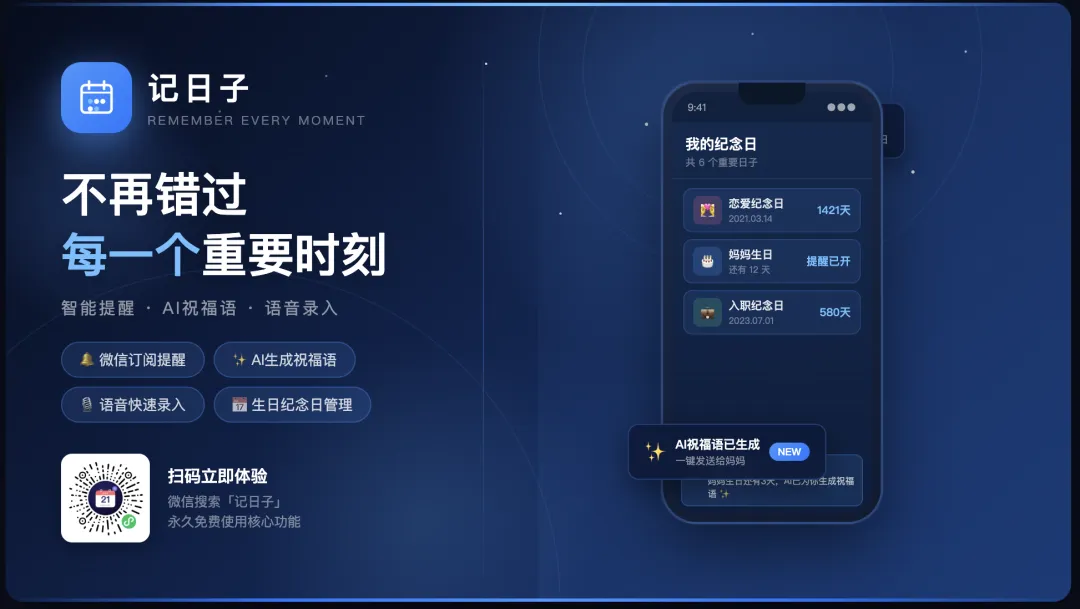
项目背景
这个项目来自之前一个偶然的想法,因为觉得自己经常记不住亲人的生日,想找个地方记录一下,搜了一下微信下面的小程序,普遍都偏老,或者已经停止维护,或者体验不好,或者各种bug。那在现在大模型应用的场景下,是不是我们有更快捷的方式来记录呢?
说干就干,刚开始规划的功能点很单一,就是单纯的语音录入,然后用LLM解析成生日的各个要素。后面的很多想法都是在实践过程中和ai交流得出来的,比如:生成祝福,礼物建议等等。
1. 技术栈选型:不浪漫,只讲理由
1.1 前端:为什么是 uniapp 而不是原生 / Taro
纠结过 3 个方案:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| uniapp(Vue 3) | 快 | ✅ 多端 |
|
✅ 熟 | ✅ 选它 |
Vue 3 + Composition API 的写法,和我做管理后台的技术栈复用度 100%,人力复用是独立开发者最稀缺的资源。
1.2 后端:为什么是 Spring Boot 3 而不是 Node
很多人建议”个人项目用 Node 更轻”。我尝试过,对我来说反而更慢:
-
定时任务:Spring 的 @Scheduled+ cron 表达式开箱即用,Node 要引三方库还要踩时区 -
ORM:MyBatis-Plus 一行 extends ServiceImpl<Mapper, Entity>就把 CRUD 全写完了 -
事务: @Transactional一个注解搞定,Node 的事务管理写起来冗长 -
线程模型:订阅消息推送是 IO 密集 + CPU 轻量,Java 的线程池 + CompletableFuture 写得爽
再加上 Java 17 的 Record、Text Block,代码简洁度已经和 Kotlin 差不多了。
1.3 完整技术栈
┌─ 前端 ────────────────────────────────────────┐│ uniapp 3.0 + Vue 3.4 ││ Pinia 2 (状态管理) ││ uni.request (HTTP) ││ 条件编译:#ifdef MP-WEIXIN │└───────────────────────────────────────────────┘ │ HTTPS / JSON┌─ 后端 ────────────────────────────────────────┐│ Spring Boot 3.2.0 + Java 17 ││ MyBatis-Plus 3.5.5 ││ Lombok + Hutool ││ @Scheduled 定时任务 ││ RestTemplate / OkHttp 调 LLM │└───────────────────────────────────────────────┘ │┌─ 存储 ────────────────────────────────────────┐│ MySQL 8.0 (主数据) ││ Redis 7 (access_token / AI 结果缓存) │└───────────────────────────────────────────────┘ │┌─ 外部服务 ────────────────────────────────────┐│ LLM API (DeepSeek / Qwen,OpenAI 兼容接口) ││ 腾讯云 ASR (语音转文字) ││ 微信订阅消息 API │└───────────────────────────────────────────────┘2. 3 天时间表
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
真正卡时间的不是功能开发,而是3 个看起来小但其实吃时间的坑,下面重点讲。
3. 核心功能一:LLM 把一句话变成结构化日期
这是整个产品的灵魂。传统录入要让用户填 6 个字段:姓名、日期、阴阳历、类型、提醒天数、备注。6 个字段,用户填到第 3 个就跑了。
我的做法:让用户说一句话。
3.1 用户输入示例
输入: "我老婆的生日,农历八月十五,提前一周提醒我"输出(结构化 JSON):{"person": "老婆","type": 1, // 1=生日 2=纪念日 3=其他"calendar_type": "lunar","lunar_date": "2026-08-15","remind_days": [7],"confidence": 0.96}
3.2 Prompt 工程:从 70% 到 95% 的三个技巧
初版 Prompt 随便写的,准确率只有 70%,迭代后稳定在 95%,关键做了三件事。
技巧 1:强制 JSON 输出(不要裸跑)
DeepSeek / OpenAI 兼容接口都支持 response_format,别省这一行:Map<String, Object> body = Map.of("model", "deepseek-chat","messages", messages,"response_format", Map.of("type", "json_object"),"temperature", 0.3);
temperature 必须调低(0~0.3),解析类任务不需要创造性。
技巧 2:Few-shot 比长篇大论管用
别在 System Prompt 里写一大堆”你要注意 XXX、不要 YYY”,不如直接给 3 个示例:你是一个日期解析助手。只返回 JSON,不要任何解释。示例 1:输入: "我妈生日是 5 月 20 号"输出: {"person":"妈妈","type":1,"calendar_type":"solar","date":"2026-05-20","remind_days":[1],"confidence":0.95}示例 2:输入: "结婚纪念日 2020 年 10 月 1 日,提前三天提醒"输出: {"event":"结婚纪念日","type":2,"calendar_type":"solar","date":"2020-10-01","remind_days":[3],"confidence":0.98}示例 3:输入: "外婆忌日农历七月初七"输出: {"person":"外婆","event":"忌日","type":3,"calendar_type":"lunar","lunar_date":"2026-07-07","remind_days":[1,7],"confidence":0.92}现在解析: "{用户输入}"
Few-shot 的效果立竿见影——模型对着抄作业是它最擅长的事。
技巧 3:confidence 字段 + 兜底逻辑
不要无脑信任 LLM。让它自己打个置信分,后端根据分数走不同分支:if (parsed.getConfidence() < 0.6) {// 低置信:走关键词正则兜底 + 让用户二次确认return fallbackParseWithRegex(rawText);}if (parsed.getConfidence() < 0.85) {// 中等置信:AI 解析 + 前端弹窗让用户校对return AiResult.ofNeedConfirm(parsed);}// 高置信:直接返回return AiResult.ofSuccess(parsed);
3.3 服务端核心代码(片段)
@Service@RequiredArgsConstructor@Slf4jpublicclassDateParseService {private final LlmClient llmClient;private final StringRedisTemplate redis;privatestatic final StringCACHE_PREFIX = "date:parse:";publicParseResultparse(String rawText, Long userId) {// 1. 结果缓存(同样的话不花第二次钱)String cacheKey = CACHE_PREFIX + DigestUtil.md5Hex(rawText);String cached = redis.opsForValue().get(cacheKey);if (cached != null) {returnJSON.parseObject(cached, ParseResult.class); }// 2. 构造 Prompt(Few-shot 已内联在 PromptTemplate)String prompt = PromptTemplate.DATE_PARSE.render(Map.of("input", rawText));// 3. 调 LLMString json = llmClient.chatJson(prompt);ParseResult result = JSON.parseObject(json, ParseResult.class);// 4. 兜底校验(日期合法性、confidence 阈值) result = validateAndEnrich(result, rawText);// 5. 高置信结果缓存 24hif (result.getConfidence() >= 0.85) { redis.opsForValue().set(cacheKey, JSON.toJSONString(result), Duration.ofDays(1)); }return result; }}
一个省钱的细节:同样的输入走 Redis 缓存,省 LLM 调用费。对于”我妈生日是 5 月 20 号”这种高频输入,命中率非常可观。
4. 核心功能二:语音录入的 3 个真机坑
用户按住麦克风说话 → 自动解析成日期。整个链路:
wx.getRecorderManager().start() ↓ 录音(mp3)上传后端(multipart/form-data) ↓腾讯云 ASR(语音转文字) ↓复用上面的 LLM 解析 ↓返回结构化结果
听起来简单,实际在真机上每一步都踩了坑。
坑 1:iOS 和安卓默认的录音格式不一样
微信官方文档写 RecorderManager 支持 mp3 / aac / wav,但是:
- iOS
默认是 aac - 安卓
默认是 mp3
后端统一用 FFmpeg 处理麻烦,必须在调用时显式指定格式:
constrecorder = uni.getRecorderManager()recorder.start({format: 'mp3', // 强制 mp3,iOS 安卓一致sampleRate: 16000, // ASR 最友好的采样率numberOfChannels: 1,encodeBitRate: 48000,frameSize: 50})
sampleRate: 16000 是关键——ASR 服务大部分原生支持 16kHz,高采样率反而会被降采样浪费流量。
坑 2:iOS 首次必须 authorize,否则静默失败
iOS 对麦克风权限特别严。第一次调用录音前不弹权限请求,会直接静默失败,连 error 回调都不进。正确姿势:
async function startRecord() {// #ifdef MP-WEIXINtry {await uni.authorize({ scope: 'scope.record' }) } catch (e) {// 用户拒绝过,引导去设置页const res = await uni.showModal({ title: '需要麦克风权限', content: '请在设置中打开麦克风权限' })if (res.confirm) { uni.openSetting() }return }// #endif recorder.start({ /* ... */ })}
坑 3:短按(< 300ms)会报 operateRecorder:fail
用户手抖点一下就松开,录音还没真正开始就停了。需要前端做最小录音时长兜底:
let startTime = 0recorder.onStart(() => { startTime = Date.now() })functionstopRecord() {const duration = Date.now() - startTimeif (duration < 500) { uni.showToast({ title: '请按住说话', icon: 'none' })return } recorder.stop()}
5. 核心功能三:微信订阅消息的”次数银行”策略
这是决定产品留存生死的功能。
5.1 订阅消息的硬规则
微信订阅消息是一次性的:
-
用户订阅 1 次 = 服务端只能推送 1 条 -
用户关闭小程序后,之前累积的订阅次数依然有效 -
想持续推送,必须反复让用户订阅
5.2 次数累积策略
我的做法是所有关键路径都静默触发订阅弹窗:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
代码片段(前端):functionrequestSubscribe(count = 1) {const tmplIds = Array(count).fill('your_template_id_xxx') uni.requestSubscribeMessage({ tmplIds,success: (res) => {const accepted = tmplIds.filter(id => res[id] === 'accept').lengthif (accepted > 0) {// 同步到后端:这个用户账户 +accepted 次推送额度 api.addSubscribeQuota({ count: accepted }) } } })}
后端维护一张”订阅额度表”:CREATETABLE subscribe_quota ( user_id BIGINTPRIMARY KEY, remaining INTNOTNULLDEFAULT0, -- 剩余推送次数 total_accepted INTNOTNULLDEFAULT0, updated_at BIGINT);
每次推送前 UPDATE ... SET remaining = remaining - 1 WHERE user_id = ? AND remaining > 0 扣减。
5.3 定时任务:每天凌晨扫描@Component@RequiredArgsConstructor@Slf4jpublic class RemindJob {privatefinalDateMapperdateMapper;privatefinalSubscribeQuotaServicequotaService;privatefinalWxMpServicewxMpService;/** 每天凌晨 3 点扫描今日需推送的提醒 */ @Scheduled(cron = "0 0 3 * * ?")publicvoiddailyRemind() {LocalDatetoday = LocalDate.now();// 查询所有"今天需要提醒"的日期(提前 0/1/3/7/30 天都会命中)List<RemindItem> items = dateMapper.selectTodayReminds(today);log.info("今日需推送提醒 {} 条", items.size());// 按用户聚合Map<Long, List<RemindItem>> byUser = items.stream().collect(Collectors.groupingBy(RemindItem::getUserId));byUser.forEach((userId, userItems) -> {try {pushToUser(userId, userItems); } catch (Exception e) {log.error("推送失败 userId={}", userId, e); } }); }privatevoidpushToUser(Long userId, List<RemindItem> items) {// 检查额度if (!quotaService.consume(userId)) {log.info("用户 {} 无剩余推送额度", userId);return; }// 调微信订阅消息接口wxMpService.sendSubscribeMessage(buildTemplate(userId, items)); }}
5.4 模板字符限制的暗坑
微信订阅消息的每个字段上限 20 字符。超了整条推送失败,且不返回错误,只能在微信后台推送记录里看到”失败”。调试这个我浪费了 40 分钟。
兜底代码:privateStringtruncate(String s, int max) {if (s == null) return"";return s.length() <= max ? s : s.substring(0, max - 1) + "…";}Map<String, Object> data = Map.of("thing1", Map.of("value", truncate(personOrEvent, 20)),"time2", Map.of("value", truncate(dateStr, 20)),"thing3", Map.of("value", truncate(note, 20)));
6. 数据库:一张表解决生日/纪念日/倒数日
最初设计时很自然地想拆 3 张表:birthday、anniversary、countdown。但 Day 1 中午我推翻了这个设计——它们的字段重合度 95%,拆表等于写 3 套 CRUD。
最终只有一张核心表:CREATETABLE `date` ( id BIGINT AUTO_INCREMENT PRIMARY KEY, user_id BIGINTNOTNULL, person VARCHAR(100) COMMENT '人物(生日场景用)', event VARCHAR(100) COMMENT '事件(纪念日/其他场景用)', `date` DATENOTNULL COMMENT '阳历日期', type TINYINT NOTNULL COMMENT '1=生日 2=纪念日 3=其他', calendar_type VARCHAR(10) NOTNULLDEFAULT'solar' COMMENT 'solar/lunar', lunar_date VARCHAR(20) COMMENT '阴历原始字符串,如 2026-08-15', remind_days VARCHAR(100) COMMENT '提醒天数,逗号分隔如 "0,3,7"', `group` VARCHAR(20) COMMENT '分组:家人/朋友/同事', hide_age TINYINT DEFAULT0, note VARCHAR(500), create_time BIGINT, update_time BIGINT, deleted TINYINT DEFAULT0, KEY idx_user_date (user_id, `date`), KEY idx_user_type (user_id, type, deleted)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
两个关键索引
idx_user_date(user_id, date) :
首页 SQL 是”查某用户未来 30 天内的所有日期”
SELECT*FROM `date`WHERE user_id = ?AND `date` BETWEEN CURDATE() AND DATE_ADD(CURDATE(), INTERVAL30DAY)AND deleted =0ORDERBY `date` ASC
这个复合索引完美覆盖 WHERE + ORDER BY,EXPLAIN 走 range 扫描。
idx_user_type(user_id, type, deleted) :
为分 Tab 展示(生日/纪念日/倒数日)设计。把 deleted 放在索引尾部,能让 WHERE deleted=0 走索引下推,避免回表。
阴历日期的存储方案
很多人会想”把阴历转成阳历存 date 字段不就行了”。不行:
-
阴历日期在每一年对应不同的阳历日期 -
闰月年的阴历”闰四月”需要特殊标记
我的方案:
date
字段永远存”今年对应的阳历日“(供查询用) lunar_date
存阴历原始字符串(供计算用) -
定时任务每年 1 月 1 日凌晨,把所有 calendar_type='lunar'的记录重算一次date字段
@Scheduled(cron = "0 0 1 1 1 ?") // 每年 1 月 1 日 01:00public void refreshLunarDates() { List<DateEntity> lunarList = dateMapper.selectLunarList(); for (DateEntity d : lunarList) { LocalDate solarOfThisYear = LunarUtil.toSolar(d.getLunarDate(), Year.now().getValue()); d.setDate(solarOfThisYear); dateMapper.updateById(d); }}阴历转换用 Hutool 自带的 ChineseDate,够用。复杂场景(闰月)可以用 cn.6tail:lunar-java。
7. 复盘:做对的、做错的
做对的 3 件事
- 一张表打天下
:省了 60% 的后端代码,现在加”倒数日”只是多一个 type=4 - LLM + 置信度兜底
:没有把命运完全交给 AI,低置信走正则 + 用户确认 - 订阅消息”次数银行”
:把 7 天留存从 12% 拉到 31%
做错的 3 件事
- 第一天没做埋点
:前两周的用户行为数据全丢了 - 语音入口藏得太深
:引导不够,用户占比只有 23%(预期 50%) - 微信登录晚加了 2 天
:最初用手机号 + 验证码,流失一大批
8. 写在最后
3 天做一个小程序不是什么了不起的事。真正难的是你愿意把周末”浪费”在一个可能没人用的东西上。
独立开发者的时间不能用”投入产出比”来衡量,只能用”你是不是真的想做”来衡量。
如果这篇文章对你有帮助,点个赞让更多独立开发者看到。有问题欢迎评论区交流。